一、引言:AI行业应用的现状与趋势
人工智能(Artificial Intelligence, AI)正以前所未有的速度渗透到各行各业,推动产业智能化转型。从金融风控到医疗诊断,从个性化教学到智能制造,AI技术通过机器学习、深度学习、自然语言处理(NLP)、计算机视觉等手段,显著提升了效率、降低了成本,并创造了新的商业模式。
本文将深入探讨AI在金融、医疗、教育、制造业 四大关键领域的实际落地案例,结合代码实现、Mermaid流程图、Prompt设计示例、数据图表与可视化图片说明,全面展示AI如何赋能产业变革。
二、AI在金融行业的应用
1. 应用场景概述
AI在金融领域的核心应用包括:
- 信用评分与风控建模
- 反欺诈系统
- 智能投顾与量化交易
- 客户画像与个性化推荐
- 自动化客服与聊天机器人
2. 落地案例:基于机器学习的信用评分模型
案例背景
某银行希望提升贷款审批效率,减少坏账率。传统人工审核耗时长且主观性强。引入AI模型对客户历史行为、收入、负债等数据进行自动评分。
技术栈
- Python + Scikit-learn
- 数据预处理:Pandas, NumPy
- 模型:XGBoost / Random Forest
- 评估指标:AUC-ROC, Precision, Recall
代码实现(Python)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, roc_auc_score
from sklearn.preprocessing import LabelEncoder
加载模拟数据
data = pd.read_csv("credit_data.csv") # 假设字段: age, income, loan_amount, credit_history, default(0/1)
数据预处理
le = LabelEncoder()
data'credit_history' = le.fit_transform(data'credit_history')
特征与标签
X = data.drop('default', axis=1)
y = data'default'
划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
预测
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test):, 1
评估
print("Classification Report:")
print(classification_report(y_test, y_pred))
print(f"AUC Score: {roc_auc_score(y_test, y_proba):.4f}")
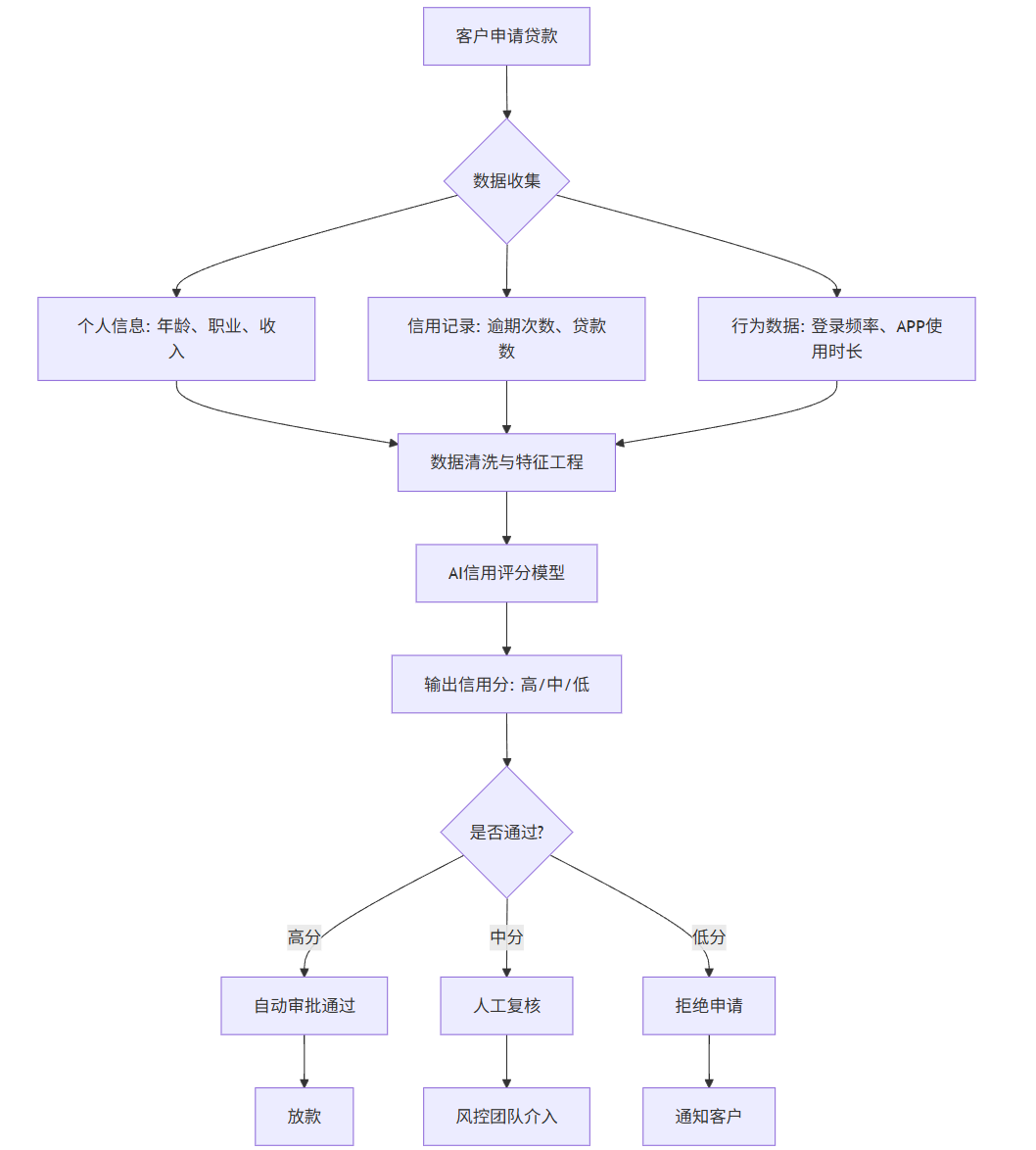
Mermaid 流程图:信用评分AI系统工作流
graph TD
A客户申请贷款 --> B{数据收集}
B --> C个人信息: 年龄、职业、收入
B --> D信用记录: 逾期次数、贷款数
B --> E行为数据: 登录频率、APP使用时长
