无监督学习,推荐系统以及强化学习
无监督学习
聚类
K-means算法
- 随机猜测簇质心点位置
- 遍历所有的点,检查这些点距离哪个质心更近,并将点分配给最近的簇质心
- 分配好后,依次查看每个簇覆盖的点,并对这些点取平均值,并将簇质心移动到平均值的位置
- 再次查看所有点,检查这些点是否更接近另外的簇质心,而不是当前分配的簇质心,并重新将这些点分配给最近的簇质心
- 再次重新取均值移动簇质心
- 重复执行前两步直到簇质心不再移动
算法实现
- 随机初始化KKK个簇质心μ1,μ2,...,μK\mu_{1}, \mu_{2}, \ldots, \mu_{K}μ1,μ2,...,μK
- 重复以下步骤
- 1.将点分配给簇质心
for i = 1 to m- c(i)c^{(i)}c(i)
:=index(from 1 to K) of cluster centroid closest tox(i)x^{(i)}x(i)
- c(i)c^{(i)}c(i)
- 2.移动簇质心
for k = 1 to K- μk\mu_{k}μk
:= average(mean) of points assigned to cluster k
- μk\mu_{k}μk
优化目标
前言:
- c(i)c^{(i)}c(i) : 表示x(i)x^{(i)}x(i)(即第iii个样本)被分配给的簇质心的序号
- μk\mu_{k}μk : 第kkk个簇质心(也就是聚类中心)的位置
- μc(i)\mu_{c^{(i)}}μc(i) : 即若想知道第x(i)x^{(i)}x(i)个样本所属的簇质心(聚类中心)的位置,就可以通过c(i)c^{(i)}c(i)知道所属的簇质点序号,再根据簇质点序号,查看μc(i)\mu_{c^{(i)}}μc(i),即第c(i)c^{(i)}c(i)个簇质心的位置
代价函数(Cost function)/失真函数(Distortion function):
- J(c(1),...,c(m),μ1,...,μk)=1m∑i=1m∣∣x(i)−μc(i)∣∣2J(c^{(1)}, \ldots, c^{(m)}, \mu_{1}, \ldots, \mu_{k}) = \frac{1}{m}\sum\limits_{i = 1}^m{||x^{(i)} - \mu_{c^{(i)}}||^{2}}J(c(1),...,c(m),μ1,...,μk)=m1i=1∑m∣∣x(i)−μc(i)∣∣2
初始化K-means
- 选择K<mK \lt mK<m
- 从mmm个训练样本中随机的取出KKK个
- 令μ1,μ2,...,μk\mu_1, \mu_2, \ldots, \mu_kμ1,μ2,...,μk等于选择的KKK个样本
随机初始化
For i = 1 to 100 {(至少尝试50∼10050 \sim 10050∼100次,但最好不要超过100010001000次)- 随机初始化KKK个簇质心(选择KKK个训练集中的样本)
- 运行
K-means算法,得到对应的c(1),...,c(m),μ1,...,μkc^{(1)}, \ldots, c^{(m)}, \mu_{1}, \ldots, \mu_{k}c(1),...,c(m),μ1,...,μk - 计算代价函数(失真函数)
- J(c(1),...,c(m),μ1,...,μk)J(c^{(1)}, \ldots, c^{(m)}, \mu_{1}, \ldots, \mu_{k})J(c(1),...,c(m),μ1,...,μk)
}- 选择代价最低的一组聚类
聚类数量选择(KKK的选择)
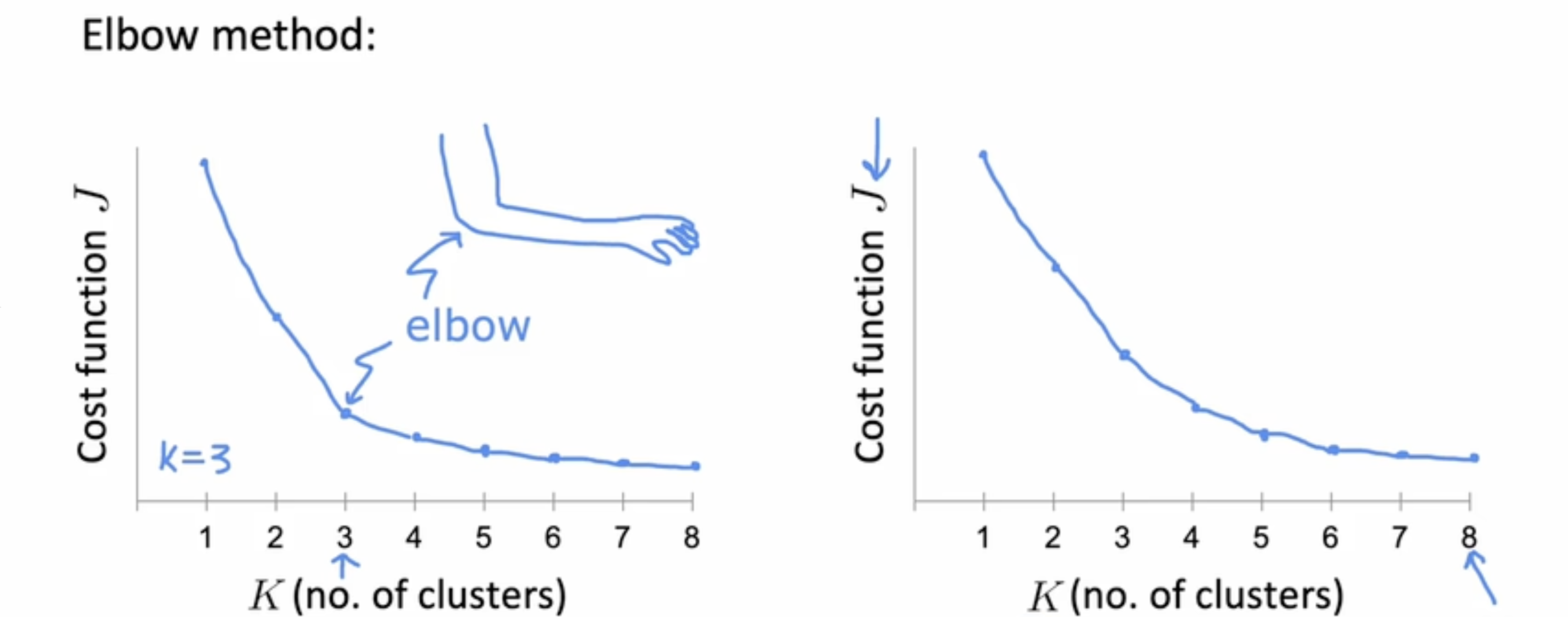
需要选择一个合适的KKK值时,往往会尝试采用多个kkk的取值,并用于训练模型后绘制出
ELBO(elbow method)
将代价函数作为聚类数量的函数进行观察,看是否有一个弯折点(如下左图,即类似手肘的弯曲,开始下降较快,经过某个点后变缓,这个点就是弯折点)
注: ELBO算法使用较少,如下右图,实际上很多情况下函数变化是比较平缓,那就会导致最后选择的KKK就是尝试中最大的KKK。
在后续用途中的表现来评估
先对模型进行训练,后续再根据具体的情况来评估哪个KKK值比较合适
Anomaly Detection(异常检测)
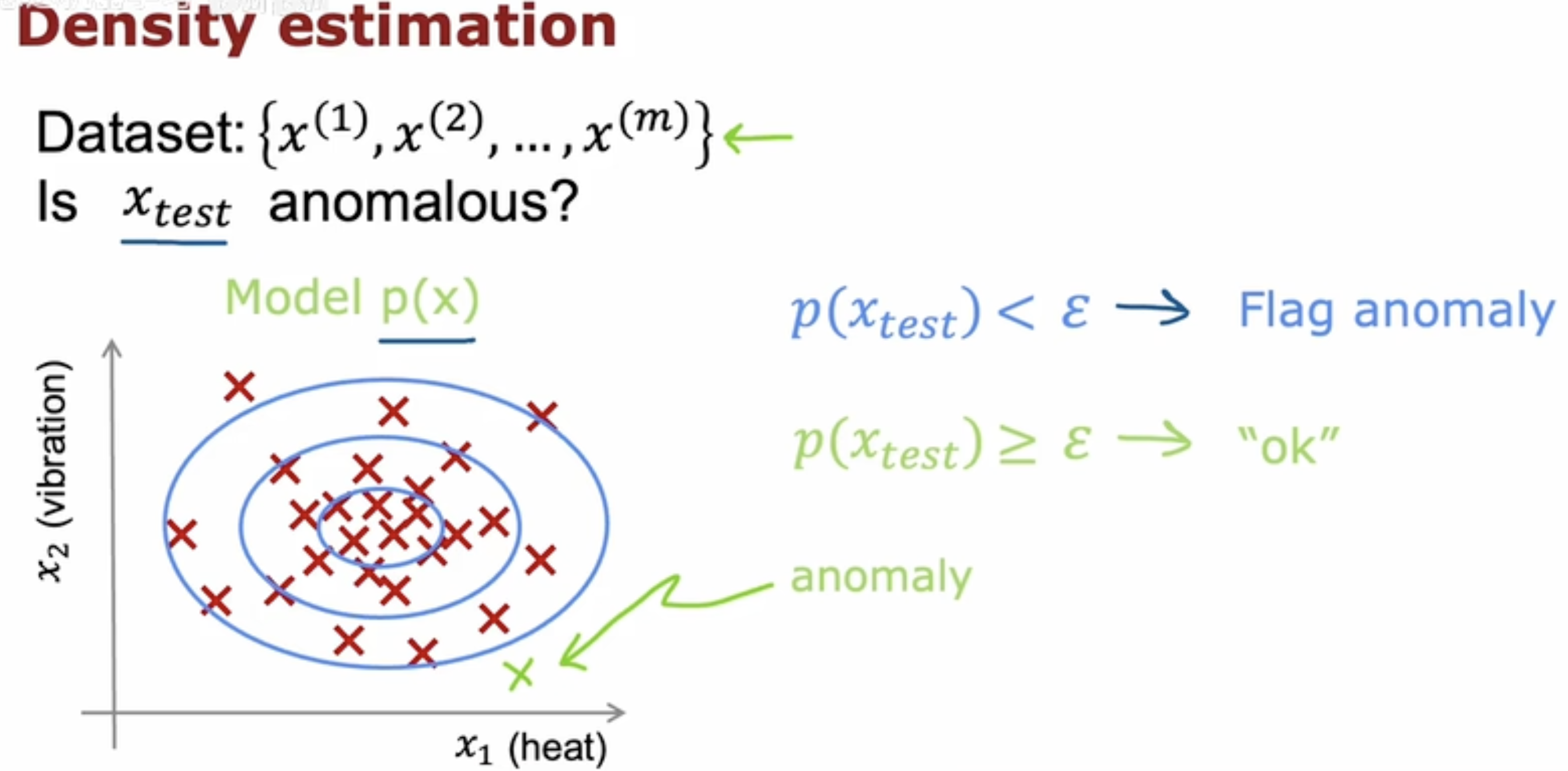
Density estimation(密度估计)
如下图,正常运行时,多数样本必然会聚集在密度高的中心区域,而机器故障时,样本会偏离这个区域,此时密度模型会判断它为异常。
即,使用模型预测样本所处区域的密度,此时可以选择一个较小值ϵ\epsilonϵ,假如预测的结果在ϵ\epsilonϵ范围内,则认为样本处于低密度区域,表明样本处于异常状态,而预测结果若大于等于ϵ\epsilonϵ,则表明处于密度足够的区域,判定为正常。
高斯(正态)分布
-
p(x)=12πσe−(x−μ)22σ2p(x) = \frac{1}{\sqrt{2\pi}\sigma}e^{\frac{-(x - \mu)^{2}}{2\sigma^{2}}}p(x)=2π σ1e2σ2−(x−μ)2
-
μ=1m∑i=1mx(i)\mu = \frac{1}{m}\sum\limits_{i = 1}^{m}x^{(i)}μ=m1i=1∑mx(i)
-
σ2=1m∑i=1m(x(i)−μ)2\sigma^{2} = \frac{1}{m}\sum\limits_{i = 1}^{m}(x^{(i)} - \mu)^{2}σ2=m1i=1∑m(x(i)−μ)2
异常检测算法
- 选择你认为可能能表现出异常的nnn个样本特征xix_{i}xi
- 为nnn个特征拟合参数μ1,...,μn,σ12,...,σn2\mu_{1}, \ldots, \mu_{n}, \sigma_{1}^{2}, \ldots, \sigma_{n}^{2}μ1,...,μn,σ12,...,σn2
- μj=1m∑i=1mxj(i)\mu_{j} = \frac{1}{m}\sum\limits_{i = 1}^{m}x_{j}^{(i)}μj=m1i=1∑mxj(i)
- σj2=1m∑i=1m(xj(i)−μj)2\sigma_{j}^{2} = \frac{1}{m}\sum\limits_{i = 1}^{m}(x_{j}^{(i)} - \mu_{j})^{2}σj2=m1i=1∑m(xj(i)−μj)2
- 给出一个新的样本xxx,计算p(x)p(x)p(x):
p(x)=∏j=1np(xj;μj,σj2)=∏j=1n12πσjexp(−(xj−μj)2σj22) \begin{aligned} p(x) &= \prod\limits_{j = 1}^{n} p(x_{j};\mu_{j},\sigma_{j}^{2}) \\\\ &= \prod\limits_{j = 1}^{n} \frac{1}{\sqrt{2\pi}\sigma_{j}}exp(-\frac{(x_{j} - \mu_{j})}{2\sigma_{j}^{2}}^{2}) \end{aligned} p(x)=j=1∏np(xj;μj,σj2)=j=1∏n2π σj1exp(−2σj2(xj−μj)2)
- 当p(x)<ϵp(x) \lt \epsilonp(x)<ϵ(ϵ\epsilonϵ为一个极小值,即当概率落到正态分布边缘时,则认为当前样本不在正常工作范围)时,则认为该样本为异常
Tips: 本算法的思想为将样本特征标准化为正态分布函数,此时若某项特征极大或极小,则对应的概率在正态分布上就是极小的,由于样本的特征之间均是独立同分布,则总概率为各个特征的概率乘积,当某个概率极小,就会导致最后的结果极小,此时判定该样本异常。
