大模型后训练入门指南
- [1. 后训练简介](#1. 后训练简介)
- [2. 后训练数据格式](#2. 后训练数据格式)
- [3. 后训练技术](#3. 后训练技术)
- [4. DPO:直接偏好优化](#4. DPO:直接偏好优化)
- [5. 在线强化学习(Online RL)](#5. 在线强化学习(Online RL))
- [6. 超越RLHF:通用范式](#6. 超越RLHF:通用范式)
-
-
- [(1)奖励模型(Reward Models)](#(1)奖励模型(Reward Models))
- [(2)基于规则的奖励(Rule-based rewards)](#(2)基于规则的奖励(Rule-based rewards))
-
- [7. 测试时计算与推理](#7. 测试时计算与推理)
-
- [7.1 论文带注释摘录](#7.1 论文带注释摘录)
-
- [Section 2.2.2: Reward modeling](#Section 2.2.2: Reward modeling)
- [7.2 其他时刻](#7.2 其他时刻)
- [附录A :](#附录A :)
-
- [1. 深入探讨PPO](#1. 深入探讨PPO)
- [2. DeepSeek的GRPO](#2. DeepSeek的GRPO)
- 附录B:
- 内容来源
大型语言模型(LLMs)彻底改变了我们撰写和阅读文档的方式。在过去的一年左右,我们不仅看到它们被用于简单的改写文档,更发现它们已具备了"先思考再行动"的能力------能够制定计划、调用浏览器等工具、编写代码并验证其功能,甚至更多------事实上,这些能力清单正迅速扩展!
这些能力有什么共同点呢?答案是:它们都是在后训练阶段(post-training) 中发展出来的。尽管后训练解锁的能力在几年前看起来几乎像魔法一样,但它获得的关注却远少于 Transformer 架构和预训练的基础内容。
本教程最初是为 Meta 的基础设施团队编写的,目标读者是没有 LLM 建模专业背景 、但希望深入了解后训练并能够参与贡献的基础设施工程师。我认为这类工程师的群体非常庞大:随着强化学习逐渐成为主流,我们需要新的基础设施来提升生产力,因此弥合这一差距至关重要!我现在将其更广泛地分享,希望 PyTorch Foundation 内有相似背景和兴趣的更多同事也能像我们团队一样从中受益。
1. 后训练简介
后训练(有时也称为"对齐")是LLM的关键组成部分,它是"教"模型如何以人类喜欢的方式回答,以及如何进行推理的过程 。
你可能会问:为什么后训练和预训练不同?后训练的作用是让模型准备好与用户进行对话,并遵循一套基本规则,比如:
- 在对话中,不止一个说话者,大家需要轮流发言
- 你应该先"听",再"说",这样才能说出相关的话
这些规则对我们来说很显然,但预训练阶段只是做下一个词预测,用来教模型认识世界,数据完全是无结构的,因此模型并没有学到这些对话的基本规则。事实上,一个刚从预训练阶段出来的模型往往并不理解自己应该在适当的时候停止说话,而是会没完没了地输出,有点像谷歌的自动补全框一样。
此外,还可以在模型中强制加入一些具有绝对优先级的"基本规则"。这种方式在后训练中通过系统提示词(system prompt)来实现(也可以通过监督微调(SFT)/奖励塑形(reward shaping),后面会详细介绍)。
2. 后训练数据格式
与这些模型进行聊天之所以成为可能,是因为在后台有一套"管道"在运作。每当你在一个类似 ChatGPT 的聊天窗口里输入消息时,你会看到这样的界面:
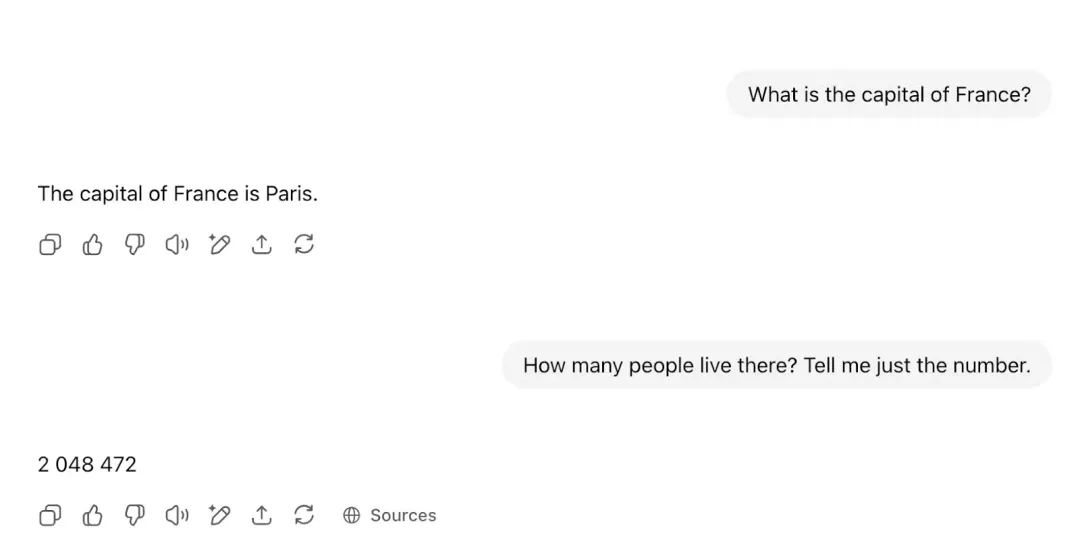
实际上,系统已经为你配置好了后训练结构,模型看到的将是类似下面的内容(以 Llama 3 的数据格式为例):
python
<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
... <|eot_id|>
<|start_header_id|>user<|end_header_id|>
What is the capital of France?<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
The capital of France is Paris
<|start_header_id|>user<|end_header_id|>
How many people live there? Tell me just the number<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
START FILLING FROM HERE请注意,LLM的基本接口并没有改变:你提供一段文本,它就会无止境地继续往下生成。
这种巧妙的"管道"处理,确保了模型能接收到所有必要的元数据,从而知道:前面的说话者已经说过话了(它不应该去模仿他们!!),并且在 assistant 说完之后就要停止。再强调一次,模型本身会愉快地一直填充下去,但当我们看到一个 <eot_id> 标记("end of turn",回合结束)时,就会阻止模型继续生成,并把结果返回给用户。
需要注意的是,这些步骤都不是模型自己完成的:尽管看起来很"聪明",但它们依然只是文本填充器,需要依靠这种人工的"牵引"来运作。
这种数据格式读起来可能有点难,但你基本上可以把它理解为类似下面这样的结构:
python
<system> You are a helpful assistant bla bla </system>
<user> What's the weather in Paris? </user>
<assistant> ANSWER HERE一个有趣的事实是:模型其实可以开心地扮演任意角色!你完全可以扮演 assistant,让它扮演 user,只要你给它输入正确的文本结构------模型会自动接管并继续生成,无论你提供什么内容。你可以试着在本地模型或 API 上体验这一点(像 ChatGPT 这样的产品会自动帮你处理这些"管道",因此你无法直接覆盖)。当然,模型对自己的格式非常敏感,所以一定要确保你使用的是正确的格式。
