谙流 ASK 是谙流团队自主研发的国产新一代云原生流平台,与 Apache Kafka 100% 协议兼容,全栈自主可控,专注私有化部署与行业场景赋能。
总体架构
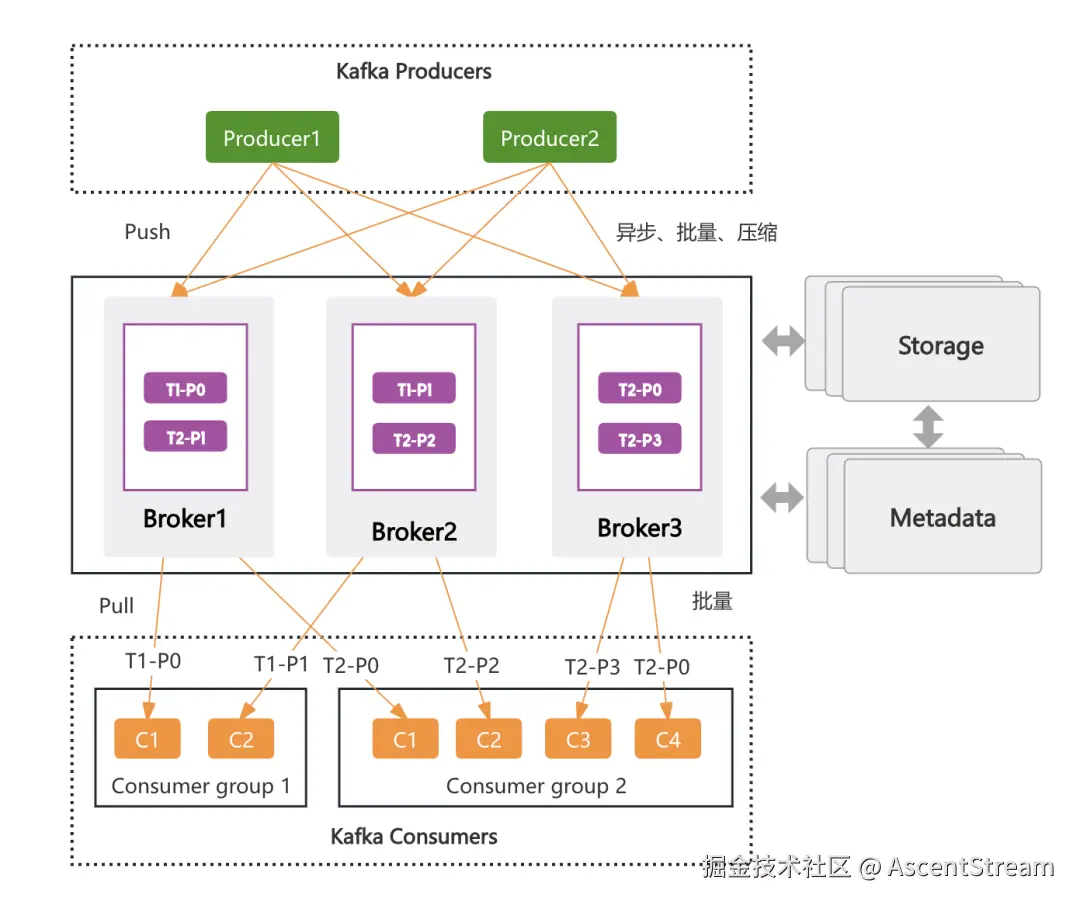
-
Broker:ASK 计算引擎负责消息的转发,并对外提供服务。通过增加或删除 Broker 节点,实现计算层的扩缩容。Topic 是 ASK 对外提供服务的基本单位,通过对 Topic 进行分区,使不同的分区分配到整个 Broker 集群上,从而利用更多 Broker 的能力,最终实现了业务级的水平扩展。
-
Storage: ASK 存储引擎负责真正的数据持久化存储,采用分片存储模型,消息打散均匀分布到整个存储集群汇中。同时,支持秒级平滑扩容,实现存储层的水平扩展,并能处理海量消息积压。
-
Metadata:负责存储分片、Topic 等元数据信息,并且承担了一部分协调选主的功能,可以简单的将其理解为 ASK 集群的配置管理中心,压力比较小,一般不会成为集群的瓶颈点进而制约集群的水平扩展能力。
-
Produces: 支持连接复用、批量异步发送,还支持端到端压缩以减少网络数据传输,并提升性能。
-
Consumers: 基于分区的消费组模型,通过扩容分区实现业务级的水平扩展。
无锁模型
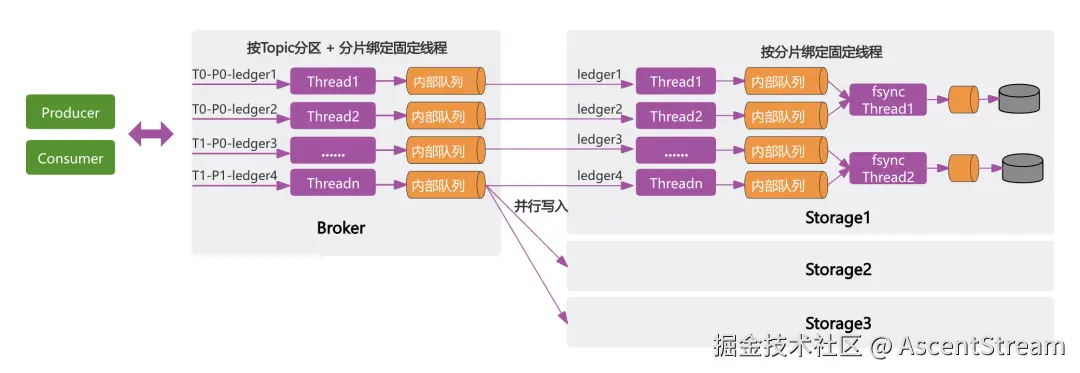
-
Reactor模型:基于 Netty 实现的 Reactor 模型,其包含一个网络线程池,负责处理网络请求,完成数据收发和编解码;业务逻辑处理则由一个业务线程池处理,充分利用现代系统的多核优势,极大地提高系统效率。
-
Broker无锁化:生产消费根据路由机制找到对应的Broker,Broker收到请求后按照 Topic 的分片参数,通过 Hash 算法绑定至固定线程,确保同一分片的数据处理逻辑在单一线程内完成,避免线程切换。同时,这种方式也隔离了任务分配,从而避免所有线程争抢请求任务,防止请求饥饿。
