Windows 系统部署 阿里团队开源的先进大规模视频生成模型 Wan2.2 教程 ------ 基于EPGF 架构
一、环境准备
基于 EPGF 架构(统一环境管理架构),需搭配以下工具以确保环境一致性:
【EPGF 白皮书】路径治理驱动的多版本 Python 架构------ Windows 环境治理与 AI 教学开发体系
【00】EPGF 架构搭建教程之 总揽篇
-
基础工具链
-
**CUDA 依赖(GPU 用户必做)**安装对应 CUDA 13.0 的 cuDNN。
-
系统上的其他必备开发组件。
二、 Wan2.2 仓库介绍

Wan2.2 是一个开源的先进大规模视频生成模型仓库,专注于提供高效、高质量的视频生成能力,支持文本转视频、图像转视频、语音转视频等多种任务。以下是其核心信息整理:
核心特点
-
混合专家(MoE)架构创新性地将混合专家架构引入视频扩散模型,通过按时间步分离去噪过程并使用专门的专家模型,在保持计算成本不变的情况下提升了模型容量,优化了生成效率。
-
电影级美学表现基于精心筛选的美学数据训练,支持对光线、构图、对比度、色调等细节的精确控制,可生成具有定制化美学风格的视频内容。
-
复杂动作生成能力相比前代模型(Wan2.1),训练数据规模显著扩大(图像增加 65.6%,视频增加 83.2%),在动作、语义和美学等维度的泛化能力大幅提升,性能处于开源和闭源模型前列。
-
高效高清混合 TI2V开源 5B 参数模型结合先进的 Wan2.2-VAE(压缩比 16×16×4),支持 720P 分辨率、24fps 的文本 - 图像转视频生成,可在消费级显卡(如 4090)上运行,是目前最快的 720P@24fps 模型之一。
支持的模型与任务
仓库提供多种预训练模型,覆盖不同生成场景:
| 模型名称 | 任务类型 | 支持分辨率 | 下载地址 (Hugging Face / ModelScope) |
