文章目录
- 一、顶会中的Partial创新思想
- 二、顶会中的Partial创新思想-GhostNet
-
- [2.1 Ghost发现了什么?](#2.1 Ghost发现了什么?)
- [2.2 如何对 GhostModule 进行二次创新?](#2.2 如何对 GhostModule 进行二次创新?)
- 三、顶会中的Partial创新思想-FasterNet
-
- [3.1 FasterNet发现了什么?](#3.1 FasterNet发现了什么?)
- 四、顶会中的Partial创新思想--SHViT
-
- [4.1 SHViT发现了什么?](#4.1 SHViT发现了什么?)
- 五、顶会中的Partial创新思想--MobileMamba
- 六、顶会中的Partial创新思想-总结
一、顶会中的Partial创新思想
Partial思想是近年来CNN、Transformer网络设计中的一个重要趋势,主要通过部分通道处理来降低计算复杂度并保持模型性能。

为什么需要介绍这个看起来非常简单的"Partial思想"?
- Partial思想是一种即插即用的思想,并且其还可以为原来的模块降低计算量和参数量,并且还可以已最简单的修改下"美化"自己的模块。
- Partial思想提出了一个关键假设:并非所有特征通道都需要经过相同的复杂处理。它将输入通道分为不同组,对不同组应用不同复杂度的操作,从而在保持表达能力的同时显著降低计算成本。<GhostNet已经证明这个问题>
- CVPR2020 GhostNet
- CVPR2023 FasterNet
- CVPR2024 SHVIT
- CVPR2025 MobileMamba
二、顶会中的Partial创新思想-GhostNet
2.1 Ghost发现了什么?
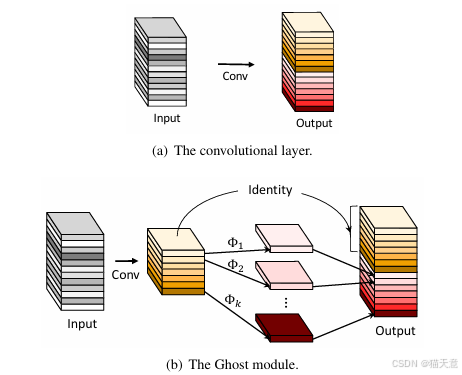
深度卷积神经网络中存在大量冗余的特征图,许多特征图彼此相似,如同 "幽灵" 一般。传统卷积层需要大量参数和计算来生成这些冗余特征图,这是不必要的。
- 假设输入的是 n 个特征图,先使用一个 Conv 生成 m 个特征图,其中 m ≤ n,通常 m = n/s。(s一般为2)
- 生成幽灵特征图,对这 m 个特征图做线性操作后再与这原始的 m 个特征图进行拼接得到输出。
线性操作的设计:
- 主要使用深度卷积(depthwise convolution)
- 核大小通常为 3×3 或 5×5
- 计算成本远低于普通卷积
2.2 如何对 GhostModule 进行二次创新?
针对 GhostModule 中的 Conv 其存在以下问题:
- 单一感受野:固定的卷积核大小限制了特征提取的多样性
- 静态特征提取:无法根据输入内容自适应调整特征提取策略
- 有限的语义理解:简单卷积难以捕获复杂的语义关系
- 缺乏全局信息:局部卷积操作缺乏全局上下文感知能力
- 重参数化卷积
DBB、DeepDBB、RepConv、DeConv...
特性卷积 - DynamicSnakeConv、风车卷积 (PSConv)、ShiftWiseConv、ConvAttn、FDConv...
- 多尺度
IDWC... - 大感受野卷积
FourierConv、FADC... - 动态卷积
DynamicConv... - 可变形卷积
DCNV2、DCNV3、DCNV4、DSA...