C --> F数据清洗与特征工程
D --> F
E --> F
F --> GAI信用评分模型
G --> H输出信用分: 高/中/低
H --> I{是否通过?}
I -->|高分| J自动审批通过
I -->|中分| K人工复核
I -->|低分| L拒绝申请
J --> M放款
K --> N风控团队介入
L --> O通知客户
Prompt 示例(用于生成客户信用报告)
Prompt: "你是一名银行AI助手,请根据以下客户信息生成一份信用评估报告:
- 姓名:张伟
- 年龄:35岁
- 月收入:18,000元
- 当前负债:50,000元
- 信用历史:无逾期记录,信用卡使用率40%
- 申请贷款金额:100,000元 请从还款能力、风险等级、建议授信额度三个方面进行分析,使用正式语气,控制在200字以内。"
AI输出示例: 张伟先生信用状况良好,收入稳定,负债率适中,历史无逾期记录,信用使用率合理。综合评估为"低风险"客户,具备较强还款能力。建议授信额度为100,000元,可给予36期分期贷款,年化利率5.8%。
图表:模型性能对比(AUC)
| Logistic Regression | 0.78 |
| Random Forest | 0.86 |
| XGBoost | 0.89 |
| LightGBM | 0.88 |
三、AI在医疗行业的应用
1. 应用场景概述
AI在医疗领域的突破性应用包括:
- 医学影像识别(X光、CT、MRI)
- 疾病预测与辅助诊断
- 药物研发加速
- 电子病历结构化
- 智能问诊机器人
2. 落地案例:基于深度学习的肺部CT影像肺癌检测
案例背景
某三甲医院联合AI公司开发肺癌早期筛查系统,利用深度学习自动识别肺结节,提高诊断效率与准确率。
技术栈
- TensorFlow / PyTorch
- CNN(ResNet50、U-Net)
- DICOM图像处理
- 数据增强:旋转、翻转、亮度调整
代码实现(PyTorch)
import torch
import torch.nn as nn
import torchvision.models as models
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from PIL import Image
import os
class LungDataset(Dataset):
def init(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.images = os.listdir(root_dir)
def len(self):
return len(self.images)
def getitem(self, idx):
img_path = os.path.join(self.root_dir, self.imagesidx)
image = Image.open(img_path).convert('RGB')
label = 1 if 'cancer' in img_path else 0 # 简化标签
if self.transform:
