1 前言
最近在搞关于PaddleOCR的识别项目,中间踩了很多个大大小小的坑,找了很多回答才把训练流程跑通。本文档更新于2025年9月6日,这很重要! 本文档内容均为笔者本人实践后的结果,未涉及的情况请大家一起讨论,共同解决。
2 关于PaddleOCR框架
2.1 PaddleOCR简单介绍
PaddleOCR 是基于百度飞桨(PaddlePaddle)深度学习框架的开源文字识别工具套件。它提供了从数据准备 → 文本检测 → 文本识别 → 后处理的完整OCR解决方案。PaddleOCR 支持中英文以及 80+ 种语言,还可以处理竖排、弯曲、手写等复杂文本场景,应用广泛,例如票据识别、文档数字化、车牌识别、工业场景等。
bash
PaddlePaddle/
- PaddleOCR # 图像识别
- PaddleNLP # 大语言模型套件
- PaddleDetection # 目标检测端到端开发套件
- PaddleServing # 部署服务
- PaddleHub # 预训练模型
- PaddleX # 低代码开发工具2.1.2 det(文字检测)
文本检测:利用检测算法检测到图像中的文本行。
2.1.3 rec(文字识别)
检测到的文本行用识别算法去识别到具体文字。
2.1.4 关键信息抽取(kie)
关键信息抽取存在非常多的实际应用场景,如表单识别、车票信息抽取、身份证信息抽取等。然而,使用人力从这些文档图像中提取或者收集关键信息耗时费力,怎样自动化融合图像中的视觉、布局、文字等特征并完成关键信息抽取是一个价值与挑战并存的问题。
文档图像中的kie一般包含2个子任务:
- ser:语义实体识别,对每一个检测到的文本进行分类。
- re:关系抽取,对每一个检测到的文本进行分类,如将其分为问题(key)和答案(value)。然后对每一个问题找到对应的答案,相当于完成key-value的匹配过程。
完成关键信息抽取,至少需要2个步骤:首先使用OCR模型,完成文字位置与内容的提取(det+rec),然后使用kie模型,根据图像、文字位置以及文字内容,提取出其中的关键信息。常见的训练方法有两种:(1)直接使用ser来分类,即det+rec+ser;(2)联合ser+re找键值对,即det+rec+ser+re。
2.1.5 指标评估
PaddleOCR计算三个OCR检测相关的指标,分别是:precision(准确率)、eecall(召回率)、hmean(F1Score)。一般场景都是关注hmean,越接近1说明模型的预测效果越好,但需注意过拟合。
2.2 架构
2.2.1 训练流程
如果需要图片的全量数据,直接paddocr.ocr即可,但实际场景往往只需要抓取部分重要信息且需提高识别准确率,需先将关键信息打好标签(PPOCRLabel),再微调模型。如果预训练的预测效果很好,就无需微调。推理模型是可以直接被调用进行识别和检测。推理模型体积更小,在预测部署、加速推理上性能优越、灵活方便,但不能用于恢复训练及二次训练。 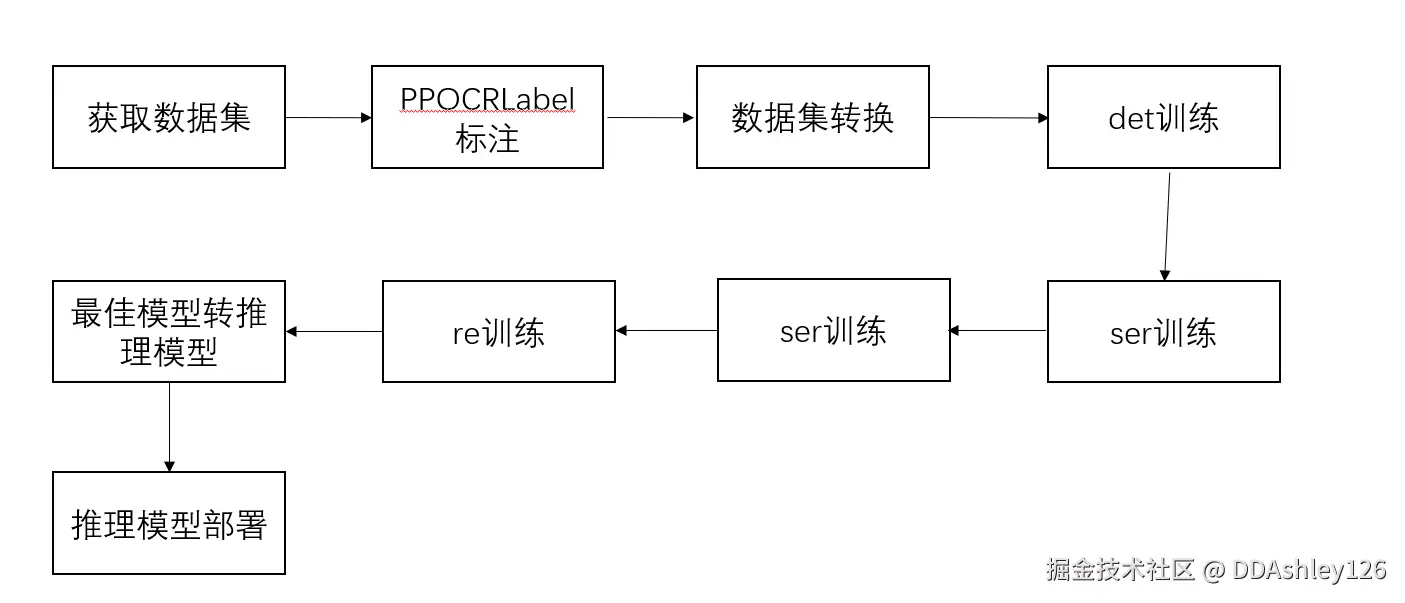
2.2.2 代码架构
为方便管理,预训练模型统一放到PaddleOCR/Preliminary_training文件夹下,推理模型统一放到PaddleOCR/inference文件夹下,数据集放到PaddleOCR/train_data文件夹下,训练后的模型放到PaddleOCR/output文件夹。