三、顶会中的Partial创新思想-FasterNet
3.1 FasterNet发现了什么?
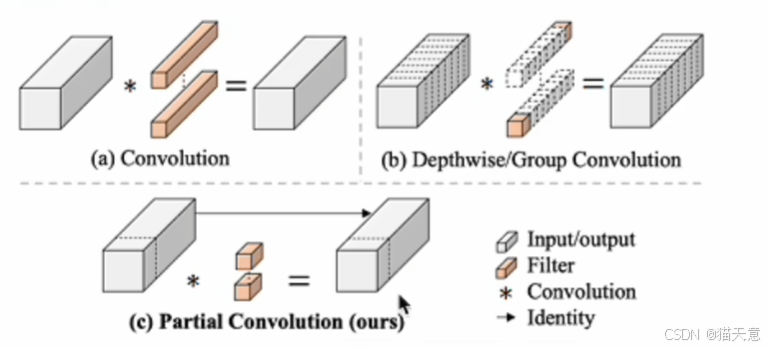
- 深度可分离卷积(DWConv)等操作虽然减少了FLOPs,但由于频繁的内存访问导致FLOPS降低
- 为补偿精度损失,需要增加通道数,进一步增加了内存访问开销
- 许多"快速"网络实际运行速度不如ResNet50
- 个人的感觉FasterNet是GhostNet的简洁版。
仅对1/4的通道进行卷积处理,剩下的直接Identity处理。
FLOPs (Floating Point Operations)
FLOPs 表示浮点运算次数,是衡量模型计算复杂度的静态指标。
- 静态度量:表示模型执行一次前向传播需要的浮点运算总数
- 理论计算量:不考虑硬件实现,纯粹从算法角度计算
- 常用定义:论文中采用广泛接受的定义,即乘加运算(multiply-adds)的数量
FLOPS (Floating Point Operations Per Second)
FLOPS 表示每秒浮点运算次数,是衡量实际计算速度的动态指标。
- 动态度量:表示硬件设备实际执行浮点运算的速度
- 硬件相关:同样的操作在不同设备上FLOPS可能差异很大
- 实际性能:反映真实的计算效率和硬件利用率
l a t e n c y = F L O P s F L O P S latency = \frac{FLOPs}{FLOPS} latency=FLOPSFLOPs
论文中指出,导致FLOPS较低的原因是频繁的内存访问。所以这就是为什么普遍的一些轻量化模块用了之后,fps都会下降的原因,因为他们大部分都是用时间换空间,虽然FLOPs上是变小了,但实际其内部操作更复杂了,内存访问也更频繁了。
四、顶会中的Partial创新思想--SHViT
4.1 SHViT发现了什么?
- 在DeiT-T模型中,后期阶段的平均头相似度高达78.3%(6头版本为64.8%)
- 在Swin-T模型中也观察到类似的高相似度现象
- 头消融实验显示,大多数注意力头可以被移除而不会显著影响性能
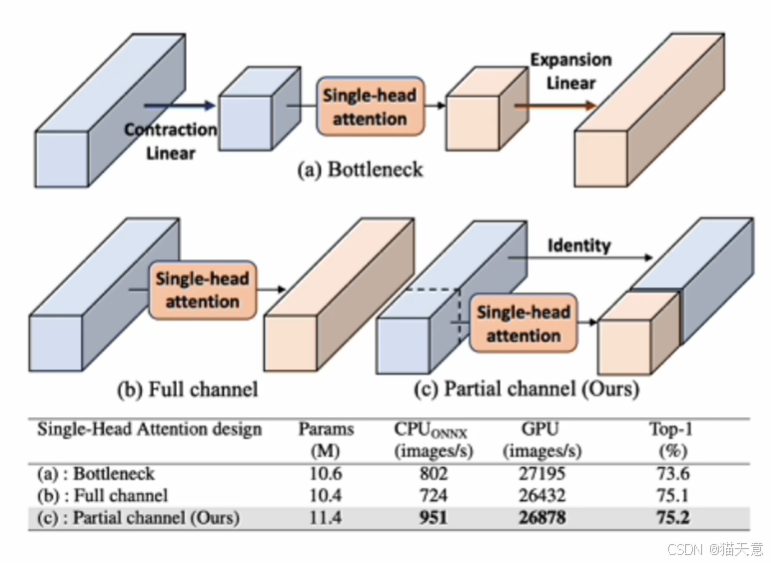
A方案:先进行通道压缩,再做Single-Head Attention,然后再升维。
B方案:全通道做Single-Head Attention。
C方案:对部分通道做Single-Head Attention。
从这个也可以看出Partial思想不论在创新上还是在效果上都要比普通的轻量化效果(A方案)要好。
五、顶会中的Partial创新思想--MobileMamba
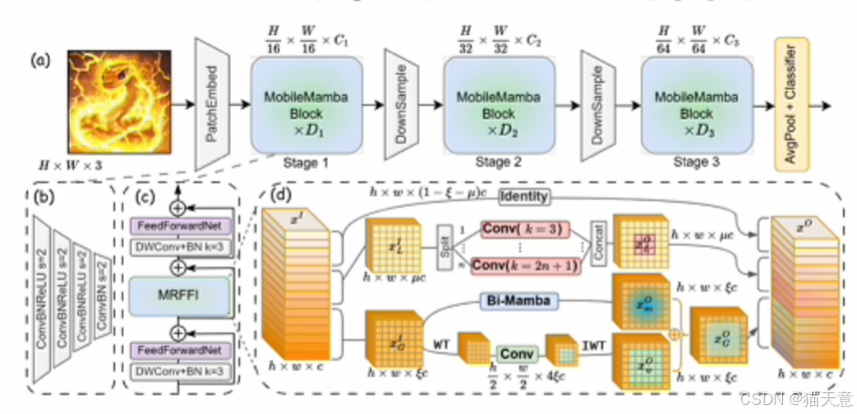
多感受野特征交互(MRFFI)模块
MRFFI模块是MobileMamba的核心创新,将输入特征沿通道维度分为三部分:
- 长距离小波变换增强Mamba (WTE-Mamba):
- 结合双向扫描Mamba模块进行全局建模
- 通过Haar小波变换提取不同频率尺度的特征表示
- 增强高频边缘细节信息的提取能力
- 高效多核深度卷积 (MK-DeConv):
- 使用不同核大小的局部卷积操作捕获多尺度感受野
- 实现多感受野信息交互
- 消除冗余恒等映射:
- 对剩余通道应用恒等映射,减少高维空间中的特征冗余
- 降低计算复杂度,提升处理速度
python
class MobileMambaModule(torch.nn.Module):