异常检测 vs 监督学习
异常检测:
- 样本数量
- 当只有非常少量的正样本(y=1)(y = 1)(y=1),类似(0∼20)(0 \sim 20)(0∼20)
- 并且有相对大量的负样本(y=0)(y = 0)(y=0)来尝试建立p(x)p(x)p(x)模型
- 异常类型
- 异常可能性较多时,正样本可能无法覆盖所有异常方式,未来的异常可能是从未出现过的
- 擅长解决的问题
- 诈骗检测
- 制造业-发现从未出现过的故障
- 监视数据中心的机器运行
监督学习:
- 样本数量
- 正负样本数量都很多
- 异常类型
- 需要包含足够多的正样本,来保证覆盖所有可能的异常类型
- 擅长解决的问题
- 垃圾邮件分类
- 制造业-发现已知的故障
- 天气预报
- 疾病分类
合适的特征选择
- 选择在出现异常时看取极大或极小值的特征
- 当现有特征在出现异常时表现并不明显时,可以对现有特征组成成新的特征
- 例:出现异常时网络流量(x1)(x_{1})(x1)特别低,但
CPU负载(x2)(x_{2})(x2)特别高 - 此时可以组合产生新特征:
- x3=x2x1x_{3} = \frac{x_{2}}{x_{1}}x3=x1x2,即(CPU负载网络流量)(\frac{\text{CPU负载}}{网络流量})(网络流量CPU负载)
- x4=(x2)2x1x_{4} = \frac{(x_{2})^{2}}{x_{1}}x4=x1(x2)2
- 例:出现异常时网络流量(x1)(x_{1})(x1)特别低,但
- 尝试多种不同的特征选择,以确保p(x)p(x)p(x)足够大
推荐系统
定义
这里以电影推荐系统为例。
- nun_{u}nu:用户数量
- nmn_{m}nm:电影数量
- nnn:特征数量
- w(i),b(i)w^{(i)}, b^{(i)}w(i),b(i):第iii个用户的参数
Tips: 由于每个人喜好不同,那么不可能使用同一个模型去预测其喜好,即可认为对每个用户均训练一个模型。
代价函数
- r(i,j)r(i, j)r(i,j):第jjj个用户是否对第iii个电影做出了评分
(0-No, 1-Yes) - y(i,j)y^{(i, j)}y(i,j):第jjj个用户对第iii个电影的评分
- w(j),b(j)w^{(j)}, b^{(j)}w(j),b(j):第jjj个用户的参数
- x(i)x^{(i)}x(i):第iii个电影的特征
- m(j)m^{(j)}m(j):第jjj个用户评分的电影数量
对于用户jjj已经电影iii,预测的结果为:w(j)⋅x(i)+b(j)w^{(j)} \cdot x^{(i)} + b^{(j)}w(j)⋅x(i)+b(j)
对应代价函数:
- minw(j)b(j)J(w(j),b(j))12m(j)∑i:r(i,j)=1(w(j)⋅x(i)+b(j)−y(i,j))2+λ2m(j)∑k=1n(wk(j))2\mathop{min}\limits_{w^{(j)}b^{(j)}}J(w^{(j)}, b^{(j)})\frac{1}{2m^{(j)}}\sum\limits_{i:r(i, j) = 1}(w^{(j)} \cdot x^{(i)} + b^{(j)} - y^{(i, j)})^{2} + \frac{\lambda}{2m^{(j)}}\sum\limits_{k = 1}^{n}(w_{k}^{(j)})^{2}w(j)b(j)minJ(w(j),b(j))2m(j)1i:r(i,j)=1∑(w(j)⋅x(i)+b(j)−y(i,j))2+2m(j)λk=1∑n(wk(j))2
对于所有用户的代价函数:
对于所有用户的所有学习参数w(1),b(1),w(2),b(2),...,w(nu),b(nu)w^{(1)}, b^{(1)}, w^{(2)}, b^{(2)}, \ldots, w^{(n_{u})}, b^{(n_{u})}w(1),b(1),w(2),b(2),...,w(nu),b(nu),有:
J(w(1),...,w(nu)b(1),...,b(nu))=12∑j=1nu∑i:r(i,j)=1(w(j)⋅x(i)+b(j)−y(i,j))2+λ2∑j=1nu∑k=1n(wk(j))2 J \left( \begin{aligned} w^{(1)}, \ldots, w^{(n_{u})} \\\\ b^{(1)}, \ldots, b^{(n_{u})} \end{aligned} \right) = \frac{1}{2}\sum\limits_{j = 1}^{n_{u}}\sum\limits_{i:r(i, j) = 1}(w^{(j)} \cdot x^{(i)} + b^{(j)} - y^{(i, j)})^{2} + \frac{\lambda}{2}\sum\limits_{j = 1}^{n_{u}}\sum\limits_{k = 1}^{n}(w_{k}^{(j)})^{2} J w(1),...,w(nu)b(1),...,b(nu) =21j=1∑nui:r(i,j)=1∑(w(j)⋅x(i)+b(j)−y(i,j))2+2λj=1∑nuk=1∑n(wk(j))2
协同过滤算法
通过参数反推特征值
给出w(1),b(1),w(2),b(2),...,w(nu),b(nu)w^{(1)}, b^{(1)}, w^{(2)}, b^{(2)}, \ldots, w^{(n_{u})}, b^{(n_{u})}w(1),b(1),w(2),b(2),...,w(nu),b(nu)
通过学习得到x(i)x^{(i)}x(i):
- J(x(i))=12∑j:r(i,j)=1(w(j)⋅x(i)+b(j)−y(i,j))2+λ2∑k=1n(xk(i))2J(x^{(i)}) = \frac{1}{2}\sum\limits_{j:r(i, j) = 1}(w^{(j)} \cdot x^{(i)} + b^{(j)} - y^{(i, j)})^{2} + \frac{\lambda}{2}\sum\limits_{k = 1}^{n}(x_{k}^{(i)})^{2}J(x(i))=21j:r(i,j)=1∑(w(j)⋅x(i)+b(j)−y(i,j))2+2λk=1∑n(xk(i))2
Tips: 这是所有用户对单个电影的成本函数,此时w,bw, bw,b已知,把xxx当参数去求。
对于所有特征x(1),x(2),...,x(nm)x^{(1)}, x^{(2)}, \ldots, x^{(n_{m})}x(1),x(2),...,x(nm):
- J(x(1),x(2),...,x(nm))=12∑i=1nm∑j:r(i,j)=1(w(j)⋅x(i)+b(j)−y(i,j))2+λ2∑i=1nm∑k=1n(xk(i))2J(x^{(1)}, x^{(2)}, \ldots, x^{(n_{m})}) = \frac{1}{2}\sum\limits_{i = 1}^{n_{m}}\sum\limits_{j:r(i, j) = 1}(w^{(j)} \cdot x^{(i)} + b^{(j)} - y^{(i, j)})^{2} + \frac{\lambda}{2}\sum\limits_{i = 1}^{n_{m}}\sum\limits_{k = 1}^{n}(x_{k}^{(i)})^{2}J(x(1),x(2),...,x(nm))=21i=1∑nmj:r(i,j)=1∑(w(j)⋅x(i)+b(j)−y(i,j))2+2λi=1∑nmk=1∑n(xk(i))2
结合参数和特征的代价函数
