一、引言
一直想着找个机会学习记录一下使用simd指令集来进行图像处理,这样可以高效的利用cpu,实现图像处理的加速。
二、图像灰度化
图像灰度化其实就是将三通道或者多通道转为单通道的过程。
拿三通道图像为例,三通道为B、G、R通道,分别代表不同的颜色,也就是我们说的彩色图像,通过对每个通道的像素值进行加权融合为一个数值,最后存储起来,就成为了一个单通道图像,也就是灰度图像。


有的人习惯使用平均权重,也就是
但是研究方向,反而是不同权重呈现的灰度效果最佳
三、代码实现
cpp
#if defined(_WIN32) || defined(_M_X64) || defined(__x86_64__)
#define USE_SSE
#include <immintrin.h>
#elif defined(__aarch64__) || defined(_M_ARM64)
#define USE_NEON
#include <arm_neon.h>
#endif
void convertToGrayscaleSIMD(const cv::Mat& input, cv::Mat& output) {
if (input.empty()) {
return;
}
// 确保输入是3通道的BGR图像
CV_Assert(input.type() == CV_8UC3);
// 创建输出灰度图像
output.create(input.size(), CV_8UC1);
const int width = input.cols;
const int height = input.rows;
const int channels = input.channels();
#ifdef USE_SSE
// SSE版本 - 每次处理16个像素
const int blockSize = 16;
for (int y = 0; y < height; ++y) {
const uchar* src = input.ptr<uchar>(y);
uchar* dst = output.ptr<uchar>(y);
int x = 0;
// 使用SSE处理16个像素的块
for (; x <= width - blockSize; x += blockSize) {
// 加载48个字节(16个像素的BGR数据)
__m128i bgr0 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src + x * channels));
__m128i bgr1 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src + x * channels + 16));
__m128i bgr2 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src + x * channels + 32));
// 解交织B、G、R分量
__m128i b0 = _mm_shuffle_epi8(bgr0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
__m128i b1 = _mm_shuffle_epi8(bgr1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1));
__m128i b2 = _mm_shuffle_epi8(bgr2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13));
__m128i b = _mm_or_si128(_mm_or_si128(b0, b1), b2);
__m128i g0 = _mm_shuffle_epi8(bgr0, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
__m128i g1 = _mm_shuffle_epi8(bgr1, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1));
__m128i g2 = _mm_shuffle_epi8(bgr2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14));
__m128i g = _mm_or_si128(_mm_or_si128(g0, g1), g2);
__m128i r0 = _mm_shuffle_epi8(bgr0, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
__m128i r1 = _mm_shuffle_epi8(bgr1, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1));
__m128i r2 = _mm_shuffle_epi8(bgr2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15));
__m128i r = _mm_or_si128(_mm_or_si128(r0, r1), r2);
// 转换为16位整数
__m128i b_lo = _mm_cvtepu8_epi16(b);
__m128i g_lo = _mm_cvtepu8_epi16(g);
__m128i r_lo = _mm_cvtepu8_epi16(r);
__m128i b_hi = _mm_cvtepu8_epi16(_mm_unpackhi_epi64(b, b));
__m128i g_hi = _mm_cvtepu8_epi16(_mm_unpackhi_epi64(g, g));
__m128i r_hi = _mm_cvtepu8_epi16(_mm_unpackhi_epi64(r, r));
// 计算灰度值:Gray = (77 * R + 150 * G + 29 * B) >> 8
__m128i gray_lo = _mm_srli_epi16(_mm_add_epi16(_mm_add_epi16(
_mm_mullo_epi16(r_lo, _mm_set1_epi16(77)),
_mm_mullo_epi16(g_lo, _mm_set1_epi16(150))),
