人工智能领域,斯坦福CS336课程(全称:CS 336 - Foundations of Large Language Models and Their Applications) 被许多学习者视为"大模型学习的必修课",不仅因为课程本身由一流学者讲授,更因为它以从零构建大语言模型为主线,让学习者真正看清楚大模型的底层运作机制。
然而,想要完全靠自学啃下这门课程,并不容易:
-
难度高:课程作业要求从零实现完整的模型组件,对基础和细节的掌握缺一不可;
-
资料分散:公开的讲义和参考代码碎片化严重,缺乏连贯的学习路径;
-
算力需求大:很多人被运行环境和训练成本卡住。
也正因如此,不少学习者虽然知道CS336的价值,但很难坚持学完。为了解决这些痛点,和鲸社区启动CS336课程作业复现计划:
-
把课程作业完整地实现并公开,降低学习门槛;
-
让学习者可以直接在社区中运行、修改、交流;
-
配备视频讲解,更加直观易懂。
和鲸社区将陆续复现课程五大作业 。今天,我们先来看由和鲸社区优秀创作者@天海一直在AI 复现的大作业一:从分词到完整Transformer的实现与实验。
作业一复现项目概览
在大作业一中,学习者需要完成从"文本输入"到"模型训练与生成"的完整链路。和鲸社区的复现涵盖了五大模块,每一步都能运行、可验证、可扩展:
1、分词(Tokenization)
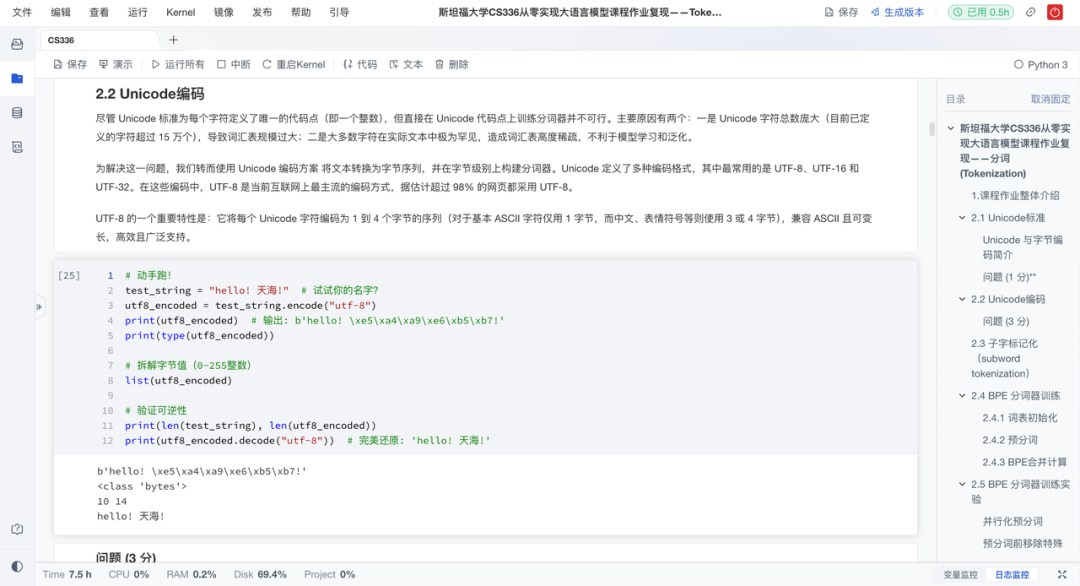
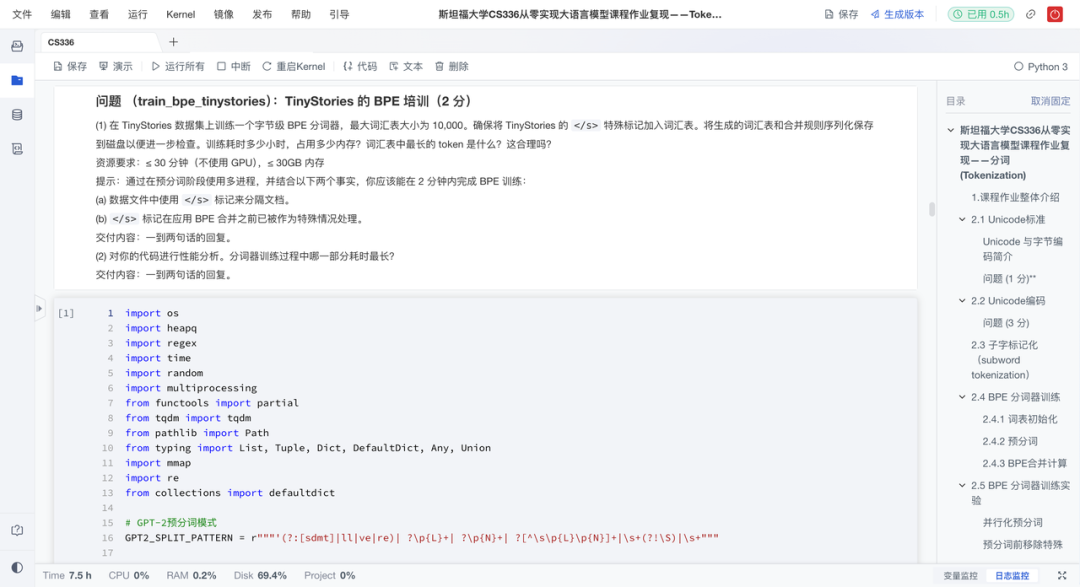
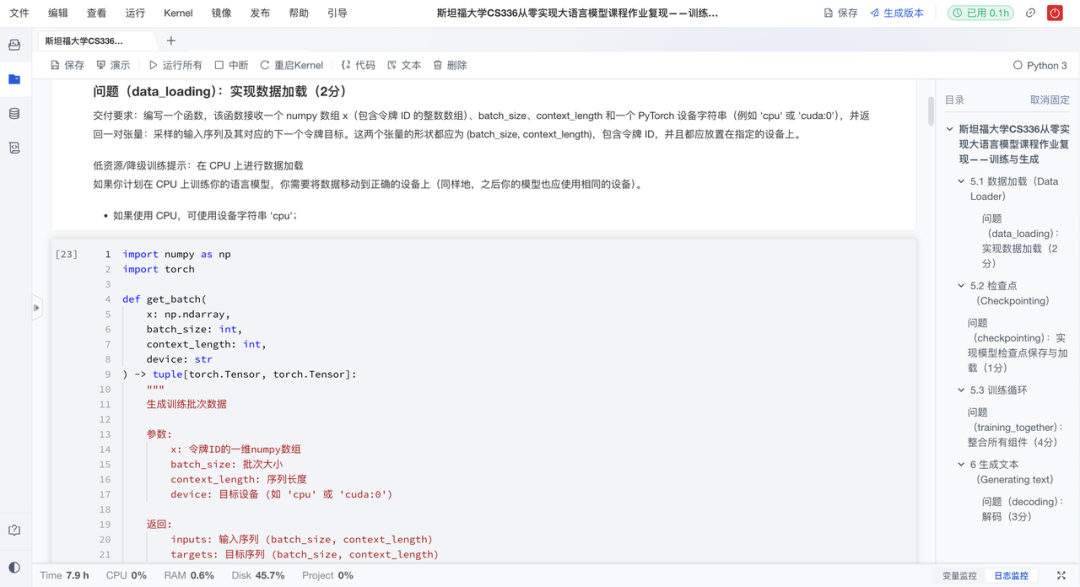
语言模型的第一步,是把自然语言切分成模型可处理的"Token"。作业复现项目从零实现字节级BPE分词器,并阐述了其相比字符级和词级分词的优势。具体来说有以下亮点:
-
BPE算法实现:重点实现当前主流的字节级BPE算法,理解其如何从256个基础字节构建出上万规模的词汇表;
-
跨语言支持:基于UTF-8字节单元构建,天然兼容多语言与表情符号,规避OOV问题;
-
**跨数据集验证:**在TinyStories和OpenWebText上训练与测试BPE分词器,分析其泛化能力与压缩效率;
-
可逆编解:支持编码与解码全流程,便于调试与下游任务集成。
该项目不仅夯实数据预处理基础,更通过实验揭示"分词方式如何影响模型上限",是理解语言模型起点的关键一环。
💻分词作业复现项目:https://www.heywhale.com/u/a63533
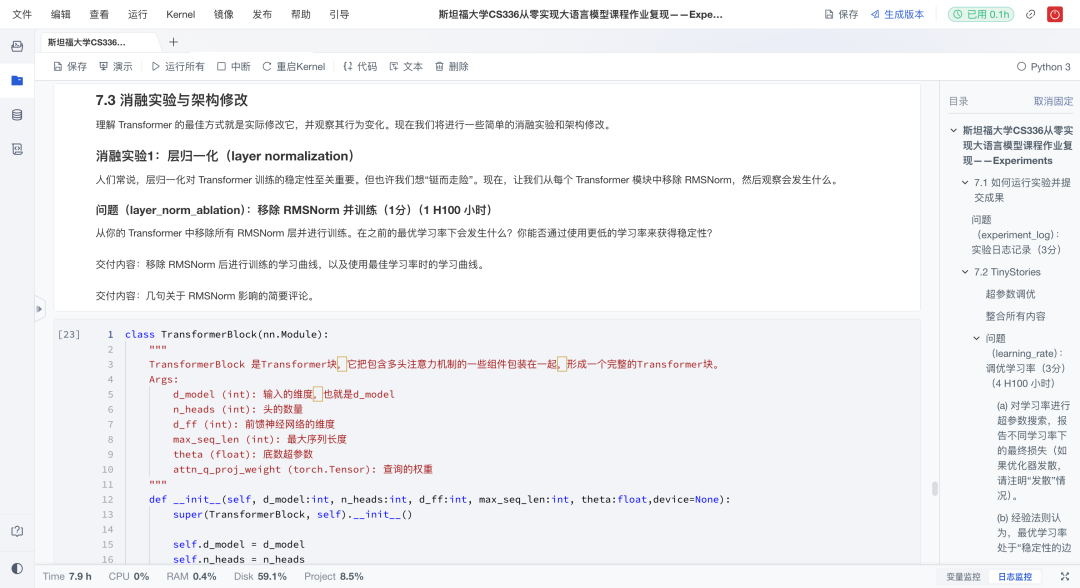
2、Transformer基础实现
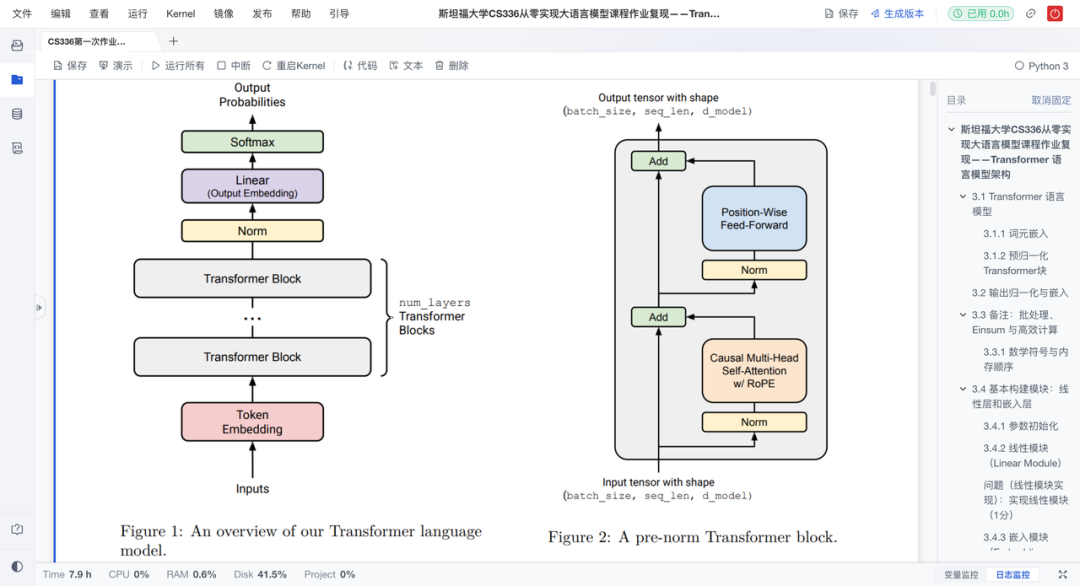
