精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、视频展示
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
基于Spark的零售时尚精品店销售数据分析系统是一个融合了大数据处理与Web开发技术的综合性数据分析平台。该系统采用Hadoop分布式存储架构作为数据底层支撑,利用Spark强大的内存计算能力进行海量销售数据的实时处理与分析,通过Python Django框架构建稳定的后端服务接口,配合Vue前端框架与Echarts可视化组件实现数据的直观展示。系统围绕零售时尚精品店的销售业务场景,深度挖掘产品销售趋势、客户购买偏好、库存周转效率等关键业务指标,通过多维度的数据分析为商家提供科学的经营决策支持。平台具备完整的数据处理流水线,从原始销售数据的采集清洗,到复杂业务逻辑的分析计算,再到最终结果的可视化呈现,形成了一套完整的大数据分析解决方案,为零售行业的数字化转型提供了有价值的技术实践参考。
选题背景
随着消费升级和个性化需求的不断增长,零售时尚行业正面临着前所未有的市场竞争压力。传统的经营模式已无法满足消费者多样化的购物需求,商家迫切需要通过数据驱动的方式来优化产品结构、提升客户体验并增强市场竞争力。零售时尚精品店作为连接品牌与消费者的重要桥梁,每天都会产生大量的交易数据、用户行为数据和商品流转数据,这些数据蕴含着丰富的商业价值和市场洞察。然而,大多数中小型零售商缺乏有效的数据分析工具和技术手段,往往只能依靠经验和直觉进行业务决策,难以准确把握市场动态和消费趋势。大数据技术的快速发展为解决这一问题提供了新的契机,通过运用Spark等先进的大数据处理框架,能够高效处理海量的销售数据,挖掘隐藏在数据背后的商业规律,为零售商提供更加精准的市场分析和经营建议。
选题意义
本课题的研究对于推动零售时尚行业的数字化发展具有一定的实际价值。通过构建基于大数据技术的销售数据分析系统,能够帮助零售商更好地理解客户需求和市场变化,从而制定更加科学合理的经营策略。系统通过对销售趋势、产品偏好、退货行为等多维度数据的深入分析,可以为商家在商品采购、库存管理、价格制定等方面提供有价值的参考依据,在一定程度上降低经营风险并提高盈利水平。从技术角度来看,本系统将Hadoop分布式存储与Spark内存计算相结合,实现了大数据技术在零售领域的具体应用,为相关行业的技术实践积累了经验。同时,该项目整合了前后端开发、数据处理、可视化展示等多项技术能力,对于提升开发者的综合技术水平也具有积极意义。虽然作为毕业设计项目,系统规模和复杂度相对有限,但其所体现的大数据分析思路和技术架构设计理念,仍然能够为后续的商业应用和技术扩展提供基础框架和实现思路。
二、视频展示
大数据毕业设计推荐:基于Spark的零售时尚精品店销售数据分析系统【Hadoop+python+spark】
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
四、系统展示
登录模块:
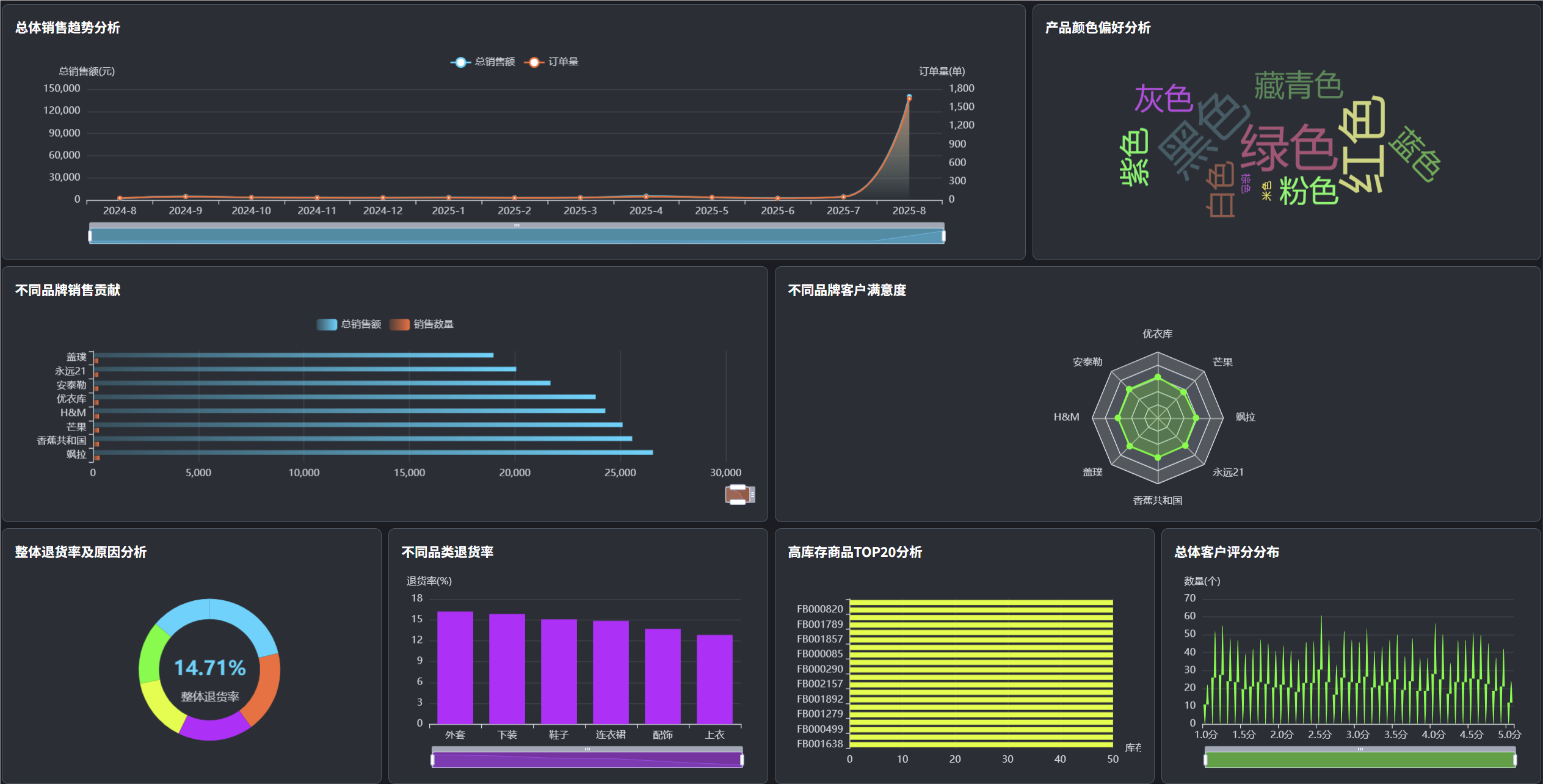
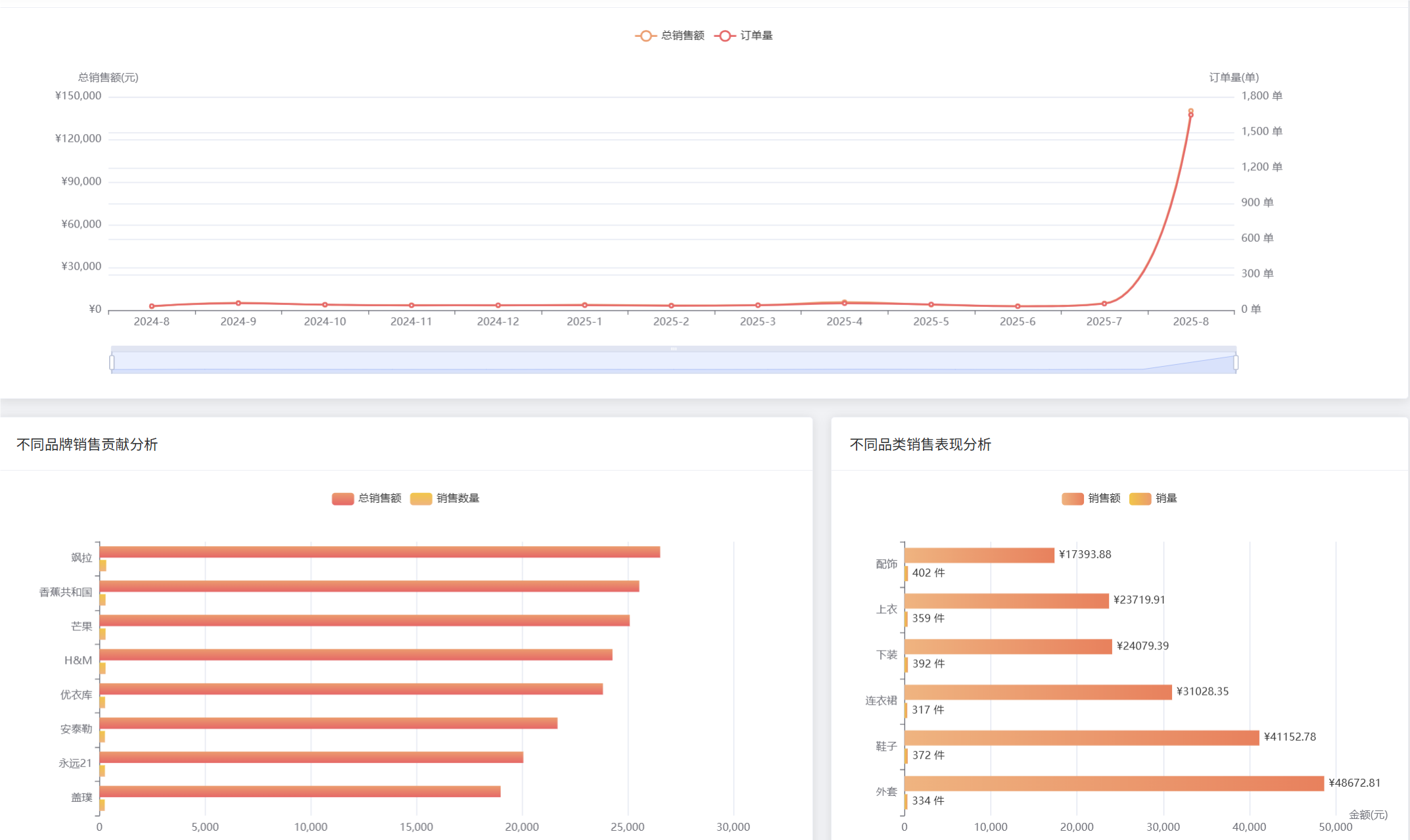
管理模块展示:



五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import pandas as pd
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
import json