-
Storage无锁化:Producer/Consumer 向 Broker 发起消息读写网络请求,Broker 转发请求至 Storage 层,由 Storage 真正地对数据进行持久化存储。与 Broker 无锁化机制类似,Storage 基于分片 ID 通过哈希算法将请求分配至固定线程。ASK 采用顺序 I/O 模型,确保同一个磁盘的数据由专用 fsync 线程全局顺序写入。
基于无锁模型,固定线程的哈希映射,将全局竞争拆解为线程内串行;多级并行(线程/存储节点)充分压榨硬件性能,逼近物理极限,实现更强的性能和更稳定的延迟。
读写IO隔离
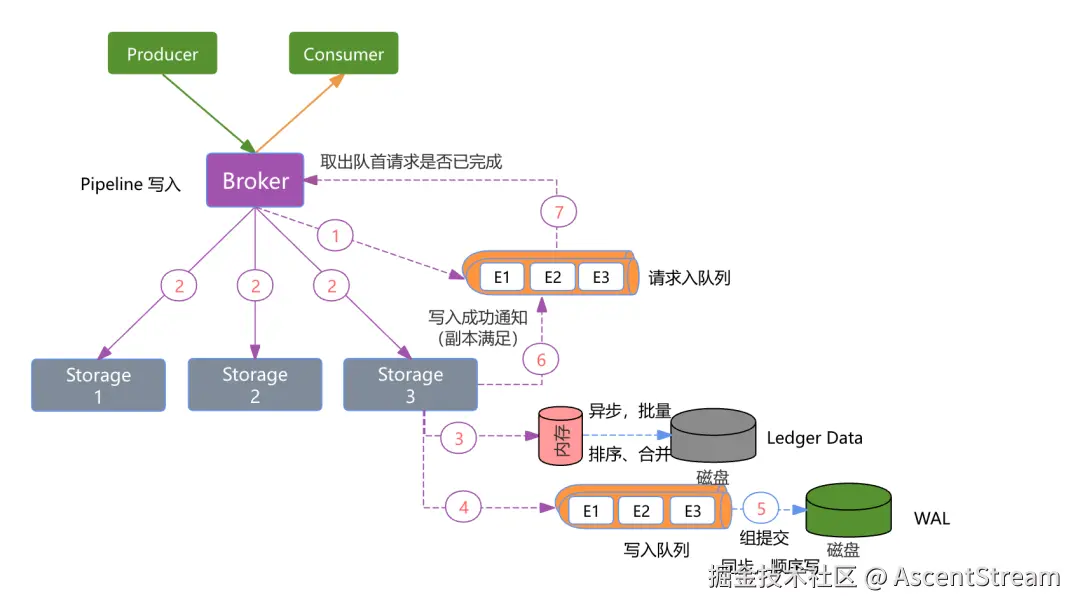
**
**
影响性能的主要因素是副本复制的效率以及读写I/O的模型。
-
并发副本写入:Apache Kafka 的 ISR 模型中,数据需先写入 Leader Broker,再由 Leader 通知 Follower 节点异步拉取,该模式的复制效率较低。尤其在数据可靠性要求高的场景下,Follower 副本的复制延迟会导致生产耗时显著增加。ASK 采用更高并发的模式,数据同时写入多个副本,只需满足预设的最小副本成功写入数即返回成功,这种机制大幅提升效率并降低延迟。
-
独立写入IO:ASK 的 I/O 模型与 Apache Kafka 存在显著差异。为保障高性能与低延迟,其存储层分为两部分,一部分是 WAL(预写日志),写入流程中只要数据成功追加至 WAL 即视为副本持久化成功,WAL 采用追加顺序写,并通过组提交的方式,在性能和延迟平衡。同时基于 Ledger ID 哈希分盘,充分利用多块磁盘提升写入并发,最大化磁盘利用率。 WAL 仅需保留增量日志,主要用于故障恢复时重建一致性状态。因其高吞吐顺序写特性和滚动覆盖机制,实际占用存储极小,可部署于专用小容量磁盘。
-