minw(1),...,w(nu)b(1),...,b(nu)x(1),...,x(nm)J(w,b,x)=12∑j:r(i,j)=1(w(j)⋅x(i)+b(j)−y(i,j))2+λ2∑j=1nu∑k=1n(wk(j))2+λ2∑i=1nm∑k=1n(xk(i))2 \begin{gathered} min \\\\ w^{(1)}, \ldots, w^{(n_{u})} \\\\ b^{(1)}, \ldots, b^{(n_{u})} \\\\ x^{(1)}, \ldots, x^{(n_{m})} \end{gathered} J(w, b, x) = \frac{1}{2}\sum\limits_{j:r(i, j) = 1}(w^{(j)} \cdot x^{(i)} + b^{(j)} - y^{(i, j)})^{2} + \frac{\lambda}{2}\sum\limits_{j = 1}^{n_{u}}\sum\limits_{k = 1}^{n}(w_{k}^{(j)})^{2} + \frac{\lambda}{2}\sum\limits_{i = 1}^{n_{m}}\sum\limits_{k = 1}^{n}(x_{k}^{(i)})^{2} minw(1),...,w(nu)b(1),...,b(nu)x(1),...,x(nm)J(w,b,x)=21j:r(i,j)=1∑(w(j)⋅x(i)+b(j)−y(i,j))2+2λj=1∑nuk=1∑n(wk(j))2+2λi=1∑nmk=1∑n(xk(i))2
梯度下降
wi(j)=wi(j)−αδδwi(j)J(w,b,x)b(j)=b(j)−αδδb(j)J(w,b,x)xk(i)=xk(i)−αδδxk(i)J(w,b,x) \begin{aligned} w_{i}^{(j)} = w_{i}^{(j)} - \alpha\frac{\delta}{\delta w_{i}^{(j)}} J(w, b, x) \\\\ b^{(j)} = b^{(j)} - \alpha\frac{\delta}{\delta b^{(j)}} J(w, b, x) \\\\ x_{k}^{(i)} = x_{k}^{(i)} - \alpha \frac{\delta}{\delta x_{k}^{(i)}} J(w, b,x) \end{aligned} wi(j)=wi(j)−αδwi(j)δJ(w,b,x)b(j)=b(j)−αδb(j)δJ(w,b,x)xk(i)=xk(i)−αδxk(i)δJ(w,b,x)
二元标签
此时不再有数字/等级评分,而仅包含喜欢/不喜欢两种可能性(相当于从线性回归变成逻辑回归)。
代价函数
预测真实标签:
- y(i,j):fw,b,x(x)=g(w(j)⋅x(i)+b(j))y^{(i, j)}: f_{w, b, x}(x) = g(w^{(j)} \cdot x^{(i)} + b^{(j)})y(i,j):fw,b,x(x)=g(w(j)⋅x(i)+b(j))
代价函数:
- L(fw,b,x(x),y(i,j))=−y(i,j)log(fw,b,x(x))−(1−y(i,j))log(1−fw,b,x(x))L(f_{w, b, x}(x), y^{(i, j)}) = -y^{(i, j)}log(f_{w, b, x}(x)) - (1 - y^{(i, j)})log(1 - f_{w, b, x}(x))L(fw,b,x(x),y(i,j))=−y(i,j)log(fw,b,x(x))−(1−y(i,j))log(1−fw,b,x(x))
- J(w,b,x)=∑(i,j):r(i,j)=1L(f(w,b,x)(x),y(i,j))J(w, b, x) = \sum\limits_{(i, j) : r(i, j) = 1} L(f_{(w, b, x)}(x), y^{(i, j)})J(w,b,x)=(i,j):r(i,j)=1∑L(f(w,b,x)(x),y(i,j))
均值归一化
当某个用户初次出现,即还未完成任何评分,那么对该用户数据进行训练可能得到的w,x,bw, x, bw,x,b均为000,此时若对该用户对电影的评分进行预测,那么结果就会为000,但这样显然是不太合理的,我们不能认为未进行评分的用户的默认评分都是000。
因此对每个电影获得的评分取均值,即得到了一个向量μ⃗=μ1,...,μm\vec{\mu} = \\mu_1, \\ldots, \\mu_{m}μ =μ1,...,μm
然后修改对于用户jjj,对于电影iii的评分的预测结果为:
- w(j)⋅x(i)+b(j)+μiw^{(j)} \cdot x^{(i)} + b^{(j)} + \mu_{i}w(j)⋅x(i)+b(j)+μi
即让预测的评分以得分均值来作为基准。
Tips: 得到的数据矩阵可以根据具体情况来决定按行均值归一还是按列均值归一
TensorFlow 实现
例:使用TensorFlow完成梯度下降
当代价函数为J=(wx−1)2J = (wx - 1)^{2}J=(wx−1)2时,此时f(x)=wx,y=1f(x) = wx, y = 1f(x)=wx,y=1,使用TensorFlow进行梯度下降的代码实现如下:
python
#表明w为需要优化的参数,同时初始值为3
w = tf.Variable(3.0)
x = 1.0
y = 1.0
alpha = 0.01
# 设定进行30次梯度下降
iterations = 30
for iter in range(iterations):
# 记录成本j所需的操作序列,并存入tape中
with tf.GradientTape() as tape:
# fwb实际上就是f(x)
fwb = w * x
# costJ就是代价函数
costJ = (fwb - y) ** 2
# 计算导数项dJdw,并指定对w求导
[dJdw] = tape.gradient(costJ, [w])
# 更新参数w
w.assign_add(-alpha * dJdw)使用梯度下降进行协同过滤
python
# 使用Adam优化器,并指定学习率为0.1
optimizer = keras.optimizers.Adam(learning_rate = 1e-1)
iterations = 200
for iter in range(iterations):
with tf.GradientTape() as tape:
#3个需要优化的参数X,W,b,均值归一化的评分向量ynorm,表明是否有评分的矩阵R,以及用户,电影数量
cost_value = cofiCostFuncV(X, W, b, Ynorm, R, num_users, num_movies, lambda)
grads = tape.gradient(cost_value, [X, W, b])
# zip函数将数字重新排列成适合应用梯度函数的顺序
optimizer.apply_gradients(zip(grads, [X, W, b]))查找相似内容
当我们想要找到与第iii个样本相似的样本,即找到某个样本kkk,该样本的特征x⃗(k)\vec{x}^{(k)}x (k)与x⃗(i)\vec{x}^{(i)}x (i)相似(即值接近)。
那么怎么判断这两个特征是否相似呢?可以做以下运算:
- ∑l=1n(xl(k)−xl(i))2\sum\limits_{l = 1}^{n}(x_{l}^{(k)} - x_{l}^{(i)})^{2}l=1∑n(xl(k)−xl(i))2
协同过滤局限性
- 冷启动问题处理不佳
- 对于一个新产品,并且用户评价很少,怎么进行评分呢?
