本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
很多人一听到 LLM 就只想到"提示词工程"。认为写好prompt就够了,可当你去面试AI产品经理岗位时,你才会发现远不止"写提示词"这么简单。对于企业生产级系统要求工程化、部署、优化与可观测性形成闭环,否则模型在真实场景里很容易翻车。今天我将总结一下掌握LLM产品的实现路径。
一、提示词工程(Prompt Engineering)
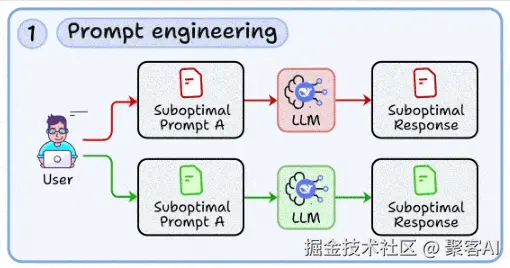
提示词不应被视为临时编写的文案,而应作为可复现、可测试的工程化模块。结构良好的提示能显著降低模型输出的不确定性,提高响应的一致性与可用性。
示例对比:
不建议写法:写一个手机描述
建议写法:
- 任务:生成产品描述(JSON 格式输出)
- 字段要求:name, 性能, 外观, 价格, 最多3个卖点
- 约束:每个卖点为短句,性能部分需列出至少2项技术参数
- 示例: { "name": "示例手机", "性能": "8GB RAM", "5000mAh", ... }
实用技巧:
- 使用模板与变体进行A/B测试,评估不同写法效果。
- 仅在需要模型推理过程可解释时启用"思维链"(Chain-of-Thought),以节省token。
- 对prompt进行版本控制,结合测试用例进行回归验证。
常见误区:
将上下文与指令混杂,导致模型难以区分重点。务必明确区分系统指令与用户输入。
二、上下文工程(Context Engineering)