|---|---|---|---|
| T2V-A14B | 文本转视频 | 480P、720P(如 1280×720、720×1280 等) | Hugging Face / ModelScope |
| I2V-A14B | 图像转视频 | 同上 | Hugging Face / ModelScope |
| TI2V-5B | 文本 - 图像混合转视频 | 720P(如 1280×704、704×1280 等) | Hugging Face / ModelScope |
| S2V-14B | 语音转视频 | 480P、720P 等多种分辨率 | Hugging Face / ModelScope |
| Animate-14B | 角色动画与替换 | 720P(如 1280×720、720×1280) | Hugging Face / ModelScope |
三、部署教程
克隆仓库与快速唤起开发环境
项目地址:
https://github.com/Wan-Video/Wan2.2.git
1. 用 GitHub Desktop 克隆仓库(EPGF 架构适配流程)
- 打开 GitHub Desktop,点击左上角 "File"→"Clone repository"
- 选择 "URL" 标签,输入仓库地址:
https://github.com/Wan-Video/Wan2.2.git - 选择本地保存路径(建议放在 EPGF 架构的项目目录下,如H:\PythonProjects1\Wan2.2),点击 "Clone" 开始克隆
- 克隆完成后,点击 GitHub Desktop 界面右边的 "Open in external editor"(需提前在 GitHub Desktop 中关联默认 IDE),直接唤起 PyCharm 打开项目