- 没有自然的使用侧面学习或有关项目/用户的附加信息
- 你可能知道很多用户的信息,但是并没有被使用到预测中
基于内容的过滤
协同过滤 vs 基于内容的过滤
协同过滤:
- 基于用户给出的评分进行推荐
基于内容的过滤:
- 根据用户的特征和电影的特征进行推荐,无需用户给出评分
深度学习(基于内容的过滤)
用户网络:
输入用户特征xux_{u}xu,输出描述用户的向量vuv_{u}vu
电影向量:
输入电影特征xmx_{m}xm,输出描述电影的向量vmv_{m}vm
预测结果:
- vu⋅vmv_{u} \cdot v_{m}vu⋅vm
- g(vu⋅vm)g(v_{u} \cdot v_{m})g(vu⋅vm)用于预测y(i,j)y^{(i, j)}y(i,j)为111的可能性
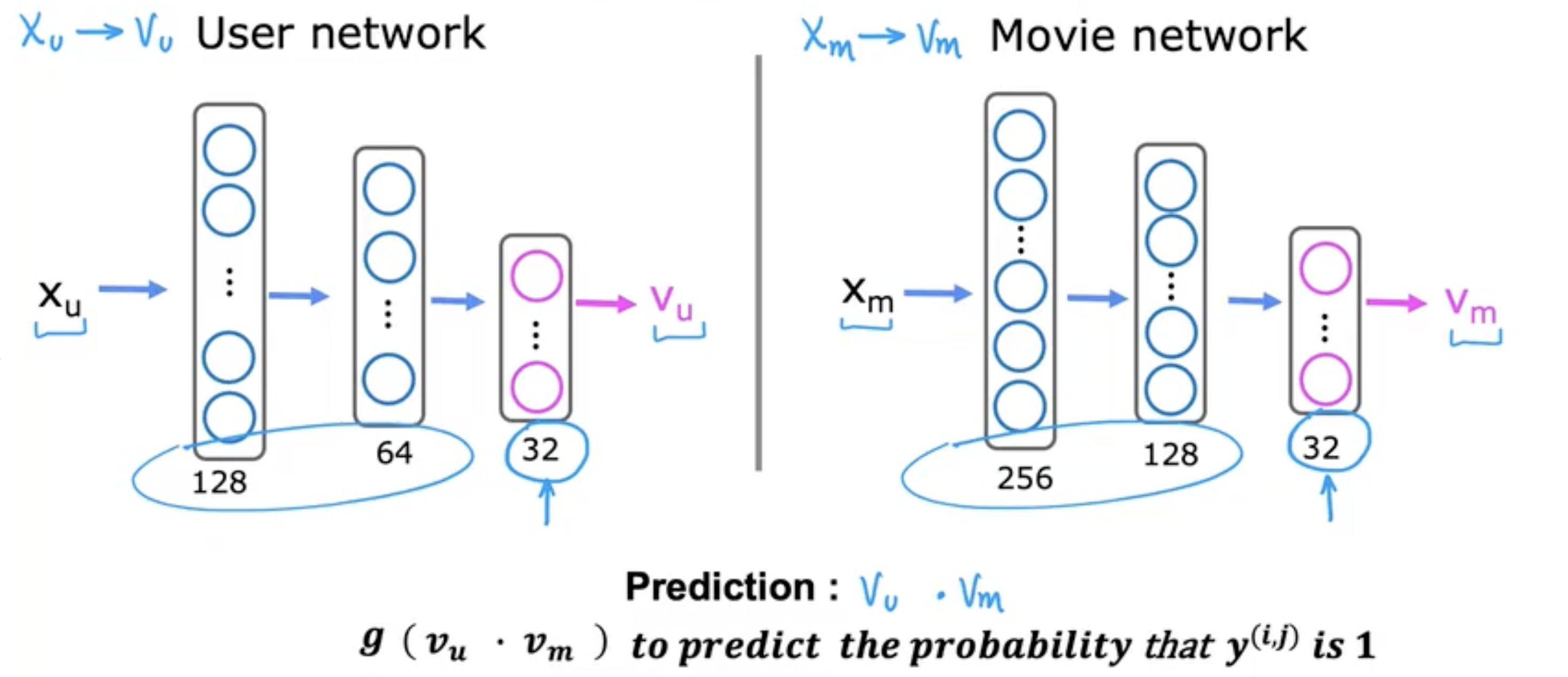
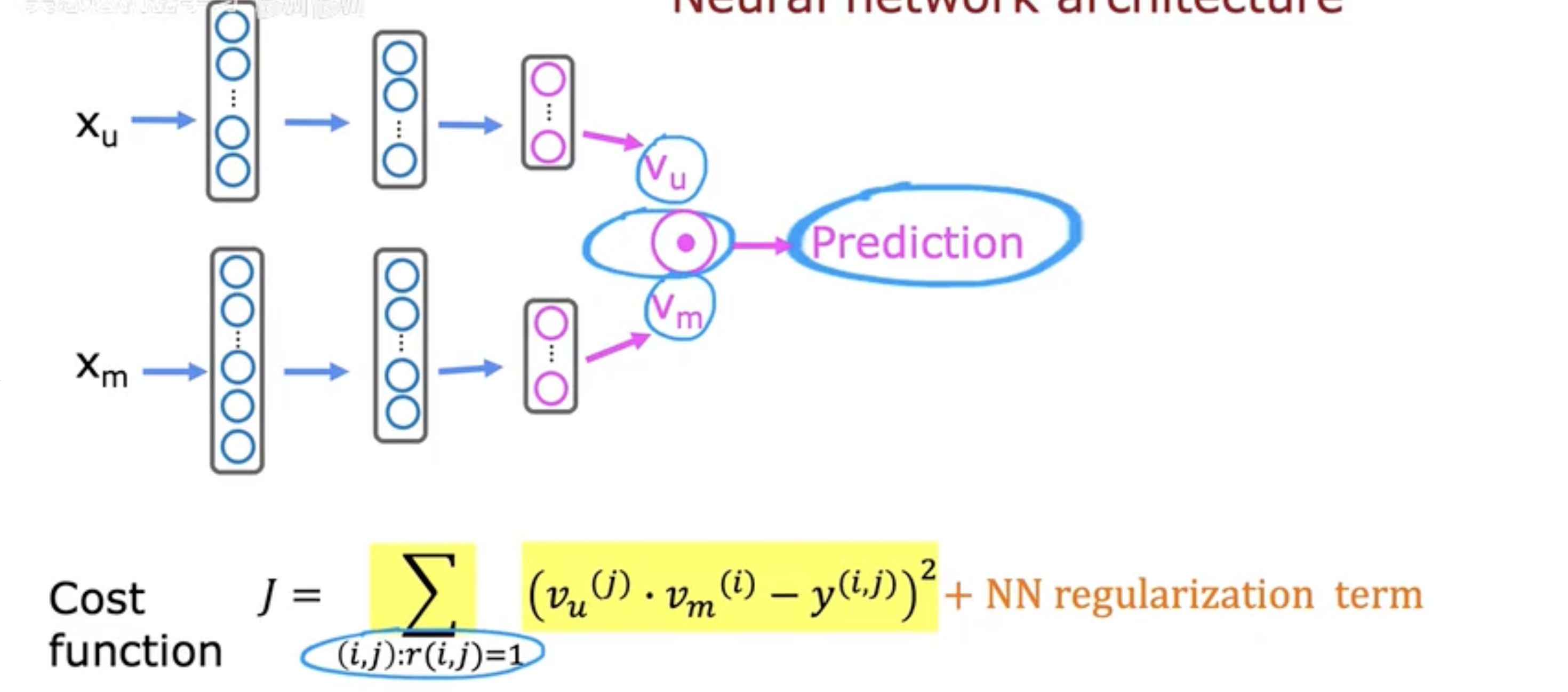
如下图,结合两个神经网络用于预测。
此时代价函数为:
- J=∑(i,j):r(i,j)=1(vu(j)⋅vm(i)−y(i,j))2+NN regularization termJ = \sum\limits_{(i, j):r(i, j) = 1}(v_{u}^{(j)} \cdot v_{m}^{(i)} - y^{(i, j)})^{2} + \text{NN regularization term}J=(i,j):r(i,j)=1∑(vu(j)⋅vm(i)−y(i,j))2+NN regularization term
从大目录中选取物品推荐
- 检索
- 生产一个包含大量可能推荐项目候选的列表,以覆盖可能推荐的内容
- 对于用户最近观看的101010部电影,找到最相似的101010个电影
- 根据用户观看最多的333个类型进行补充,找到最热门的101010部电影
- 找到用户所在国家最热门的202020部电影
- 去处重复想并去除用户已经看过/购买过的电影
- 生产一个包含大量可能推荐项目候选的列表,以覆盖可能推荐的内容

- 排名
- 检索获取的列表,利用训练好的模型进行排序
- 根据预测用户将会给出的最高评分向用户展示
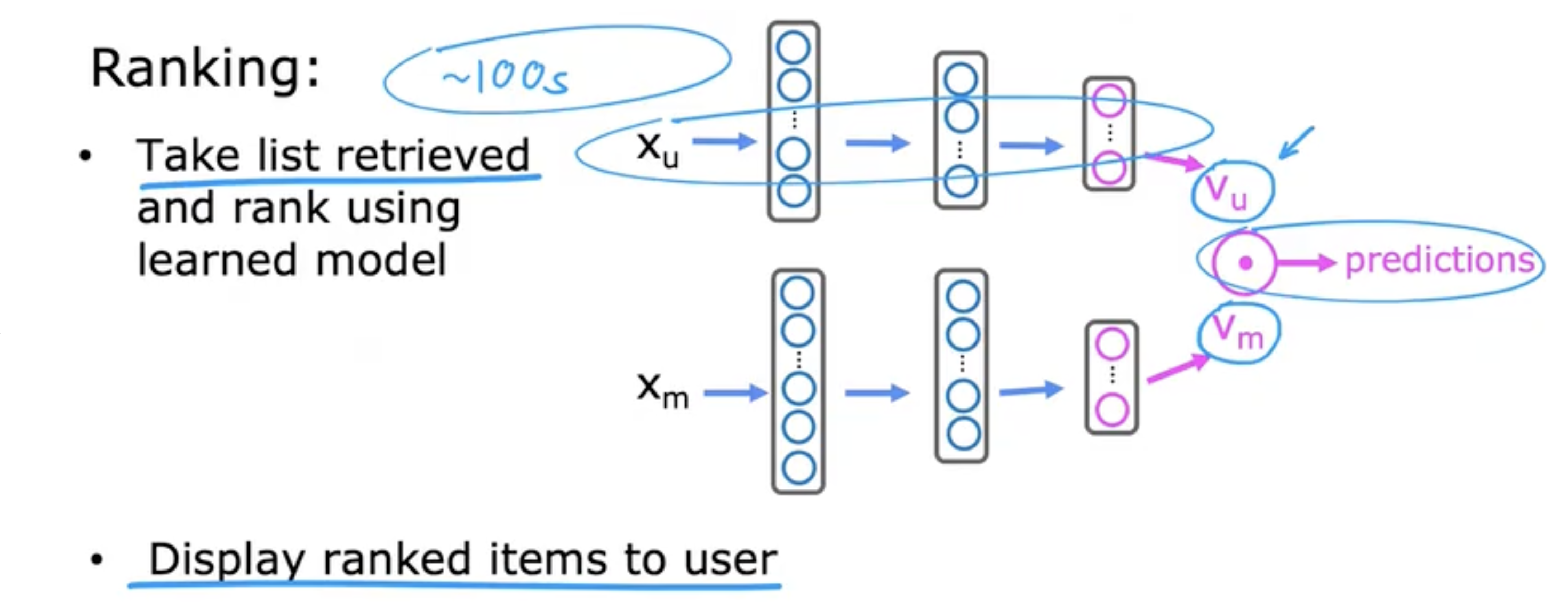
TensorFLow实现
python
import tensorflow as tf
user_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation = 'relu'),
tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(32)
])
item_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation = 'relu'),
tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(32)
])
# 提取特征并输入到神经网络中
input_user = tf.keras.layers.Input(shape = (num_user_features))
vu = user_NN(input_user)
# vu = tf.linalg.l2_normalize(vu, axis = 1)
# 矢量归一化使其长度为1(L2归一化)
vu = tf.math.l2_normalize(vu, axis = 1)
