原文链接:https://arxiv.org/pdf/2411.19860
0. 概述
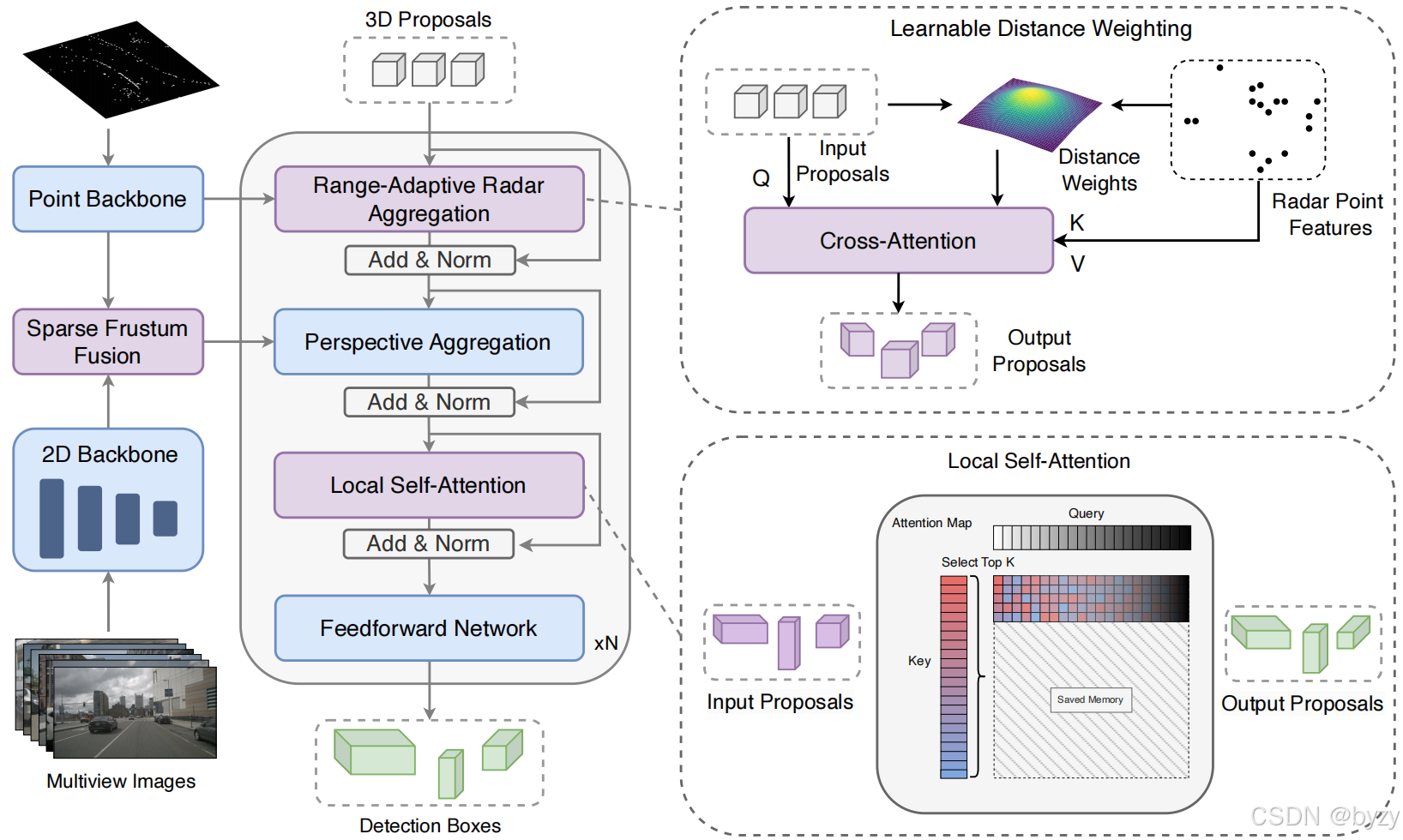
图像由卷积特征提取器编码,而雷达点则由基于Transformer的点编码器处理。随后进行两阶段融合:第一阶段将雷达特征投影到图像上关联语义特征,第二阶段则从透视提案初始化稀疏3D物体查询,通过交叉注意力聚合多模态特征。距离自适应的雷达细化基于距离指导物体与雷达的交互,透视空间中的可变形注意力则捕捉语义特征。
1. 雷达点编码器
本文使用轻量化的点Transformer提取雷达特征。通过空间填充曲线和序列化邻域映射,编码器将无结构的点转化为稀疏但信息密集的表达。将点分组为不重叠的区块,进行区块内的注意力以建模空间关系。
3D点和物体查询被编码到相同的位置嵌入空间中,以在后续的融合阶段实现直接交互。
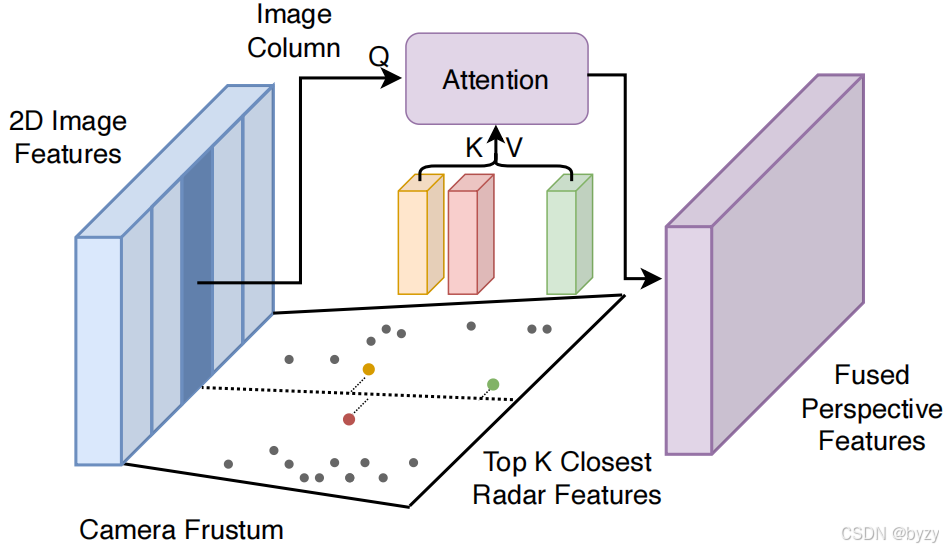
2. 稀疏视锥融合(SFF)
编码的雷达特征向量首先被投影到各相机的视锥空间中,将深度与水平索引转换为可学习位置编码。图像特征由下采样像素的位置来编码。对每个图像列,查询垂直维度上最近的 K K K个雷达点,并通过交叉注意力融合。
3. 距离自适应雷达(RAR)聚合
本文使用距离自适应的雷达聚合解码层,基于空间关系动态调整特征交互。
具体来说,距离感知的注意力机制基于雷达点与物体中心的接近程度来自适应地调整权重:
A t t n ( q , k , v ) = s o f t m a x ( q k T d − α ∥ p q − p k ∥ 2 r max ) v Attn(q,k,v)=softmax(\frac{qk^T}{\sqrt{d}}-\alpha\frac{\|p_q-p_k\|2}{r{\max}})v Attn(q,k,v)=softmax(d qkT−αrmax∥pq−pk∥2)v
其中 p q , p k p_q,p_k pq,pk分别表示物体查询和雷达点的3D位置, r max r_{\max} rmax为最大检测距离。 q ∈ R N q × d q\in\mathbb R^{N_q\times d} q∈RNq×d, k , v ∈ R N k × d k,v\in\mathbb R^{N_k\times d} k,v∈RNk×d。 α \alpha α控制空间偏置的强度。
4. 局部自注意力(LSA)
传统的DETR类结构使用全局自注意力交互所有查询,但本文发现查询只需要与空间邻居交互。故LSA将每个查询限制为仅与其 K K K近邻查询交互。
此外,本文还重新安排了解码块的结构,将自注意力放置于跨模态特征聚合之后,从而使查询先收集相关特征,再根据空间关系确定重复检测和误检。