精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、开发环境
- 三、视频展示
- 四、项目展示
- 五、代码展示
- 六、项目文档展示
- 七、总结
-
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻)
一、项目介绍
基于Python+Django的医疗数据分析系统是一个采用现代化Web开发技术构建的医疗信息处理平台。该系统运用Python作为核心开发语言,结合Django强大的Web框架能力,构建了稳定可靠的后端服务架构。前端采用Vue.js配合ElementUI组件库,为用户提供直观友好的操作界面。系统数据存储依托MySQL关系型数据库,确保医疗数据的安全性和完整性。整个系统按照B/S架构设计,用户通过浏览器即可访问所有功能模块。系统设计了管理员和普通用户两种角色权限,管理员负责用户信息维护、医疗数据管理以及预测数据分析等核心业务,普通用户可以完成注册登录并查看相关医疗数据信息。通过PyCharm集成开发环境进行系统开发和调试,整个项目结构清晰,代码可维护性强,为医疗数据的数字化管理提供了有效的技术解决方案。
选题背景
随着现代医疗行业的快速发展和医疗信息化程度的不断提升,各类医疗机构每天都会产生大量的患者数据、诊疗记录、检验报告等医疗信息。传统的纸质记录和简单的电子表格管理方式已经无法满足现代医疗数据处理的需求,医疗数据的存储、查询、分析和预测成为了医疗管理工作中的重要环节。医疗数据具有数据量大、结构复杂、实时性要求高等特点,需要专业的信息系统来进行有效管理。同时,医疗数据分析对于疾病预防、治疗方案制定、医疗资源配置等方面具有重要价值。在这样的背景下,开发一个基于现代Web技术的医疗数据分析系统,能够帮助医疗机构更好地管理和利用医疗数据资源。Python语言在数据处理和分析领域的优势,结合Django框架的Web开发能力,为构建这样的系统提供了良好的技术基础。
选题意义
本课题的开发具有一定的实际应用价值和学习意义。从实用角度来看,该系统能够为小型医疗机构或医疗数据管理部门提供一个相对简单实用的数据管理工具,帮助实现医疗数据的电子化存储和基础分析功能。通过系统的用户管理模块,可以实现不同权限用户对医疗数据的分级访问,保障数据安全。医疗数据管理功能能够帮助整理和存储各类医疗信息,而预测数据分析模块虽然功能相对基础,但也能为医疗决策提供一定的数据支持。从技术学习角度而言,该项目涵盖了完整的Web开发流程,包括后端API设计、数据库设计、前端界面开发等环节,有助于加深对Python Web开发技术的理解和掌握。同时,医疗数据分析这一应用领域也具有一定的社会意义,能够让开发者了解医疗信息化的基本需求和技术实现方式。虽然作为毕业设计项目,系统功能相对基础,但依然能够为后续深入学习医疗信息系统开发奠定良好基础。
二、开发环境
开发语言:Python
数据库:MySQL
系统架构:B/S
后端框架:Django
前端:Vue+ElementUI
开发工具:PyCharm
三、视频展示
计算机毕业设计 基于Python+Django的医疗数据分析系统
四、项目展示
登录模块:
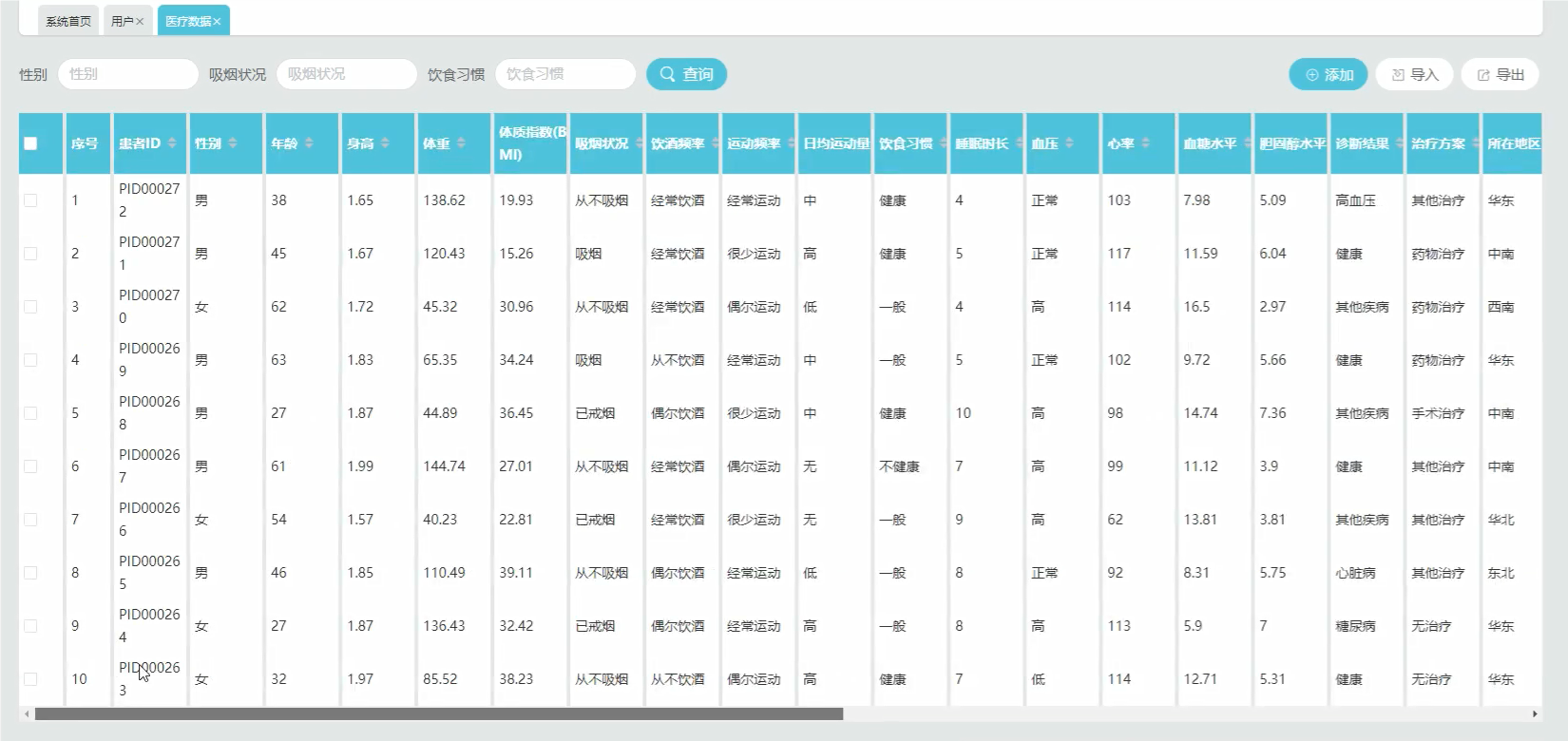
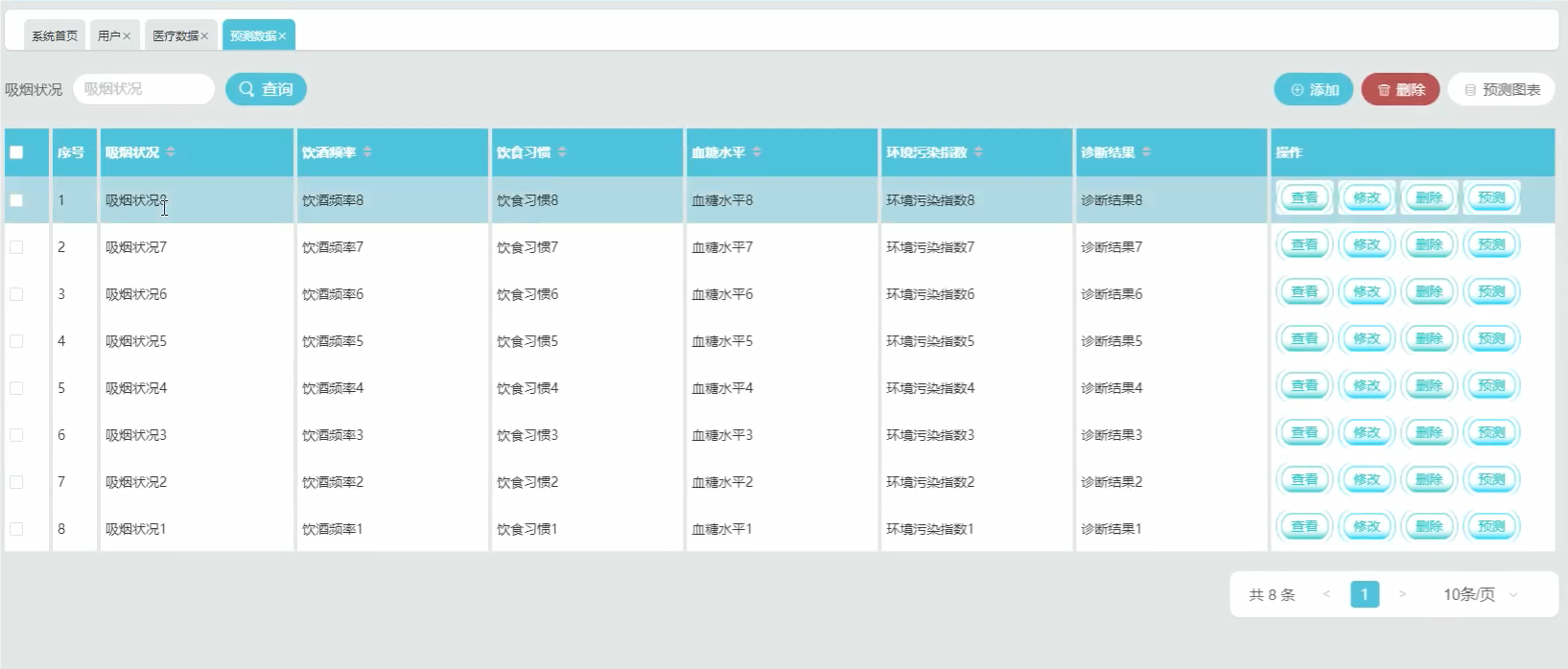
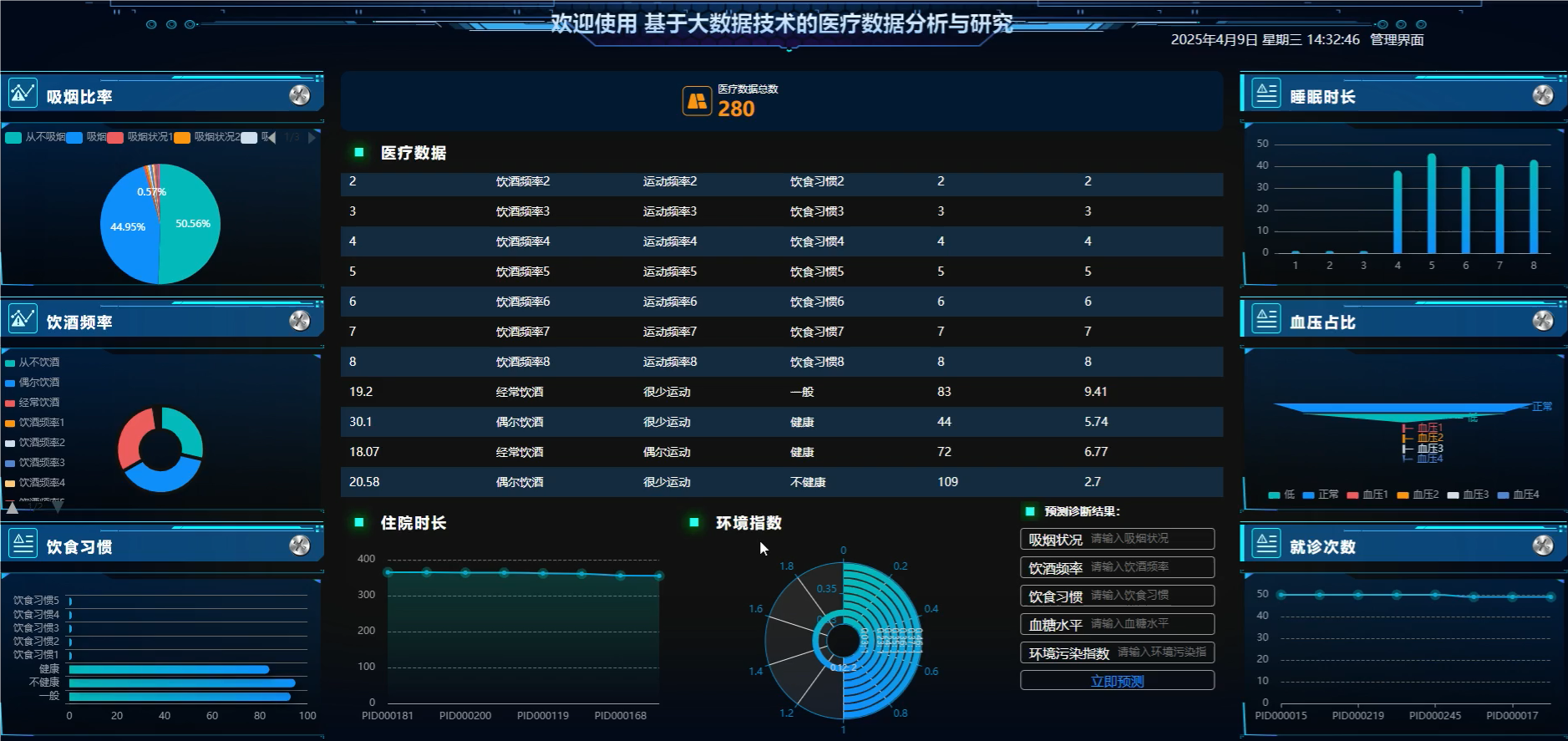
管理模块:
五、代码展示
bash
from pyspark.sql import SparkSession
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
from django.contrib.auth.models import User