input_item = tf.keras.layers.Input(shape = (num_item_features))
vm = user_NN(input_item)
# vu = tf.linalg.l2_normalize(vu, axis = 1)
vm = tf.math.l2_normalize(vm, axis = 1)
# 计算最终预测
output = tf.keras.layers.Dot(axes = 1)([vu, vm])
# 声明这是一个以用户和电影特征为输入的模型,同时输出为上面定义的输出
model = Model([input_user, input_item, output])
# 使用均方差损失函数
cost_fn = tf.keras.losses.MeanSquaredError()强化学习(Reinforcement learning)
什么是强化学习?
-
你只需要去告诉计算机需要做什么,而不需要去告诉它该怎么做。
-
指定奖励函数而不是最优动作。
- 例:对于直升机:
- 如果它飞的很好,可以每秒给它一个奖励。
- 如果它飞的不好,可以每秒给一个负的奖励。
- 如果它坠毁了,给它一个极大的负奖励。
- 例:对于直升机:
回报(return)
定义
回报即衡量智能体从某一时刻开始,未来能获得的奖励总和。
折扣因子
折扣因子通常用希腊字母γ\gammaγ(gamma) 表示,取值范围在0,10, 10,1之间,核心作用是衡量 "未来奖励" 相对于 "即时奖励" 的重要性:
- 当γ\gammaγ接近111时:智能体更"看重未来",会优先考虑长期收益(比如为了后续获得100100100分奖励,愿意暂时接受当前000分甚至少量负分)
- 当γ\gammaγ接近000时:智能体更"关注当下",只重视即时奖励(比如只在意当前步的得分,忽略后续可能的高奖励)
决策与策略制定
π\piπ函数
输入状态sss,输出策略aaa,即π(s)=a\pi(s) = aπ(s)=a。
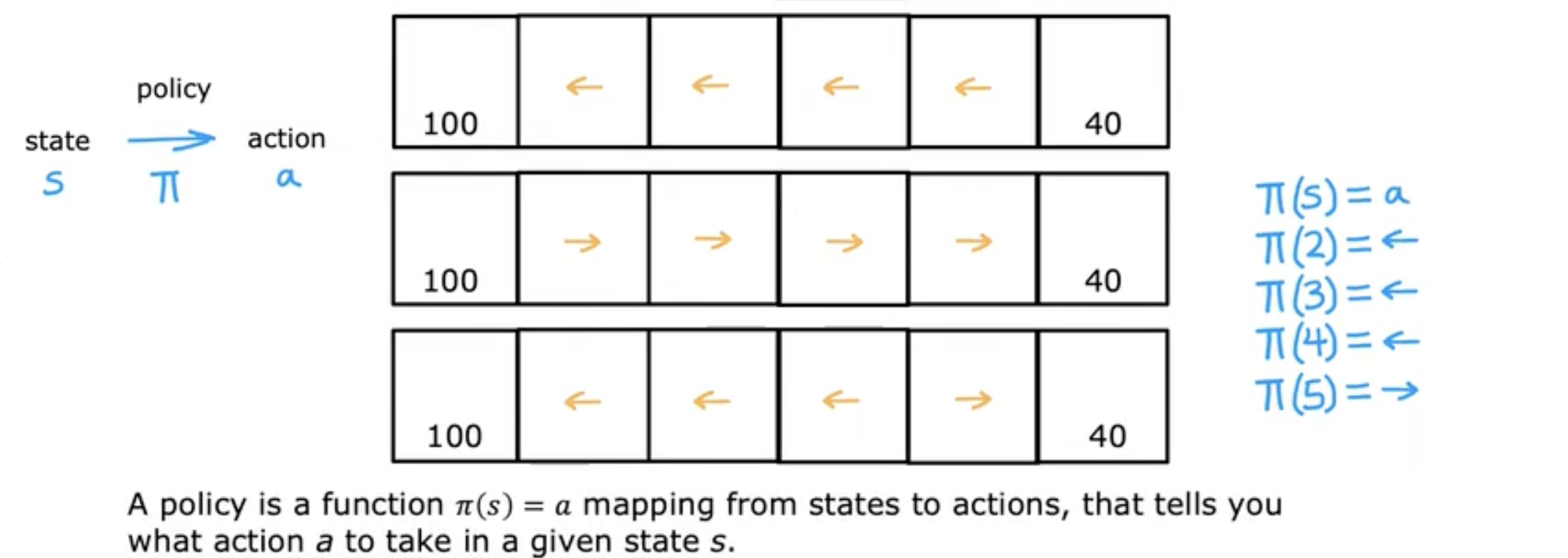
强化学习的目标就是找到一个策略π\piπ告诉你在任何状态(s)(s)(s)下的行动(a=π(s))(a = \pi(s))(a=π(s))使得获得的回报最大。
关键概念
states(状态)
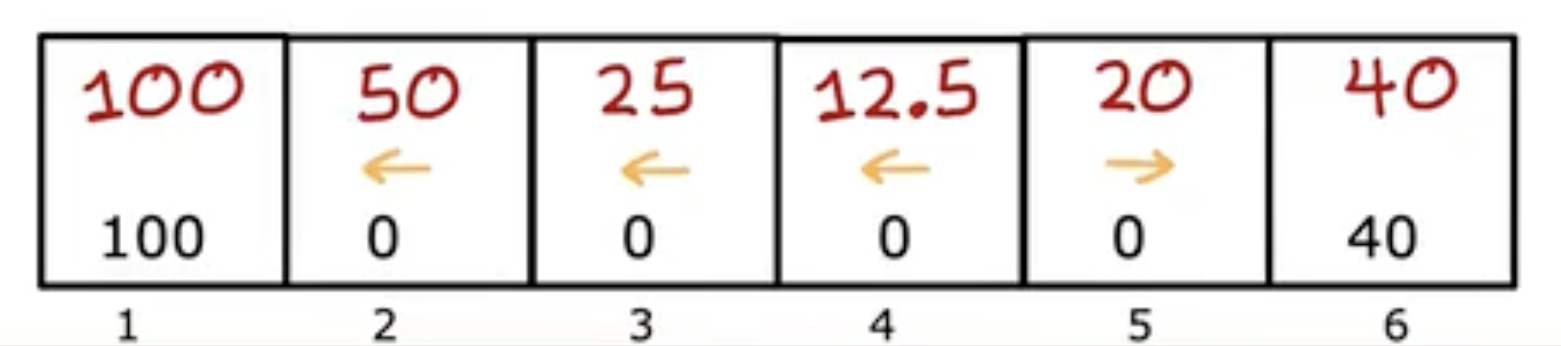
- Mars rover(火星探测器):6种状态
- Helicopter(直升机):直升机的位置
- Chess(国际象棋):棋子的位置
actions(动作集合)
- Mars rover(火星探测器):左/右移动
- Helicopter(直升机):移动直升机控制杆的所有可能方式
- Chess(国际象棋):合法的移动方式
rewards(奖励)
- Mars rover(火星探测器):100, 0, 40
- Helicopter(直升机):+1, -1000
- Chess(国际象棋):+1, 0, -1
discount factor γ\gammaγ(折扣因子)
- Mars rover(火星探测器):0.5
- Helicopter(直升机):0.99
- Chess(国际象棋):0.995
return(回报)
- Mars rover(火星探测器):R1+γR2+γ2R3+...R_{1} + \gamma R_{2} + \gamma^{2} R_{3} + \ldotsR1+γR2+γ2R3+...