def __init__(self, dim, global_ratio=0.25, local_ratio=0.25,
kernels=3, ssm_ratio=1, forward_type="wstd", ):
super().__init__()
self.dim = dim
self.global_channels = nearest_multiple_of_16(int(global_ratio * dim))
if self.global_channels + int(local_ratio * dim) > dim:
self.local_channels = dim - self.global_channels
else:
self.local_channels = int(local_ratio * dim)
self.identity_channels = self.dim - self.global_channels - self.local_channels
if self.local_channels != 0:
self.local_op = DWConv2d_BN_ReLU(self.local_channels, self.local_channels, kernels)
else:
self.local_op = nn.Identity()
if self.global_channels != 0:
self.global_op = MWTConv2d(self.global_channels, self.global_channels, wt_levels=1, ssm_ratio=ssm_ratio, forward_type=forward_type)
else:
self.global_op = nn.Identity()
self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(
dim, dim, bn_weight_init=0, ))
def forward(self, x): # x (B,C,H,W)
x1, x2, x3 = torch.split(x, [self.global_channels, self.local_channels, self.identity_channels], dim=1)
x1 = self.global_op(x1)
x2 = self.local_op(x2)
x = self.proj(torch.cat([x1, x2, x3], dim=1))
return xX1,X2,X3 = Spilt(X)
X1 = Global(X1)
X2 = Local(X2)
Y = Concat(X1,X2,X3)
Global:
- Transformer
- Mamba
- 特性卷积(傅里叶卷积...)
Local:
众多的module,Conv都支持
六、顶会中的Partial创新思想-总结
- 我们利用一些变种卷积可以在GhostNet、FasterNet上继续做创新,轻松达到二次创新的效果。
- 我们可以模仿SHViT,用别的Transformer模块的时候,我们也可以利用上Partial思想,达到降低计算量和参数量的效果,并且也有二次创新的效果。
- 我们也可以模仿MobileMamba(Mamba+CNN+Partial),Mamba和CNN部分都可以换,然后也可以换成(Transformer+CNN+Partial)等等...
如果使用到Partial思想,到时候可以生成一些特征图来证明,确实存在冗余特征图,增强自己论文的说服力。