摘要:
本文工作:
(1)我们提出了一个快并且准确率高的跟踪算法------RT-MDNet,是基于多域卷积神经网络MDNet。该方法加速了特征提取过程,并且为示例分类,学习了更多的判别模型。它通过在每个激活中保持具有大感受野的高分辨率特征来增强目标和背景的表示质量。
(2)引入了一个新的loss来区分多个领域的前景实例,并学习具有相似语义的目标队形的更具区分性的嵌入。
做出的贡献:
与MDNet相比,RT-MDNet实现了大约25倍的加速,准确率几乎相同。我们的算法在多个流行的跟踪基准数据集(包括OTB2015、UAV123、TemleColor)中进行评估,即使在没有特定于数据集的参数调整的情况下,它的性能也始终优于最先进的实时跟踪方法。
1、介绍
原先使用的方法及其不足之处:
CNN在视觉跟踪中非常有效,但是精度提升的同时对于实时系统来说往往太慢了。且只有少数方法同时保证了精度和速度。
MDNet是一个基于CNN的sota算法,这个算法是受到R-CNN的启发,它们通过一个在大规模数据集上预先训练的CNN,并在测试视频的第一帧进行微调。
其他多域学习框架专注于目标域相对于每个域中的背景的显著性,但它没有优化以区分跨多个域的潜在目标实例。因此,MDNet的学习模型对于区分表示测试序列中具有相似语义 的看不见的目标。
详细地重新介绍本文的工作:
首先,我们使用RoIAlign层从前面的全卷积特征图中提取对象表示。更新网络架构以构建高分辨率特征图并扩大每个激活的感受野。前者有助于精确的表示候选对象,后者是学习目标的丰富语义信息。
其次,我们在预训练阶段引入了一个实例嵌入损失,并聚合到原始MDNet中使用的现有二进制前景/背景分类损失。新的损失函数在在潜在空间中嵌入观察到的目标实例之间方面起着重要作用。它使我们能够学习看不见的对象的更具辨别力的表示,即使它们具有相同的类标签 或相似的语义。
2、最近的工作:
(1)基于CNN的视觉跟踪算法通常将目标跟踪表述为判别目标检测问题。
(2) 一些方法绘制对应于候选区域的一组样本,并使用CNN独立计算它们的可能性。
(3)最近基于判别相关滤波器的技术通过结合深度神经网络的表示显著提高了准确性。
(4) 请注意,大多数具有竞争性准确性的实时跟踪器都依赖于手工制作的特征或有限的深度表示使用。与这些实时跟踪方法相反,我们的算法在纯深度神经网络框架内具有更简单的推理管道。
目标检测中的特征提取:
R-CNN 在目标检测中是成功的,但是从各个区域中提取特征进行推理有很大的开销。
Fast R-CNN 使用RoIPooling降低了其特征提取的计算成本。它通过对特征图中的特征区域应用最大池化来计算固定大小的特征向量。虽然成本下降但是RoIPooling对定位目标无效,因为它依赖于粗略的特征图。
为了缓解这一限制,mask R-CNN 引入了一种新的特征提取做技术RoI对齐(RoIAlign),它通过双线性插值逼近特征,以获得更好的目标定位。
我们的工作为自适应RoIAlign提出了一种改进的网络架构,以提取与区域建议相对应的鲁棒特征。
3.高效的特征提取和判别特征学习:
我们CNN 架构 与改进的 RoiAlign 层 ,该层在保持表示质量的同时加速特征提取。我们还讨论了一种新的多域学习方法,具有前景对象的判别实例嵌入。
3.1 网络结构
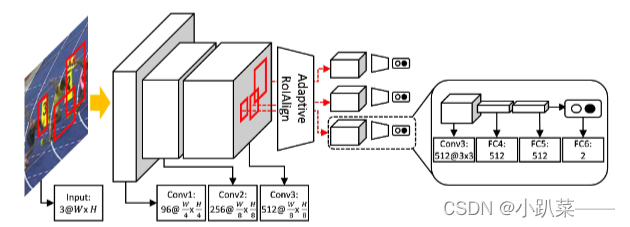
网络由三个全卷积层(conv1-3)+ 一个自适应RoIAlign layer +三个全连接层(fc4-6)组成。
输入为 有着一系列proposal bounding boxes 的 整个图片;
conv1-3用于获取一些共享的特征映射;
自适应RoIAlign layer 来提取每个RoI的特征(通过这种特征计算策略,我们在提高特征质量的同时显著降低了计算复杂度);
fc4-6进行二分类(每个RoI中提取的特征表示被馈送到两个全连接层,用于目标和背景之间的分类);
fc61-fc6D为域特定层,是为多域学习创建的;并学习判别实例嵌入。
在在线跟踪过程中,一组特定领域的全连接网络被替换成为具有softmax交叉熵损失的单个二元分类层,这将使用来自初始帧的示例进行微调。
3.2改进的用于视觉跟踪的RoIAlign
为了构建一个高分辨率、丰富语义信息的特征图。
通过计算更密集的卷积特征图并扩大每个激活的感受野来解决。为此我们去掉了VGGM网络中的conv2层的最大池化层。并且在conv3中使用r=3来扩张卷积。
这使得输出的特征图比原始VGG-M网络中的conv3层的输出产生两倍更大的特征图。
如下图所示:
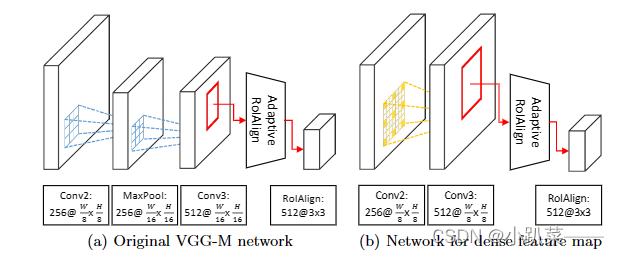
我们的自适应RoIAlign层使用改进的双线性插值计算更可靠的特征,特别是对大目标。
我们的自适应RoIAlign层产生一个7*7的特征图,在层之后应用最大池化层来生成3*3的特征图。尽管改进的RoIAlign做了微小的更改,但它在实践中显著提高了我们的跟踪算法的性能。
3.3为判别实例嵌入的预训练
MDNet 有单独的共享层和特定领域的层来学习区分目标和背景。
提出的新损失项,称为实例嵌入损失,它强制不同领域的目标对象在共享特征空间中彼此相距很远,并能够学习新测试序列中看不见的目标对象的判别表示。
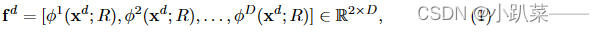
R为Bounding box, xd为输入的图像,d为域, fd为网络输出的分数,D为在一个训练数据集中域的数量。
输出的特征被输入到一个用于二分类的softmax公式。
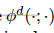 是一个2D的二分类分数,是从d域的最后一个全卷积层fc6d获得的。
是一个2D的二分类分数,是从d域的最后一个全卷积层fc6d获得的。
两个softmax 方程如下:
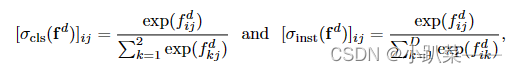
然后总的loss由两部分组成:

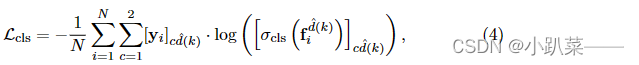
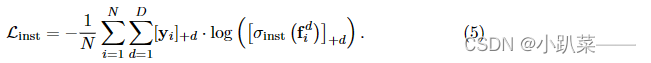
4、在线跟踪算法
算法pipline和MDNet几乎相同。
4.1跟踪的主要流程
预训练 -->
将特定领域层(fc61-fc)的多个分支替换为每个测试序列的单个分支 --->
给定具有目标位置ground truth的第一帧,我们微调链接层fc4-6,并将网络定制为测试序列 --->
剩下的帧,我们以在线方式更新全连接层,而卷积层是固定的 -->
优化函数

我们训练里一个 边界框回归器来提高目标位置的准确度。
使用从视频第一帧的ROI的一组提取的特征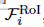
我们训练了一个简单的线性回归器,我们应用从第二帧学习到的边界框回归器,如果估计的目标状态足够可靠
4.2在线模型更新
两个互补的更新策略,与MDNet相同,长期更新和短期更新,以保持鲁棒性和适应性。
使用长时间收集的样本定期应用长期更新,而当估计目标的分数低于阈值并且结果不可靠时,会触发短期更新。
小批量由128个实例组成------32个正样本和96个负样本,我们在在线学习过程的每次迭代中,使用hard minibatch 采样。通过测试1024个Hard负例并选择具有前96个正分数的示例来识别hard 负例。
4.3实施细节
网络初始化和输入管理:
三个卷积层的权重从imageNet上预训练的VGG-M网络中的相应部分转移,而全连接层时随机初始化的。
调整输入图像的大小,使目标对象大小适合107*107,并裁剪到包含所有样本RoIs的最小矩形。最后一个卷积层中单个单元的感受野大小等于75*75.
离线预训练:
为每一个离线预训练迭代,我们构建了一个minibatch,其中包含从单个域收集的样本。
我们首先在选定的域中随机采样 8 帧,并从每一帧中抽取 32 个正例和 96 个负例,这导致小批量中总共有 256 个正例和 768 个负例。
在IoU度量方面,正边界框与地面真实的重叠大于0.7,而负样本的IoU小于0.5。
并不是在每次迭代中反向传播梯度,而是在多次迭代中从反向传递累计梯度。
在我们的实验中,网络每50次迭代更新,我们在ImageNet-Vid上训练我们的模型,这是一个用于对象检测的大模型数据集合。
在线训练:
预训练是通用的,我们必须在每个测试视频的第一帧微调预训练的网络。与预训练相同的IoU标准绘制了500个正样本和5000个负样本。
从第二帧开始,在每一帧中完成跟踪后收集在线更新的训练数据。该跟踪器分别收集了50个正例和200个负例,它们与估计的目标位置相比分别是大于0.7IoU的,小于0.3。
我们的算法不是存储原始图像块,而是通过避免冗余计算来保持它们的特征表示以节省时间和内存。每 10 帧执行长期更新。
优化:
SGD优化方法。
对于离线学习,我们以0.0001的学习率训练网络1000个epoch,而在测试视频的第一帧训练50次迭代。
对于线上更新,微调迭代次数为15,并且学习率被设置为0.0003.fc6的学习率是fc4-5的10倍,来促进实践中的收敛性。权重衰减和动量分别固定为0.0005和0.9。