这是作业的重头戏。复现项目从零搭建了Transformer的核心模块,实现"手动拼装"大模型核心引擎。具体来说有以下亮点:
-
自注意力:从头实现因果多头自注意力机制,包括QKV计算、掩码处理与输出投影;
-
位置编码:实现可学习的位置嵌入层,为模型注入序列顺序信息;
-
前馈结构:实现RMSNorm+SwiGLU前馈网络,增强表达力与稳定性;
-
模块测试:采用模块化设计,每层可独立验证,降低学习门槛。
通过亲手实现每一层,学习者得以穿透框架黑箱,深入理解Transformer的运作机制。
💻Transformer作业复现项目:https://www.heywhale.com/u/10f21e
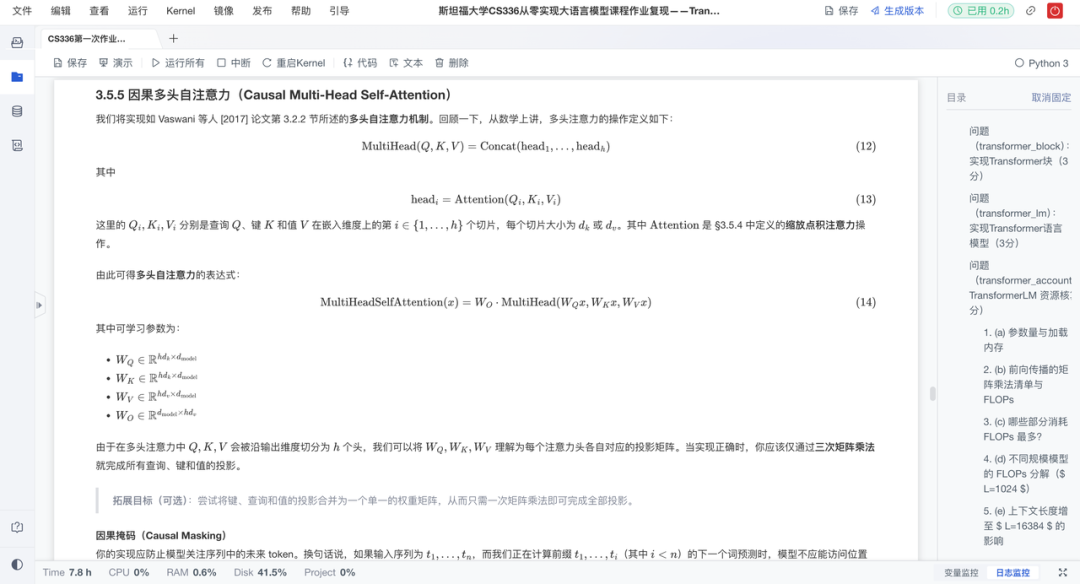
3、训练Transformer语言模型(Transformer LM)