from django.contrib.auth import authenticate, login
from .models import MedicalData, PredictionData
import json
import pandas as pd
import numpy as np
from datetime import datetime
from django.db.models import Q
spark = SparkSession.builder.appName("MedicalDataAnalysis").getOrCreate()
@csrf_exempt
def user_management(request):
if request.method == 'GET':
users = User.objects.all()
user_list = []
for user in users:
user_info = {
'id': user.id,
'username': user.username,
'email': user.email,
'is_active': user.is_active,
'date_joined': user.date_joined.strftime('%Y-%m-%d %H:%M:%S')
}
user_list.append(user_info)
return JsonResponse({'code': 200, 'data': user_list, 'message': '获取用户列表成功'})
elif request.method == 'POST':
data = json.loads(request.body)
username = data.get('username')
password = data.get('password')
email = data.get('email')
if User.objects.filter(username=username).exists():
return JsonResponse({'code': 400, 'message': '用户名已存在'})
if User.objects.filter(email=email).exists():
return JsonResponse({'code': 400, 'message': '邮箱已被注册'})
user = User.objects.create_user(username=username, password=password, email=email)
user.save()
return JsonResponse({'code': 200, 'message': '用户创建成功'})
elif request.method == 'PUT':
data = json.loads(request.body)
user_id = data.get('user_id')
try:
user = User.objects.get(id=user_id)
user.is_active = data.get('is_active', user.is_active)
user.email = data.get('email', user.email)
user.save()
return JsonResponse({'code': 200, 'message': '用户信息更新成功'})
except User.DoesNotExist:
return JsonResponse({'code': 404, 'message': '用户不存在'})
elif request.method == 'DELETE':
data = json.loads(request.body)
user_id = data.get('user_id')
try:
user = User.objects.get(id=user_id)
user.delete()
return JsonResponse({'code': 200, 'message': '用户删除成功'})
except User.DoesNotExist:
return JsonResponse({'code': 404, 'message': '用户不存在'})
@csrf_exempt
def medical_data_management(request):
if request.method == 'GET':
page = int(request.GET.get('page', 1))
size = int(request.GET.get('size', 10))
search_keyword = request.GET.get('keyword', '')
medical_data_query = MedicalData.objects.all()
if search_keyword:
medical_data_query = medical_data_query.filter(
Q(patient_name__icontains=search_keyword) |
Q(diagnosis__icontains=search_keyword) |
Q(department__icontains=search_keyword)
)
total_count = medical_data_query.count()
start_index = (page - 1) * size
end_index = start_index + size
medical_data_list = medical_data_query[start_index:end_index]
data_list = []
for data in medical_data_list:
data_info = {
'id': data.id,
'patient_name': data.patient_name,
'age': data.age,
'gender': data.gender,
'diagnosis': data.diagnosis,
'treatment': data.treatment,
'department': data.department,
'doctor_name': data.doctor_name,
'admission_date': data.admission_date.strftime('%Y-%m-%d'),
'discharge_date': data.discharge_date.strftime('%Y-%m-%d') if data.discharge_date else None,
'medical_cost': float(data.medical_cost)
}
data_list.append(data_info)
return JsonResponse({
'code': 200,
'data': {
'list': data_list,
'total': total_count,
'page': page,
'size': size
},
'message': '获取医疗数据成功'
})
elif request.method == 'POST':
data = json.loads(request.body)
medical_data = MedicalData(
patient_name=data.get('patient_name'),
age=data.get('age'),
gender=data.get('gender'),
diagnosis=data.get('diagnosis'),
treatment=data.get('treatment'),