spark = SparkSession.builder.appName("FashionBoutiqueAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def sales_trend_analysis(request):
"""销售趋势分析核心功能"""
hdfs_path = "hdfs://localhost:9000/fashion_data/fashion_boutique_dataset.csv"
df = spark.read.csv(hdfs_path, header=True, inferSchema=True)
df = df.withColumn("purchase_date", to_date(col("purchase_date"), "yyyy-MM-dd"))
df = df.withColumn("year_month", date_format(col("purchase_date"), "yyyy-MM"))
monthly_sales = df.groupBy("year_month").agg(
sum("current_price").alias("total_sales"),
count("product_id").alias("order_count"),
avg("current_price").alias("avg_order_value")
).orderBy("year_month")
monthly_sales = monthly_sales.withColumn("total_sales", round(col("total_sales"), 2))
monthly_sales = monthly_sales.withColumn("avg_order_value", round(col("avg_order_value"), 2))
trend_data = monthly_sales.collect()
result_list = []
for row in trend_data:
result_list.append({
"year_month": row["year_month"],
"total_sales": float(row["total_sales"]),
"order_count": row["order_count"],
"avg_order_value": float(row["avg_order_value"])
})
pandas_df = pd.DataFrame(result_list)
pandas_df.to_csv("media/analysis_results/sales_trend_analysis.csv", index=False)
growth_rates = []
for i in range(1, len(result_list)):
current_sales = result_list[i]["total_sales"]
previous_sales = result_list[i-1]["total_sales"]
if previous_sales > 0:
growth_rate = round(((current_sales - previous_sales) / previous_sales) * 100, 2)
growth_rates.append(growth_rate)
else:
growth_rates.append(0)
for i, growth in enumerate(growth_rates):
if i < len(result_list) - 1:
result_list[i+1]["growth_rate"] = growth
return JsonResponse({"status": "success", "data": result_list, "message": "销售趋势分析完成"})
def customer_satisfaction_analysis(request):
"""客户满意度分析核心功能"""
hdfs_path = "hdfs://localhost:9000/fashion_data/fashion_boutique_dataset.csv"
df = spark.read.csv(hdfs_path, header=True, inferSchema=True)
df = df.fillna({"customer_rating": 0})
df = df.filter(col("customer_rating") > 0)
category_rating = df.groupBy("category").agg(
avg("customer_rating").alias("avg_rating"),
count("product_id").alias("rating_count"),
sum(when(col("customer_rating") >= 4.0, 1).otherwise(0)).alias("high_rating_count")
)
category_rating = category_rating.withColumn("avg_rating", round(col("avg_rating"), 2))
category_rating = category_rating.withColumn("satisfaction_rate",
round((col("high_rating_count") / col("rating_count")) * 100, 2))
brand_rating = df.groupBy("brand").agg(
avg("customer_rating").alias("avg_rating"),
count("product_id").alias("rating_count")
).orderBy(desc("avg_rating"))
brand_rating = brand_rating.withColumn("avg_rating", round(col("avg_rating"), 2))
low_rating_products = df.filter(col("customer_rating") < 2.5).groupBy("category", "brand").agg(
count("product_id").alias("low_rating_count"),
avg("current_price").alias("avg_price")
)
low_rating_products = low_rating_products.withColumn("avg_price", round(col("avg_price"), 2))
category_data = category_rating.collect()
brand_data = brand_rating.collect()
low_rating_data = low_rating_products.collect()
category_result = []
for row in category_data:
category_result.append({