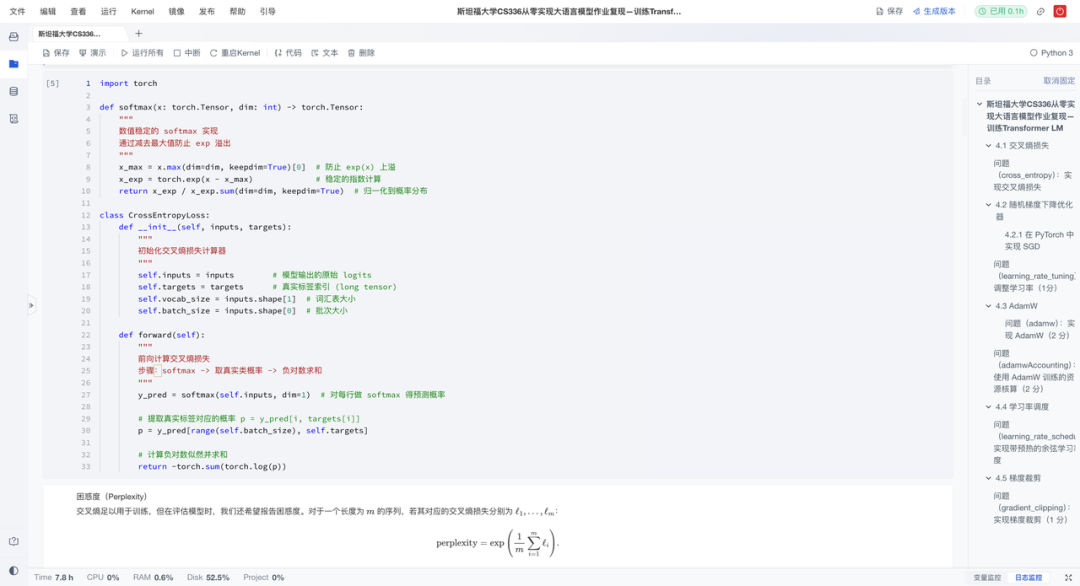
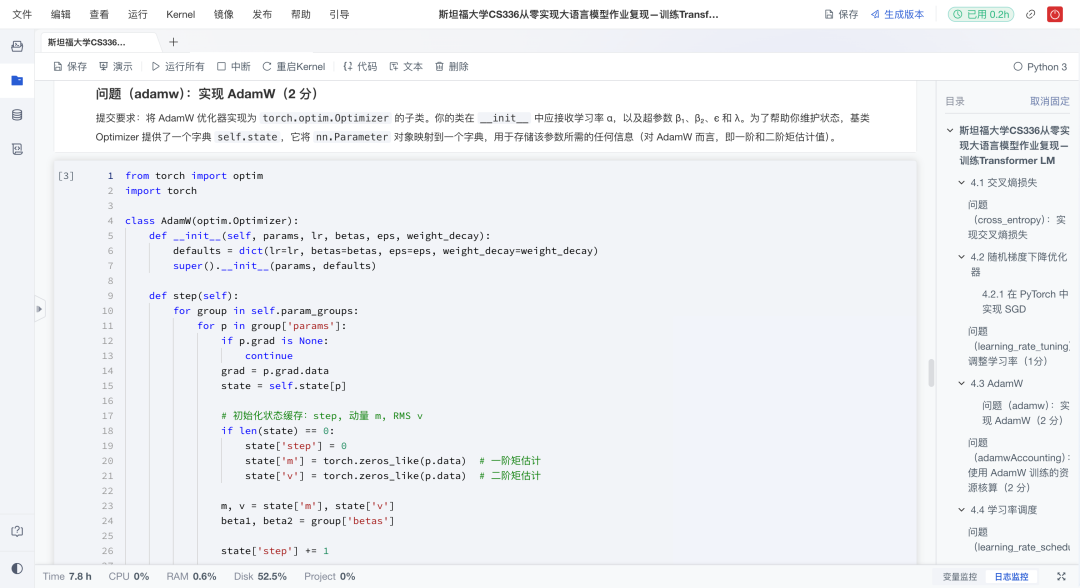
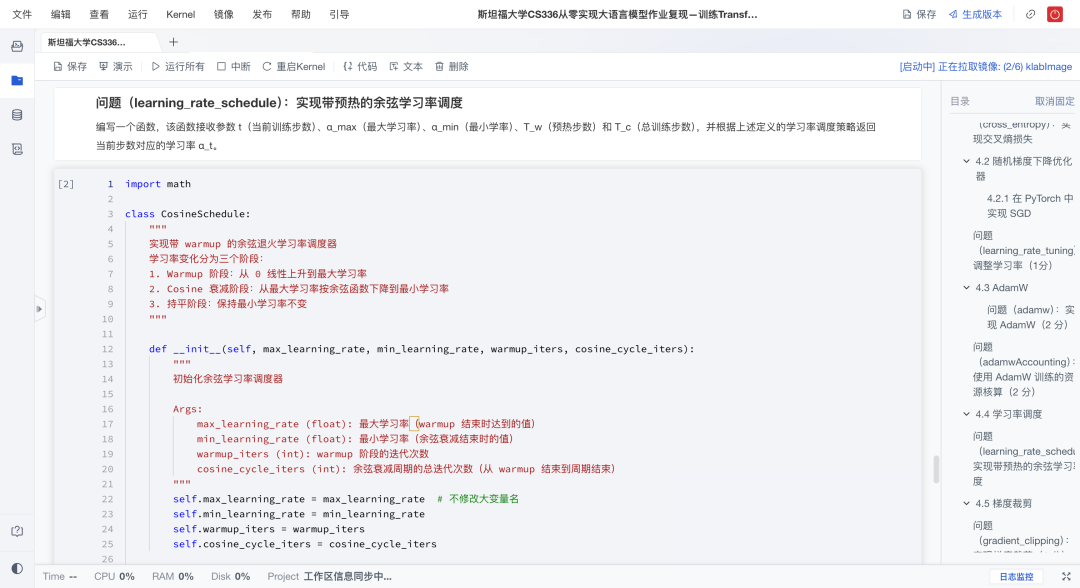
这是承上启下的关键环节。项目构建完整的训练基础设施,涵盖损失函数、优化器与训练循环,打造可运行的端到端训练系统。具体来说有以下亮点:
-
损失实现:手动编写数值稳定的交叉熵损失,处理softmax溢出问题;
-
优化器:从头实现AdamW,包含动量、自适应学习率与权重衰减;
-
梯度控制:引入梯度裁剪,防止深层网络训练崩溃;
-
学习率:采用warmup + 余弦衰减策略,提升收敛效率与稳定性;
-
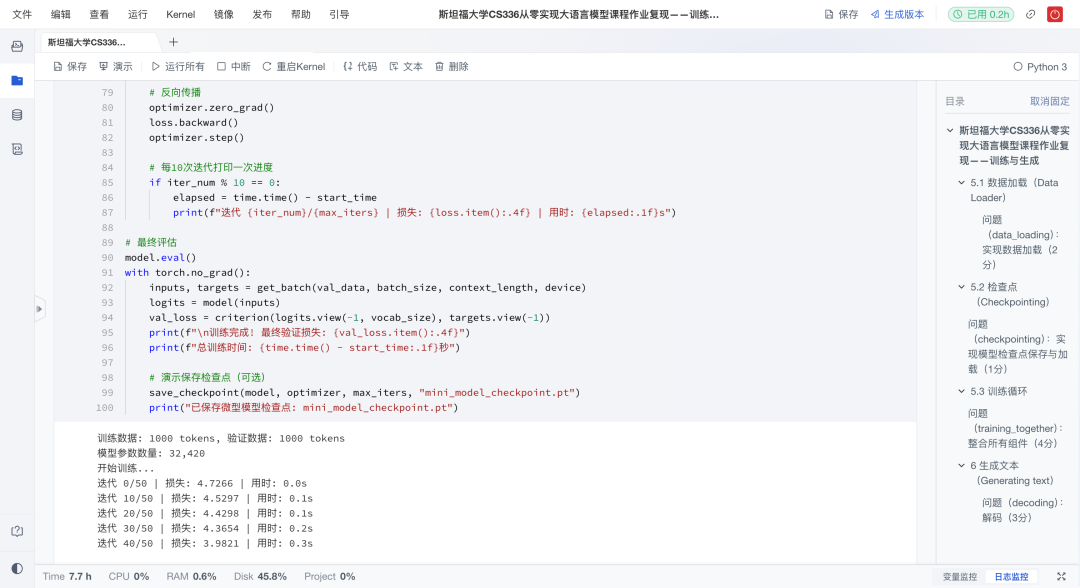
训练监控:建立实验日志系统,记录并追踪loss随训练步数和时间的变化,用于分析模型收敛情况。
