✨作者主页 :IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍
基于大数据的贵州茅台股票数据分析系统是一个集成了Hadoop、Spark等大数据技术栈的综合性金融数据分析平台。系统采用Python/Java语言开发,后端基于Django/Spring Boot框架构建,前端运用Vue、ElementUI、Echarts等现代化技术实现数据可视化。系统核心功能涵盖价格趋势分析、成交量与流动性分析、波动性与风险评估以及技术指标有效性验证四大模块。通过Spark SQL和Pandas进行大数据处理,系统能够对茅台股票的历史交易数据进行深度挖掘,包括日均价格走势分析、价格区间分布统计、成交量变化趋势跟踪、价量关系相关性研究、日内波动率计算、MACD和RSI等技术指标分析。系统支持实时数据处理和批量数据分析,为投资者提供全方位的股票分析工具和决策支持,助力量化投资策略制定和风险控制管理。
选题背景
随着资本市场的不断发展和投资者对量化分析需求的日益增长,传统的股票分析方法已难以满足现代投资决策的复杂性要求。贵州茅台作为A股市场的标杆性企业,其股价表现不仅反映了白酒行业的发展趋势,更是整个消费板块乃至市场情绪的重要风向标。然而,茅台股票数据的复杂性和海量特征使得传统分析工具难以进行深度挖掘和精准预测。大数据技术的快速发展为金融数据分析带来了新的机遇,Hadoop和Spark等分布式计算框架能够高效处理大规模时间序列数据,而机器学习算法的应用则为识别隐藏的市场规律提供了可能。在这种技术背景下,构建一个集成多维度分析功能的股票数据分析系统,不仅能够满足投资者对深度数据分析的需求,也为大数据技术在金融领域的应用探索提供了实践平台。
选题意义
本系统的构建具有多层面的实际价值和理论意义。从投资者角度来看,系统提供的多维度数据分析功能能够帮助投资者更科学地评估投资风险,优化投资决策过程,特别是对于茅台这类高价值股票的分析,系统的技术指标验证和波动性分析功能可以为投资者提供更为客观的参考依据。对于金融机构而言,系统的量化分析能力能够辅助其建立更为精准的风险控制模型和投资策略。从技术发展角度,本系统展示了大数据技术在金融数据处理方面的实际应用能力,为相关技术在金融行业的进一步推广提供了参考案例。