3. 后训练技术
后训练是一个快速发展的领域,不同的团队会采用不同的技术手段。我们来看 OLMo 2 论文中描述的这条流水线:

接下来的部分将逐一介绍流程中的每一个步骤。
3.1 SFT:有监督微调
SFT 的核心在于模仿。概念上很简单:你强制性地一步一步教模型学会一个答案。
举个例子,如果这是下棋,可以使用 Magnus Carlsen 的比赛数据进行训练,强制要求模型在每一步都必须遵循 Magnus 的走法。这样你能达到Magnus的水平,但他的水平就是你的上限,你没有办法进一步超越他(而这正是强化学习(Reinforcement Learning, RL)的优势:你可以不断尝试,直到变得非常强大,后面会讲到)。
对于 LLM 来说,SFT 的过程就是逐字学习理想答案 。因此,损失函数就是输出层的交叉熵(cross-entropy),理想的"类别"就是"正确"词语的 ID。一个常见的问题是:这不就是和预训练一样吗?确实很相似,但有一个关键的不同点:**SFT只以提示词为条件进行学习,而不学习提示词本身。**为什么?因为我们要学习的是"如何回答这个问题",而不是"学习问题本身"。
请记住:和预训练不同,在后训练中我们有系统提示词(system prompt)和用户提示词(user prompt)(见上文的"后训练数据格式")。这些输入部分需要作为条件参数,但不需要从中学习。实现方式是:**我们把整个序列输入(包括系统提示词、用户提示词以及特殊字符),在前向传播时不做任何遮罩(masking),但是在计算损失时,会对所有非回答部分的 token 进行掩蔽,只在模型的回答部分计算损失。**输入时不掩码提示词是为了让其参与条件参数计算,而在反向传播阶段进行掩码是为了防止提示词影响损失计算。
SFT 和预训练如此相似,以至于在实践中,SFT 可以直接复用预训练的基础设施:比如在 Megatron 这样的训练平台上,SFT 用的 dataloader 和 trainer class 都和预训练相同,只是额外设置一个参数,用来对提示词部分的损失进行掩蔽。
不过,SFT 的规模远远小于预训练 。预训练需要消耗数万亿(trillions)的 token,而 SFT 最多只需要几百万个样本,也就是几十亿(billions)级别的 token。
谁来写回答?
SFT 是逐字学习的,这带来了两个重要限制:
- 你的上限取决于谁写了答案(见上文的例子)。
- 更关键的是,你会严重依赖数据质量。在实践中,你的上限往往不是由最好的答案决定,而是被最差的答案拉低。因为当你从人类那里收集答案时,不可能所有答案都非常优质;有些答案质量不高,但它们却会极大地影响模型的最终质量。
那么我们该怎么办?我们无法改变"人性",所以一个思路是:让 LLM 自己生成将要用来训练的回答 。一开始这听起来可能不太直观,但这种方法叫做 拒绝采样(Rejection Sampling) (可参考 Llama 2 论文)。它的原理在于:我们并不是只生成一个回答(如果那样确实不会提升模型),而是生成多个回答(通常是 10 个),通过不同的检查点、随机种子、系统提示词等方式来增加多样性。然后,我们挑选出最优的回答(通常通过一个管线来排序,其中可能包括"人类偏好奖励模型"这样的辅助模型),再把它加入到训练数据池中。如果你有机器学习背景,可以把这个方法大致类比为:从一个集成模型中提炼出一个单一模型(虽然这个类比有点模糊,但大概就是这个意思)。
这个循环可以迭代很多次。如果做得好,模型就能不断"爬坡",越来越好。
3.2 强化学习入门
强化学习是一个广泛的范畴,其中最有名的就是基于人类反馈的强化学习(RLHF),但 RL 并不局限于此。
一般来说,RL 的核心思想是:你现在是一个能够对环境采取行动的智能体(agent),并且可以观察到行动的结果,同时从中获得奖励(reward)。你可以把这些奖励理解为一种可以用来训练的"标签",不过,反向传播的方式会有所不同(后面会详细讲)。
如何训练?
在 RL 中确实会进行反向传播,但其运作方式与监督学习中清晰的前向-反向循环存在关键差异。
关键区别在于:在 RL 中,我们没有像交叉熵(Cross Entropy)或均方误差(MSE)这样可微分的损失函数。奖励以及类似浏览器这样的工具不可微分,因此不能直接通过它们进行反向传播,这确实很麻烦。
因此,我们采用一个非常粗略的近似方法:直接作用于模型输出的对数概率(logprobs)。若行动获得正向反馈则增大其值,若反馈消极则减小其值。随后通过反向传播调整网络底层参数来实现这种变化 。需要注意的是,这种方法的效率远低于优化监督学习的损失函数(如 MSE 或交叉熵):监督学习的损失函数会返回一个密集的梯度向量,而这里我们只从整个回合中得到一个标量,每次交互获得的"学习信息"要少得多。
RL 学习过程中还有更多"花样",不同算法会针对主要问题(梯度消失/爆炸、样本效率、基础设施优化等)做出不同选择,但整体思路就是这样。附录中提供了 Proximal Policy Optimization (PPO) 的详细逐步推导。
从基础设施的角度来看:相比"标准"的监督学习,你需要在模型上运行大量推理,这成本更高(自回归、逐 token 生成 vs 监督学习中可以一次性前向传递整个序列),对基础设施要求更多(如 KV 缓存等)、批处理更困难,等等。
尽管训练目标非常粗糙,但强化学习在稀疏奖励或长期奖励场景中表现卓越 ,而 SFT 则要求奖励必须密集(需要为每个token提供正确答案)。
用下棋的类比来说:
- SFT:逐步教模型复制每一步棋。
- RL :模型只有在赢得整局比赛(可能在 20 步之后)时才获得奖励。通过探索与利用的权衡,训练算法会偏好那些能更频繁获得更高奖励的模型配置。
虽然起初模型会很弱,但经过足够多的对局训练,最终可以达到甚至远超Magnus的水平,换句话说,RL 的上限要高得多。
某种意义上,你可以把 RL 看作一台神奇的机器,它能弥合"判断能力"和"实际操作能力"之间的巨大差距。我可以判断一名 F1 车手什么时候犯错,但我做不到哪怕是最差 F1 车手能做的事情。而强化学习能将任何纸上谈兵的车迷转变为真正的赛车手🏎️。
一句话总结就是:"如果你能判断它,你就能学会它 !"