image = self.transform(image)
return image, label
数据增强与加载
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
dataset = LungDataset(root_dir='data/lung_ct/', transform=transform)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
模型定义
model = models.resnet50(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 2) # 二分类:癌/非癌
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
训练循环(简化)
for epoch in range(5):
for images, labels in dataloader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
Mermaid 流程图:AI辅助肺癌诊断系统

Prompt 示例(用于生成影像报告)
Prompt: "你是一名放射科AI助手,请根据以下CT影像分析结果生成一份专业报告:
- 扫描部位:胸部
- 发现结节:右肺上叶,直径8mm,边界不清,密度不均
- AI恶性概率:87%
- 患者年龄:58岁,吸烟史30年 请用医学术语描述发现,提出进一步检查建议,控制在150字内。"
AI输出示例: CT示右肺上叶见一8mm磨玻璃结节,边缘毛刺,密度不均,AI评估恶性风险87%。结合患者58岁及长期吸烟史,建议行PET-CT检查或穿刺活检以明确性质,密切随访三个月后复查CT。
图表:AI与医生诊断准确率对比
| 初级医生 | 76% | 82% | 79% |
| 高级医生 | 85% | 88% | 86% |
| AI模型 | 91% | 85% | 89% |
| AI+医生协作 | 94% | 92% | 93% |
四、AI在教育行业的应用
1. 应用场景概述
AI正在重塑教育模式,主要应用包括:
- 个性化学习路径推荐
- 智能批改与作业分析
- 虚拟助教与答疑机器人
- 学生行为分析与预警
- 自适应考试系统
2. 落地案例:基于NLP的作文智能批改系统
案例背景
某在线教育平台开发AI作文批改系统,支持中小学语文作文自动评分与反馈,减轻教师负担。
技术栈
- Hugging Face Transformers
- BERT / RoBERTa 微调
- NLP任务:文本分类、语法纠错、语义相似度
- 评分维度:内容、结构、语言、创新
代码实现(Hugging Face + BERT)
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
import torch
from torch.utils.data import Dataset
自定义数据集
class EssayDataset(Dataset):