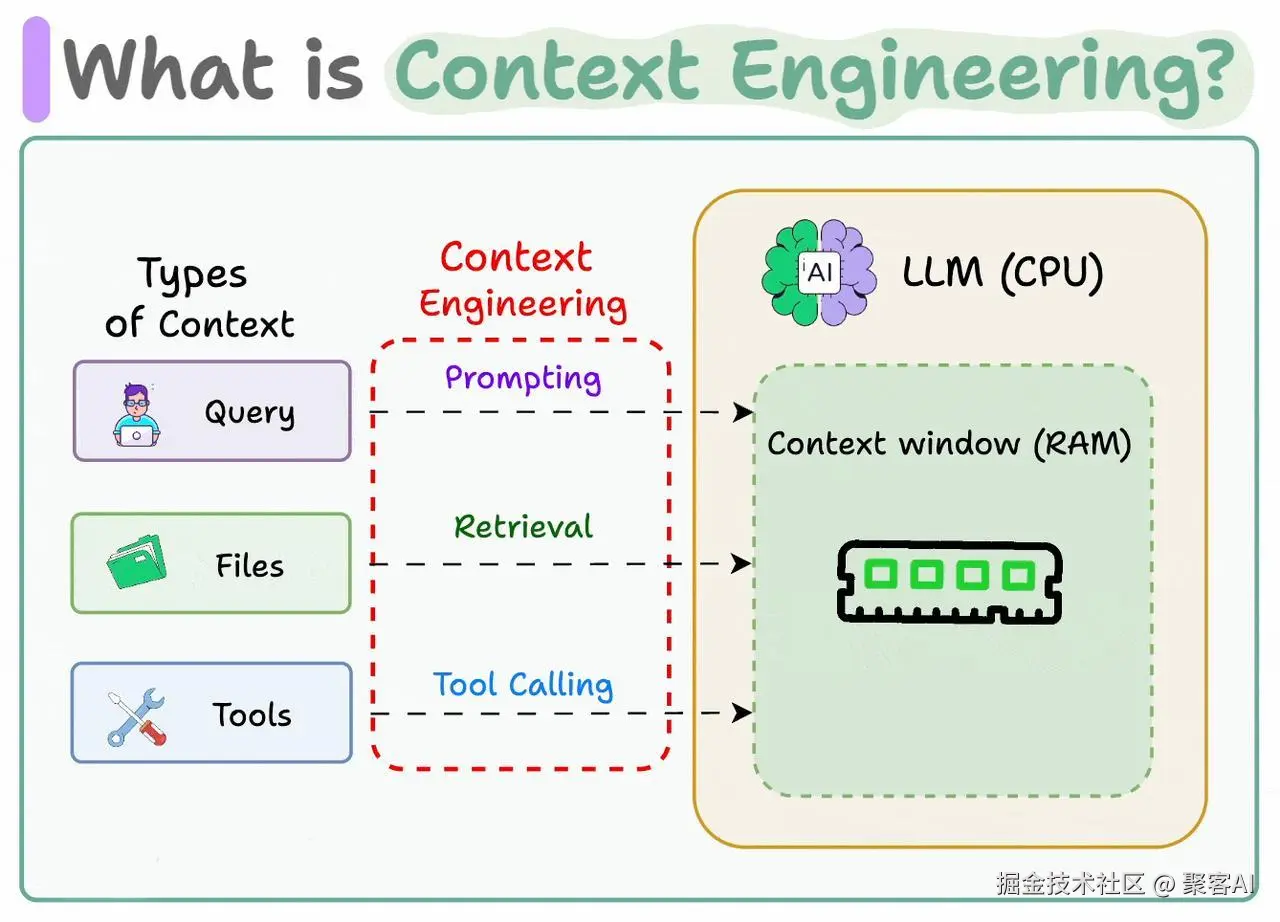
LLM本身"记忆"有限,需动态引入外部信息(如数据库、近期交互等),并确保上下文简洁、相关,以提升回答准确性并减少幻觉。
典型做法:
- 在客服场景中,提取用户最近3次关键交互的摘要。
- 将关键订单信息作为结构化数据嵌入prompt。
- 对长文档先进行检索或摘要,再选择关键段落注入。
实用技巧:
- 采用滑动窗口或时间加权机制管理上下文长度。
- 使用高召回检索后再进行精排与过滤。
- 限制上下文token数量,优先注入结构化信息。
常见误区:
上下文过长或噪声过多会导致"上下文坍塌",模型忽略早期重要信息。
ps:如果你不了上下文工程在Agent中的工作原理,强烈建议你看看我之前整理过的一个技术文档:《图解Agent上下文工程,小白都能看懂》
三、微调技术(Fine-tuning)
微调假设您将继续在特定学习任务上训练LLM。例如,您可能希望在以下任务上微调LLM:
- 英语-西班牙语翻译
- 自定义支持消息路由
- 专业问答
- 文本情感分析
- 命名实体识别
- 请输入具体的网页文本内容,以便我进行翻译。
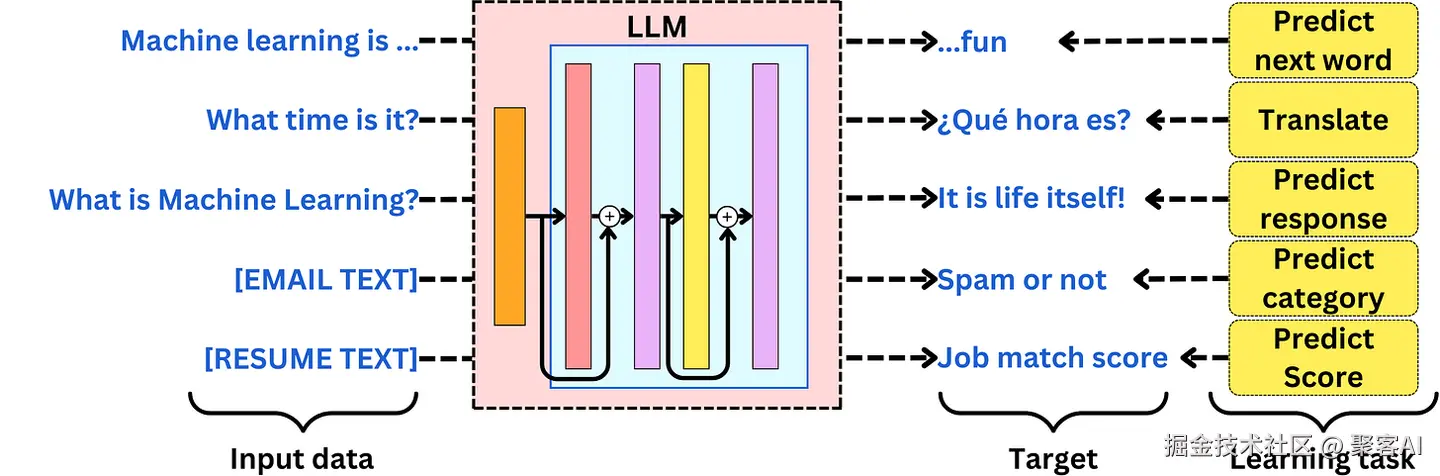
微调假设你有训练数据来使LLM专门用于特定的学习任务。这意味着你需要能够识别正确的输入数据、适当的学习目标和正确的训练过程。
关键流程:
- 数据清洗与格式化,构建"指令-响应"对。
- 选择微调方法,如LoRA/QLoRA等参数高效方法,或全参数微调。