bash
OCRProject/
- inference/ # 存放推理模型
- output/ # 存放输出结果
- PaddleOCR/ # 使用内部的PaddleOCR代码
- train_data/ # 训练数据3 环境准备
本项目要求python3.7~3.9版本,且依赖库需严格遵循给定的版本(没有明确版本的除外)。环境是paddleocr训练过程中最麻烦的事情,依赖库版本稍微有一点对不上就到处报错。后来发现,自2024年初以后,paddleocr代码的提交都没有经过验证,才会出现很多报错和库兼容的问题。如果能找回24年以前版本的paddleocr就最好啦,不能的就一定要看本节内容。
3.1 环境搭建
3.1.1 添加环境变量
安装python,并添加路径至系统变量,只有添加了环境变量才能在cmd或powershell启动启动图片标注应用。
3.2 虚拟环境
① 创建虚拟环境并激活,需要的请找相关文章 ② 在项目根目录,拉取PaddleOCR代码
git
git clone https://gitee.com/paddlepaddle/PaddleOCR.git③ 进入PaddleOCR文件夹,释放分支
git
cd PaddleOCR
git checkout release/2.7④ 安装相关依赖库
python
pip install -r requirements.txt⑤ 代码修改
-
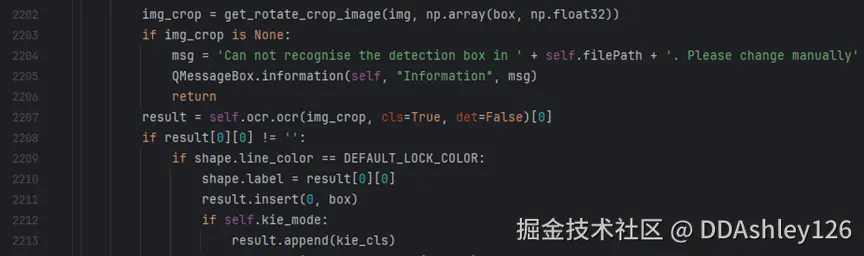
打开PaddleOCR/PPOCRLabel/PPOCRLabel.py文件,修改2207行代码
改动前:
 改动后:
改动后: 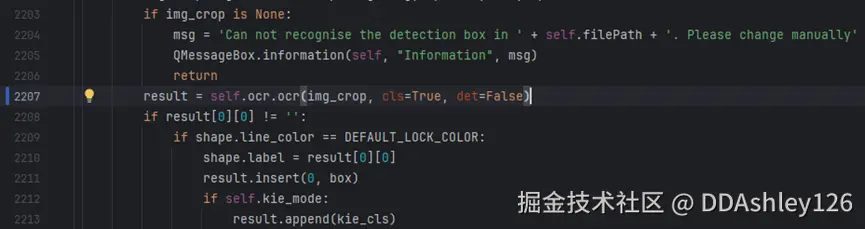
-
打开PaddleOCR/PPOCRLabel/gen_ocr_train_val_test.py,修改48、52和56行的代码
改动前:
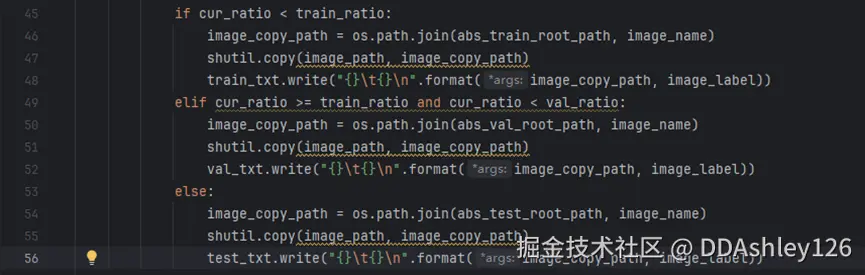 改动后:
改动后: 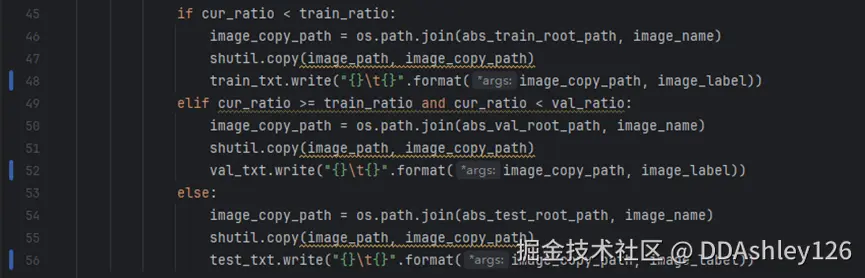
-
打开PaddleOCR/toolsinfer_kie_token_ser_re.py,修改84和101行代码:
改动前:

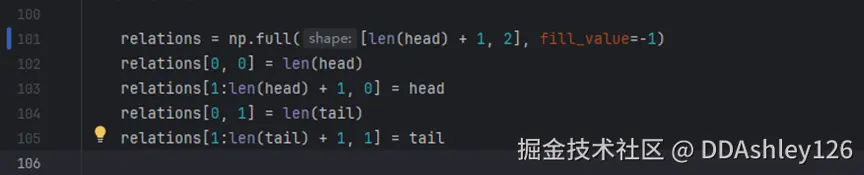 改动后:
改动后: 

-
文件PaddleOCR/ppocr/data/imaug/label_ops.py,修改第1205行
进行ser预测时,改动前报错:
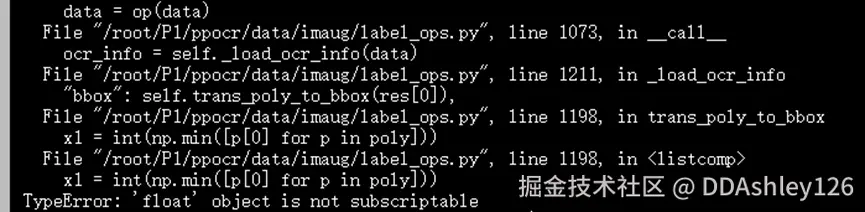 改动前:
改动前:  改动后:
改动后: 
-
若使用gpu运行,则文件PaddleOCR/tools/program.py需要修改680行
改动前:
 改动后:
改动后: 
⑥ gpu环境其他依赖
gpu仅需安装paddlepaddle-gpu,cuda版本需适配,否则会报错(以cuda=12.6为例)
bash