def init(self, texts, labels, tokenizer, max_len=512):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def len(self):
return len(self.texts)
def getitem(self, idx):
text = str(self.textsidx)
label = self.labelsidx
encoding = self.tokenizer(
text,
truncation=True,
padding='max_length',
max_length=self.max_len,
return_tensors='pt'
)
return {
'input_ids': encoding'input_ids'.flatten(),
'attention_mask': encoding'attention_mask'.flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
加载预训练模型
model_name = 'hfl/chinese-roberta-wwm-ext'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=5) # 5分制评分
假设训练数据
texts = "春天来了,花儿开了...", "我的梦想是当一名医生..."
labels = 4, 5
dataset = EssayDataset(texts, labels, tokenizer)
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=2,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
开始训练(实际需更大数据集)
trainer.train()
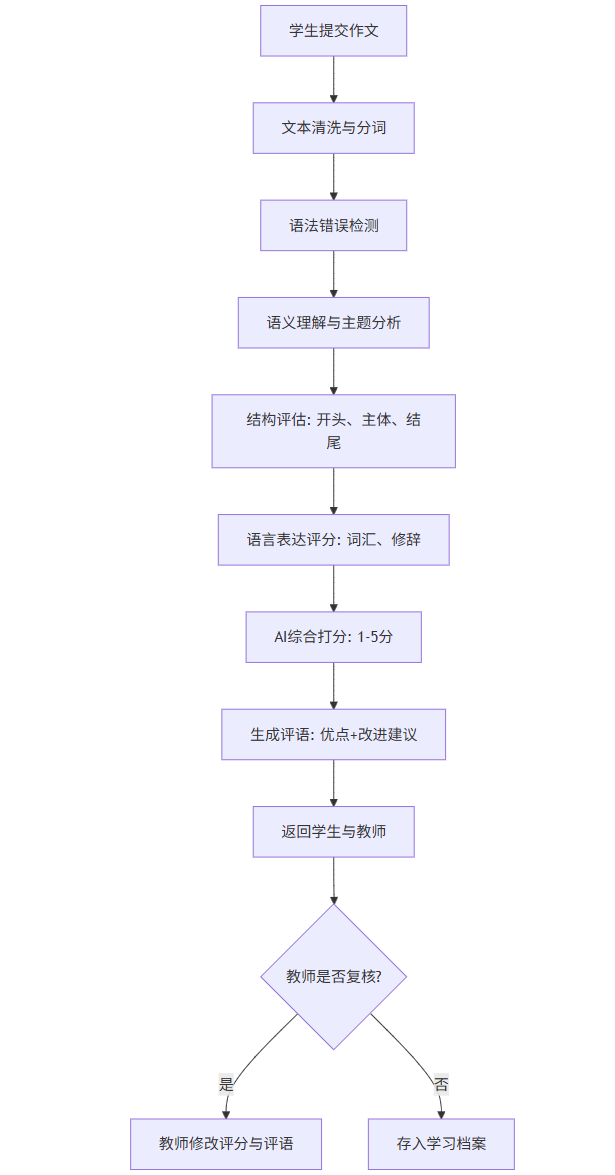
Mermaid 流程图:AI作文批改系统流程
graph TD
A学生提交作文 --> B文本清洗与分词
B --> C语法错误检测
C --> D语义理解与主题分析
D --> E结构评估: 开头、主体、结尾
E --> F语言表达评分: 词汇、修辞
F --> GAI综合打分: 1-5分
G --> H生成评语: 优点+改进建议
H --> I返回学生与教师
I --> J{教师是否复核?}
J -->|是| K教师修改评分与评语
J -->|否| L存入学习档案
Prompt 示例(用于生成作文评语)
Prompt: "你是一名语文老师AI助手,请为以下小学生作文生成评语: 作文标题:《我的妈妈》 内容节选:'妈妈每天很早起床做饭,送我上学,晚上还要加班。她很辛苦,我爱妈妈。' 请从情感表达、细节描写、语言流畅性三个方面点评,提出1条改进建议,语气亲切,控制在100字内。"
AI输出示例: 作文感情真挚,表达了对妈妈的爱。能抓住妈妈早起做饭、加班等细节,但可增加一个具体事例,如'有一次我发烧,妈妈背我去医院',让故事更生动。语言通顺,继续加油!