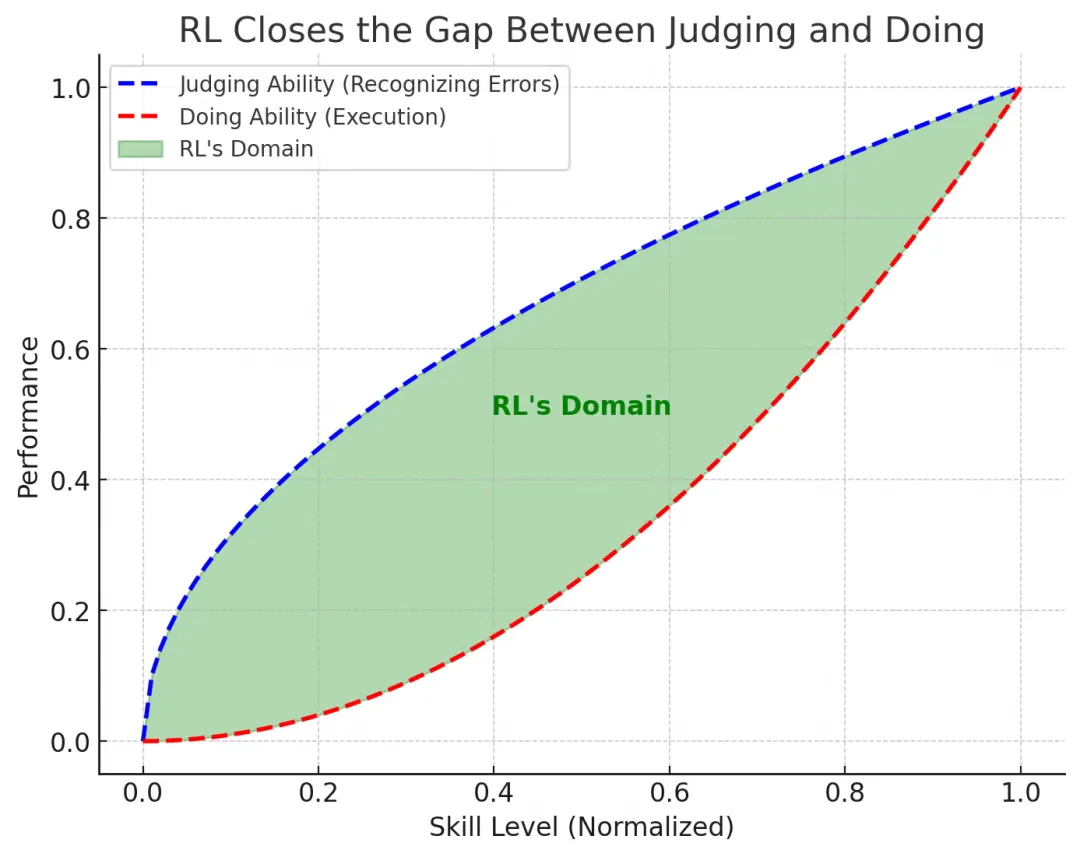
奖励劫持(Reward Hacking)
需要注意一点:强化学习的性能上限仍取决于你的判断能力(蓝色曲线),也就是你的奖励质量决定了上限。对于游戏这类场景,奖励非常清晰(你可以 100% 精准地判断是否获胜),因此上限几乎是无限的。理论上,RL 可以应用到任何场景,但如果你的判断能力不强,智能体学到的可能只是噪声。
RL 的一个直接限制就是它可能学到你不希望出现的行为:RL 会尽一切手段去最大化你给予的奖励 ,所以模型会做你要求它做的事情,而不是你真正想要的。我们称这种现象为 奖励劫持(reward hacking),虽然模型本身无辜,但设计奖励机制的人需要承担责任。
一个典型例子:RL 发现《超级马里奥 1》存在一个 30 多年的漏洞:跳跃后,如果你转身,你会在一帧内无敌。由于 RL 的奖励是最大化得分,而更快通关可以获得更高分数,它就利用这个漏洞疯狂刷高分,从而获取更多奖励。
- 开发者的期望:最大化得分;保持像人类一样玩;不利用漏洞
- 开发者实际给的指令:最大化得分
顺便说一句,这种情况在人类身上也会发生!我们称之为反向激励(Perverse Incentives),本质上和 RL 的奖励劫持是同一个道理。一个著名案例是:英国政府为控制德里毒蛇数量,对每条死蛇提供奖金。起初效果很好,大量毒蛇被杀。但后来人们开始专门养蛇以赚取奖金。
在LLM中的应用
类似于下棋的例子,RL 的上限可以高于 SFT,因此它成为教模型如何以人类喜欢的方式进行对话(RLHF)、如何进行推理等任务的首选方法。正如我们刚看到的,你能达到的上限取决于奖励的质量:如果你使用分类器来提供奖励,那么你的上限就是该分类器的准确率。
RLHF
其中一种奖励分类器是人类偏好。很难用规则明确写出人类喜欢的写作风格,所以我们的方法是训练一个分类器来对生成文本进行打分。我们通过准确率和 PR AUC 来监控其性能(如果你只需要对文本进行排序,PR AUC 才必需;否则像 F1 或 Accuracy 这样的点估计就足够)。
一旦你有了这个分类器,你所需要做的就是针对它运行 RL,并优化模型以适应其反馈。
4. DPO:直接偏好优化
现在让我们看看 LLM 后训练流程中的第二个模块 。DPO 是一种专门用于 LLM 的 RLHF 的算法,它不是通用的 RL 算法(不像 PPO 等,可以用来训练机器人或其他任何任务)。
实际上,严格来说,DPO 甚至不是真正的 RL 算法;它只是"假装"是 RL!DPO 的核心思想是:如果做出一些合理假设,就可以在训练 RLHF 的同时,得到一个可微分的损失函数。
更准确地说,DPO 允许我们在某些假设下,将马尔可夫决策过程(MDP)的问题转化为监督学习问题 (后面会详细介绍),这很重要,因为通常解决 MDP 的唯一通用方法是通过强化学习(其代价函数效率很低)。
DPO 的核心思想是:不需要单独的奖励模型,你可以让 LLM 同时作为策略模型和奖励模型 。为什么?因为 LLM 可以给出在某个问题下生成某个答案的概率。因此,如果你有一个偏好对,你可以简单地说:对于同一个问题,希望偏好答案的概率高,而被拒绝答案的概率低。换句话说,你要最大化这个差异,从而得到一个非常漂亮的可微分函数!