_mm_mullo_epi16(b_lo, _mm_set1_epi16(29))), 8);
__m128i gray_hi = _mm_srli_epi16(_mm_add_epi16(_mm_add_epi16(
_mm_mullo_epi16(r_hi, _mm_set1_epi16(77)),
_mm_mullo_epi16(g_hi, _mm_set1_epi16(150))),
_mm_mullo_epi16(b_hi, _mm_set1_epi16(29))), 8);
// 打包回8位整数
__m128i gray = _mm_packus_epi16(gray_lo, gray_hi);
// 存储结果
_mm_storeu_si128(reinterpret_cast<__m128i*>(dst + x), gray);
}
// 处理剩余像素
for (; x < width; ++x) {
const uchar* p = src + x * channels;
dst[x] = (77 * p[2] + 150 * p[1] + 29 * p[0]) >> 8;
}
}
#elif defined(USE_NEON)
// NEON版本 - 每次处理8个像素
const int blockSize = 8;
for (int y = 0; y < height; ++y) {
const uint8_t* src = input.ptr<uint8_t>(y);
uint8_t* dst = output.ptr<uint8_t>(y);
int x = 0;
// 使用NEON处理8个像素的块
for (; x <= width - blockSize; x += blockSize) {
// 加载24个字节(8个像素的BGR数据)
uint8x8x3_t bgr = vld3_u8(src + x * channels);
// 转换为16位整数
uint16x8_t r16 = vmovl_u8(bgr.val[2]); // R分量
uint16x8_t g16 = vmovl_u8(bgr.val[1]); // G分量
uint16x8_t b16 = vmovl_u8(bgr.val[0]); // B分量
// 计算灰度值:Gray = (77 * R + 150 * G + 29 * B) >> 8
uint16x8_t gray16 = vaddq_u16(
vaddq_u16(
vmull_u8(vget_low_u8(bgr.val[2]), vdup_n_u8(77)),
vmull_u8(vget_low_u8(bgr.val[1]), vdup_n_u8(150))
),
vmull_u8(vget_low_u8(bgr.val[0]), vdup_n_u8(29))
);
// 右移8位并转换为8位
uint8x8_t gray = vshrn_n_u16(gray16, 8);
// 存储结果
vst1_u8(dst + x, gray);
}
// 处理剩余像素
for (; x < width; ++x) {
const uchar* p = src + x * channels;
dst[x] = (77 * p[2] + 150 * p[1] + 29 * p[0]) >> 8;
}
}
#else
// 通用版本(无SIMD)
for (int y = 0; y < height; ++y) {
const uchar* src = input.ptr<uchar>(y);
uchar* dst = output.ptr<uchar>(y);
for (int x = 0; x < width; ++x) {
const uchar* p = src + x * channels;
dst[x] = (77 * p[2] + 150 * p[1] + 29 * p[0]) >> 8;
}
}
#endif
}四、指令集解析
cpp
// 平台检测宏
#if defined(_WIN32) || defined(_M_X64) || defined(__x86_64__)
#define USE_SSE
#include <immintrin.h>
#elif defined(__aarch64__) || defined(_M_ARM64)
#define USE_NEON
#include <arm_neon.h>
#endif1.这部分代码通过预处理器宏检测目标平台:
-
如果是Windows或x86/x64架构,定义
USE_SSE并包含SSE指令集头文件 -
如果是ARM64架构,定义
USE_NEON并包含NEON指令集头文件
2.const int blockSize = 16;
SSE寄存器是128位,可存储16个像素,一个uchar类型像素的8bit。
3.
cpp
__m128i bgr0 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src + x * channels));
__m128i bgr1 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src + x * channels + 16));
__m128i bgr2 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src + x * channels + 32));_mm_loadu_si128(),用于将128位数据从内存加载到SSE寄存器。
除此之外,还有一个类似的函数_mm_load_si128()。这两个函数的区别在于load和loadu。
_mm_load_si128()函数要求内存地址必须16字节对齐(即地址是16的倍数)。若地址未对齐,调用此函数会导致未定义行为(程序崩溃或数据错误)。
_mm_loadu_si128()允许内存地址未对齐(无需是16的倍数)。
牺牲少量性能换取灵活性,适用于无法保证对齐的场景。
reinterpret_cast<const __m128i*>(),强制转换功能。
- static_cast<类型说明符>(表达式)
- dynamic_cast<类型说明符>(表达式)
- const_cast<类型说明符>(表达式)
- reinterpret_cast<类型说明符>(表达式)
与这些类似
4.