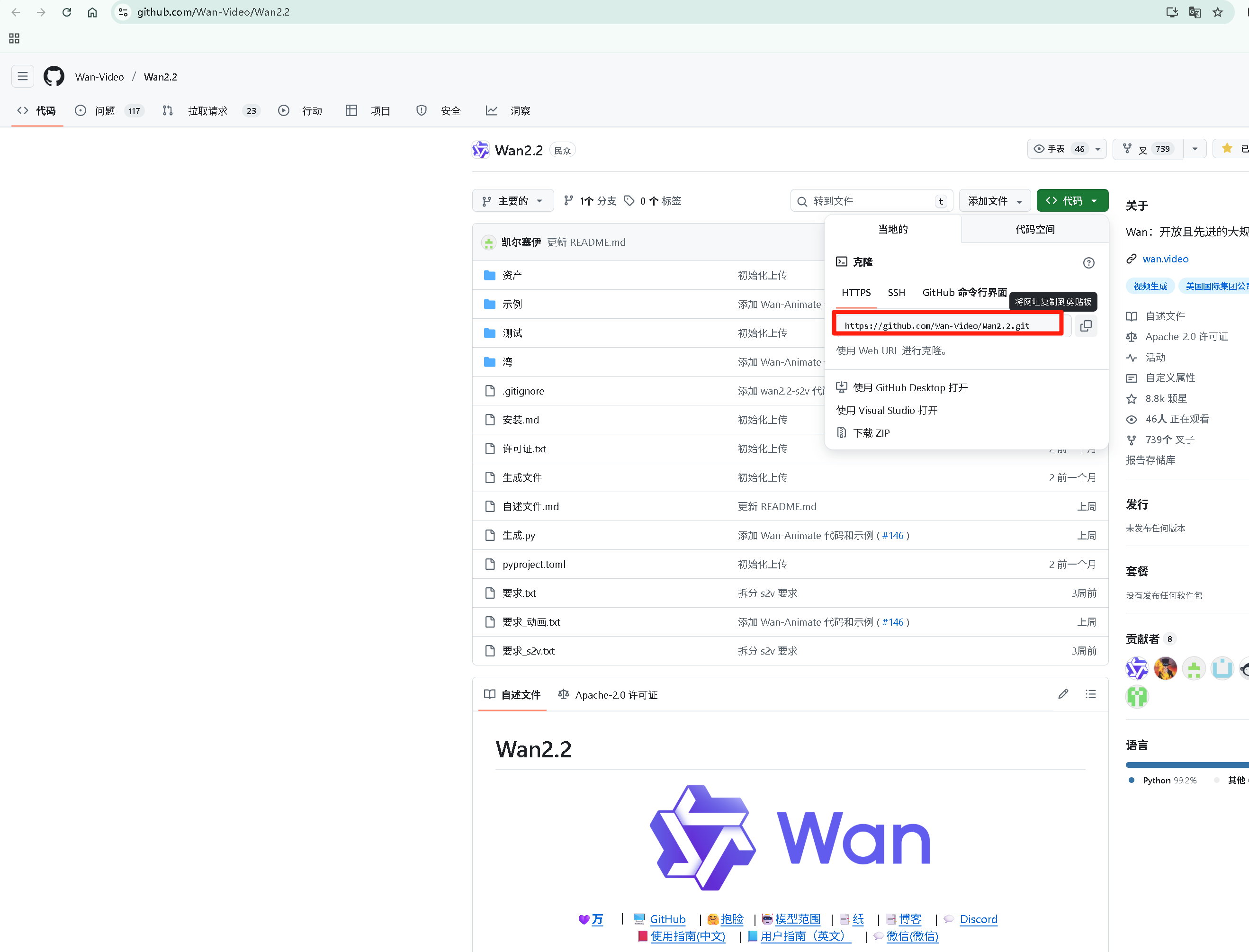 复制克隆链接
复制克隆链接
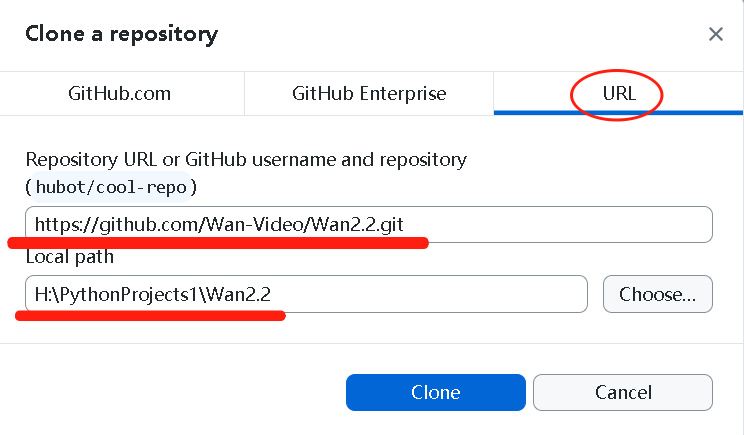 在 URL 处输入 从项目官网 复制的 克隆链接 并设置储存位置
在 URL 处输入 从项目官网 复制的 克隆链接 并设置储存位置
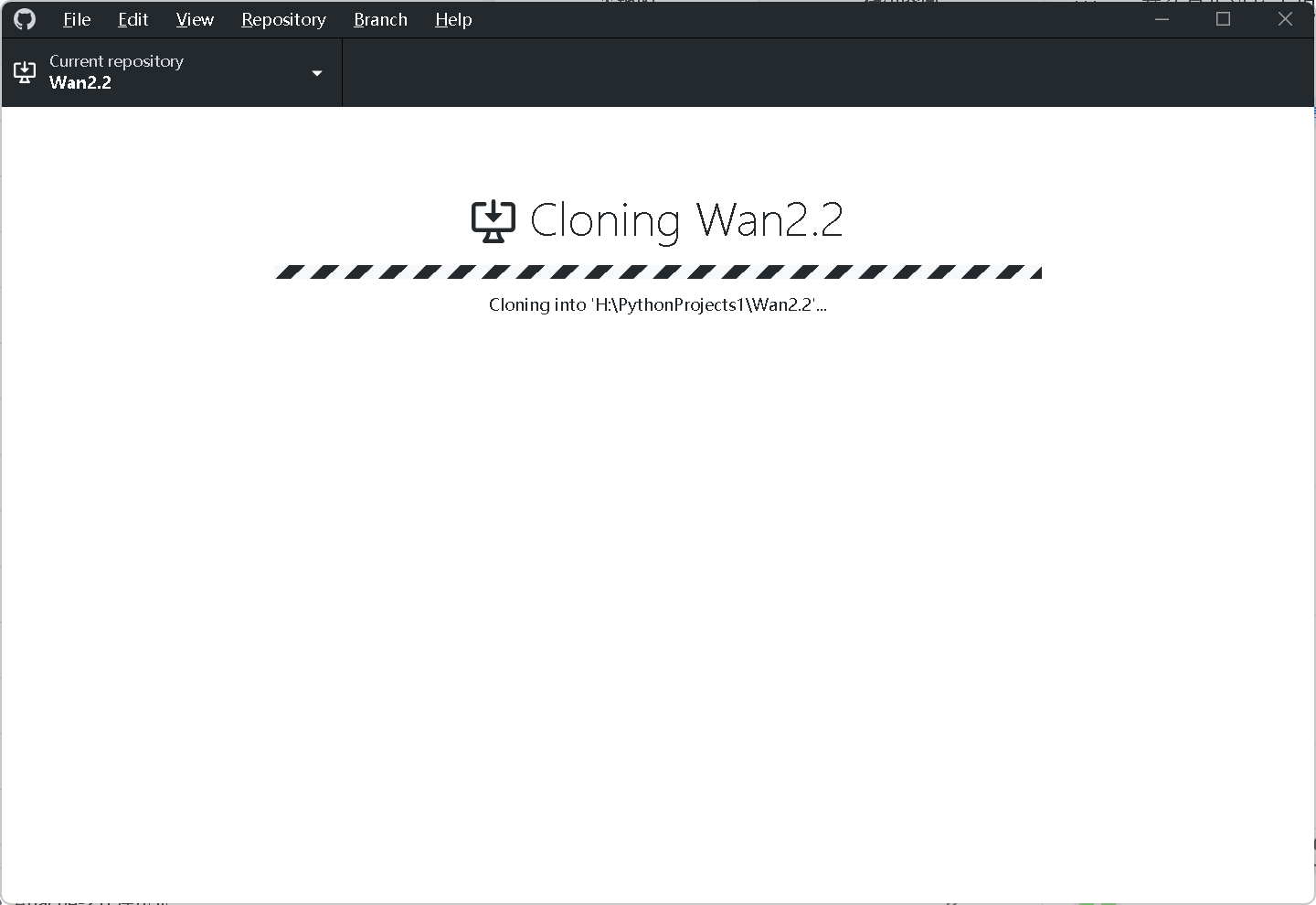 GitHub Desktop 快速克隆中
GitHub Desktop 快速克隆中
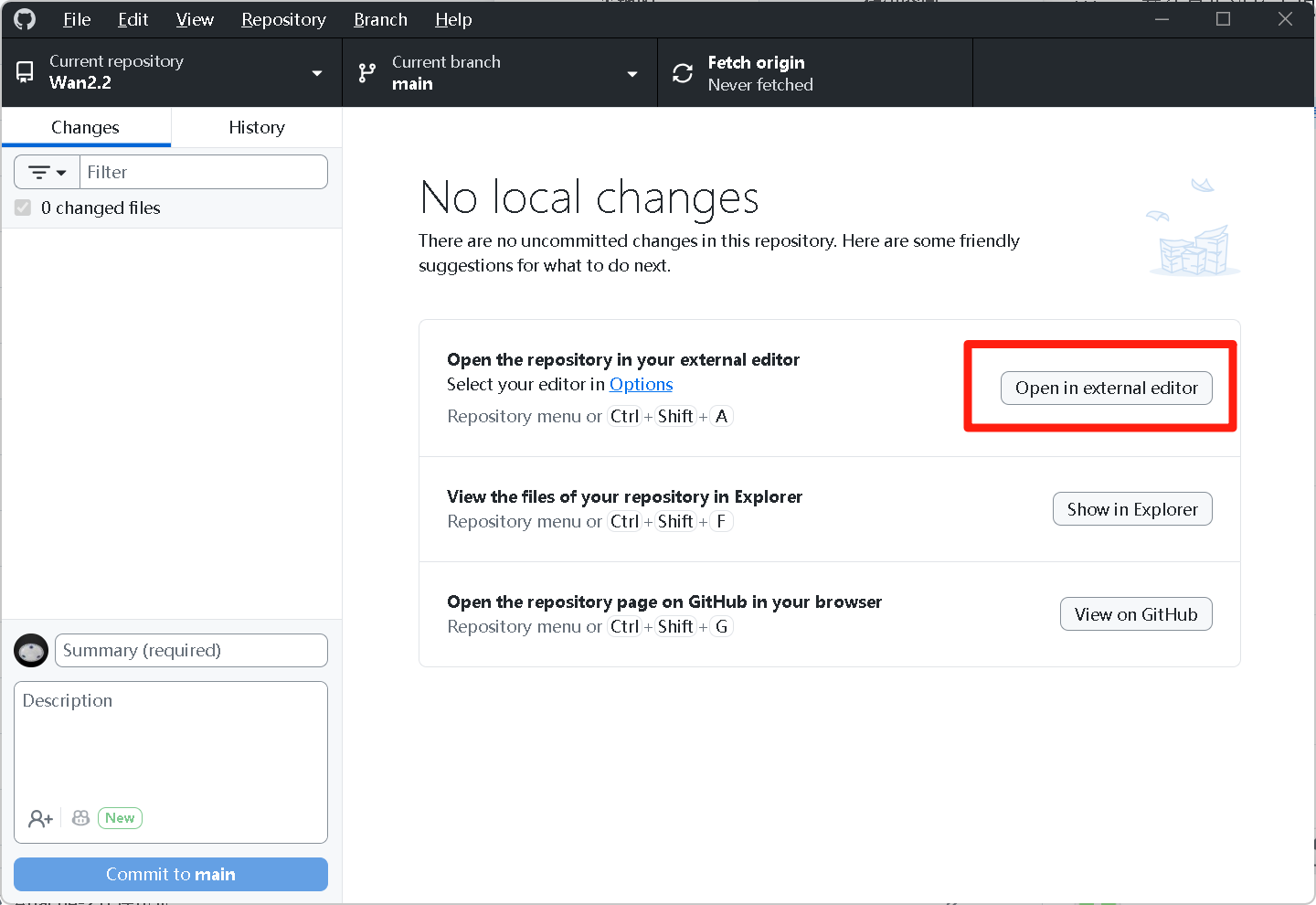 克隆完成后 点击界面右边的 Open in external editor 打开 IDE (PyCharm)
克隆完成后 点击界面右边的 Open in external editor 打开 IDE (PyCharm)