与 PPO 或其他需要大量推理生成多个答案来采样的 RL 算法相比,DPO 的运行成本非常低 。但缺点是 DPO 不进行探索,因此模型的上限也有限。下面是 DPO 与"真正的"RL算法(如 PPO)的更详细对比(我们接下来会详细讲解 PPO)。
| 特性 | DPO(直接偏好优化) | PPO(近端策略优化) |
|---|---|---|
| 优化方式 | 监督学习 | 强化学习(RL) |
| 数据需求 | 固定数据集(提示词,偏好答案,拒绝答案)三元组 | 环境交互数据 + 奖励模型 |
| 损失函数 | 类二分类损失函数 | 裁剪策略梯度损失 |
| 探索机制 | ❌ 无(固定数据集,完全离线) | ✅ 有(策略可探索新响应------在线算法) |
| 同策略? | ❌ 异策略(从固定数据学习) | ✅ 同策略(需新交互数据) |
| 计算成本 | ✅ 低(每个三元组单次前向传播) | ❌ 高(环境交互 + PPO训练) |
| 训练稳定性 | ✅ 稳定(类似微调) | ❌ 不稳定(RL方差) |
| 收敛速度 | ✅ 快 | ❌ 慢(需大量交互数据) |
| 性能限制因素 | ❌ 数据质量 | ✅ 计算资源(更优选择) |
| 最佳适用场景 | 低成本人类偏好对齐 | 灵活性高但成本昂贵的微调 |
5. 在线强化学习(Online RL)
在我们示例的 LLM 后训练流程中,第三个也是最后一个模块是 在线 RL 。"标准"算法是 PPO(近端策略梯度,Proximal Policy Gradients),由 OpenAI 于 2017 年提出。另一种被广泛采用的算法是 GRPO (Group Relative Policy Optimization),由 DeepSeek 提出。
关键概念:On-policy与Off-policy
策略(policy)就是你正在训练的 LLM 。On-policy意味着与环境的每次交互都直接来自正在训练的模型 。这就像我们跟随私人教师学习:尝试某个行为→犯错→立即获得反馈→带着新知识再次尝试。这种方式远优于Off-policy,后者通过观察他人在相同情境的行为进行学习(这个"他人"可以是过去的自己,因此通常会将历史行为存储在回放缓冲区供后续使用)
强化学习算法属于这两类之一:PPO 属于 on-policy ,而Q-learning(如 DQN)属于 off-policy。
| 特性 | On-Policy RL(如 PPO) | Off-Policy RL(如 DQN、DPO) |
|---|---|---|
| 定义 | 从当前策略收集的数据中学习 | 从之前收集的数据中学习(即使来自旧策略) |
| 探索能力 | ✅ 有(不断生成新回合,探索-利用权衡自然融入策略网络的 logits 中,初期大量探索,逐渐转向利用) | ❌ 离线运行时不进行探索,只是重复使用之前生成的数据(如 DPO)。在线运行可探索,但探索策略需自行定义(如 epsilon-greedy) |
| 基础设施效率 | ❌ 低(需要持续在线生成数据) | ✅ 高(可重复使用过去生成的数据) |
| 训练稳定性 | ❌ 不稳定(策略持续变化) | ✅ 更稳定(固定数据集或回放缓冲区) |
| 计算成本 | ❌ 高(需要频繁生成回合) 成本主要来自同步训练循环(收集 → 训练 → 收集 → 训练) | ✅ 低(在存储数据上训练) |
| 示例算法 | PPO、A2C、TRPO | DQN、DDPG、SAC、DPO |
| 最佳应用场景 | 需要持续探索的情况 | 可以存储并复用过去经验的情况 |
从基础设施角度看:在线RL与离线RL
On-policy 与 Off-policy 是从模型训练动态的角度来看问题的。如果从基础设施的角度考虑,我们更关注离线(Offline)与在线(Online),这两个概念与Off-Policy和On-Policy高度对应,因此常被互换使用,尽管技术上仍存在细微差异:
- 若采用离线学习 ,则只能进行Off-Policy学习 (因为数据由其他模型生成并保存)。拒绝采样和DPO都属于Off-Policy的离线算法。这是基础设施中最简单的实现方式。
- 若采用在线学习 ,On-Policy 与 Off-Policy 实际上更像是一个连续谱,尤其是当你考虑使用多台机器和同步时。如果你想严格做到 On-Policy,就意味着:批大小(batch size)为 1,从该模型生成样本,并在整个训练过程中设置屏障,确保模型不断更新,同时在重新同步权重到所有节点之前,不采样新的轨迹。
代码实现层面:
python
# Idealized PPO training loop
collector = CollectorClass(model)
for i in range(num_collection):
collector.sync_weights_() # align weights across all workers
# resume collection and put trainer node on hold <- this is bad!
data = next(collector) # collect data
# Put collector nodes on hold <- this is bad!
for j in range(num_epochs):
for batch in split_data_randomly(data):
loss_val = loss_fn(data)
loss_val.backward()
optim.step()
optim.zero_grad()因此,一定程度的"off-policy"是可取且可接受的。这引申出诸多问题:off-policy的允许程度如何?多频繁更新采样权重?如何通过重叠权重同步、数据采集和模型训练流程来最大化吞吐量?
我不希望各位离开本节时形成"off-policy和离线算法必然低效且应完全避免"的认知。事实上,Llama流程的前两个环节(SFT和DPO)本质上是通过监督代价函数来解决对齐马尔可夫决策过程的方法。这些方法可视为某种形式的离线off-policy强化学习:
- 我们的SFT数据来自拒绝采样(Rejection Sampling) ,即通过模型自身生成数据。虽然未使用DQN等标准off-policy RL算法,但这种拒绝采样方式实则为off-policy优化的变体。