图表:AI批改与教师评分相关性
| 001 | 4.5 | 4.3 | 0.2 |
| 002 | 3.8 | 3.9 | 0.1 |
| 003 | 5.0 | 4.8 | 0.2 |
| 004 | 3.0 | 3.1 | 0.1 |
五、AI在制造业的应用
1. 应用场景概述
AI在制造业的核心应用包括:
- 预测性维护(Predictive Maintenance)
- 视觉质检(AOI, Automated Optical Inspection)
- 生产排程优化
- 供应链需求预测
- 数字孪生与仿真
2. 落地案例:基于LSTM的设备故障预测系统
案例背景
某汽车零部件工厂部署AI系统,通过传感器数据预测机床故障,减少非计划停机。
技术栈
- Python + TensorFlow/Keras
- 时间序列模型:LSTM
- 输入特征:温度、振动、电流、转速
- 输出:未来24小时故障概率
代码实现(LSTM 时间序列预测)
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
模拟传感器数据
data = pd.read_csv("machine_sensor_data.csv") # time, temp, vibration, current, rpm, fault_label
特征缩放
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data\['temp', 'vibration', 'current', 'rpm'])
构建时间序列样本
def create_sequences(data, seq_length):
X, y = \[\], \[\]
for i in range(len(data) - seq_length):
X.append(datai:i+seq_length)
y.append(datai+seq_length, 0) # 预测温度异常(可扩展为故障概率)
return np.array(X), np.array(y)
seq_length = 50
X, y = create_sequences(scaled_data, seq_length)
划分训练测试集
split = int(0.8 * len(X))
X_train, X_test = X:split, Xsplit:
y_train, y_test = y:split, ysplit:
构建LSTM模型
model = Sequential([
LSTM(50, return_sequences=True, input_shape=(seq_length, 4)),
LSTM(50),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
预测未来趋势
prediction = model.predict(X_test:1)
print("Predicted next temperature (scaled):", prediction00)
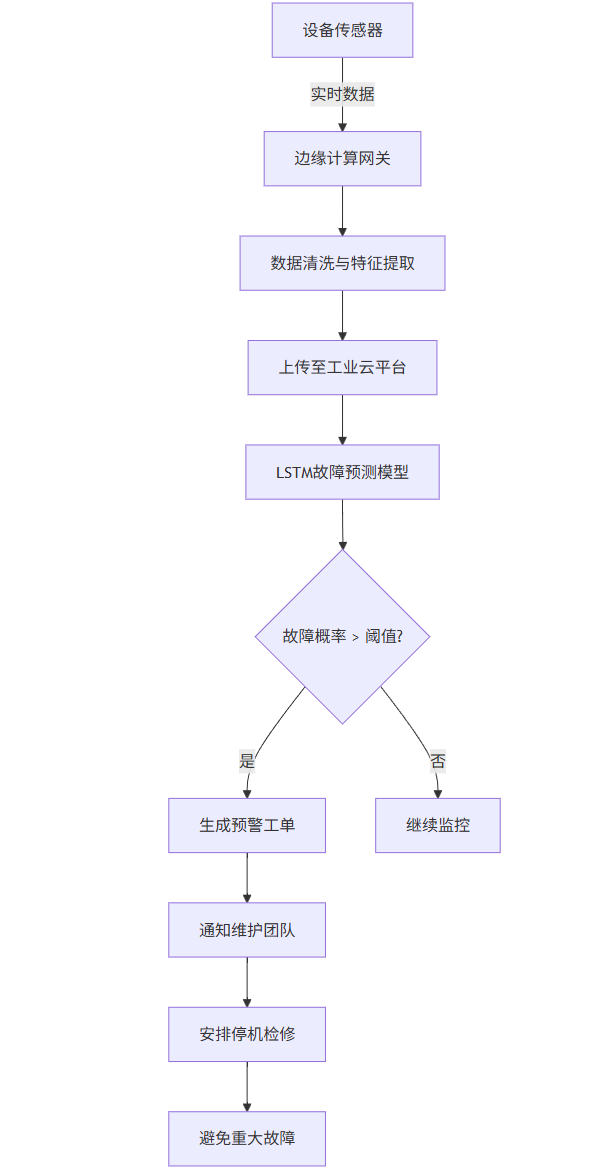