department=data.get('department'),
doctor_name=data.get('doctor_name'),
admission_date=datetime.strptime(data.get('admission_date'), '%Y-%m-%d').date(),
discharge_date=datetime.strptime(data.get('discharge_date'), '%Y-%m-%d').date() if data.get('discharge_date') else None,
medical_cost=data.get('medical_cost')
)
medical_data.save()
spark_df = spark.createDataFrame([(
medical_data.patient_name,
medical_data.age,
medical_data.gender,
medical_data.diagnosis,
medical_data.department
)], ['patient_name', 'age', 'gender', 'diagnosis', 'department'])
spark_df.createOrReplaceTempView("new_medical_data")
spark.sql("SELECT * FROM new_medical_data").show()
return JsonResponse({'code': 200, 'message': '医疗数据添加成功'})
@csrf_exempt
def prediction_data_analysis(request):
if request.method == 'GET':
prediction_type = request.GET.get('type', 'disease_trend')
if prediction_type == 'disease_trend':
medical_data = MedicalData.objects.all().values('diagnosis', 'admission_date', 'age', 'gender')
df_data = list(medical_data)
if len(df_data) == 0:
return JsonResponse({'code': 400, 'message': '暂无医疗数据进行分析'})
spark_df = spark.createDataFrame(df_data)
spark_df.createOrReplaceTempView("medical_analysis")
disease_stats = spark.sql("""
SELECT diagnosis, COUNT(*) as count, AVG(age) as avg_age
FROM medical_analysis
GROUP BY diagnosis
ORDER BY count DESC
""").collect()
trend_data = []
for row in disease_stats:
trend_data.append({
'disease_name': row['diagnosis'],
'case_count': row['count'],
'average_age': round(row['avg_age'], 2)
})
prediction_result = PredictionData(
prediction_type='疾病趋势分析',
prediction_result=json.dumps(trend_data),
prediction_date=datetime.now().date()