- 同理,DPO也是一种off-policy优化形式 ,它避免了实际RL梯度更新(缓慢且不稳定)的问题。
不同团队在如何利用这些技术、如何组合使用上有不同方案,但并非每个团队都会公开这些信息。
6. 超越RLHF:通用范式
我们并不局限于只使用人类反馈,实际上,也确实不止于此。如果你想学会编程,可以提供一个测试环境,并根据通过的测试数量给予奖励;如果你想学会解积分,可以用 Wolfram 检查你的公式是否正确。
简而言之,你可以通过混合 Software 1.0 与 Software 2.0 来构建奖励管线。常见模式如下:
(1)奖励模型(Reward Models)
一个分类器,输出连续分数(0 到 1,有时甚至不受限制),用于对多个答案进行排序,特别是在难以用明确规则表达目标的领域(如人类偏好、写作风格等)。
- 结果奖励模型(Outcome Reward Models, ORMs):ORMs 根据最终结果提供反馈,只考虑思考链的最终结果。这类模型最常见,如果有人仅说"奖励模型",通常指的就是这类。
- 过程奖励模型(Process Reward Models, PRMs) :例如在下棋中,奖励是稀疏的:只有赢或输时才有奖励。直觉上,密集奖励可以帮助智能体更精细地理解哪些行为是可取的。PRMs 就是做这个的:不仅判断最终输出,还评估整个步骤序列。例如,PRM 会检查整个推理链的每一步是否合理。由于噪声较大,这类模型尚未被广泛使用。
(2)基于规则的奖励(Rule-based rewards)
你可以写一组规则,并为每条规则设置奖励(或者整体遵守时的奖励)。
- 软件管线:运行"传统"软件 1.0,并根据运行结果提供奖励。例如,编程通过测试用例或通过代码规范检查。
- 评判器 :当无法通过传统软件管线检查规则遵守情况时,可以使用 LLM 来验证。例如,你可以写一套安全规则,例如"禁止涉及性内容",裁判会问:"所有规则都遵守了吗?"。注意:这与连续分数的奖励模型不同,因为你只能得到二元答案(规则是否遵守),无法对多个答案进行排序。因此,这类方法通常用于提供负奖励,如果有规则被违反。实践中往往无需训练专门模型,直接提示基础模型进行评判即可。
这些都是可以构建非常复杂的奖励塑形(reward shaping)管线 的组件。例如,你可以设计一个复杂的有向无环图(DAG),提供非常细粒度的奖励。
下面是编程的简单示例:
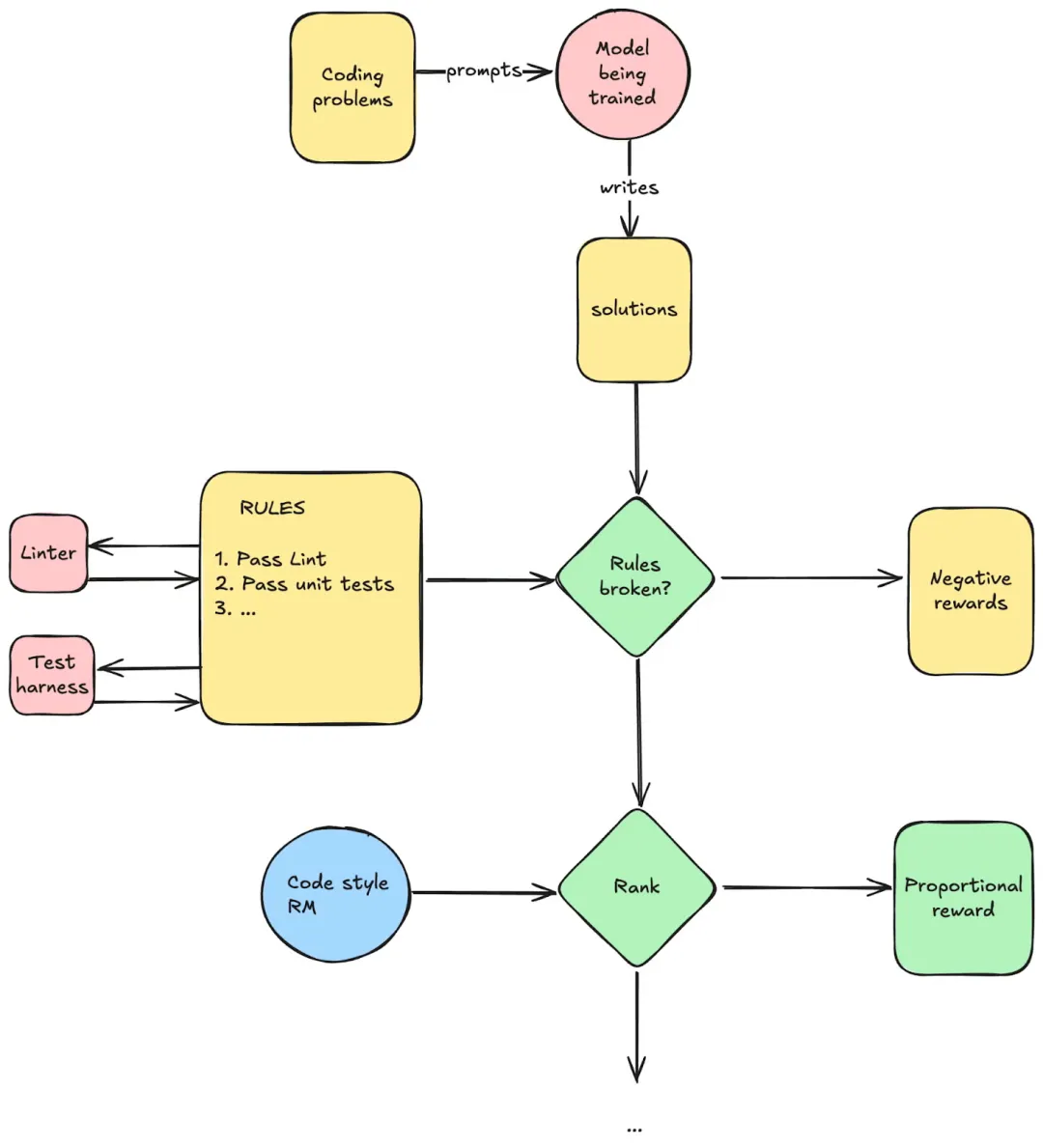
这会带来基础设施方面的影响:
- 测试环境和其他可执行程序的沙箱化。
- 这些奖励模型的部署位置:你可能会有很多奖励模型,而且它们可能很大(不要把它们当作小型专用分类器!它们通常和你正在训练的模型差不多大)。
- 我们应当预期,会有越来越多的工程师开发越来越好的奖励管线(更细粒度,用于塑造模型行为)。这些管线本身可以成为工程师贡献的主要领域,也可以在 Hub 上集中管理,并进行众包式开发。
7. 测试时计算与推理
**测试时推理(Test-time reasoning)**是过去一年由 OpenAI 提出并引领的一个重要趋势,随后被 DeepSeek 在其 DeepSeek R1 论文中成功复现。
让我们更深入地探讨这一概念。
简而言之,它是在以往工作的基础上发展而来的(例如 Chain of Thought 和 ReAct 循环 ),这些研究发现:在模型正式给出答案之前,让它"自言自语"式地推理,可以显著提升答案的质量,尤其是在某些领域(比如数学)。更有趣的是,这种能力是模型自发涌现的,从未经过专门训练。于是,自然的下一步就是研究如何训练 LLM,让它在这个"思考步骤"上表现得更好。
我们并不知道 OpenAI 采用了什么技术,但 DeepSeek R1 论文里最令人惊讶的发现是:你并不需要特别复杂的机制来诱导这种学习。事实上,他们证明,只需给予模型"思考的空间"就够了 ,方法就是简单地指示模型在<think> 和 </think> 标签之间生成文本,并且确保这段文本不是空的。
这是他们使用的 system prompt:

在这一机制建立之后,他们进入了奖励建模阶段。
7.1 论文带注释摘录
我强烈推荐大家阅读 DeepSeek R1 论文全文,因为写得非常好。这里,我引用了其中的一些章节,并加入了我自己的评论,以便为非该领域的专业读者提供背景信息。
Section 2.2.2: Reward modeling
The reward is the source of the training signal, which decides the optimization direction of RL. To train DeepSeek-R1-Zero, we adopt a rule-based reward system that mainly consists of two types of rewards:
- Accuracy rewards: The accuracy reward model evaluates whether the response is correct. For example, in the case of math problems with deterministic results, the model is required to provide the final answer in a specified format (e.g., within a box), enabling reliable rule-based verification of correctness. Similarly, for LeetCode problems, a compiler can be used to generate feedback based on predefined test cases.
评论:这些内容整体上和我们之前看到的差不多,概念上很简单。真正实现时,需要机器学习工程师具备技巧,去设计既不嘈杂、又能将强化学习过程引导到期望方向的高质量奖励。
- Format rewards: In addition to the accuracy reward model, we employ a format reward model that enforces the model to put its thinking process between '<think>' and '</think>' tags.