这一部分可以让学习者体会到"代码能学会语言",并通过可视化验证训练是否成功,为后续的生成与实验打下基础。
💻Transformer LM作业复现项目:https://www.heywhale.com/u/ae8d62
4、训练与生成(Training & Generation)
在有了模型架构后,复现项目实现了可运行的训练循环,并让模型真正"开口说话"。具体来说有以下亮点:
-
端到端:整合数据加载、训练循环与检查点保存,支持断点续训;
-
文本生成:实现基于采样的自回归生成,输入提示即可续写文本;
-
效果演进:对比不同训练阶段的生成结果,形成"loss↓→ 文本↑"的直观反馈。
更重要的是,这套训练与生成代码可以在社区环境直接运行,即便算力有限,也能快速看到模型收敛的过程。
💻Training&Generation作业复现项目:https://www.heywhale.com/u/e73b28
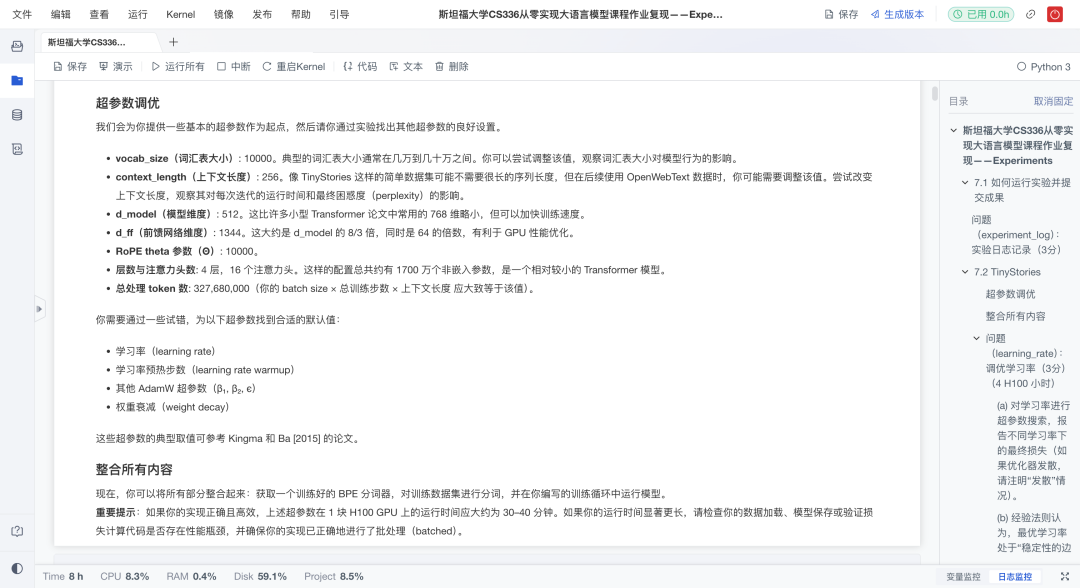
5、实验与验证(Experiments)
在完成模型构建与训练后,复现进一步展开了系统实验,探索不同超参数设置对模型性能的影响。具体来说有以下亮点:
-
超参探索 :系统性地进行实验,对比不同学习率 和batch size对模型训练稳定性、收敛速度和最终性能的影响;
-
定量评估:使用困惑度(Perplexity)等指标客观衡量模型质量;
-
分词实验:跨数据集测试BPE行为,分析长token成因与泛化能力;
-
记录复盘:保留参数、曲线与结果,支持迭代优化与对比分析。
这一部分不仅教会"怎么做",更强调"怎么验证",为后续独立研究与工程调优打下坚实基础。
💻Experiments作业复现项目:https://www.heywhale.com/u/f1ef9f