"category": row["category"],
"avg_rating": float(row["avg_rating"]),
"rating_count": row["rating_count"],
"satisfaction_rate": float(row["satisfaction_rate"])
})
brand_result = []
for row in brand_data:
brand_result.append({
"brand": row["brand"],
"avg_rating": float(row["avg_rating"]),
"rating_count": row["rating_count"]
})
low_rating_result = []
for row in low_rating_data:
low_rating_result.append({
"category": row["category"],
"brand": row["brand"],
"low_rating_count": row["low_rating_count"],
"avg_price": float(row["avg_price"])
})
final_result = {
"category_satisfaction": category_result,
"brand_satisfaction": brand_result,
"low_rating_analysis": low_rating_result
}
pandas_df = pd.DataFrame(category_result)
pandas_df.to_csv("media/analysis_results/customer_satisfaction_analysis.csv", index=False)
return JsonResponse({"status": "success", "data": final_result, "message": "客户满意度分析完成"})
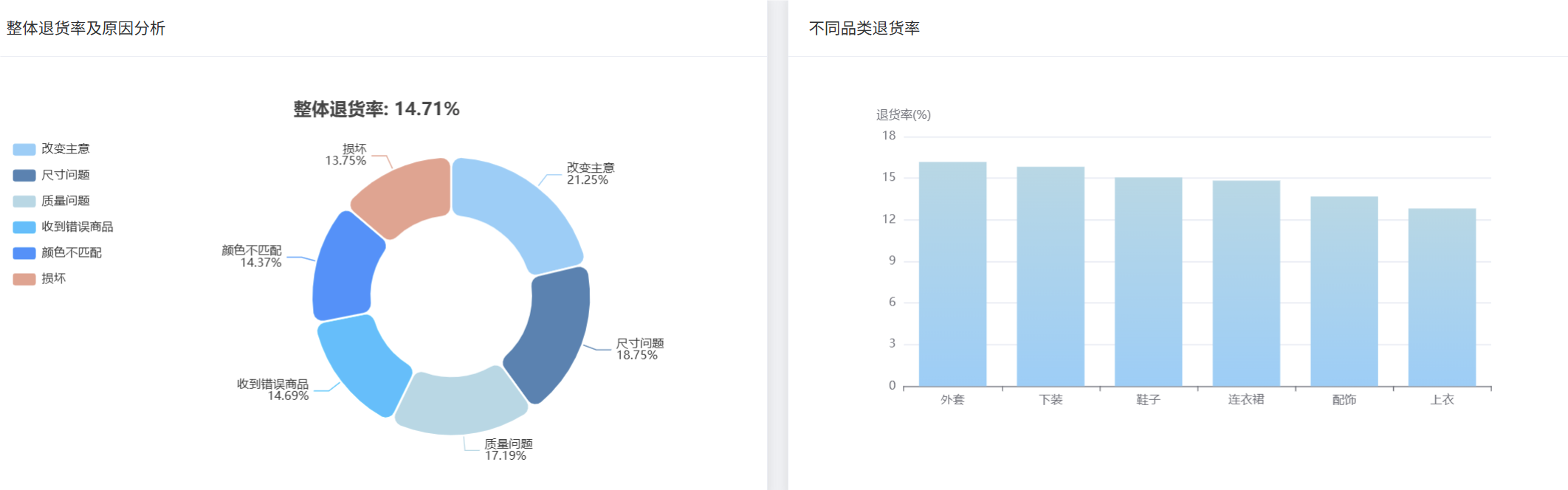
def return_behavior_analysis(request):
"""退货行为分析核心功能"""
hdfs_path = "hdfs://localhost:9000/fashion_data/fashion_boutique_dataset.csv"
df = spark.read.csv(hdfs_path, header=True, inferSchema=True)
df = df.fillna({"return_reason": "未退货"})
total_orders = df.count()
returned_orders = df.filter(col("is_returned") == True).count()
overall_return_rate = round((returned_orders / total_orders) * 100, 2)
return_reason_stats = df.filter(col("is_returned") == True).groupBy("return_reason").agg(
count("product_id").alias("return_count")
).orderBy(desc("return_count"))
return_reason_stats = return_reason_stats.withColumn("return_percentage",