评论: 太聪明了!!!这是一个非常简单的方法,用来推动模型开始利用思考过程。否则,它可能不会持续稳定地在 <think> 和 </think> 标签之间探索思考的可能性。通过在模型不这么做时施加强烈的负奖励,可以把它拉回正轨,并将探索约束在必须使用这些标签的范围内。他们在 R1-Zero 中到此为止,但实际上你可以继续做更复杂的奖励建模。比如,R1-Zero 有时会在思考过程中混用英文和中文,你可以通过添加一个提示(然后附加一个奖励)来强制它用英文思考。你还可以在思考过程被判定为"不好"(比如不一致等)时添加中间的负奖励,从而进一步引导模型。可以看出,这其实是一种通用范式 ......
- We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline.
评论:或许社区里的某个人最终会想出办法,让过程奖励模型(process RMs)真正发挥作用......
7.2 其他时刻
"顿悟"时刻

这一点对我来说非常有趣,因为强化学习本质上学会了自主回溯 。这真的很酷,说实话我原本没想到会发生这种情况。我想象你可以通过搜索来进一步改进这一点:最简单的是 束搜索(beam search ),然后你可以扩展到 树搜索算法,比如 MCTS (蒙特卡洛树搜索 )。现在我们已经有了一个可行的基线方法,我认为在这些更复杂的方法上我们会看到更快的进展。在我看来,这是对这项工作的一个严重误解:DeepSeek 并没有证明 AI 不需要大量算力,恰恰相反 ! 他们只是表明,要入门并不需要复杂的方法,简单方法 + 大规模训练就足够了,这是 AI 领域我们反复学到的一个教训。
自主增加思考时间(测量时计算量)
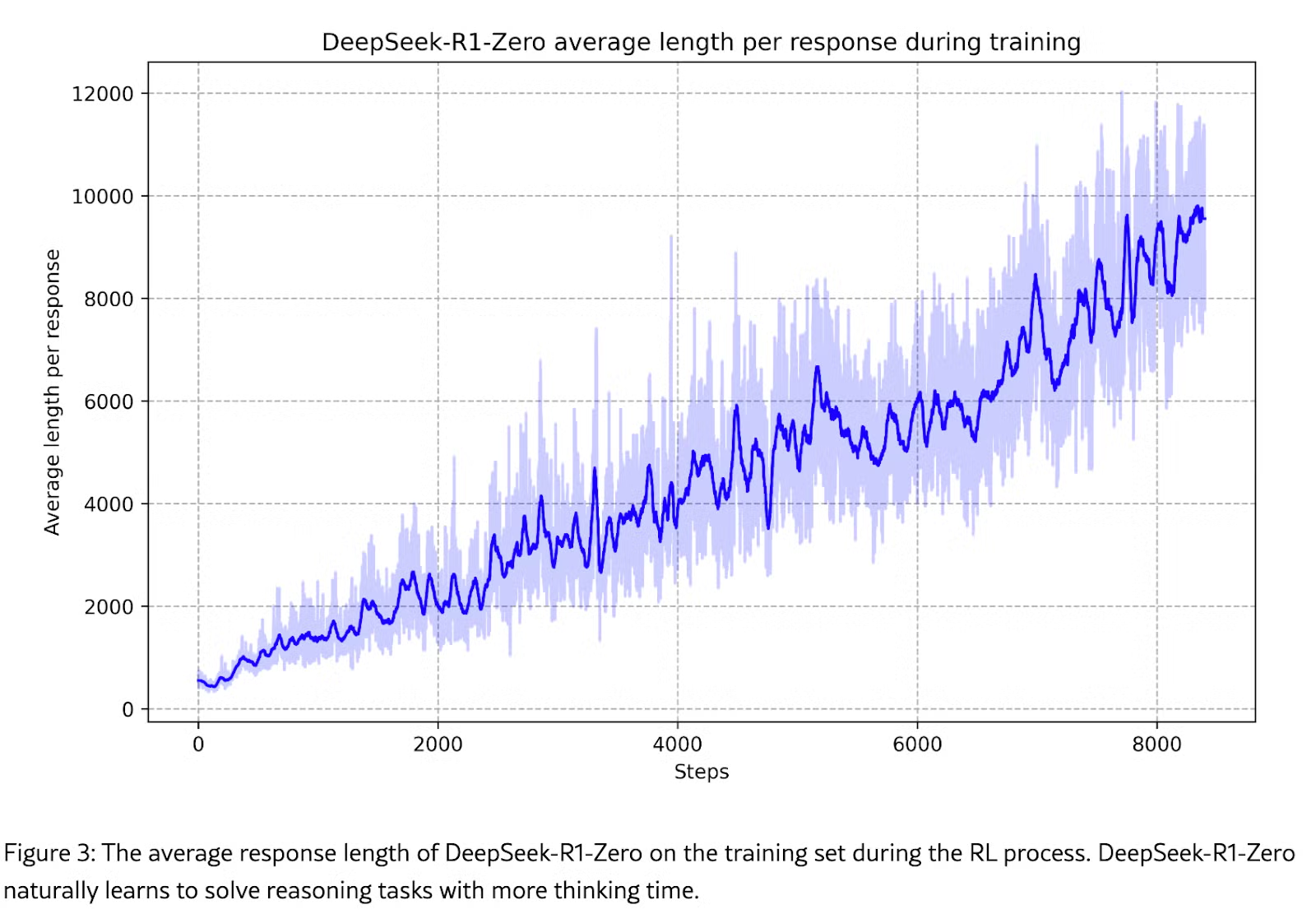
由于他们从未对模型思考时间过长进行惩罚,强化学习就会发现,思考更长时间完全没有坏处,随着迭代的进行,它只会不断向更长的思考路径方向发展。这是意料之中的。我猜如果继续下去,模型也会自动学会在达到最大序列长度时停止,因为那时它无法记住完整的推理轨迹,继续下去不会有帮助(甚至可能有害)。
再次说明,模型学会了测试时计算量越大越好,因此我们应预期计算需求会随之上升。
附录A :
1. 深入探讨PPO
让我们深入探讨强化学习中的反向传播。先从监督学习(无强化学习)的"基本训练循环"开始:
python
loss_fn = nn.CrossEntropyLoss()
for batch in dataset:
x, y = batch
y_hat = model(x) # 只进行一次前向
loss = loss_fn(y, y_hat)
loss.backward() # 一次反向传播回想一下,在强化学习中,我们没有一个明确定义的损失函数,因此我们做的是:如果某个行动好,就让它更可能被选择;如果某个行动不好,就让它更不可能被选择。那么,我们如何实现这一点呢?