)
prediction_result.save()
return JsonResponse({
'code': 200,
'data': {
'prediction_type': '疾病趋势分析',
'analysis_result': trend_data,
'total_cases': len(df_data)
},
'message': '疾病趋势分析完成'
})
elif prediction_type == 'cost_analysis':
medical_data = MedicalData.objects.all().values('department', 'medical_cost', 'age')
cost_data = list(medical_data)
if len(cost_data) == 0:
return JsonResponse({'code': 400, 'message': '暂无费用数据进行分析'})
spark_df = spark.createDataFrame(cost_data)
spark_df.createOrReplaceTempView("cost_analysis")
cost_stats = spark.sql("""
SELECT department,
AVG(medical_cost) as avg_cost,
MAX(medical_cost) as max_cost,
MIN(medical_cost) as min_cost,
COUNT(*) as patient_count
FROM cost_analysis
GROUP BY department
ORDER BY avg_cost DESC
""").collect()
cost_analysis_result = []
for row in cost_stats:
cost_analysis_result.append({
'department': row['department'],
'average_cost': round(row['avg_cost'], 2),
'max_cost': round(row['max_cost'], 2),
'min_cost': round(row['min_cost'], 2),
'patient_count': row['patient_count']
})
prediction_result = PredictionData(
prediction_type='医疗费用分析',
prediction_result=json.dumps(cost_analysis_result),
prediction_date=datetime.now().date()
)
prediction_result.save()
return JsonResponse({
'code': 200,
'data': {
'prediction_type': '医疗费用分析',
'analysis_result': cost_analysis_result
},
'message': '医疗费用分析完成'
})
elif request.method == 'POST':
data = json.loads(request.body)
analysis_params = data.get('analysis_params', {})
age_range = analysis_params.get('age_range', [0, 100])
gender_filter = analysis_params.get('gender', 'all')
medical_query = MedicalData.objects.filter(age__gte=age_range[0], age__lte=age_range[1])