独立读取IO:另外一部分是 Ledger 数据,Ledger 数据存储采用异步持久化设计。数据写入内存即完成步骤 3 的响应,真正的数据存储在 Ledger 对应的磁盘。Ledger 数据不用像 WAL 一样,优先写入到内存中,根据设定的写入策略异步批量写入到磁盘(例如内存写满了则一次性刷盘)。由于混合分片写入,虽然保证了顺序写,但会带来随机读的情况,为了缓解随机读的问题,内存的数据会按照 ledger ID 进行排序,将相同 ledger 的数据尽最大放在一起,从而减少随机读。另外同 WAL 一样,基于 Ledger ID 哈希分盘,利用多块磁盘提升写入并发。
ASK 基于高效的副本异步批量确认机制 (满足最小副本即响应)和组提交压缩技术 ,大幅降低复制延迟;同时采用全局顺序写 I/O 模型,结合内存排序合并与磁盘组提交,最大化磁盘吞吐。此外,存储层分片分盘模型实现线性扩展,彻底规避 I/O 争抢瓶颈。
多级缓存
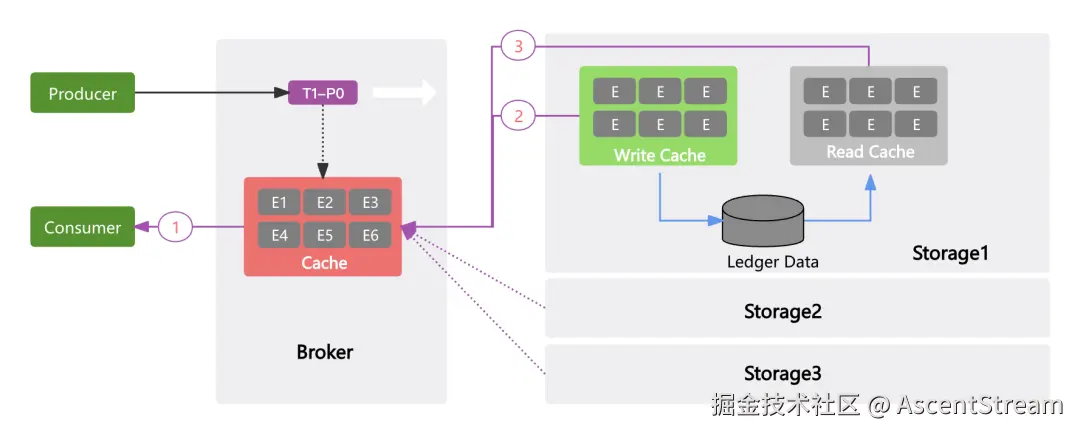
存算分离架构下,消息读取需额外经过 Broker→Storage 的网络调用,为优化此开销,ASK 设计三级缓存:
-
Broker 内存缓存:Producer 消息成功写入后,Broker 将最新写入的数据存入 Cache 模块。为了减少 JVM GC 带来的影响,采用 Netty 的 Recycler 对象池技术进行高效的对象分配和回收,基于 LRU 对缓存的对象进行淘汰。对于追尾读(Tailing Reads)场景,Consumer 直接从该缓存读取(路径①),最大减少读请求穿透至存储层。
-
Storage 写缓存:当出现追赶读(Catch-up Reads)的场景(需要读取历史数据或消费跟不上生产),在 Broker 的 Cache 模块中找不到对应消息时,这时必须穿透到存储层获取数据。在 Storage 层设计了读缓存(Read Cache)和写缓存(Write Cache)。写缓存存放的是当前要刷入Ledger磁盘的数据。查询时,会优先在写缓存中查找消费者需要拉取的数据(路径②)。