pip install --pre paddlepaddle-gpu==2.5.2 -i https://www.paddlepaddle.org.cn/packages/nightly/cu126/
pip install protobuf>=3.20.2
pip install paddlepaddle-gpu==2.5.2
Pip install paddlenlp==2.5.2
pip install numpy==1.24.0⑦ cpu环境其他依赖
python
pip install paddlepaddle==2.6.0
pip install setuptools_scm==7.0.4
pip install xlrd
pip install paddlenlp==2.6.0
pip install paddleocr==2.6.1.3
pip install numpy==1.24.04 数据集制作与转换
PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
4.1 数据集制作
4.1.1 PPOCRLabel启动
①进入PaddleOCR/PPOCRLabel目录
bash
cd PaddleOCR/PPOCRLabel①在Terminal启动指令
bash
python PPOCRLabel.py --lang ch --kie True这里可能会出现报错,根据终端显示的报错修改就行。
4.1.2 打标签
① 左上角打开【文件】-【打开目录】(目录里面应当存放本次训练所需图片)
② 关键区域标记
标注自己想要的区域,区域之间的间距要尽可能的大,区域之间尽量不要重叠。 标注过程中,对于无关于kie关键信息的文本内容,均需要将其标注为other类别,相当于背景信息。标注过程中,需要以文本行为单位进行标注。数据量方面,一般来说,对于比较固定的场景,50张左右的训练图片即可达到可以接受的效果,可以使用PPOCRLabel完成KIE的标注过程。
③ 识别区域结果
标注完成后,点击右方的重新识别或使用快捷键ctrl+R进行一次文字识别。当一张图的关键文字区域都标注完成后,右下角的确认即可继续标注下一张图片。
④ 导出结果
所有图片标注完成后,或者标注过程需要中断,导出相关文件。如果无需进行文字识别模型微调的就不用导出识别结果,其余的都要把下图红框内的选项都点一遍。 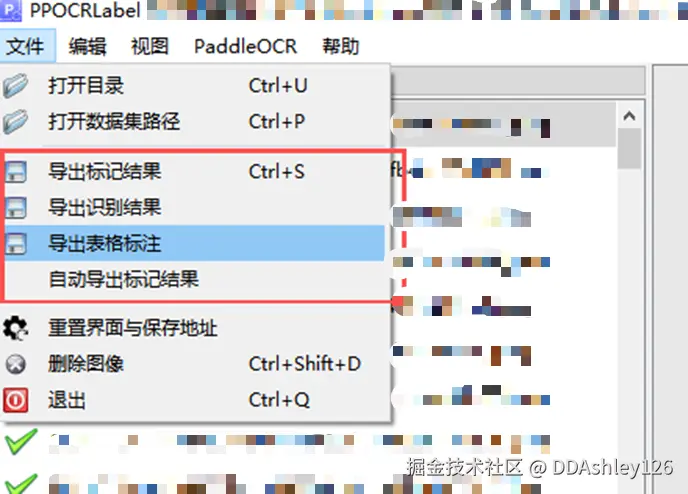
⑤ 完成后文件夹多出四个文件fileState.txt,Label.txt,rec_gt.txt,crop_img。其中crop_img中的图片用来训练文字识别模型,fileState记录图片的标注状态,Label为文字检测模型的训练标签,rec_gt为文字识别模型的训练标签。
4.2 数据集转换
4.2.1 det和rec的数据集
在PPOCRLabel目录下,执行以下指令划分数据集,将标注数据划分为训练集、验证集和测试集。注意数据集路径最好不要包含中文。
bash
python gen_ocr_train_val_test.py --datasetRootPath /这里写刚刚标注好的数据集路径/脚本文件默认训练集、验证集和测试集的划分比例为6:2:2,划分后的数据集默认路径为上一级目录的train_data文件夹下,并生成det和rec文件夹,例如:
程序自动分好训练集测试集和验证集的数据,至此文字检测(det)和文字识别(rec)的数据集就做好了。det的文件结构如下(rec的结构也是一样):
bash
det/
- test/ # 测试集图片
- train/ # 训练集图片
- val/ # 验证集图片
- test.txt # 测试集图片信息
- train.txt # 训练集图片信息
- val.txt # 验证集图片信息4.2.2 ser的数据集
ser训练的数据集可以直接使用分好的det数据集,但是部分文件需要修改,修改后方可微调ser模型。 打开4.2.1生成的det数据集的test.txt、train.txt、val.txt文件,把"key_cls"字段名替换成"label",此时ser数据集制作完成。
4.2.4 re的数据集
re的数据集制作比较麻烦,label名称不仅限定为键值对,形式,还要添加label与label之间的连接关系,而且使用的也不多,这里就不详细介绍了,只给出re数据集的图片信息文件的数据结构:
bash
[
{
"transcription": "你今天吃了吗",
"points": [[11, 59], [14, 59], [14, 97], [11, 97]],
"id": 1,
"linking": [[1, 2]],
"label": "question"
},
{
"transcription": "吃了",
"points": [[25, 63], [36, 63], [36, 101], [25, 101]],
"id": 2,
"linking": [[1, 2]],
"label": "answer"
}
]- question的id要比answer的id大
- linking的格式要question的id在前,answer在后,例如\[question_id, answer_id]
5 模型训练
5.1 预训练模型获取
在官方文档上下载预训练模型,下载之后在PaddleOCR根目录下建立Preliminary_training文件夹,将下载的模型解压至该文件夹。 det和rec预训练模型下载地址:预训练模型, ser和re预训练模型下载地址:预训练模型
5.2 微调训练
5.2.1 det模型训练
PaddleOCR中提供的模型大多数为通用模型,在进行文本检测的过程中,相邻文本行的检测一般是根据位置的远近进行区分,使用通用中英文检测模型进行文本检测时,容易将临近的不同字段检测到一起,从而增加后续KIE任务的难度。
① 选取你想要的模型,找到对应的yml文件 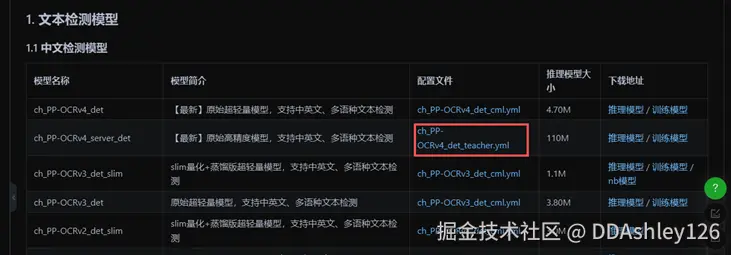 ② 下载对应的预训练模型并解压(不微调就下载推理模型)
② 下载对应的预训练模型并解压(不微调就下载推理模型) 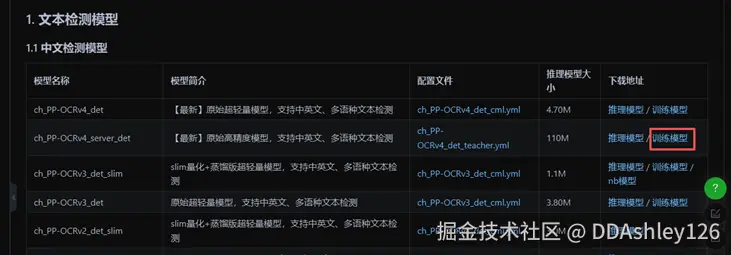
③ 在PaddleOCR/configs里面找到需要修改的yml文件 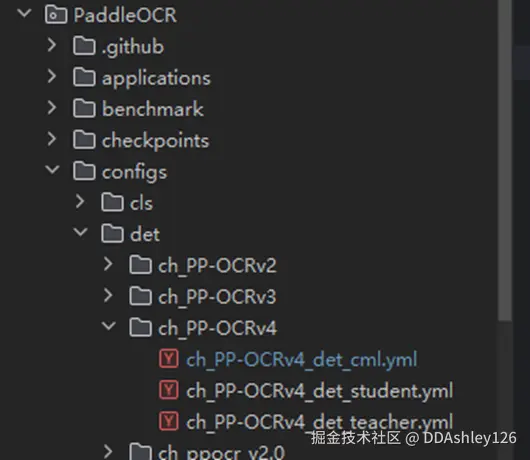
④ 修改参数 需要修改的字段(视情况设置)
| 参数 | 说明 |
|---|---|
| Global.use_gpu | 是否使用gpu训练,需要为True |