if gender_filter != 'all':
medical_query = medical_query.filter(gender=gender_filter)
filtered_data = medical_query.values('diagnosis', 'age', 'gender', 'medical_cost', 'department')
filtered_list = list(filtered_data)
if len(filtered_list) == 0:
return JsonResponse({'code': 400, 'message': '根据筛选条件未找到相关数据'})
spark_df = spark.createDataFrame(filtered_list)
spark_df.createOrReplaceTempView("filtered_medical_data")
custom_analysis = spark.sql("""
SELECT diagnosis,
COUNT(*) as total_cases,
AVG(age) as avg_patient_age,
AVG(medical_cost) as avg_treatment_cost,
department
FROM filtered_medical_data
GROUP BY diagnosis, department
ORDER BY total_cases DESC
""").collect()
custom_result = []
for row in custom_analysis:
custom_result.append({
'diagnosis': row['diagnosis'],
'total_cases': row['total_cases'],
'avg_patient_age': round(row['avg_patient_age'], 2),
'avg_treatment_cost': round(row['avg_treatment_cost'], 2),
'department': row['department']
})
return JsonResponse({
'code': 200,
'data': {
'custom_analysis_result': custom_result,
'filter_conditions': analysis_params
},
'message': '自定义分析完成'
})六、项目文档展示

七、总结
本项目成功设计并实现了基于Python+Django的医疗数据分析系统,为医疗数据的数字化管理提供了一个完整的技术解决方案。通过采用Python作为核心开发语言,结合Django强大的Web框架能力,构建了稳定可靠的后端服务架构,有效处理医疗数据的存储、查询和分析需求。系统前端运用Vue.js配合ElementUI组件库,为用户呈现了直观友好的操作界面,提升了用户体验。整个系统按照B/S架构设计,用户通过浏览器即可访问所有功能模块,具有良好的跨平台兼容性。
在功能实现方面,系统建立了完善的用户权限管理机制,管理员可以进行用户信息维护、医疗数据管理以及预测数据分析等核心业务操作,普通用户能够完成注册登录并查看相关医疗数据信息。医疗数据管理模块支持数据的增删改查、分页显示和关键字搜索,满足了基本的数据管理需求。预测数据分析功能通过集成Spark大数据处理技术,实现了疾病趋势分析和医疗费用分析等功能,为医疗决策提供了数据支持。项目开发过程中积累了丰富的Web开发经验,加深了对Python Web开发技术栈的理解和掌握,为后续深入学习医疗信息系统开发奠定了良好基础。
大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