我们的模型已经输出了一个关于行动的概率分布,所以最后一层会对所有动作进行 Softmax 。我们希望的是:对好的行动给予正梯度,对不好的行动给予负梯度。
基本上,我们想做的就是类似这样的操作:
python
model.weights.grad[good_actions] += delta
model.weights.grad[bad_actions] -= delta自动求导(Autograd)可以帮我们实现这一点:为了让梯度上增加一个固定的增量(delta),我们需要一个函数,它在求导后能给出这个增量。答案是乘法 。因此,我们的"损失函数"就可以简单地表示为:log_probs * per_token_reward。
让我们保持高层次的理解,逐步展开(否则 PPO 的损失看起来会非常复杂):
python
for batch in dataloader: # 遍历训练数据集 (提示词)
prompts = batch # 得到输入提示词: (bsz, prompt_lens). 可以是不规则的,也可以是打包的。
responses, log_probs = model.generate(prompts) # 自回归生成,需要大量前向计算、KV 缓存等。如果你对这部分不清楚,可以阅读本附录B。.
# 另请注意:我们必须返回所有中间生成步骤的对数概率,且这些数据需保留在计算图中(不进行分离操作),因为后续计算将依赖这些信息。
# responses 和 log_probs 的大小为:(bsz, response_lens),同样可以是不规则或打包的。
sequence_rewards = get_feedback(responses) # 获取奖励(例如,人类偏好或启发式奖励)
# 注意,奖励可以为负值,在这种情况下,符号将为负。
# 这是一个大小为 (bsz,)的张量
per_token_reward = discount(sequence_rewards)
# 这一项的大小为 (bsz, response_lens)。
# 一种简单的折扣方法是将每个 token 乘以一个因子 gamma(例如 0.99)。
# 最后一个 token 的奖励为 1,倒数第二个 token 的奖励为 1 * gamma,再前一个 token 的奖励为 1 * gamma * gamma,依此类推。
# 你不想只最大化某个时间步 t 的奖励,而是想最大化从当前到回合结束的奖励总和。
optimizer.zero_grad() # 重置梯度
# 根据奖励信号手动调整 log-probs
adjusted_log_probs = log_probs * per_token_reward
# 这是针对你的随机策略的奖励期望梯度的随机估计器。
# 换句话说:平均来看,这个梯度指向策略表现良好的方向!
loss = -adjusted_log_probs.sum() # 等同于最大化优秀行动的概率
loss.backward() # 仍然只需一次反向传播调用!PyTorch 会自动处理。
optimizer.step() # 更新模型参数需注意:虽然我们会进行多次前向传播(由于自回归生成特性),但仅需执行一次反向传播(前提是保留计算图。若这些生成过程由VLLM等工具完成,则需要额外进行一次前向传播以重建本端的计算图,不过这部分开销应该不大......)。
现在让我们把它变得更贴近实际情况。
以上内容都是概念上的做法。但当你真正去尝试时,一切很可能会发散 😀。
让我们做一些改进:
- 自适应增量(Adaptive delta) :使用固定增量并不理想,因为更新的幅度应该与选择的优劣成比例。与其手动调整 log-probs,不如让反向传播自动完成这项工作。如果你想增加某个动作的概率,可以直接最大化其对数概率。为了在梯度下降中实现这一点,我们最小化负对数概率。这就是策略梯度损失函数(Policy Gradient Loss)。
python
policy_gradient_loss = - (rewards * log_probs).sum(dim=-1).mean()
policy_gradient_loss.backward()- 减少方差 :如果我们只用上面的方法进行训练,有些回答会得到非常高的奖励,而另一些则可能是零奖励,这会导致训练不稳定。一种缓解方式是引入基线 ,即"平均行动的期望累计奖励":不算糟糕,但也不算优秀。直观理解是:一个行动的好坏始终取决于当时可供选择的替代方案。比如说,拿到 100 万美元看起来很棒,但如果你本来有机会拿到 1 亿美元,那就完全不一样了。
这种相对于基线的"好坏"被称为优势(advantage),它是强化学习中的一个核心概念。
那么,如何预测这个基线分数(也叫作一个状态的价值)呢?有两种方法:
- 价值网络(Value Network)
训练一个模型来完成这个任务:你可以训练一个价值网络来估计基线应该是多少。 - 蒙特卡洛方法(Monte Carlo)
简单地跑一批生成(通常 4-5 次就够了),然后把所有生成的累计奖励取平均,这就是对该价值的估计。
接下来,我们的代码会变成这样:
python
for batch in dataloader:
prompts = batch
responses, log_probs = model.generate(prompts)
rewards = discount(get_feedback(responses)) # Already discounted
for n in range(epochs):
for _prompts, _log_probs, _rewards in make_minibatches(
prompts,
log_probs,
rewards,
):
values = value_network(_prompts) # 通过价值网络来预测基线 V(s)
optimizer.zero_grad()
# REINFORCE with baseline
advantages = _rewards - values # Compute advantage estimate
loss = - (advantages * _log_probs).sum(dim=-1).mean()
loss += advantages.pow(2).mean()
loss.backward()
optimizer.step()但是,这样还是不稳定!强化学习本身就具有极强的不稳定性和难以调控的特性 (不过与其他领域相比,它在大型语言模型中的表现反而出奇地稳定)。其中一个原因是奖励分布可能呈现非常长的尾部,也就是说,你的梯度行为并不理想。因此在实际应用中,我们必须确保参数更新受到良好约束,以保证训练过程的稳定性。
而PPO的核心思路就是通过四大约束机制来强制实现稳定性:
- 优势标准化
上面的代码是直接乘以原始的 advantage,但即使我们已经尽力做了基线处理,它仍然可能导致过大的更新,从而让训练变得不稳定。一种让训练更"乖巧"的办法就是:把 advantage 平移成零均值,并缩放到单位方差。
python
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)- 重要性采样
但这仍然不够。为了进一步改进,我们需要强制更新保持在一个信任域内。PPO 的做法是:阻止相对于旧策略来说过大的更新 (所以没错,它需要保留时间 t−1 时的模型 )。
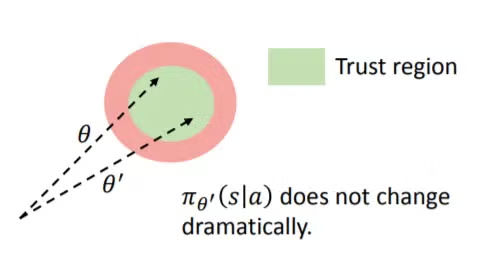
所以现在我们改为这样做:
python
old_log_probs = get_old_log_probs(prompts, responses).detach() # 之前策略的 Log probs
importance_sampling_ratio = torch.exp(log_probs - old_log_probs)
safe_advantages = importance_sampling_ratio * advantages- 裁剪过大的更新
这是最常见的策略。如果梯度可能过大、带来风险,就直接把它裁剪掉。
python
old_log_probs = get_old_log_probs(prompts, responses).detach() # 之前策略的 Log probs
importance_sampling_ratio = torch.exp(log_probs - old_log_probs)
clipped_sampling_ratio = torch.clamp(importance_sampling_ratio, 1 - epsilon, 1 + epsilon)
even_safer_advantages = clipped_sampling_ratio * advantages- 取最小值
这一点对我来说最让我惊讶。不是只使用裁剪后的 advantage,而是要在裁剪前后的版本之间取一个最小值 。原因很微妙:强化学习会尽力最大化奖励,如果你只提供裁剪后的奖励,它会把奖励尽量推到接近裁剪阈值的地方,这仍然会让整个训练过程不稳定(更多细节可以参考这里)。
python
old_log_probs = get_old_log_probs(prompts, responses).detach() # 之前策略的 Log probs
importance_sampling_ratio = torch.exp(log_probs - old_log_probs)
clipped_sampling_ratio = torch.clamp(importance_sampling_ratio, 1 - epsilon, 1 + epsilon)
# 取两者的最小值
safe_advantages_final_final = torch.min(importance_sampling_ratio * advantages, clipped_sampling_ratio * advantages)将上面内容整理在一起就是:
python
epsilon = 0.2 # Clipping threshold
for batch in dataloader:
prompts = batch
# prev_log_probs are part of the loss - non-differentiable
with torch.no_grad():
responses, prev_log_probs = model.generate(prompts)
rewards = discount(get_feedback(responses))
values = value_network(prompts)
advantages = rewards - values
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# ref_log_probs are used for regularization
with torch.no_grad():
ref_log_probs = get_old_log_probs(prompts, responses).detach()
for n in range(epochs):
for batch in make_minibatches(...):
log_probs = model(batch.prompts)[1]
ratio = torch.exp(log_probs - batch.prev_log_probs) # Importance ratio
clipped_ratio = torch.clamp(ratio, 1 - epsilon, 1 + epsilon)
# The min() function prevents the model from "gaming" the clipped update
loss = -torch.min(ratio * batch.advantages, clipped_ratio * batch.advantages).mean()