- Helicopter(直升机):R1+γR2+γ2R3+...R_{1} + \gamma R_{2} + \gamma^{2} R_{3} + \ldotsR1+γR2+γ2R3+...
- Chess(国际象棋):R1+γR2+γ2R3+...R_{1} + \gamma R_{2} + \gamma^{2} R_{3} + \ldotsR1+γR2+γ2R3+...
policy π\piπ(π\piπ策略)
- Mars rover(火星探测器):
- Helicopter(直升机):找到策略π(s)=a\pi(s) = aπ(s)=a
- Chess(国际象棋):找到策略π(s)=a\pi(s) = aπ(s)=a
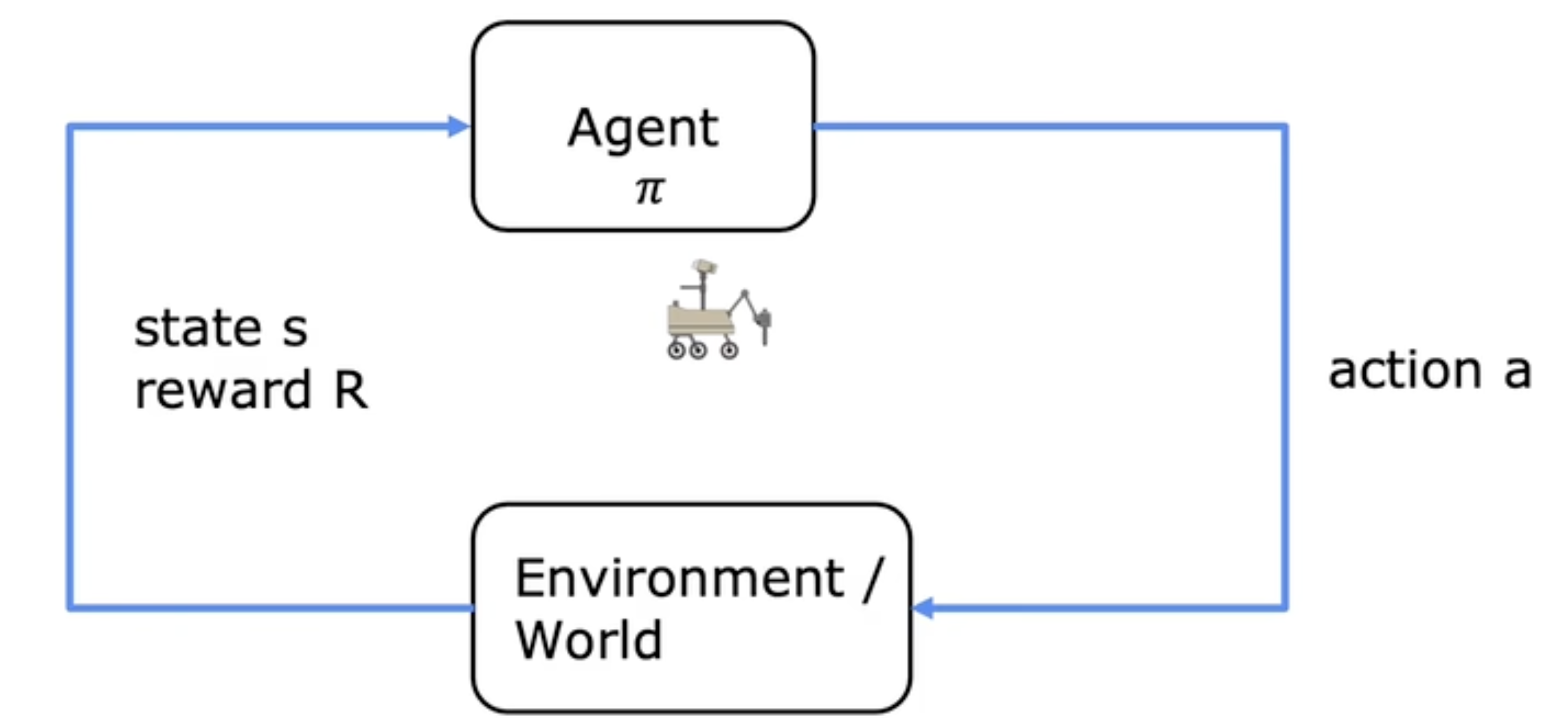
Markov Decision Process(MDP)(马尔可夫决策过程)
未来只取决于你现在所处的位置,而不是你是如何到达这里的。
状态动作价值函数
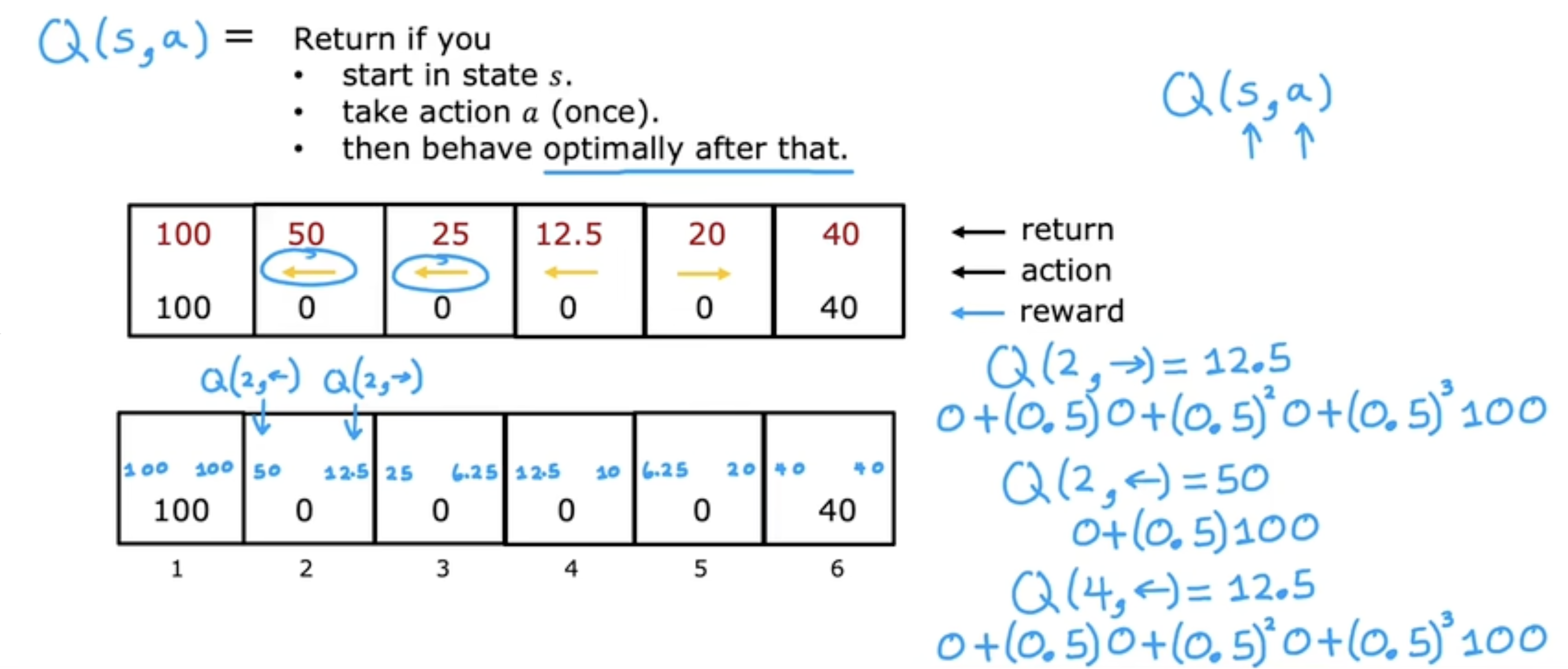
定义(Q-function)
Q(s,a)=Return if you⋅开始于状态s⋅采取行动a(一次)⋅此后均采取最优行为 Q(s, a) = \begin{array}{l} \quad \text{Return if you} \\\\ \quad \cdot \quad \text{开始于状态s} \\\\ \quad \cdot \quad \text{采取行动a(一次)} \\\\ \quad \cdot \quad \text{此后均采取最优行为} \end{array} Q(s,a)=Return if you⋅开始于状态s⋅采取行动a(一次)⋅此后均采取最优行为
策略选择:
- 在状态sss能获得的最大回报为maxaQ(s,a)\mathop{max}\limits_{a} Q(s, a)amaxQ(s,a)
- 状态sss最好的行动aaa是能够最大化QQQ值的maxaQ(s,a)\mathop{max}\limits_{a} Q(s, a)amaxQ(s,a)
火星探测车代码示例
python
import numpy as np
from utils import *
# 状态/动作数量
num_states = 6
num_actions = 2
# 奖励
terminal_left_reward = 100
terminal_right_reward = 40
each_step_reward = 0
# 折扣因子
gamma = 0.5
# 走向错误方向的可能性
misstep_prob = 0
generate_visualization(terminal_left_reward, terminal_right_reward, each_step_reward, gamma, misstep_prob)Bellman Equationb(贝尔曼方程)
定义:
- R(s)R(s)R(s) :当前状态能获得的奖励
- sss : 当前状态
- aaa :当前行动
- s′s^{\prime}s′ :行动aaa之后到达的状态
- a′a^{\prime}a′ :在状态s′s^{\prime}s′将采取的行动
- Q(s,a)=R(s)+γ maxa′Q(s′,a′)Q(s, a) = R(s) + \gamma \; \mathop{max}\limits_{a^{\prime}}Q(s^{\prime}, a^{\prime})Q(s,a)=R(s)+γa′maxQ(s′,a′)
随机环境
状态随机转移:
即执行动作后,转移到的新状态不确,如:
- 执行向右移动时:
- 有90%90\%90%的概率向右走(目标方向)
- 有10%10\%10%的概率向左走(反方向)
期望回报:
- 期望回报
- = Average(R1+γR2+γ2R3+γ3R4+...)Average(R_{1} + \gamma R_{2} + \gamma^{2} R_{3} + \gamma^{3} R_{4} + \ldots)Average(R1+γR2+γ2R3+γ3R4+...)