round((col("return_count") / returned_orders) * 100, 2))
category_return_rate = df.groupBy("category").agg(
count("product_id").alias("total_count"),
sum(when(col("is_returned") == True, 1).otherwise(0)).alias("return_count")
)
category_return_rate = category_return_rate.withColumn("return_rate",
round((col("return_count") / col("total_count")) * 100, 2))
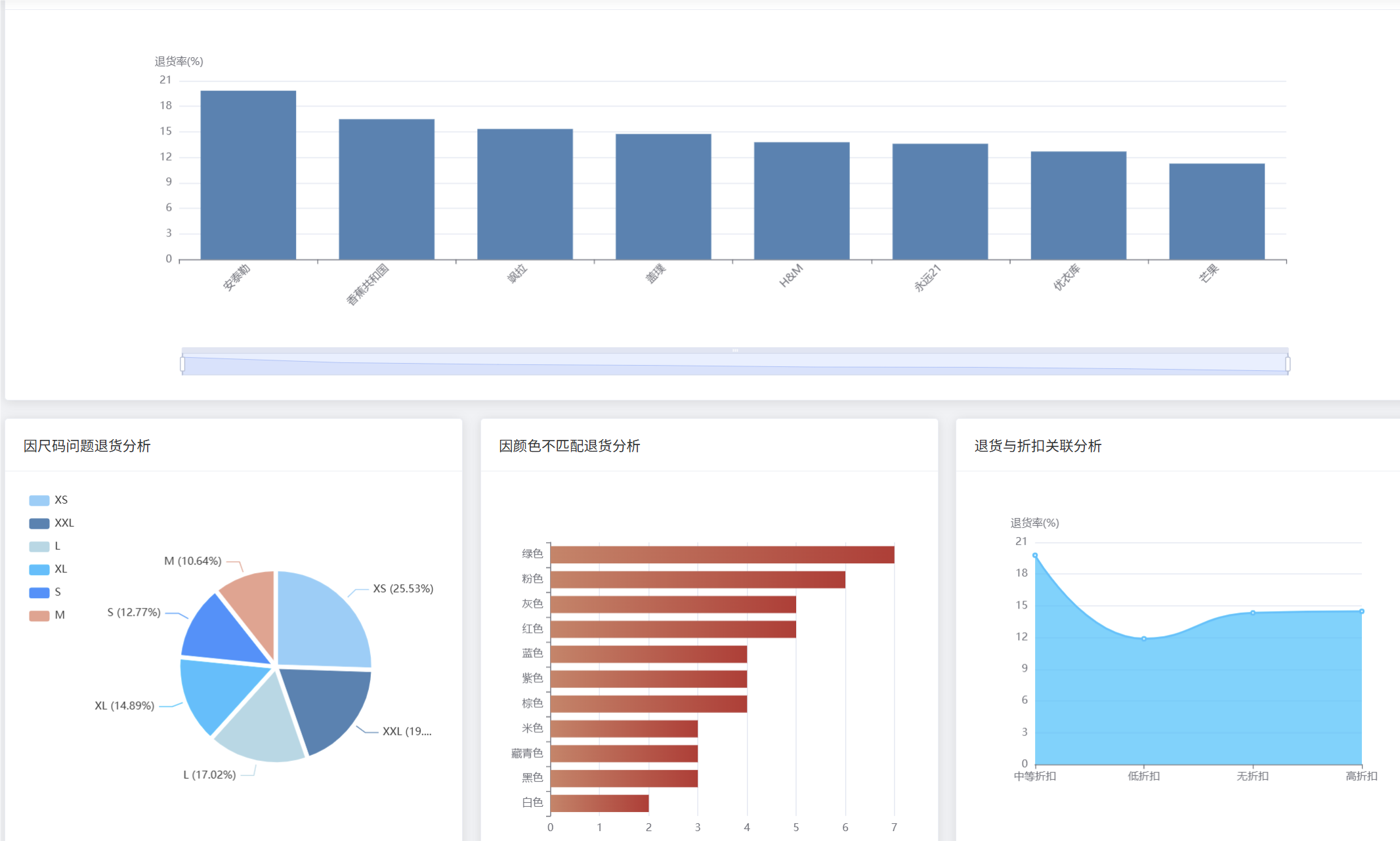
brand_return_rate = df.groupBy("brand").agg(
count("product_id").alias("total_count"),
sum(when(col("is_returned") == True, 1).otherwise(0)).alias("return_count")
)
brand_return_rate = brand_return_rate.withColumn("return_rate",
round((col("return_count") / col("total_count")) * 100, 2)).orderBy(desc("return_rate"))
size_return_analysis = df.filter((col("is_returned") == True) & (col("return_reason").contains("尺码"))).groupBy("size").agg(
count("product_id").alias("size_return_count")
).orderBy(desc("size_return_count"))
price_return_analysis = df.filter(col("is_returned") == True).select(
"current_price", "markdown_percentage", "return_reason"
)
price_ranges = price_return_analysis.withColumn("price_range",
when(col("current_price") < 50, "低价位(<50)")
.when((col("current_price") >= 50) & (col("current_price") < 100), "中价位(50-100)")
.when((col("current_price") >= 100) & (col("current_price") < 200), "中高价位(100-200)")
.otherwise("高价位(>=200)")
).groupBy("price_range").agg(count("current_price").alias("return_count"))
reason_data = return_reason_stats.collect()
category_data = category_return_rate.collect()
brand_data = brand_return_rate.collect()