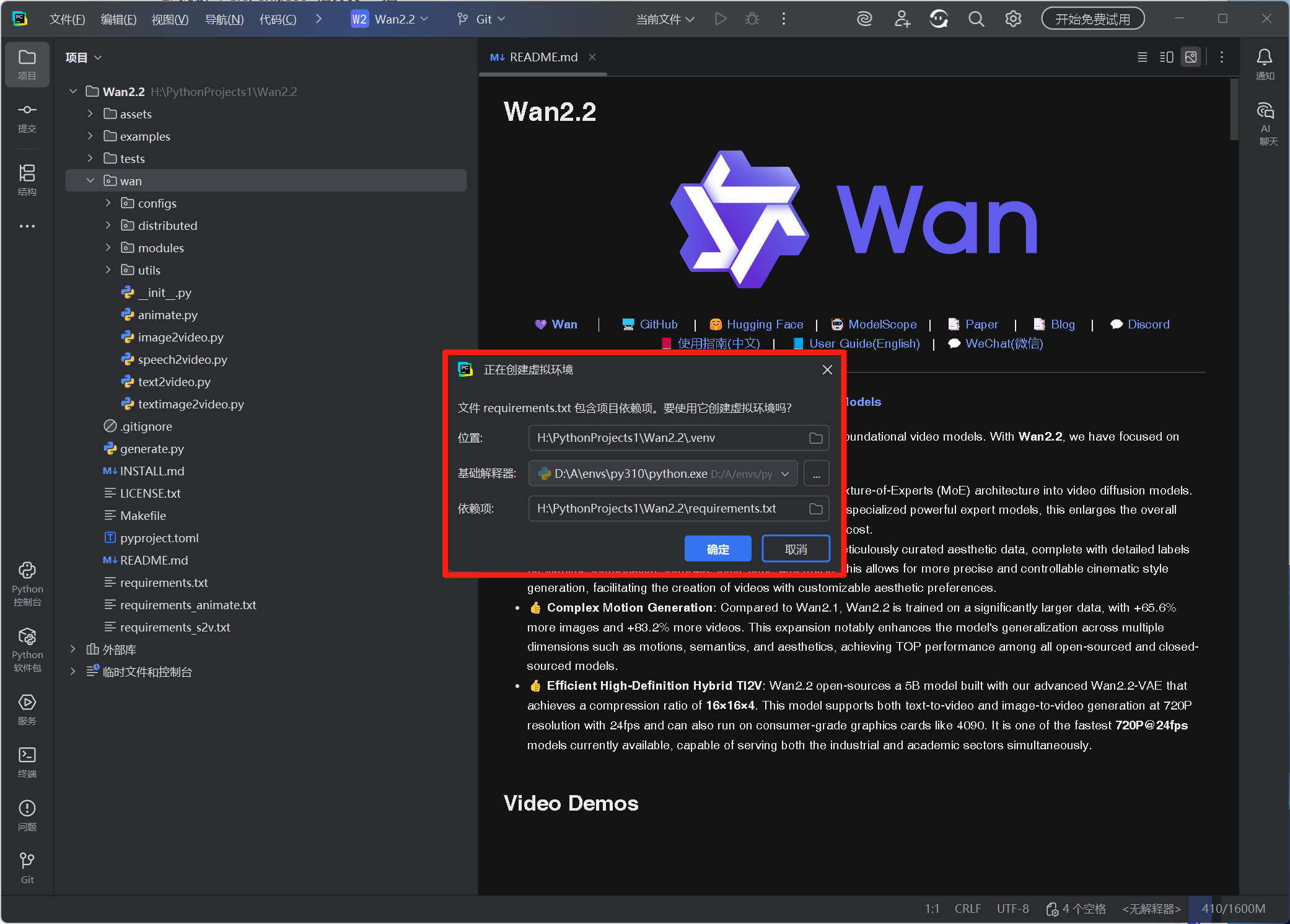
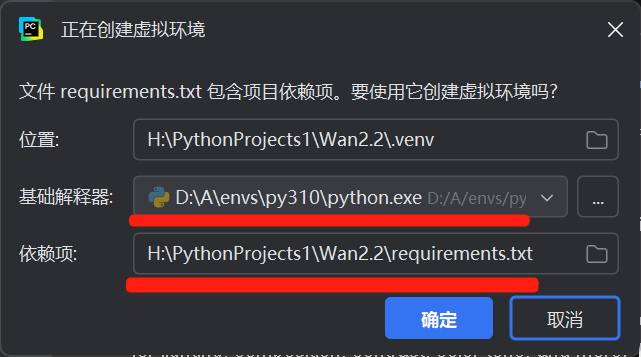
2. 基于 EPGF 架构创建虚拟环境
- PyCharm 打开项目后,会自动检测 requirements.txt 文件,并弹出新建虚拟环境的引导窗口 "Create virtual environment" 提示
- 基础解释器位置:选择选择 EPGF 架构预设的 Python 3.10(路径通常为D
:\A\envs\py310\python.exe) - 依赖项:确认路径是本项目的 requirements.txt 文件位置,然后点击 "确定",项目会在
.venv目录创建隔离环境 - 验证环境关联:点击 PyCharm 右下角 "Python 3.10(.venv)",确认解释器路径为项目内