- = ER1+γR2+γ2R3+γ3R4+...ER_{1} + \\gamma R_{2} + \\gamma\^{2} R_{3} + \\gamma\^{3} R_{4} + \\ldotsER1+γR2+γ2R3+γ3R4+...
AverageAverageAverage即在随机环境下采取策略尝试很多次(如上千次),所获的的平均奖励,也就是期望回报。
随机强化学习中的贝尔曼方程:
- Q(s,a)=R(s)+γ Emaxa′Q(s′,a′)Q(s, a) = R(s) + \gamma \; E\\mathop{max}\\limits_{a\^{\\prime}}Q(s\^{\\prime}, a\^{\\prime})Q(s,a)=R(s)+γEa′maxQ(s′,a′)
连续状态空间应用
直升机
状态:
- x,y,zx, y, zx,y,z : 位置
- ϕ\phiϕ :滚转(左右翻转)
- θ\thetaθ :俯仰角
- ω\omegaω :偏航
- x˙,y˙,z˙,ϕ˙,θ˙,ω˙\dot{x}, \dot{y}, \dot{z}, \dot{\phi}, \dot{\theta}, \dot{\omega}x˙,y˙,z˙,ϕ˙,θ˙,ω˙ :对应状态的速度
月球着陆器
操作:
- 什么都不做
- 左侧推进器:推动着陆器向右移动
- 右侧推进器:推动着陆器向左移动
- 主引擎:推动着陆器向上移动
对应状态向量;
s=xyx˙y˙θθ˙lr s = \left \\begin{aligned} x \\\\ y \\\\ \\dot{x} \\\\ \\dot{y} \\\\ \\theta \\\\ \\dot{\\theta} \\\\ l \\\\ r \\end{aligned} \\right s= xyx˙y˙θθ˙lr
- x,yx, yx,y :横坐标和纵坐标
- x˙,y˙\dot{x}, \dot{y}x˙,y˙ :在横坐标和纵坐标上的移动速度
- θ\thetaθ : 着陆器机身的角度
- θ˙\dot{\theta}θ˙ : 着陆器机身的角度的变化速度(角速度)
- l,rl, rl,r :左右腿是否接触地面
奖励函数:
- 成功抵达平台:100∼140100 \sim 140100∼140
- 朝向或原理平台情况:靠近加分,远离扣分
- 坠毁:−100-100−100
- 软着陆: +100+100+100
- 腿着陆:+10+10+10
- 使用主引擎一次:−0.3-0.3−0.3
- 使用单侧推进器一次(左右推进器之一):−0.03-0.03−0.03
学习策略:
目标为学习一个策略π\piπ,对于给定状态:
s=xyx˙y˙θθ˙lr s = \left \\begin{aligned} x \\\\ y \\\\ \\dot{x} \\\\ \\dot{y} \\\\ \\theta \\\\ \\dot{\\theta} \\\\ l \\\\ r \\end{aligned} \\right s= xyx˙y˙θθ˙lr
采取一个行动a=π(s)a = \pi(s)a=π(s),使得回报最大。
此时γ=0.985\gamma = 0.985γ=0.985
学习状态值函数
输入
通过将444个操作转换成独热编码的方式,与状态向量合并为一个向量作为神经网络的输入。
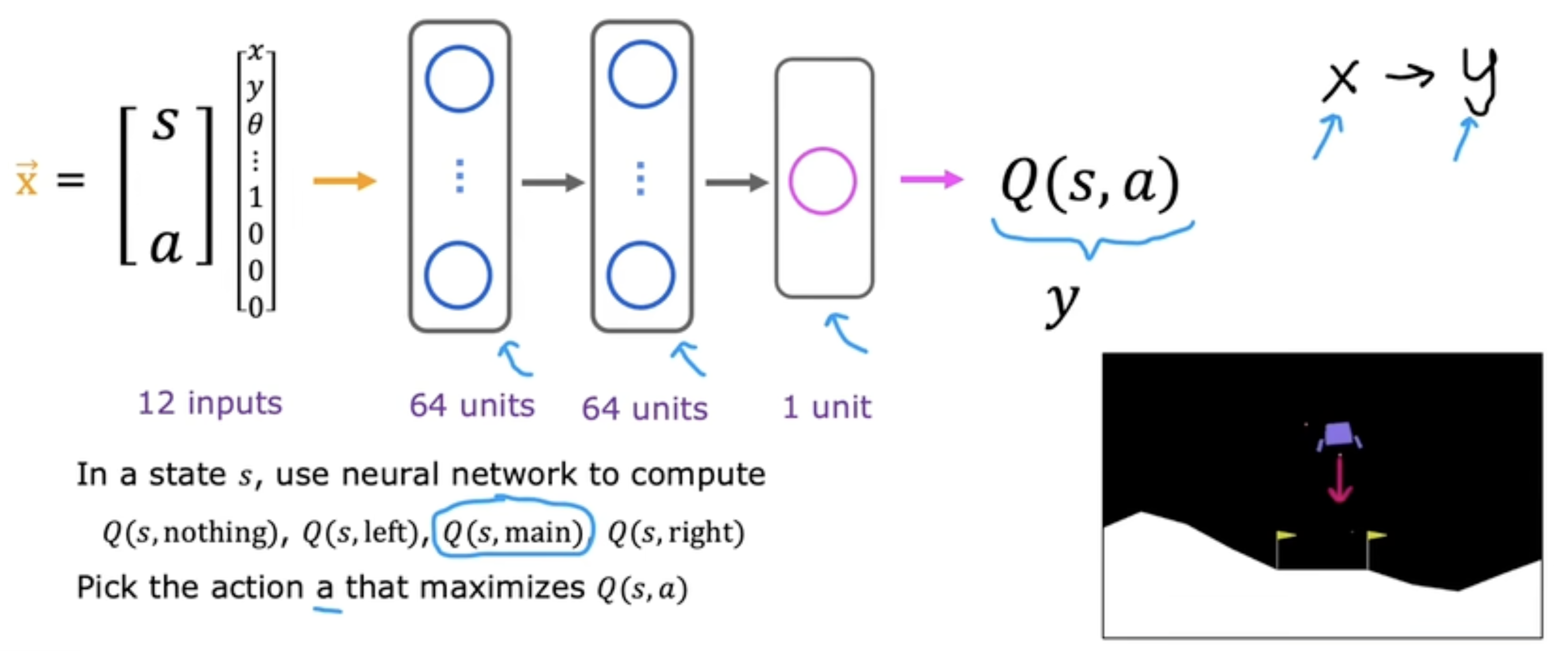
训练集
此时贝尔曼方程为:
Q(s,a)⏟x=R(s)+γ maxa′Q(s′,a′)⏟y\mathop{\underbrace{Q(s, a)}}\limits_{x} = \mathop{\underbrace{R(s) + \gamma \; \mathop{max}\limits_{a^{\prime}}Q(s^{\prime}, a^{\prime})}}\limits_{y}x Q(s,a)=y R(s)+γa′maxQ(s′,a′)
此时xxx是已知的,yyy中一部分已知,另一部分则通过神经网络获得。
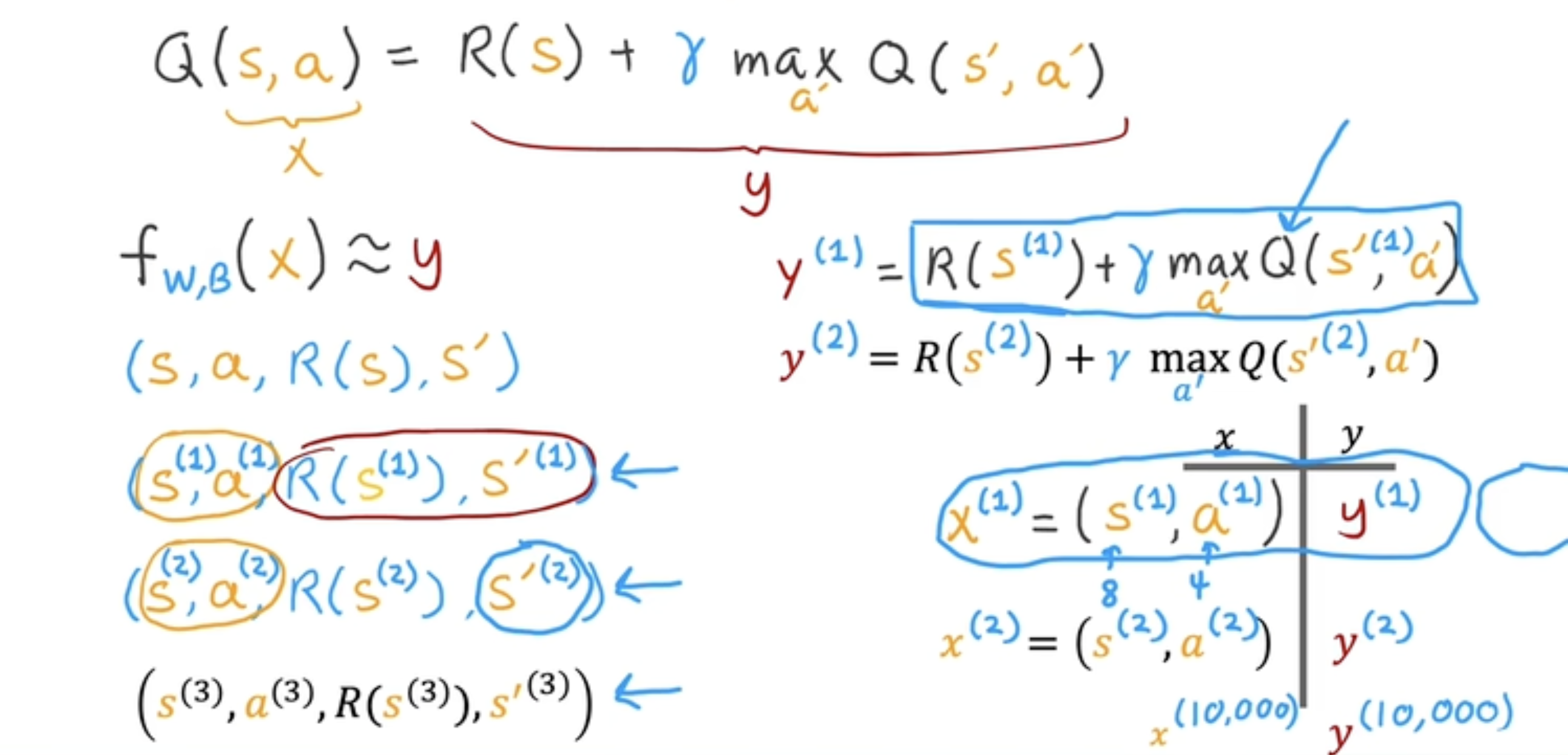
Q-learning算法
- 随机初始化神经网络,将其作为Q(s,a)Q(s, a)Q(s,a)的初始猜测
- 重复执行以下步骤
- 在月球登陆器中执行行动,获取元组(s,a,R(s),s′)(s, a, R(s), s^{\prime})(s,a,R(s),s′)
- 存储最近的100001000010000个(s,a,R(s),s′)(s, a, R(s), s^{\prime})(s,a,R(s),s′)元组(存入经验回放池中)
- 训练神经网络:
- 用x=(s,a)x = (s, a)x=(s,a)和y=R(s)+γ maxa′Q(s′,a′)y = R(s) + \gamma \; \mathop{max}\limits_{a^{\prime}} Q(s^{\prime}, a^{\prime})y=R(s)+γa′maxQ(s′,a′)创建100001000010000个样本
- 训练新的网络QnewQ_{new}Qnew,使Qnew(s,a)≈yQ_{new}(s, a) \approx yQnew(s,a)≈y
- 令Q=QnewQ = Q_{new}Q=Qnew
Tips: 以矩阵Ax=yAx = yAx=y为例,此时训练AAA,同时训练完成后迭代更新yyy。

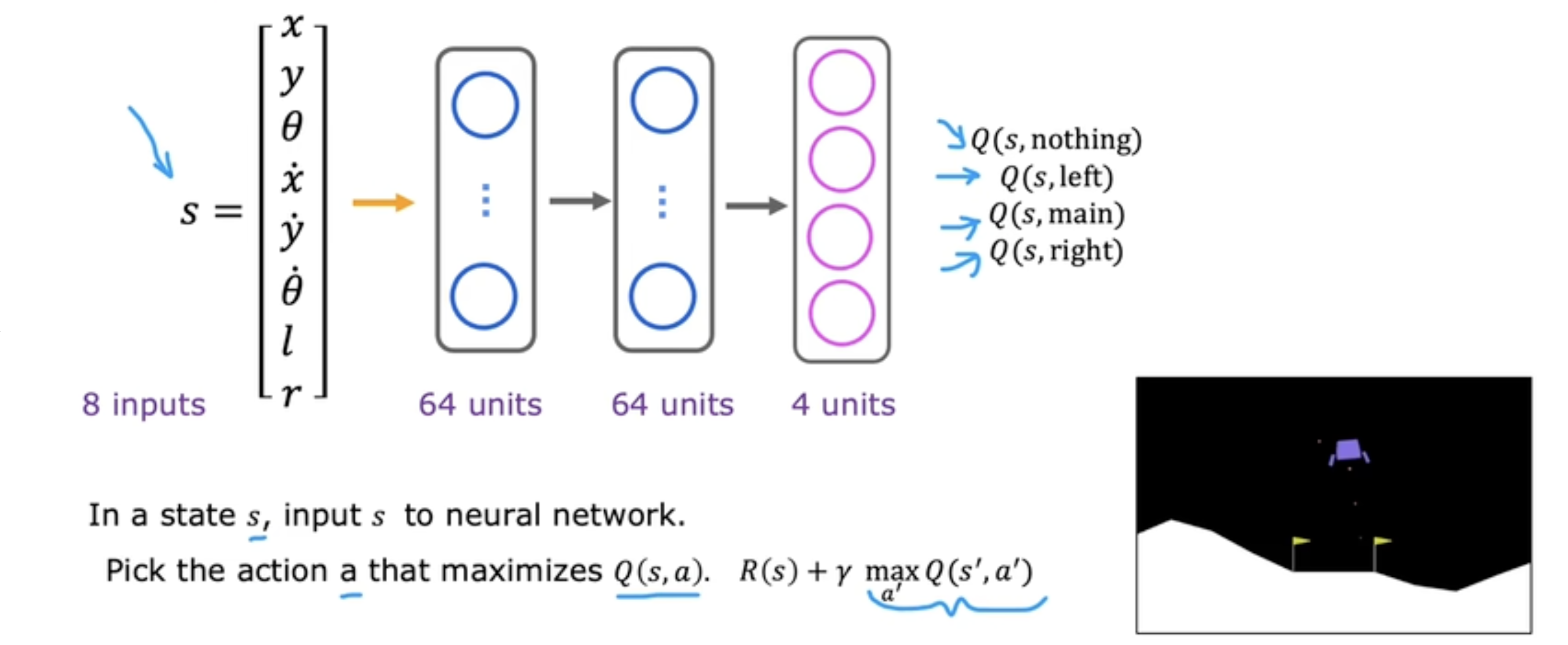
算法优化-改进神经网络结构
原本的神经网络在输入中包含当前的行动,为了提升效率,对神经网络进行修改,在输入中去掉代表当前行动的独热编码,同时将输出层修改成444个神经元,使得神经网络一次推理即可得到444个行动的预测结果。
ϵ\epsilonϵ-贪心
在某些状态sss,有以下两种策略:
- 选项1:
- 选择一个能使得Q(s,a)Q(s, a)Q(s,a)最大的行动aaa
- 选项2(ϵ\epsilonϵ-贪心策略(ϵ=0.05\epsilon = 0.05ϵ=0.05)):
- 在95%95\%95%的概率下,选择一个能使得Q(s,a)Q(s, a)Q(s,a)最大的行动aaa
- 在5%5\%5%的概率下,随机选择一个行动aaa
mini-batch(小批量)
当训练集规模很大时,梯度下降算法就会变得很慢。
小批量梯度下降的理念是每一步不使用完整的训练集,而仅采取一个较小的子集,每次梯度下降的迭代仅需查看这个较小的子集。
注: 虽然小批量梯度下降不那么可靠,但每次迭代的成本极低。
Soft Update(软更新/自我更新)
在强化学习中,每次迭代将会设置Q=QnewQ = Q_{new}Q=Qnew
这里可以通过自我更新对参数进行渐进性的修改:
- W=0.01Wnew+0.99WW = 0.01W_{new} + 0.99WW=0.01Wnew+0.99W
- B=0.01Bnew+0.99BB = 0.01B_{new} + 0.99BB=0.01Bnew+0.99B
Tips: 通过自我更新方式可以使得强化学习算法更快收敛