cpp
// 解交织B、G、R分量
__m128i b0 = _mm_shuffle_epi8(bgr0, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
__m128i b1 = _mm_shuffle_epi8(bgr1, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1));
__m128i b2 = _mm_shuffle_epi8(bgr2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13));
__m128i b = _mm_or_si128(_mm_or_si128(b0, b1), b2);_mm_shuffle_epi8()函数,这个函数是根据掩码mask(_mm_setr_epi8()),获取对应的bgr0中的元素。
bgr0中存储的为(b0,g0,r0,b1,g1,r1,b2,g2,r2,b3,g3,r3,b4,g4,r4,b5)
经过这个shuffle函数后,依据mask(0,3,6,9,12,15,-1......),分别取第0,3,6...位置的bgr0元素,即为(b0,b1,b2,b3,b4,b5,0,0,0,.......)
剩余的也是类似处理流程。
_mm_or_si128(b0,b1),可以理解为将两个数值合并异或操作。最终获取全部的B通道元素。
5.
cpp
// 转换为16位整数
__m128i b_lo = _mm_cvtepu8_epi16(b);
__m128i g_lo = _mm_cvtepu8_epi16(g);
__m128i r_lo = _mm_cvtepu8_epi16(r);
__m128i b_hi = _mm_cvtepu8_epi16(_mm_unpackhi_epi64(b, b));
__m128i g_hi = _mm_cvtepu8_epi16(_mm_unpackhi_epi64(g, g));
__m128i r_hi = _mm_cvtepu8_epi16(_mm_unpackhi_epi64(r, r));这里是为了转到16位,因为8位元素范围是0-255,后面要经过乘法运算,这个范围是会越界的。所以转为16位,128的SSE只能存储8个16位元素,所以分别将原数据的低8位与高8位分别存储下来。
_mm_unpackhi_epi64(b, b),这个函数就是获取高8位的函数。然后将低、高8位分别存储。
6.
cpp
// 计算灰度值:Gray = (77 * R + 150 * G + 29 * B) >> 8
__m128i gray_lo = _mm_srli_epi16(_mm_add_epi16(_mm_add_epi16(
_mm_mullo_epi16(r_lo, _mm_set1_epi16(77)),
_mm_mullo_epi16(g_lo, _mm_set1_epi16(150))),
_mm_mullo_epi16(b_lo, _mm_set1_epi16(29))), 8);这里就是计算灰度值了,需要先将权重0.144等分别×256。最后再进行移位运算,移8位与÷256有着一样的结果。
_mm_add_epi16(),相加运算
_mm_mullo_epi16(),相乘运算
_mm_srli_epi16(),可以理解为移位运算
7.
cpp
// 打包回8位整数
__m128i gray = _mm_packus_epi16(gray_lo, gray_hi);
// 存储结果
_mm_storeu_si128(reinterpret_cast<__m128i*>(dst + x), gray);_mm_packus_spi16(),将两个 128 位寄存器中的 16 位有符号整数压缩为 8 位无符号整数,并使用饱和运算来处理溢出。
_mm_storeu_si128(),用于将128位SIMD寄存器(__m128i类型)中的数据非对齐存储到内存地址.
操作类型 内在函数 速度
对齐存储 _mm_store_si128 更快
非对齐存储 _mm_storeu_si128 稍慢
五、结果对比
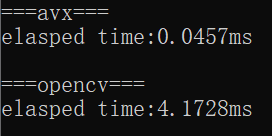
采用opencv自带的函数耗时4ms左右,而采用自己实现的simd加速方法,速度将近提升了100倍。