- 使用验证集监控过拟合与泛化能力。
- 灰度发布,观察线上表现。
实用技巧:
- 训练数据需保持多样性,避免模型机械记忆。
- 可采用混合训练策略,保留原有通用能力。
- 引入对抗样本测试,增强模型鲁棒性。
常见误区:
低质量训练数据会放大错误行为;未设置回滚机制可能导致线上事故难以恢复。
四、RAG系统(Retrieval-Augmented Generation)
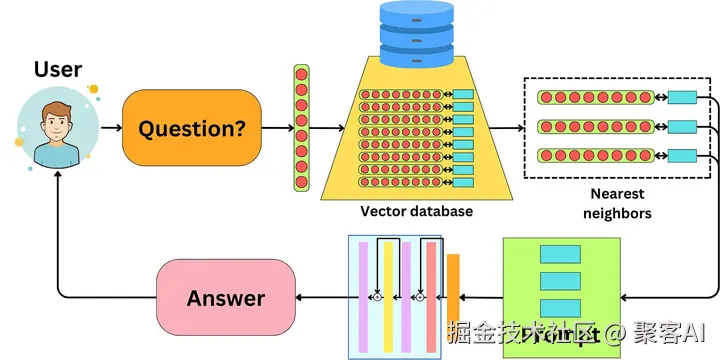
检索增强生成 (RAG) 指的是将 LLM 暴露在数据库中存储的新数据上。我们不修改LLM;相反,我们在提示中为LLM提供额外的数据上下文,以便LLM能够根据主题信息回答问题。
RAG 的想法是将您希望向 LLM 暴露的数据编码为嵌入,并将该数据索引到向量数据库中。
当用户提出一个问题时,它会被转换为一个嵌入,我们可以用它在数据库中搜索相似的嵌入。一旦我们找到相似的嵌入,我们会用相关的数据构造一个提示,为LLM提供上下文来回答问题。这里的相似性通常使用余弦相似性度量。
关键组成:
- 文档切分(chunking):按语义与长度合理分段。
- 嵌入与索引:选用适合的embedding模型与向量数据库(如FAISS、Milvus)。
- 查询重构:优化检索query以提高召回。
- 上下文融合:在prompt中明确约束模型仅依据提供证据作答。
示例prompt片段:
ini
请依据以下证据回答问题。若证据不足,请说明并建议后续操作。
证据1: [...]
证据2: [...]