# + add value_network loss, ref model regularization and entropy boost...
optimizer.zero_grad()
loss.backward()
optimizer.step()如果你看到它以公式的形式写出来,希望现在就不会觉得那么可怕了!
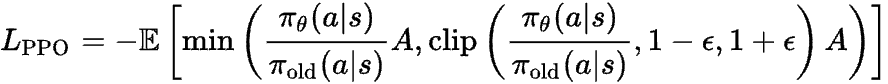
在 PPO 中,还有两个额外的损失函数。
价值损失(Value Loss) 用于在训练策略网络的同时,共同训练价值网络 。简单来说,你可以使用在各次生成中实际获得的回报来继续训练价值网络,因此它就是一个 均方误差(MSE)损失 :
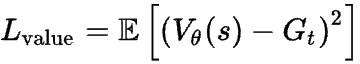
最后,作为另一个保护措施,我们还要防止强化学习过度改变模型权重:毕竟在预训练阶段让模型学习世界知识耗费了数百万美元的计算资源,我们不希望 RL 让模型偏离得太远。
一种简单的方法就是添加一个 KL 散度损失项 。
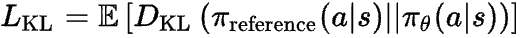
最终的PPO损失为:
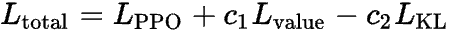
其中 c1 和 c2 是需要你通过实验设置的超参数,用来平衡这些损失项(通常取值较小)。
2. DeepSeek的GRPO
现在你已经掌握了所有基础知识,可以打开论文去阅读那些看似可怕的公式了。这是 DeepSeek 的 GRPO 公式(摘自他们的论文):

基于蒙塔卡洛的优势估计
GRPO 的"创新"是对奖励进行蒙特卡洛采样,这其实是一个老方法,早在价值网络出现之前就有人用过!价值网络本应更稳定,但你也可以想象,它的计算成本要高得多。在社区里对这个问题有一些讨论,目前还没有定论:谁知道价值网络是不是很快就会卷土重来呢!
运行成本
总结一下,在最坏的情况下,我们需要按顺序运行以下模型(这里只展示核心网络操作):
- 运行策略模型 ,生成 token 并获取 log-probsinference
→ 1 次前向传播 - 根据生成的token运行参考策略模型 ,获取 log-probsreference
→ 1 次前向传播 - 根据生成的token运行奖励模型 ,得到奖励
→ 1 次前向传播 - 运行价值模式 计算价值 → 优势估计
→ 1 次前向传播 - 开启梯度下,输入一批 token 运行策略模型,得到 log-prob
- 计算损失:
lp0 = f(log-probstrain, log-probsinference, advantage) + c2 L(log-probstrain, log-probsreference) - 反向传播
lp0,用 Adam 更新策略模型权重 - 计算价值损失:
lp1 = c1 L(value, advantage) - 反向传播
lp1,用 Adam 更新价值网络权重
如果像 GRPO 那样去掉价值函数,就省掉了步骤 4(1 次前向传播)和步骤 8-9(1 次反向传播 + 优化器更新),从而节省了大量的内存和计算资源。
附录B:
为什么生成比处理提示更耗资源?
如果你看看LLM云服务商的收费,你会发现输出 token 的价格总是比输入 token 贵得多,例如:GPT-5 的价格是每百万输入 token 1.25 美元,而每百万输出 token 10 美元。这是为什么呢?
原因在于自回归生成比处理已经存在的文本要昂贵得多!这是由 Transformer 的工作原理决定的。
- Transformer 总是需要处理整个序列,因此处理一段已有文本只需要一次前向传播(forward)。
- 生成新文本时 ,每生成一个 token 都需要一次前向传播。你生成一个新词后,把它加入已有序列,再次输入模型生成下一个词,如此循环 。这非常耗费计算资源,不过可以通过 KV Cache 来缓解。
需要注意,这与 RNN(如 LSTM)不同:
- 如果序列长度为 L,RNN 在生成下一个 token 时,只需处理这个新 token 并重用之前的状态即可。
- Transformer 是无状态的,每次都要输入整个序列,然后再前向一次生成第 L+1 个 token!
幸运的是,大量计算可以被复用,因此 KV Cache 可以大幅缓解这个问题(否则我们根本无法在生产环境中部署这些模型),但它依然是一个性能瓶颈。
举个例子,你有一个系统提示词:
"You are a nice LLM, be kind"
然后用户输入:
"What's the capital of France?"
模型会收到以下输入来开始生成:
"You are a nice LLM, be kindWhat's the capital of France?"
这整个序列可以一次前向传播(forward)完成处理,因为所有 token 都在其中。现在,你生成第一个 token:
"The"
为了生成下一个 token,你需要再次用整个序列进行前向传播!此时模型需要输入:
"You are a nice LLM, be kindWhat's the capital of France?The"
模型会生成 capital(实际上会先生成一个空格,但为了演示速度,我们就这样简化)。
接着,再次生成下一个 token,输入变为:
"You are a nice LLM, be kindWhat's the capital of France?The capital"
你可以看到,这样生成每个 token 都非常耗计算资源......