教育层面上,系统整合了数据科学、金融分析和软件工程等多个学科知识,为相关专业学生提供了一个综合性的学习实践平台。虽然作为毕业设计项目,系统在功能完整性和数据处理规模上存在一定局限性,但其所体现的技术架构和分析方法论仍具有一定的参考价值,为后续更大规模系统开发奠定了基础。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
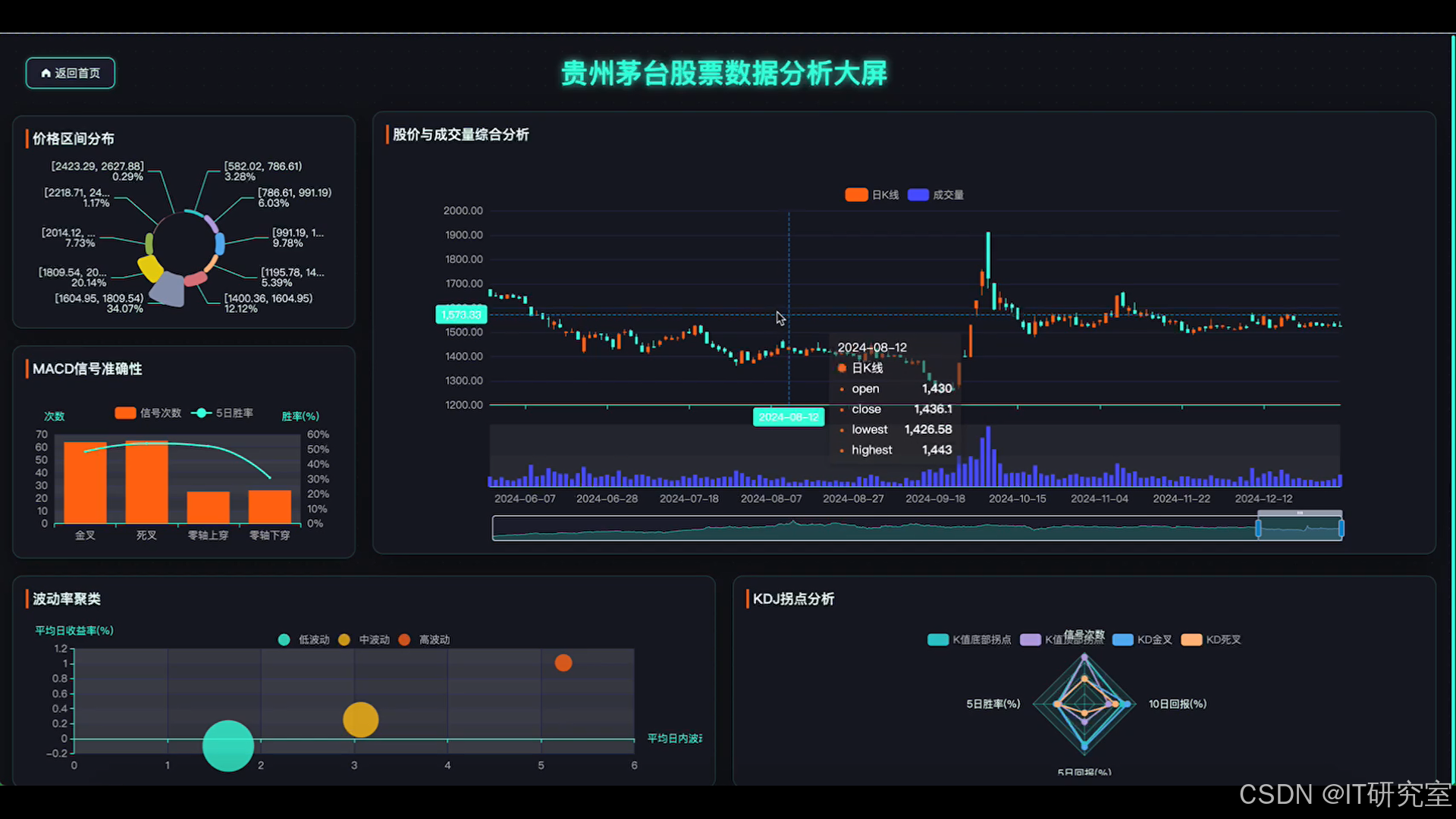
三、系统界面展示
- 基于大数据的贵州茅台股票数据分析系统界面展示:
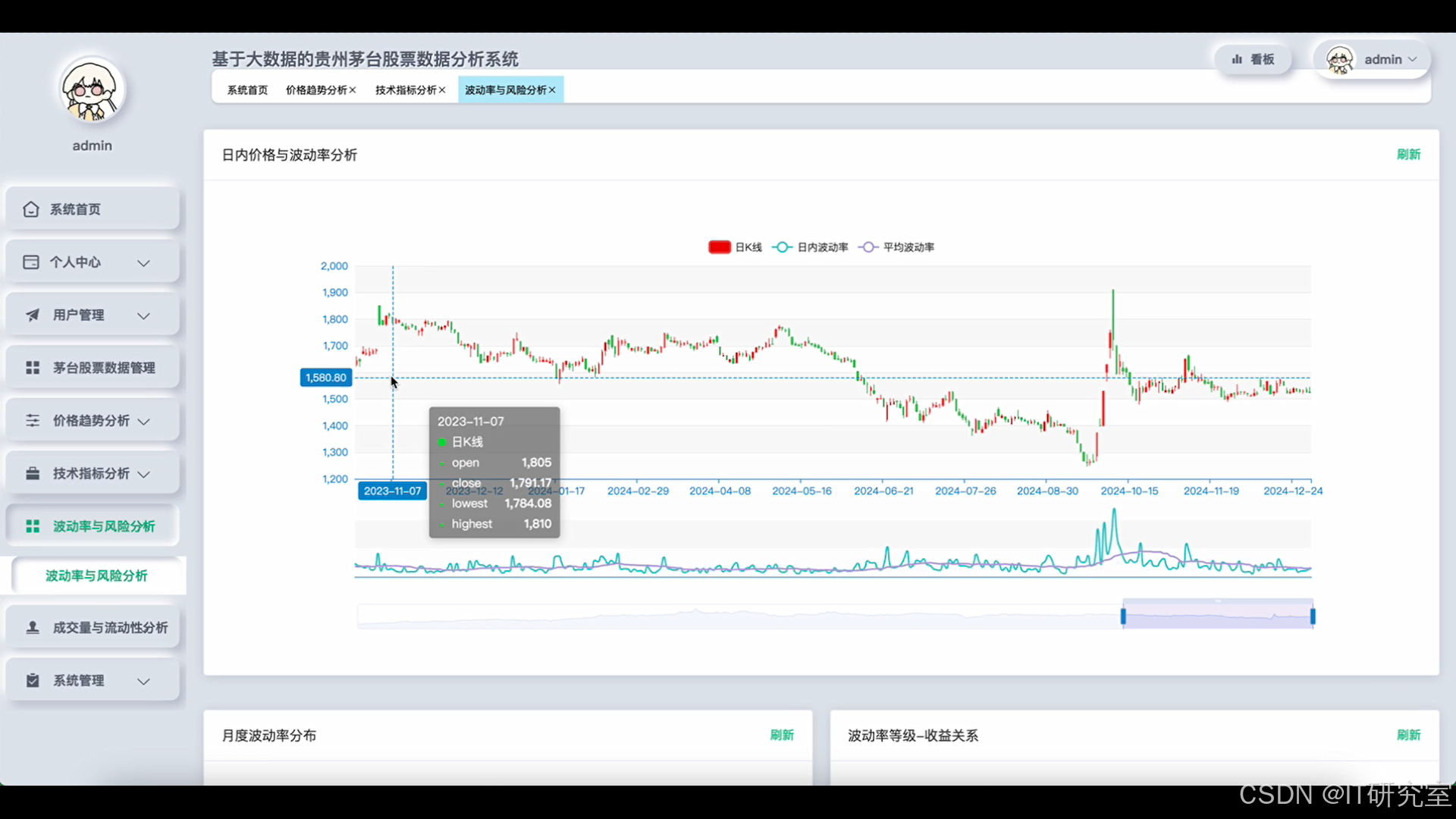
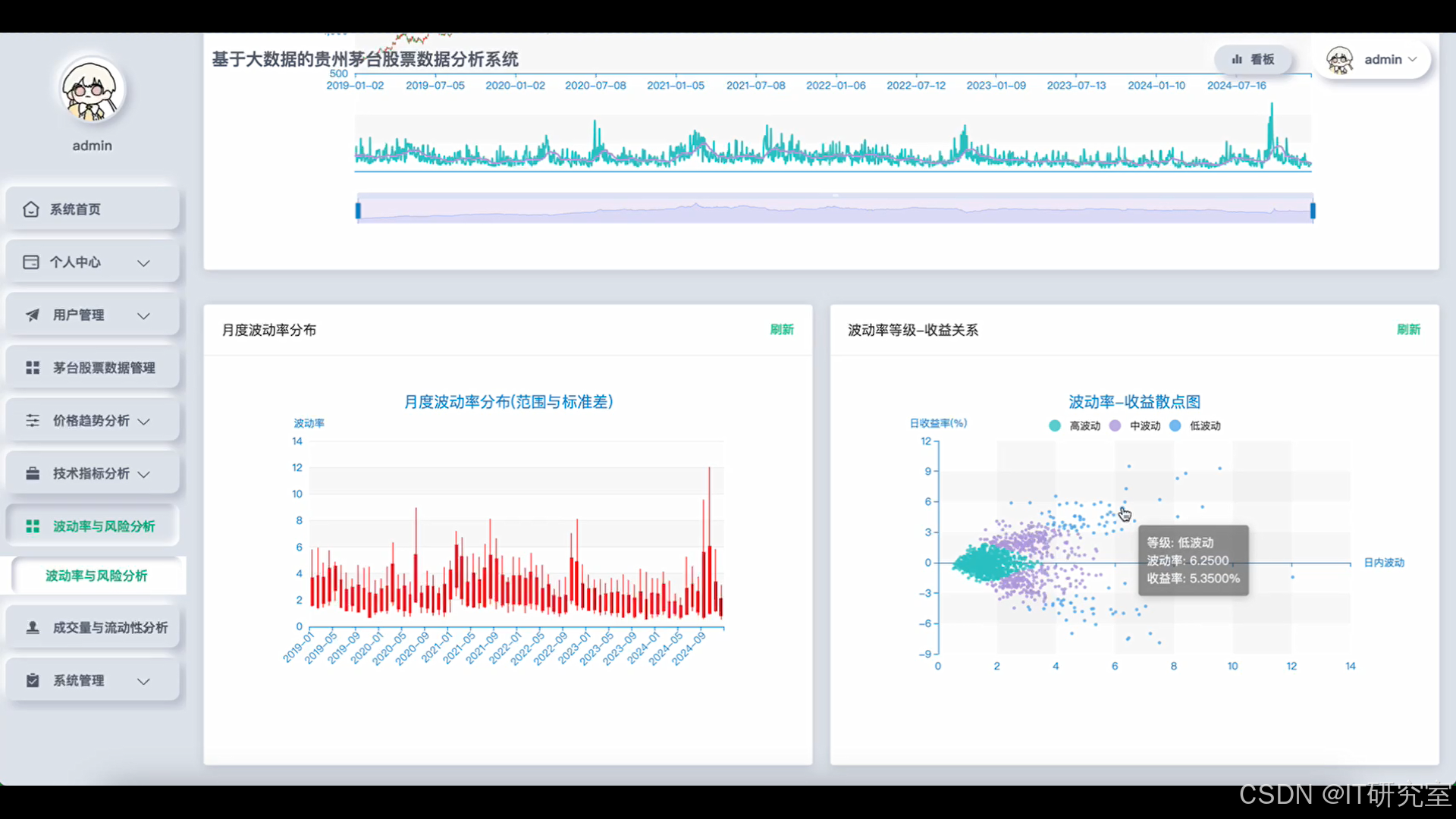
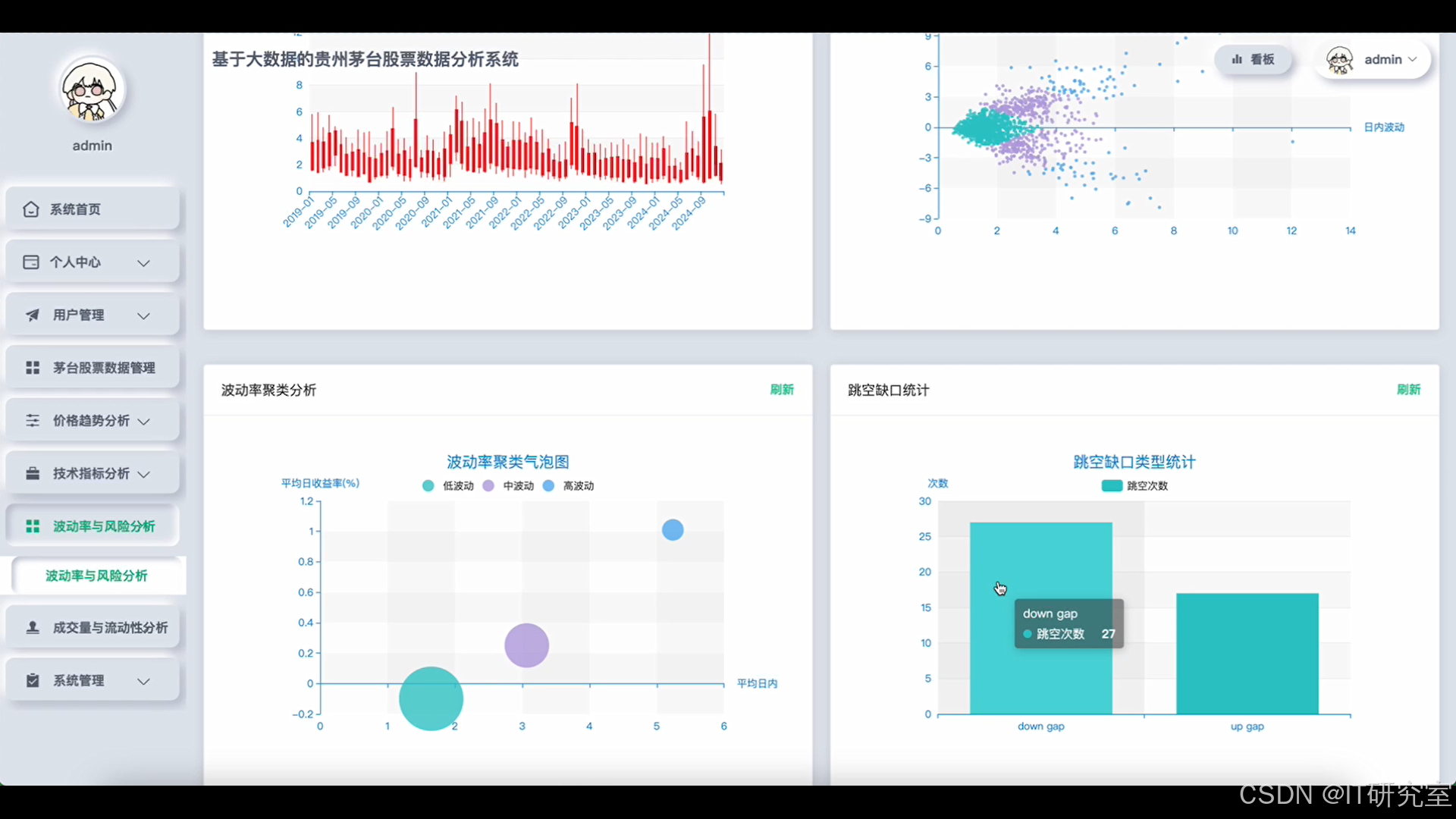
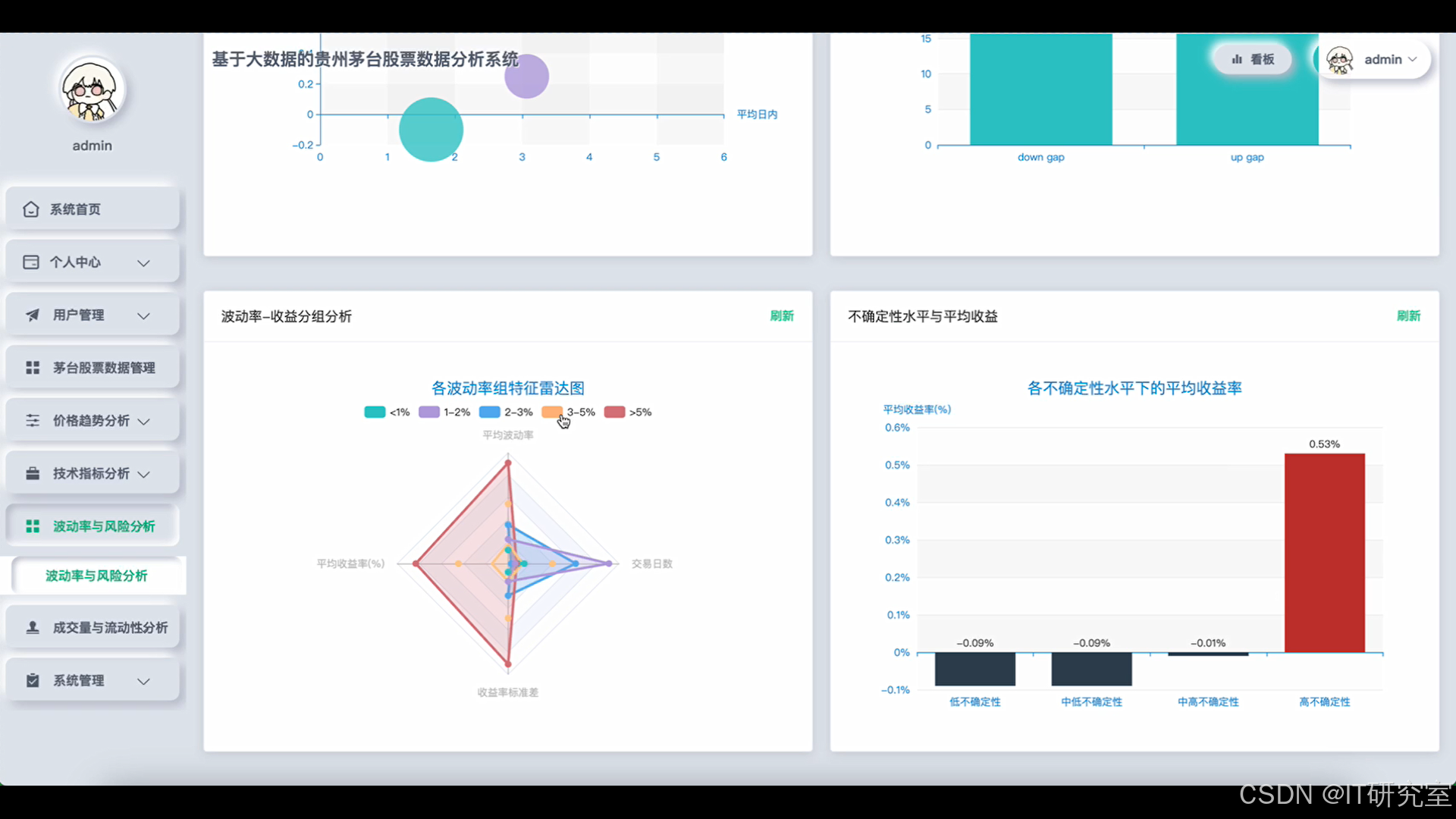
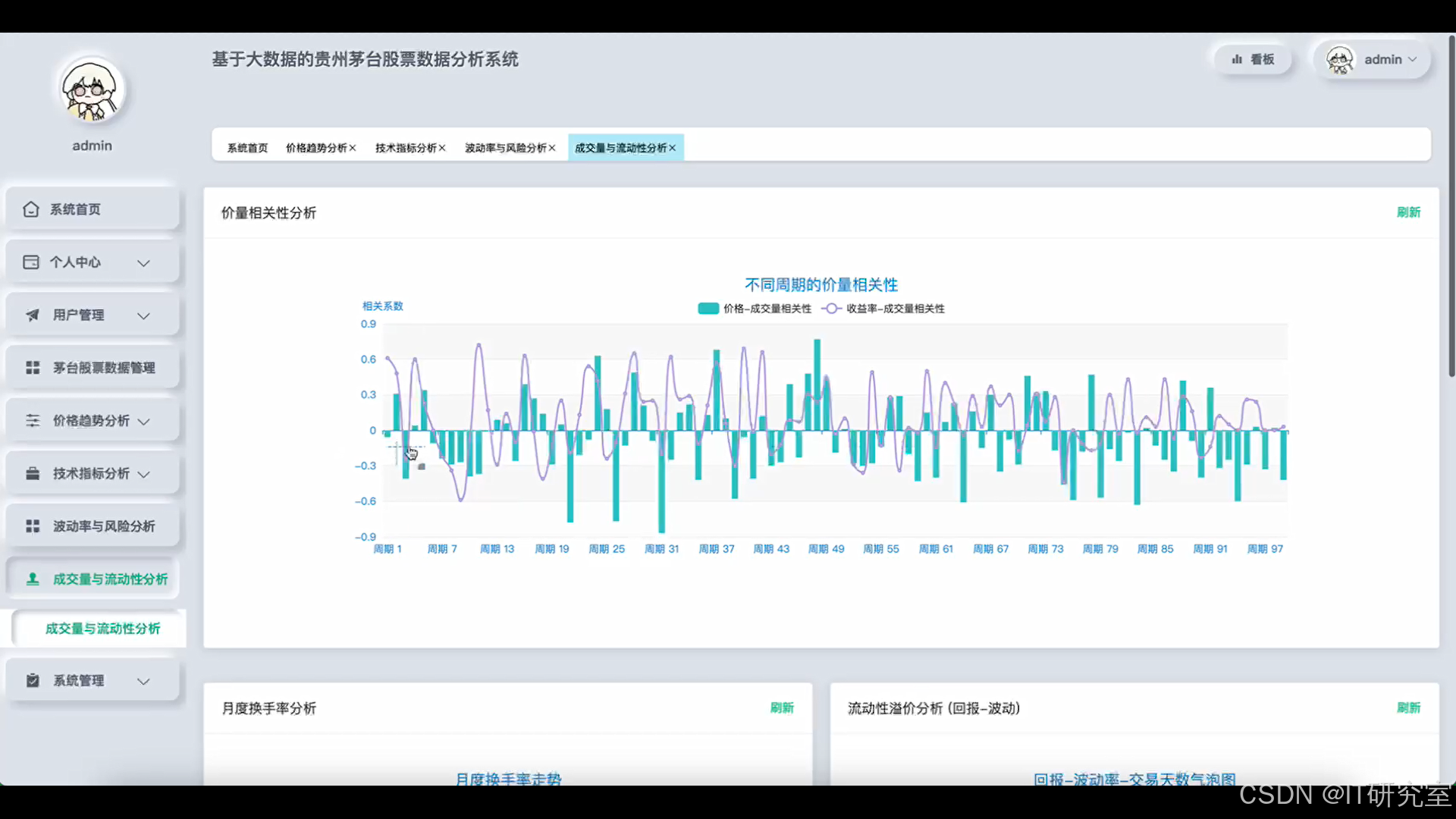
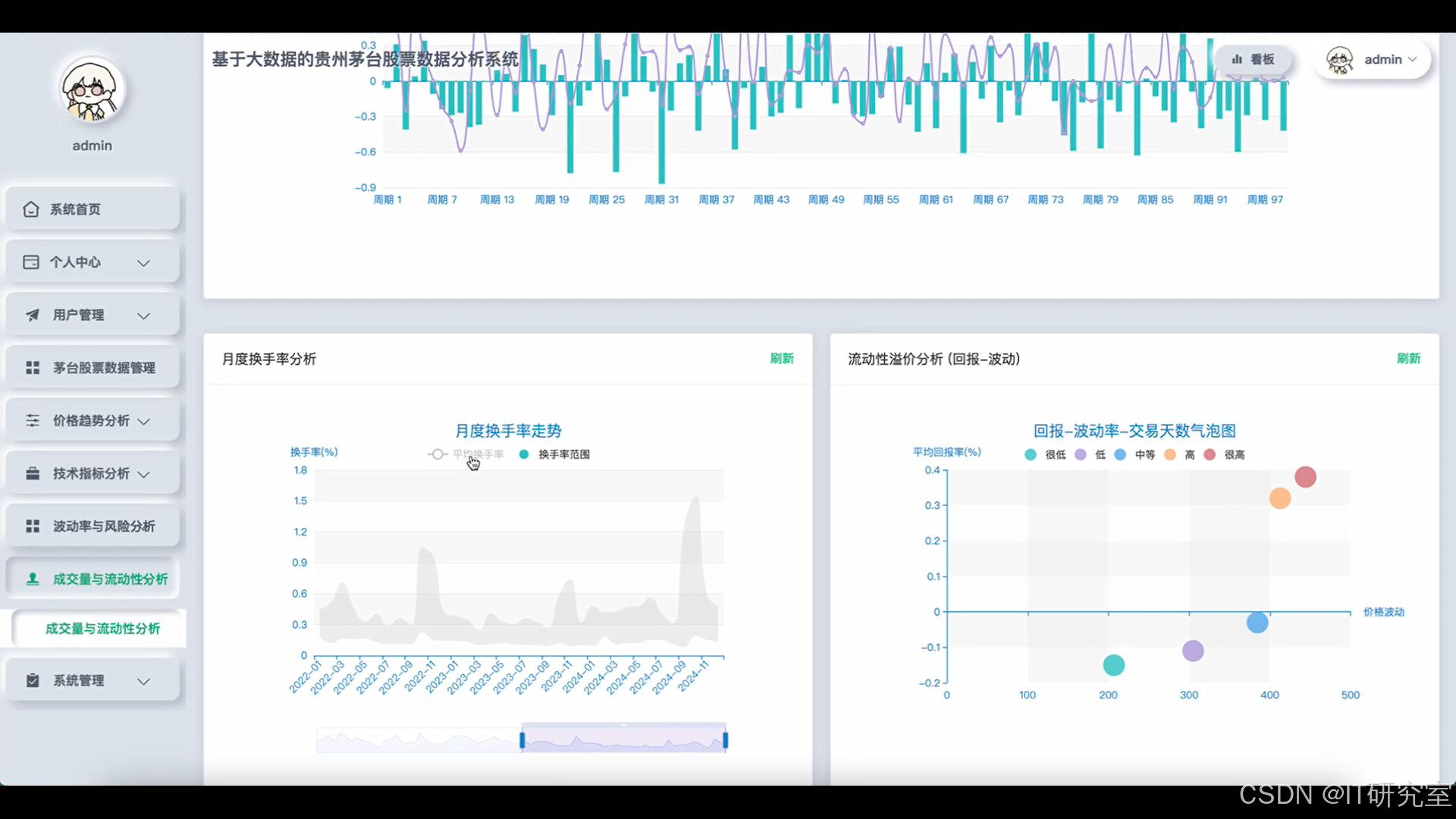
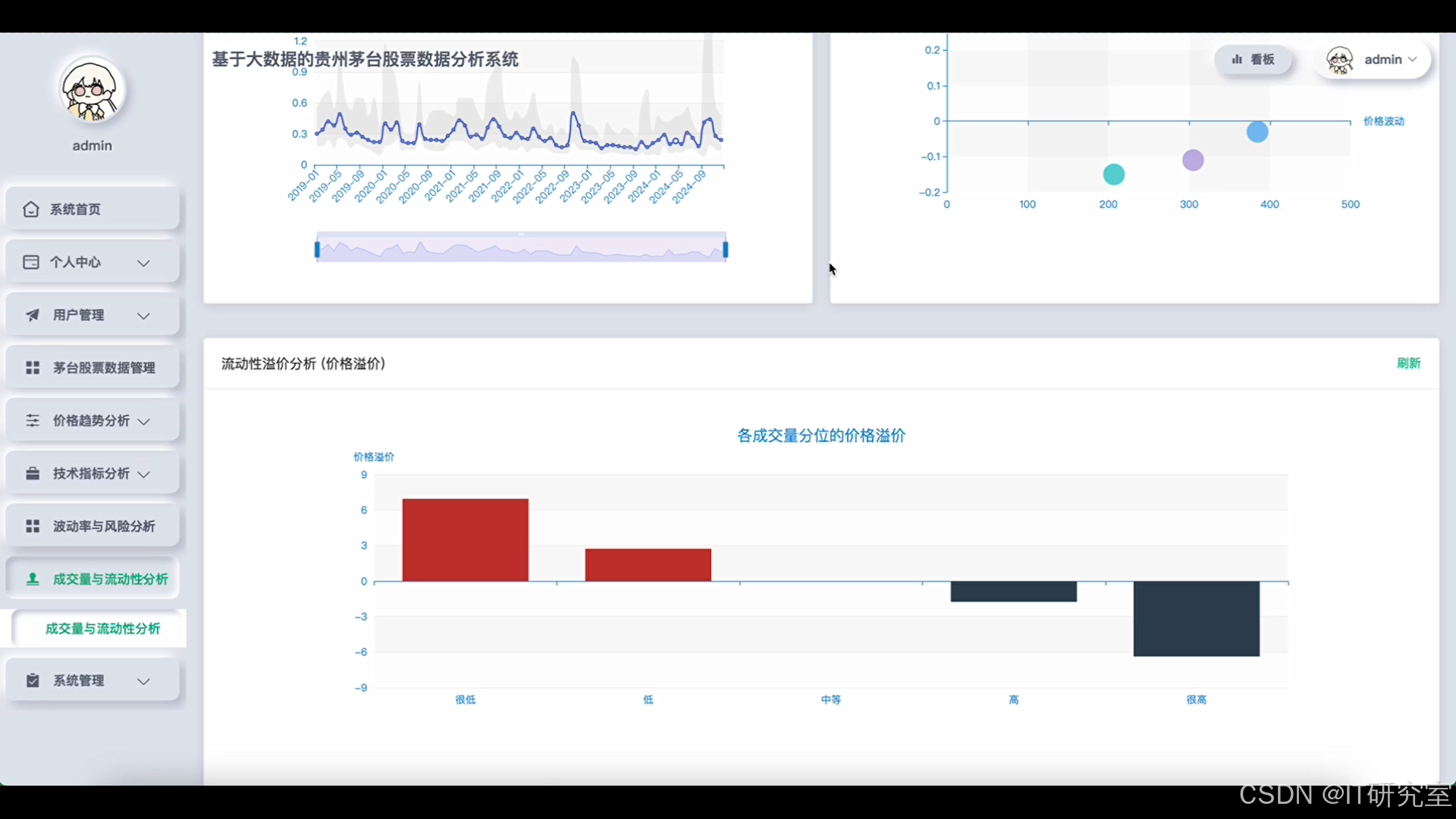
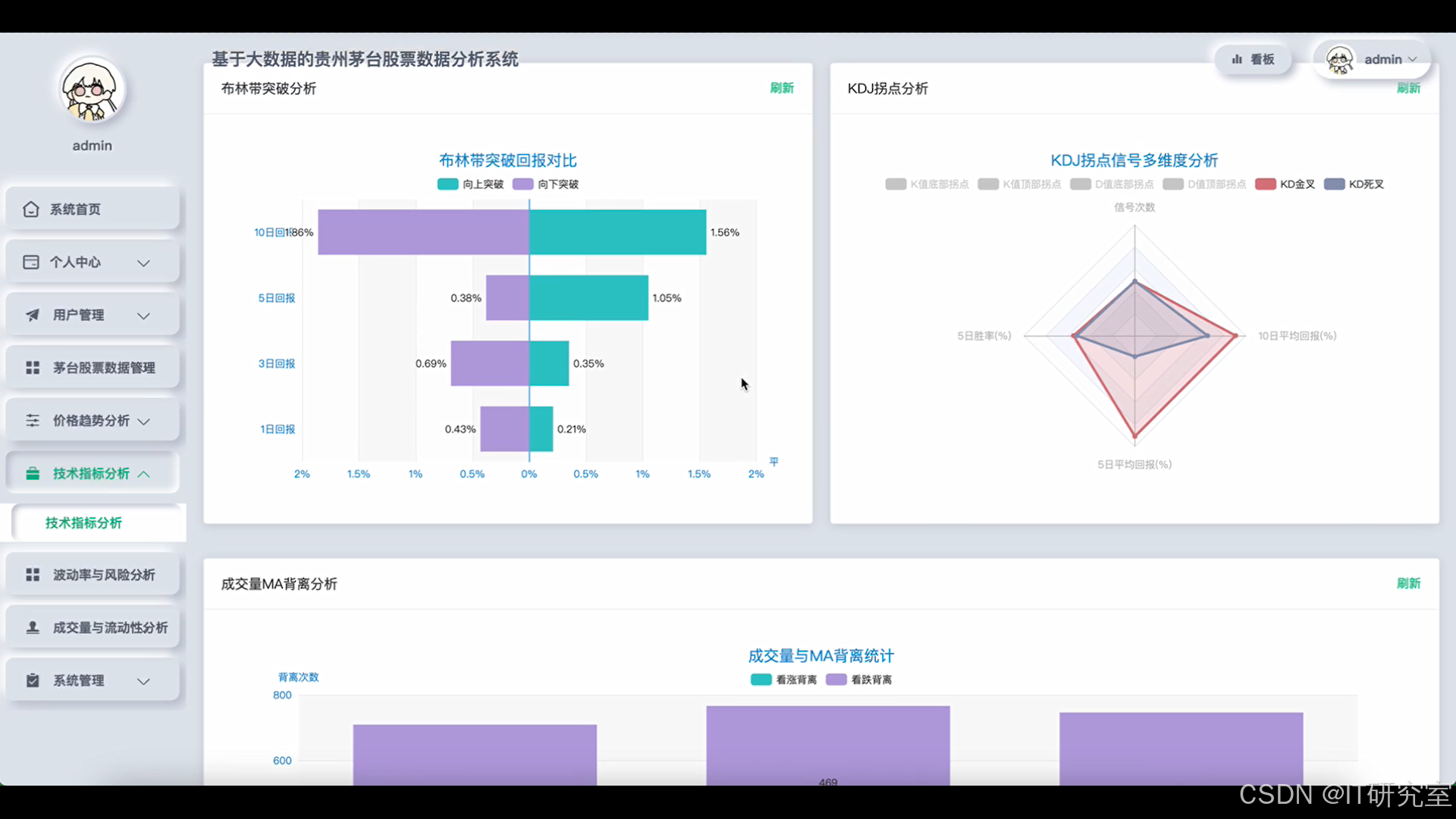
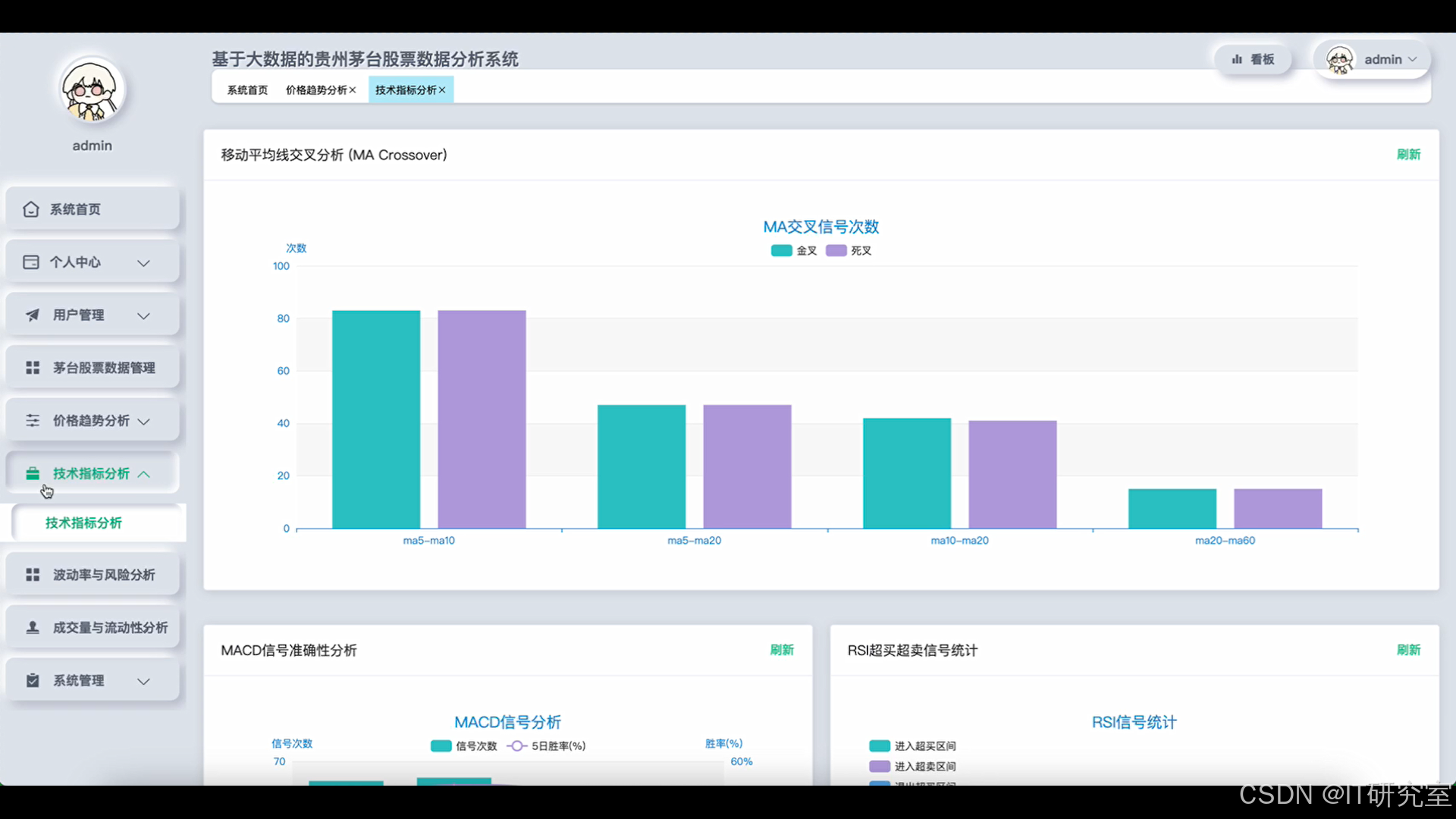
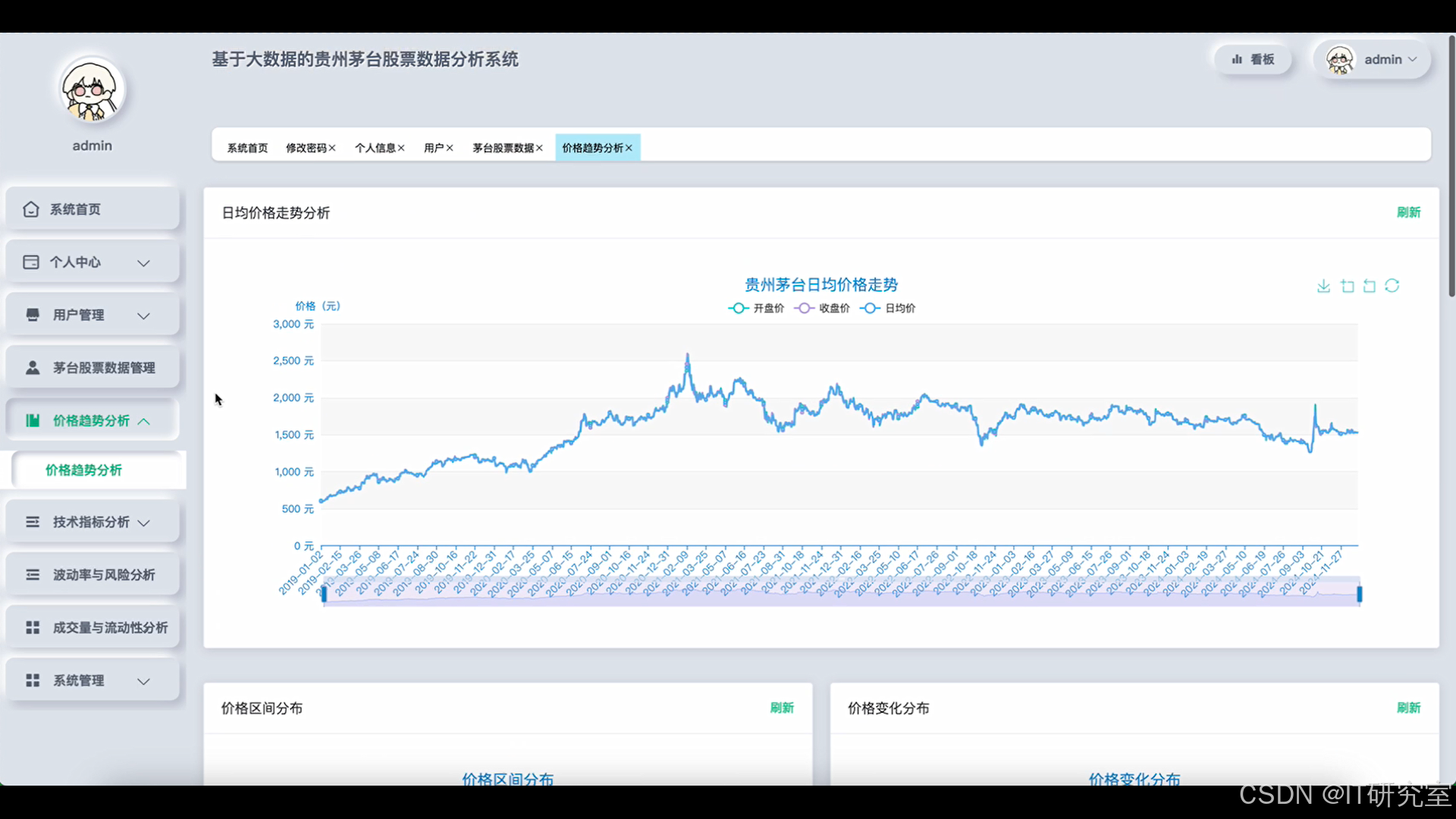
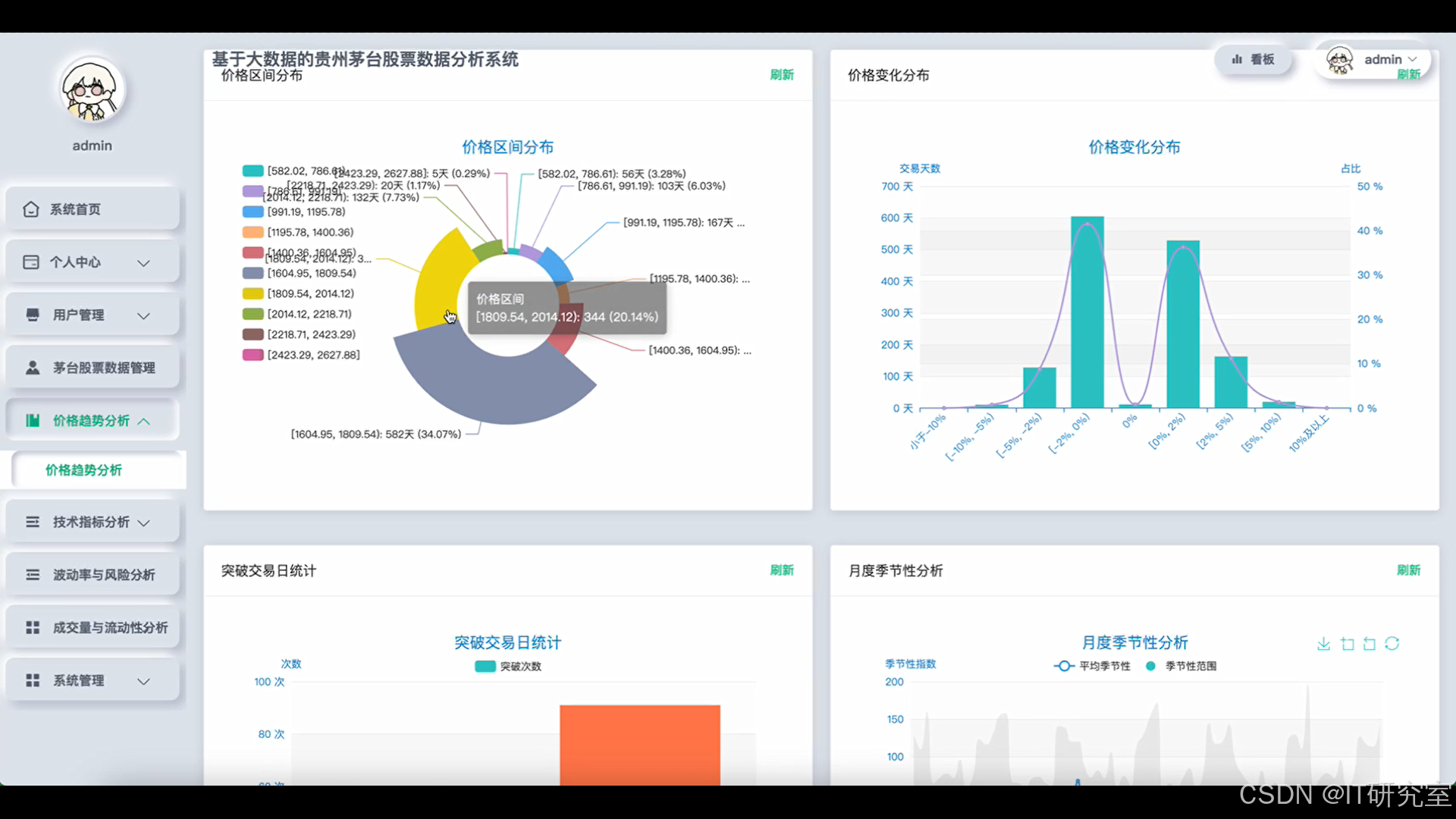
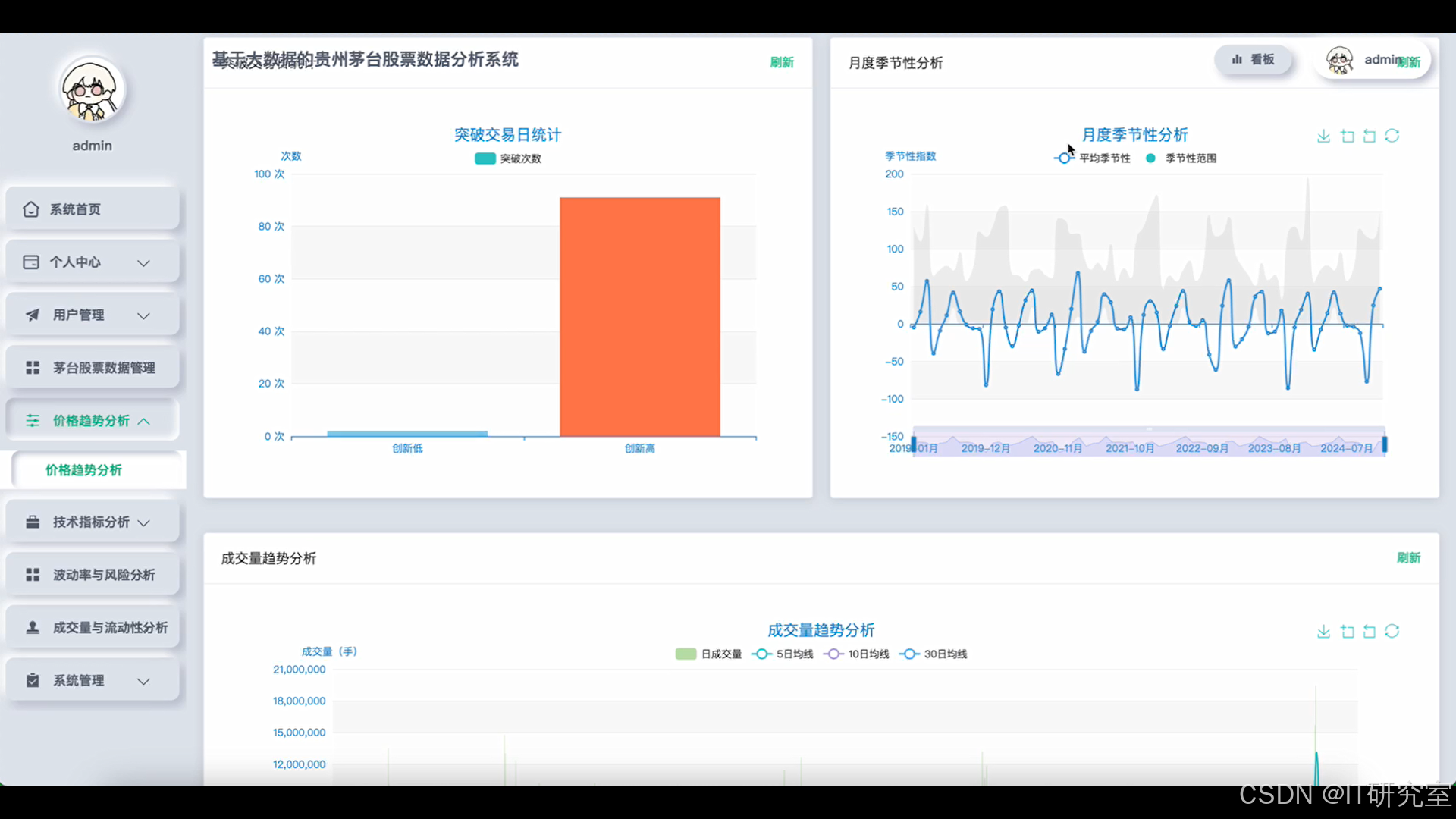
四、代码参考
- 项目实战代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import talib