Mermaid 流程图:预测性维护系统架构
graph TB
A设备传感器 -->|实时数据| B边缘计算网关
B --> C数据清洗与特征提取
C --> D上传至工业云平台
D --> ELSTM故障预测模型
E --> F{故障概率 > 阈值?}
F -->|是| G生成预警工单
F -->|否| H继续监控
G --> I通知维护团队
I --> J安排停机检修
J --> K避免重大故障
Prompt 示例(用于生成维护建议)
Prompt: "你是一名工厂AI运维助手,请根据以下设备数据生成维护建议:
- 设备编号:M102
- 当前状态:运行中
- 振动值:持续上升,过去24小时增长35%
- AI预测:72小时内故障概率82%
- 最近一次保养:30天前 请用技术语言提出具体维护建议,包括优先级和操作步骤。"
AI输出示例: 设备M102振动异常升高,AI预测72小时内高概率发生轴承故障。建议立即安排优先级P1的预防性维护:1)停机检查主轴轴承;2)更换润滑油脂;3)校准动平衡。避免非计划停机造成产线中断。
图表:故障预测准确率与维护成本对比
| 传统定期维护 | - | 120 | 8 |
| AI预测性维护 | 85% | 75 | 2 |
六、跨领域AI平台架构设计(综合案例)
Mermaid 架构图:企业级AI中台
graph TD
subgraph 数据层
A业务系统 --> B数据湖: Hadoop/MinIO
CIoT设备 --> B
D外部API --> B
end
subgraph AI平台层
B --> E数据治理: 清洗、标注
E --> F特征仓库
F --> G模型训练: AutoML
G --> H模型仓库: MLflow
end
subgraph 应用层
H --> I金融: 风控引擎
H --> J医疗: 影像分析API
H --> K教育: 个性化推荐
H --> L制造: 预测维护
end
I --> M前端系统
J --> M
K --> M
L --> M
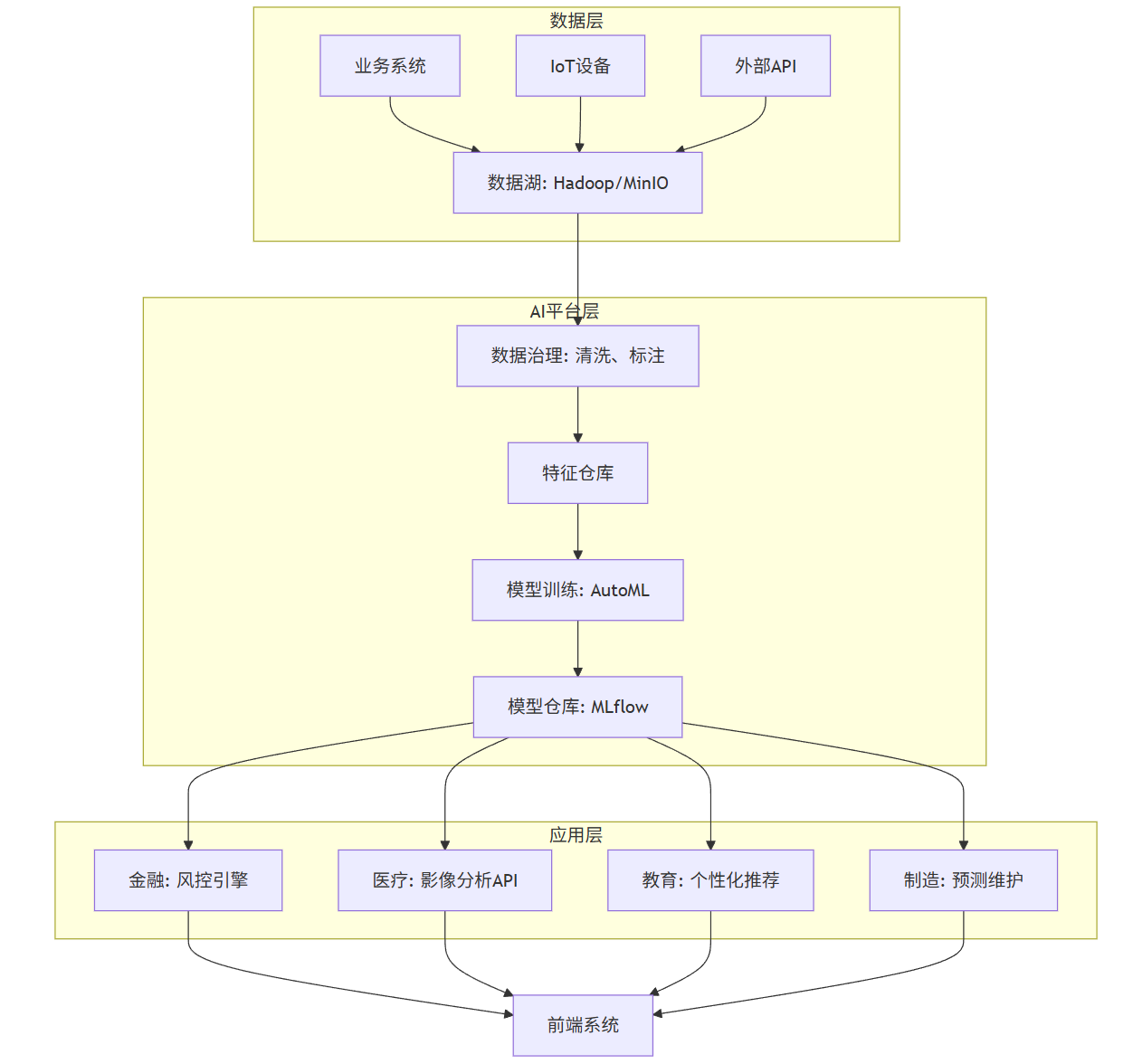
该架构支持多行业AI能力复用,实现"一次训练,多处部署"。
七、挑战与未来展望
当前挑战
- 数据隐私与安全:医疗、金融数据敏感,需合规处理(如GDPR、HIPAA)
- 模型可解释性:黑箱模型难被医生、风控官信任
- 算力成本高:大模型训练需GPU集群
- 行业知识壁垒:AI工程师缺乏医疗/金融专业知识
未来趋势
- 多模态AI:融合文本、图像、语音(如医疗问诊机器人)
- 边缘AI:在设备端实时推理(如工厂摄像头)
- AI Agent:自主决策的智能体(如自动交易Agent)
- 联邦学习:跨机构协作建模,保护数据隐私
八、结语
AI已在金融、医疗、教育、制造业等领域实现深度落地,不仅提升了效率,更推动了服务模式的创新。通过代码实践、流程图设计、Prompt工程与数据可视化,我们可以更清晰地理解AI系统的运行逻辑与价值创造过程。
未来,随着大模型、Agent、边缘计算等技术的发展,AI将从"辅助工具"逐步演变为"智能中枢",真正实现产业智能化升级。