-
Storage 读缓存:如果在写缓存中未命中,此时需要真正穿透磁盘去读取数据。ASK 没有重度依赖 Page Cache 技术,而是通过自定义缓存避免因为 Page Cache 换页抖动带来的不可控系统级别问题。为了减少 IO 读取的次数,会批量预读数据到读缓存,为其它消费组共享数据。
-
分散读取:ASK 不会像 Apache Kafka 那样读写的主要压力都集中在 Leader Broker 上。在穿透存储层读取时,ASK 会对该分区的多副本进行分散读取,避免单点热点/ 避免热点集中在单个副本上。
ASK 采用三级缓存机制:Broker 内存拦截热点请求、Storage 内存缓存(Write/Read Cache)减少磁盘读 I/O,通过缓存分层最大化减少额外网络开销和磁盘读取的影响。
实际效果
以下是某客户实际生产环境的流量监控截图,QPS 达到千万级别,日均消息量达万亿级别,消息存储量接近 PB 级。
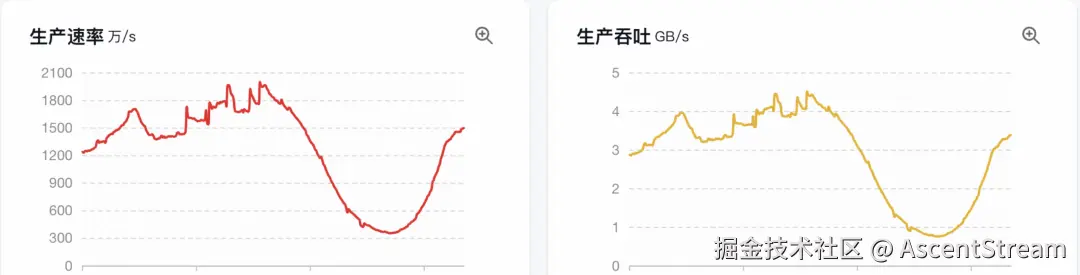
可见 Storage 层写入吞吐量达到读取吞吐量的10 倍以上(实际峰值差距可能更大)。由于消费端资源限制未能扩展到最佳并发度,导致存在持续性消费延迟(表现为尾部延迟持续追赶)。


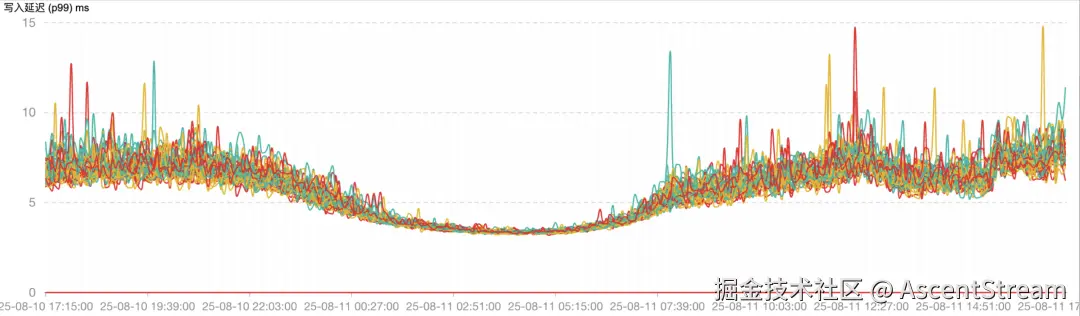
延迟表现保持稳定,P99 延迟控制在 15ms 以内 ,其中主流请求(约95%)的延迟集中在 6-8ms 区间。
结束语
谙流 ASK 以突破性的技术创新重新定义了高性能流处理的标准:
- 架构革命 :通过 存算分离 、无锁模型 和 多级缓存 三大核心设计,彻底解决了传统消息系统的性能瓶颈,实现百万级 TPS 、毫秒级延迟的极致体验。
- 场景赋能 :支持秒级弹性扩缩容、PB 级消息积压、智能副本调度等企业级特性,满足金融、通信、物联网等行业对高并发、低延迟、强一致性的严苛需求。