| Global.epoch_num | 训练轮数,视情况修改,一般来说det和rec要500轮,ser要50轮 |
| Global.save_model_dir | 模型保存路径,修改为你想输出的路径,例如./output/det |
| Global.pretrained_model | 预训练模型,如果想对自己的模型进行二次训练,则修改为本地已经训练好的best_accuracy.pdparams的地址。注意路径为best_accuracy.pdparams文件的路径,但不用加pdparams后缀,如"./Preliminary_training/ch_PP-OCRv4_det_teacher/best_accuracy" |
| Global.save_inference_dir | 推理模型输出目录 |
| Global.save_res_path | 预测结果的输出路径 |
| Global.infer_img | 预测图像路径或文件夹 |
| Train.dataset.data_dir | 训练集路径,一般来说是train文件夹地址 |
| Train.dataset.label_file_list | 数据标签路径,一般来说是train.txt地址 |
| Train.dataset.transforms.batch_size_per_card | 训练批量大小,使用gpu时可适当增大,但需保证值为2的n次方。增大意味着模型的泛化能力可能会下降 |
| Eval.dataset.data_dir | 测试集路径,一般来说是val文件夹地址 |
| Eval.dataset.label_file_list | 测试集数据标签路径,一般来说是val.txt地址 |
| Global.checkpoints | 存档点配置为训练出来最新模型地址(latest模型地址)。这个参数在未训练前不能配置, 会报错找不到存档点 |
④ 开始训练 返回值PaddleOCR根目录下,输入指令开始训练
python
python tools/train.py -c configs/det/"上面yml文件路径" -o ...(临时修改的配置项,如Global.use_gpu=False)"-c"指的是训练的配置文件;"-o"代表替换配置文件的值,临时替换某些配置项。训练完成后Global.save_model_dir路径下会出现以下文件:
bash
output/det/
- best_accuracy/
- best_model/
- config.yml
- iter_epoch_xxx.*
- latest.*
- train.log| 文件 | 说明 |
|---|---|
| best_accuracy | 训练出来的最佳模型 |
| iter_epoch_xxx | 训练每经过xx轮的模型文件 |
| latest.* | 最新模型,二次训练时的checkpoints应指向这个 |
| train.log | 日志文件 |
| config.yml | 本次训练所使用的配置 |
⑤ 模型评估
bash