spark = SparkSession.builder.appName("MaotaiStockAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def price_trend_analysis(stock_data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(stock_data_path)
df = df.withColumn("trade_date", to_date(col("交易时间"), "yyyy-MM-dd"))
df = df.withColumn("daily_avg_price", (col("开盘价") + col("收盘价") + col("最高价") + col("最低价")) / 4)
df = df.withColumn("price_volatility", (col("最高价") - col("最低价")) / col("开盘价") * 100)
window_spec = Window.partitionBy().orderBy("trade_date").rowsBetween(-19, 0)
df = df.withColumn("ma20", avg("收盘价").over(window_spec))
df = df.withColumn("volatility_20d", stddev("price_volatility").over(window_spec))
price_ranges = df.select(
when(col("收盘价") < 1000, "low").when(col("收盘价") < 1500, "medium").when(col("收盘价") < 2000, "high").otherwise("ultra_high").alias("price_range")
).groupBy("price_range").count()
trend_analysis = df.select(
col("trade_date"), col("收盘价"), col("daily_avg_price"), col("ma20"), col("price_volatility"), col("volatility_20d")
).filter(col("trade_date") >= date_sub(current_date(), 365))
breakout_days = df.filter(
(col("收盘价") == df.agg(max("收盘价")).collect()[0][0]) | (col("收盘价") == df.agg(min("收盘价")).collect()[0][0])
).select("trade_date", "收盘价", "成交量", "涨跌幅%")
seasonal_pattern = df.withColumn("month", month("trade_date")).withColumn("quarter", quarter("trade_date")).groupBy("month", "quarter").agg(
avg("收盘价").alias("avg_close_price"), avg("涨跌幅%").alias("avg_return"), count("*").alias("trading_days")
)
return trend_analysis, price_ranges, breakout_days, seasonal_pattern
def volume_liquidity_analysis(stock_data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(stock_data_path)
df = df.withColumn("trade_date", to_date(col("交易时间"), "yyyy-MM-dd"))
df = df.withColumn("volume_ma", avg("成交量").over(Window.partitionBy().orderBy("trade_date").rowsBetween(-9, 0)))
df = df.withColumn("amount_volume_ratio", col("成交额") / col("成交量"))
df = df.withColumn("volume_price_correlation", col("成交量") * col("涨跌幅%"))