问题: [...]实用技巧:
- 对检索结果进行可信度评估(如时效、来源权威性)。
- 建立定期更新索引机制。
- 设置相似度阈值与去重策略。
常见误区:
直接使用无关或过时证据,可能导致"具备依据的幻觉"。
ps:关于RAG的优化,我之前也写过很多,这里也把我写的一份几万字的RAG优化文档分享给我的粉丝朋友,自行领取:《检索增强生成(RAG)》
五、智能体开发(Agent Development)
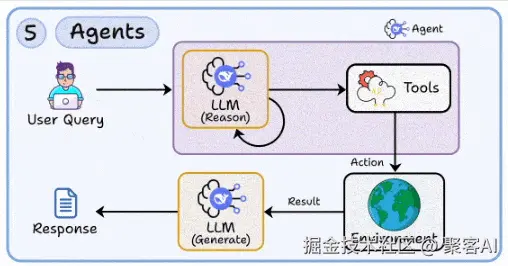
智能体具备多步推理、工具调用与状态管理能力,可处理复杂任务流程。
核心能力:
- 工具调用:如搜索、数据库查询、API调用等。
- 状态管理:维护会话上下文与任务进度。
- 错误恢复:设计降级方案与回退机制。
- 可观测性:记录每一步的输入、输出与决策逻辑。
流程示意:
解析意图 → 选择工具 → 执行 → 结果汇总 → 输出或继续。
实用技巧:
- 将外部服务封装为统一工具接口。
- 采用标准化协议(如MCP)规范消息交互。
- 建立决策回放机制,便于调试。
常见误区:
智能体过度依赖外部服务,缺乏故障隔离与观测手段,导致链路脆弱。
六、LLM部署(Deployment)
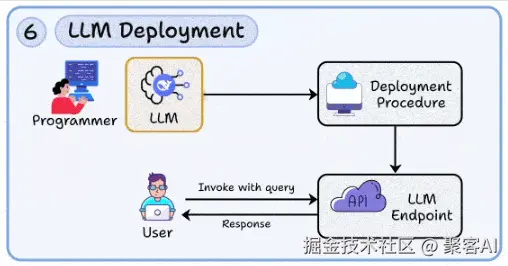
生产环境中的模型服务需满足高并发、低延迟、高可靠与成本可控等要求。
关键实践:
- 使用Docker容器化与Kubernetes编排,支持弹性扩缩容。
- 通过批处理、异步请求等方式优化延迟。
- 实现资源隔离,区分高低优先级任务。
- 强化安全与治理:API鉴权、限流与反滥用机制。
实用技巧:
- 监控token消耗与推理时长,制定用量控制策略。
- 准备轻量模型作为降级方案。
- 实施灰度发布与快速回滚。
常见误区:
直接部署未经负载测试的模型,易导致服务不稳定或成本失控。
七、LLM优化(Optimization)
通过模型压缩与推理加速技术,实现在精度与效率之间的平衡。
常用方法:
- 量化(8-bit/4-bit)降低内存占用。
- 剪枝与稀疏化,移除冗余参数。
- 知识蒸馏,训练轻量学生模型。
- 推理优化:混合精度、动态批处理等。
实用技巧:
- 任何优化前需建立回归测试基准。
- 采用分阶段策略,逐步评估量化、剪枝、蒸馏的影响。
- 边缘设备优先考虑蒸馏+量化组合。
常见误区:
过度压缩导致模型在关键场景中性能显著下降。
八、LLM可观测性(Observability)
建立全链路监控体系,是实现模型持续迭代与风险管控的基础。
必需监控指标:
- 输入输出日志(含prompt版本与上下文)。
- 延迟、错误率、token消耗。
- RAG检索质量(召回率、精确率)。
- 用户端指标:满意度、人工干预率等。
实用技巧:
- 日志记录需脱敏处理敏感数据。
- 构建会话回放能力,支持在测试环境重现问题。
- 设置异常告警,并将典型错误案例推送审核。
常见误区:
仅记录系统级指标,缺乏prompt与上下文信息,导致无法追溯模型决策原因。
总结:从提示词到生产级LLM系统
掌握以上八大支柱,意味着你不再只是一个"提示词写手",而是一名能够构建可靠、高效、可迭代LLM产品的工程师。好了,今天的分享就到这里,如果对你有所帮助,点个小红心,我们下期见。