python tools/eval.py -c configs/det/"上面yml文件路径" -o Global.checkpoints=./output/det/best_accuracy(训练后的最佳模型地址)注意此时的checkpoints必须修改,不修改的话评估模型指向的还是原来的预训练模型。
⑥ 转换成推理模型
bash
python tools/export_model.py -c configs/det/"上面修改的yml文件"导出成功后,Global.save_inference_dir目录下会生成3个文件,根据需要选择模型,优先使用Student模型(平衡精度和速度),精度更高的情况使用Teacher模型,速度要求高使用Student2模型。
5.2.2 rec模型训练
rec的微调训练与det的一样。
5.2.3 ser训练
语义实体识别指的是给定一段文本行,确定其类别(如姓名、住址等类别),采用vi_layoutxlm算法进行微调。
①选取模型并下载(官网只有一个,不用选)
②修改配置文件ser_vi_layoutxlm_xfund_zh.yml,配置项大体与det的相同,不同的配置视情况修改
| 参数 | 说明 |
|---|---|
| Global.kie_rec_model_dir | rec模型的路径,如果使用自己训练的模型则要修改,路径为推理模型的路径 |
| Global.kie_det_model_dir | det模型的路径,如果使用自己训练的模型则要修改,路径为推理模型的路径 |
| Architecture.Backbone.num_classes | 类别数,假设字典中包含n个字段(包含other)时,则类别数为2n-1; 假设字典中包含n个字段(不含other)时,则类别数为2n+1 |
| PostProcess.class_path | 存放类别的文件路径,一般为txt文件,类别名称一行写一个 |
③ 运行指令开始训练开始训练
bash
python tools/train.py -c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml④评估已训练模型的准确性(注意与det的差别)
bash
python tools/train.py -c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=/训练后的最佳模型地址/⑤转换为推理模型
bash
python tools/export_model.py -c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=/训练后的最佳模型地址/导出成功后的推理模型文件与det的类似。
⑥进行推理测试
bash
python ppstructure/kie/predict_kie_token_ser.py \
--kie_algorithm=LayoutXLM \
--ser_model_dir=/转换好的ser推理模型地址/ \
--image_dir=/进行预测的图像路径/ \
--ser_dict_path=/类别文件路径/ser可视化结果保存到Global.save_res_path路径。
6 常见问题