volume_percentile_90 = df.approxQuantile("成交量", [0.9], 0.1)[0]
large_volume_days = df.filter(col("成交量") > volume_percentile_90).select(
"trade_date", "收盘价", "成交量", "成交额", "涨跌幅%"
).withColumn("volume_impact_score", col("成交量") * abs(col("涨跌幅%")) / 100)
liquidity_metrics = df.groupBy(date_trunc("month", "trade_date").alias("month")).agg(
avg("成交量").alias("avg_volume"), avg("成交额").alias("avg_amount"), avg("amount_volume_ratio").alias("avg_price_per_share"),
stddev("成交量").alias("volume_volatility"), sum("成交量").alias("total_volume")
)
price_volume_correlation = df.select(corr("收盘价", "成交量").alias("price_volume_corr"), corr("涨跌幅%", "成交量").alias("return_volume_corr"))
volume_trend = df.withColumn("volume_change_pct", (col("成交量") - lag("成交量", 1).over(Window.partitionBy().orderBy("trade_date"))) / lag("成交量", 1).over(Window.partitionBy().orderBy("trade_date")) * 100)
abnormal_trading = df.filter((abs(col("涨跌幅%")) > 5) | (col("成交量") > volume_percentile_90)).select(
"trade_date", "开盘价", "收盘价", "最高价", "最低价", "成交量", "成交额", "涨跌幅%"
).withColumn("abnormal_type", when(abs(col("涨跌幅%")) > 5, "price_abnormal").when(col("成交量") > volume_percentile_90, "volume_abnormal").otherwise("both"))
return large_volume_days, liquidity_metrics, price_volume_correlation, volume_trend, abnormal_trading
def volatility_risk_analysis(stock_data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(stock_data_path)
df = df.withColumn("trade_date", to_date(col("交易时间"), "yyyy-MM-dd"))
df = df.withColumn("daily_return", (col("收盘价") - lag("收盘价", 1).over(Window.partitionBy().orderBy("trade_date"))) / lag("收盘价", 1).over(Window.partitionBy().orderBy("trade_date")) * 100)
df = df.withColumn("intraday_volatility", (col("最高价") - col("最低价")) / col("开盘价") * 100)
df = df.withColumn("gap_size", (col("开盘价") - lag("收盘价", 1).over(Window.partitionBy().orderBy("trade_date"))) / lag("收盘价", 1).over(Window.partitionBy().orderBy("trade_date")) * 100)