size_data = size_return_analysis.collect()
price_data = price_ranges.collect()
reason_result = []
for row in reason_data:
reason_result.append({
"return_reason": row["return_reason"],
"return_count": row["return_count"],
"return_percentage": float(row["return_percentage"])
})
category_result = []
for row in category_data:
category_result.append({
"category": row["category"],
"total_count": row["total_count"],
"return_count": row["return_count"],
"return_rate": float(row["return_rate"])
})
brand_result = []
for row in brand_data:
brand_result.append({
"brand": row["brand"],
"return_rate": float(row["return_rate"]),
"return_count": row["return_count"]
})
final_result = {
"overall_return_rate": overall_return_rate,
"return_reasons": reason_result,
"category_return_rates": category_result,
"brand_return_rates": brand_result,
"total_orders": total_orders,
"returned_orders": returned_orders
}
pandas_df = pd.DataFrame(reason_result)
pandas_df.to_csv("media/analysis_results/return_behavior_analysis.csv", index=False)
return JsonResponse({"status": "success", "data": final_result, "message": "退货行为分析完成"})六、项目文档展示

七、项目总结
基于Spark的零售时尚精品店销售数据分析系统是一个将大数据技术与实际业务场景相结合的综合性项目。该系统运用Hadoop分布式存储和Spark内存计算引擎构建了稳定高效的大数据处理平台,通过Python Django框架提供后端服务支持,结合Vue前端技术和Echarts可视化组件实现了完整的数据分析解决方案。系统围绕零售时尚行业的核心业务需求,设计了销售趋势分析、客户满意度评估、退货行为研究等多个分析模块,能够从海量销售数据中提取有价值的商业洞察。项目在技术实现上体现了大数据技术栈的实际应用,从数据采集清洗到复杂分析计算,再到结果可视化展示,形成了完整的数据处理流水线。虽然作为毕业设计项目,系统规模相对有限,但其技术架构设计合理,功能模块划分清晰,代码实现规范,具备了一定的实用性和可扩展性。通过这个项目的开发,不仅能够加深对大数据技术的理解和掌握,也为今后从事相关领域的工作积累了宝贵的实践经验。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