① 运行kie_label_convert.py脚本时,出现cv2无法解析imread函数情况  解决方法:在虚拟环境找到cv2,把cv2.pyb文件复制到site-package路径下即可。之后返回代码就可以看见cv2能够解析imread函数了。
解决方法:在虚拟环境找到cv2,把cv2.pyb文件复制到site-package路径下即可。之后返回代码就可以看见cv2能够解析imread函数了。
② ser+re任务预测时,出现 InvalidArgumentError: The dims of Input(X) should be greater than 0
原因:图片里无法检测识别出文字。
解决方案:跳过
③ re模型微调,出现AttributeError: 'bool' object has no attribute 'sum'
原因:版本不兼容,paddlenlp<2.6
解决方案:paddlenlp需降至2.5.2,paddlepaddle降至2.5.2
④ re模型训练,出现 File "D:\path\pythonProject\ystOCR\PaddleOCR\tools\program.py", line 584, in eval metric'fps' = total_frame / total_time ZeroDivisionError: float division by zero
原因:验证集数量过少
⑤ 无法加载model_config.json 
在ser任务转换推理模型时,出现无法加载json文件的报错,排查后发现ser任务的config文件自动保存为config.json而不是model_config.json,而paddleOCR里默认配置文件为model_config.json。
解决方法:将config.json重命名为model_config.json(这个貌似在paddle3.0以上版本才会出现)
⑥ ser+re预测推理时出现The dims of Input(X) should be greater than 0 
原因1:数据集中的question的id属性值小于answer的id属性值,如{'label': 'question', 'id': 2, 'linking': \[\[2, 1]}, {'label': 'answer', 'id': 1, 'linking': \[2, 1]}]
原因2:图片问题,模型无法从图中识别出文字,特别是方向上下倒转的图片 解决方法:修改数据集的label的顺序,将question排在answer前面。最后数据集长这样:{id:1, linking:\[\[1, 2]},{id:2, linking:\[1, 2]}],而不能{id:2, linking:\[\[1, 2]}, {id:1, linking:\[1, 2]}]
⑦ 推理模型没有pdimodel,但是有json
原因:paddlepaddle版本为3.0以上,要降级到2.6以下版本
⑧ PPOCRLabel无法自动标注或识别闪退,出现"tuple"object has no attribute "list"(3、8冲突,很离谱对吧) 解决方案:paddlenlp版本过低,换成2.6.1.3即可
⑨ infer和predict函数的区别是什么 一个是转推理模型前的预测(infer),一个是转成推理模型后的预测(predict)