rolling_window = Window.partitionBy().orderBy("trade_date").rowsBetween(-19, 0)
df = df.withColumn("volatility_20d", stddev("daily_return").over(rolling_window))
df = df.withColumn("var_95", expr("percentile_approx(daily_return, 0.05)").over(rolling_window))
df = df.withColumn("max_drawdown", (col("收盘价") - max("收盘价").over(rolling_window)) / max("收盘价").over(rolling_window) * 100)
volatility_clusters = df.select("trade_date", "intraday_volatility", "daily_return", "volatility_20d").withColumn(
"volatility_regime", when(col("volatility_20d") > 3.0, "high_vol").when(col("volatility_20d") > 1.5, "medium_vol").otherwise("low_vol")
)
gap_analysis = df.filter(abs(col("gap_size")) > 2.0).select(
"trade_date", "gap_size", "收盘价", "涨跌幅%", lag("收盘价", 1).over(Window.partitionBy().orderBy("trade_date")).alias("prev_close")
).withColumn("gap_direction", when(col("gap_size") > 0, "gap_up").otherwise("gap_down"))
risk_return_analysis = df.groupBy(date_trunc("quarter", "trade_date").alias("quarter")).agg(
avg("daily_return").alias("avg_return"), stddev("daily_return").alias("return_volatility"),
min("daily_return").alias("min_return"), max("daily_return").alias("max_return"),
avg("intraday_volatility").alias("avg_intraday_vol")
).withColumn("sharpe_ratio", col("avg_return") / col("return_volatility"))
uncertainty_index = df.withColumn("uncertainty_score", col("volatility_20d") * abs(col("daily_return")) + col("intraday_volatility")).select(
"trade_date", "uncertainty_score", "收盘价", "成交量"
).withColumn("uncertainty_percentile", percent_rank().over(Window.partitionBy().orderBy("uncertainty_score")))
return volatility_clusters, gap_analysis, risk_return_analysis, uncertainty_index五、系统视频
基于大数据的贵州茅台股票数据分析系统项目视频:
大数据毕业设计选题推荐-基于大数据的贵州茅台股票数据分析系统-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的贵州茅台股票数据分析系统-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说~谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