.venv\Scripts\python.exe,说明 EPGF 架构的环境隔离生效
四、依赖安装(核心优化步骤)
1. 修改 requirements.txt 适配 Windows
在 PyCharm 左侧项目树中打开requirements.txt,按以下内容注释冲突依赖(利用 EPGF 架构的依赖管理避免版本冲突):
第 1 行
第 2 行
第 3 行
第 15 行
#torch>=2.4.0 # 由EPGF统一管理PyTorch版本
#torchvision>=0.19.0
#torchaudio
opencv-python>=4.9.0.80
diffusers>=0.31.0
transformers>=4.49.0,<=4.51.3
tokenizers>=0.20.3
accelerate>=1.1.1
tqdm
imageio[ffmpeg]
easydict
ftfy
dashscope
imageio-ffmpeg
#flash_attn # Windows需手动安装适配版本
numpy>=1.23.5,<2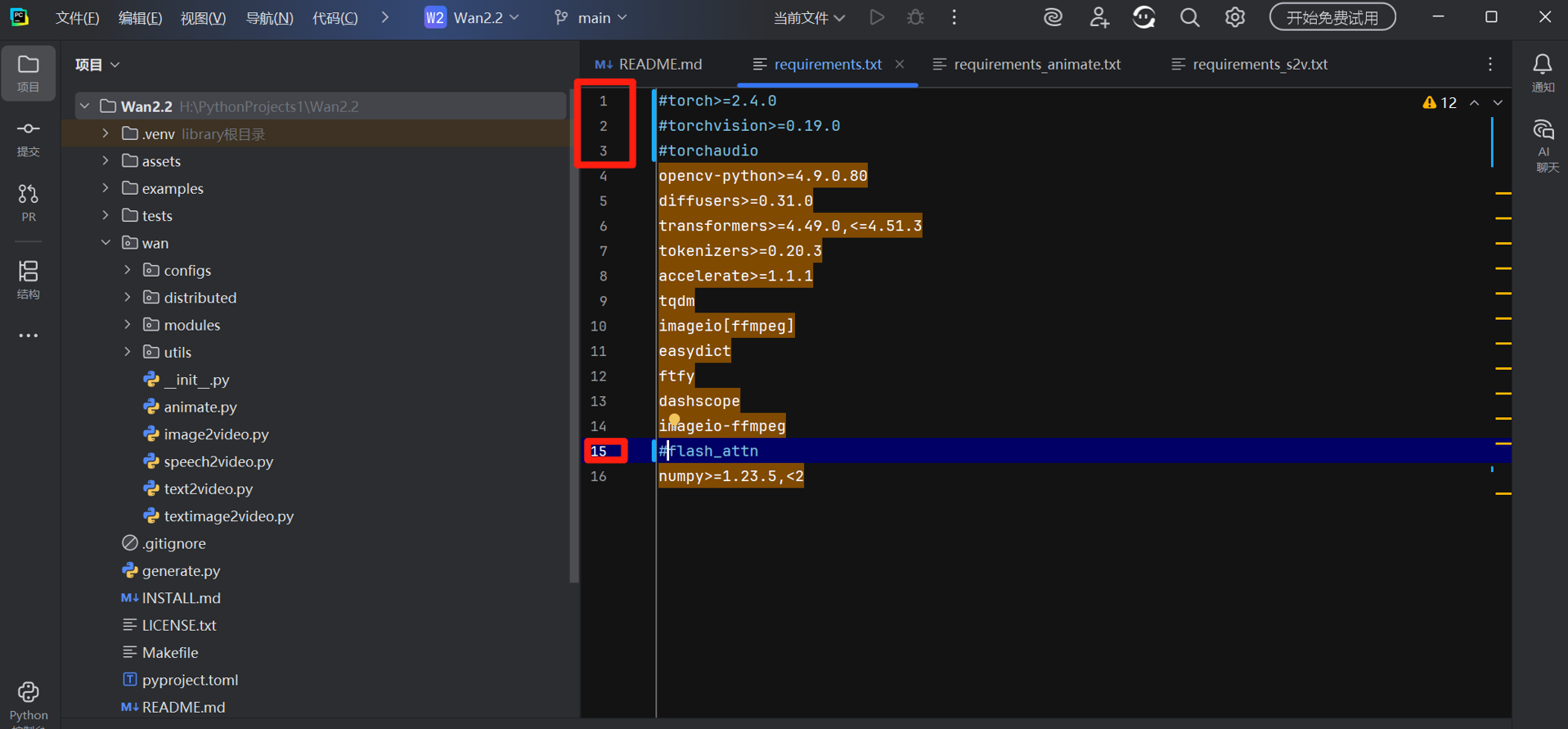
2. 安装 GPU 版 PyTorch
-
打开 PyCharm 底部 "Terminal"(CMD )(默认已激活
.venv环境,显示(.venv)) -
执行适配 CUDA 12.9 的安装命令(EPGF 架构已配置 PyPI 镜像加速):
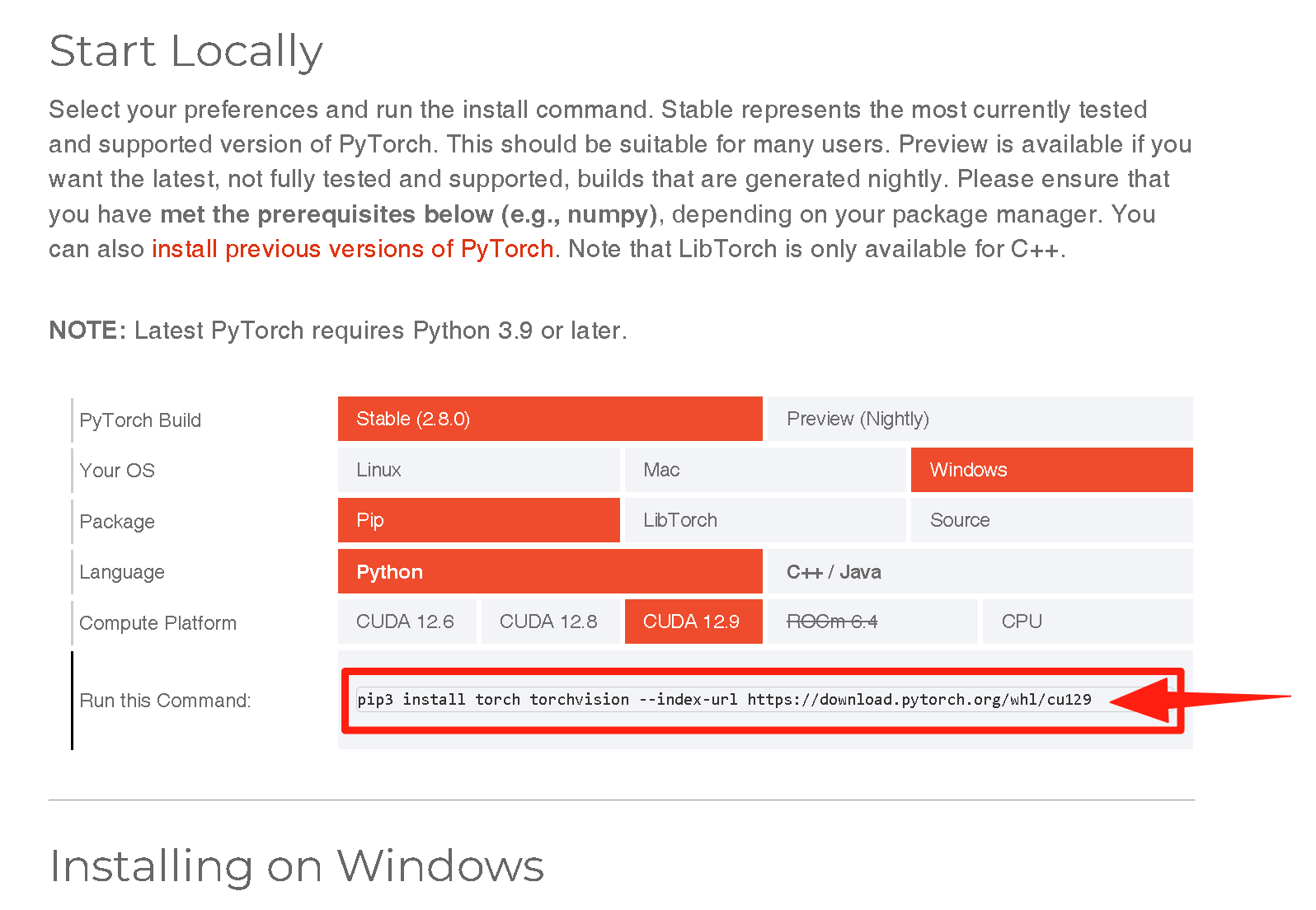
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu129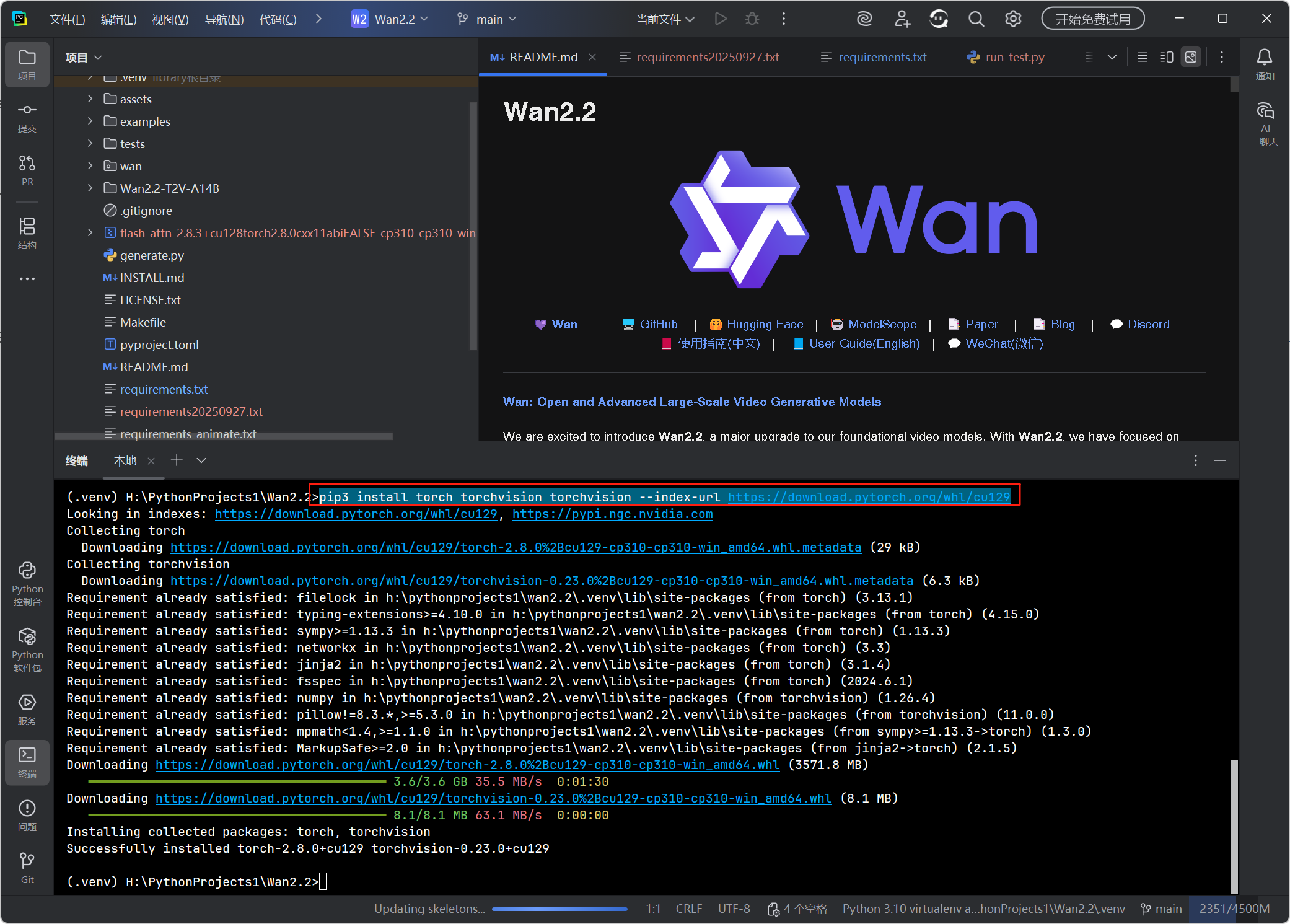
-
验证 PyTorch 的 CUDA GPU 支持 安装是否成功:
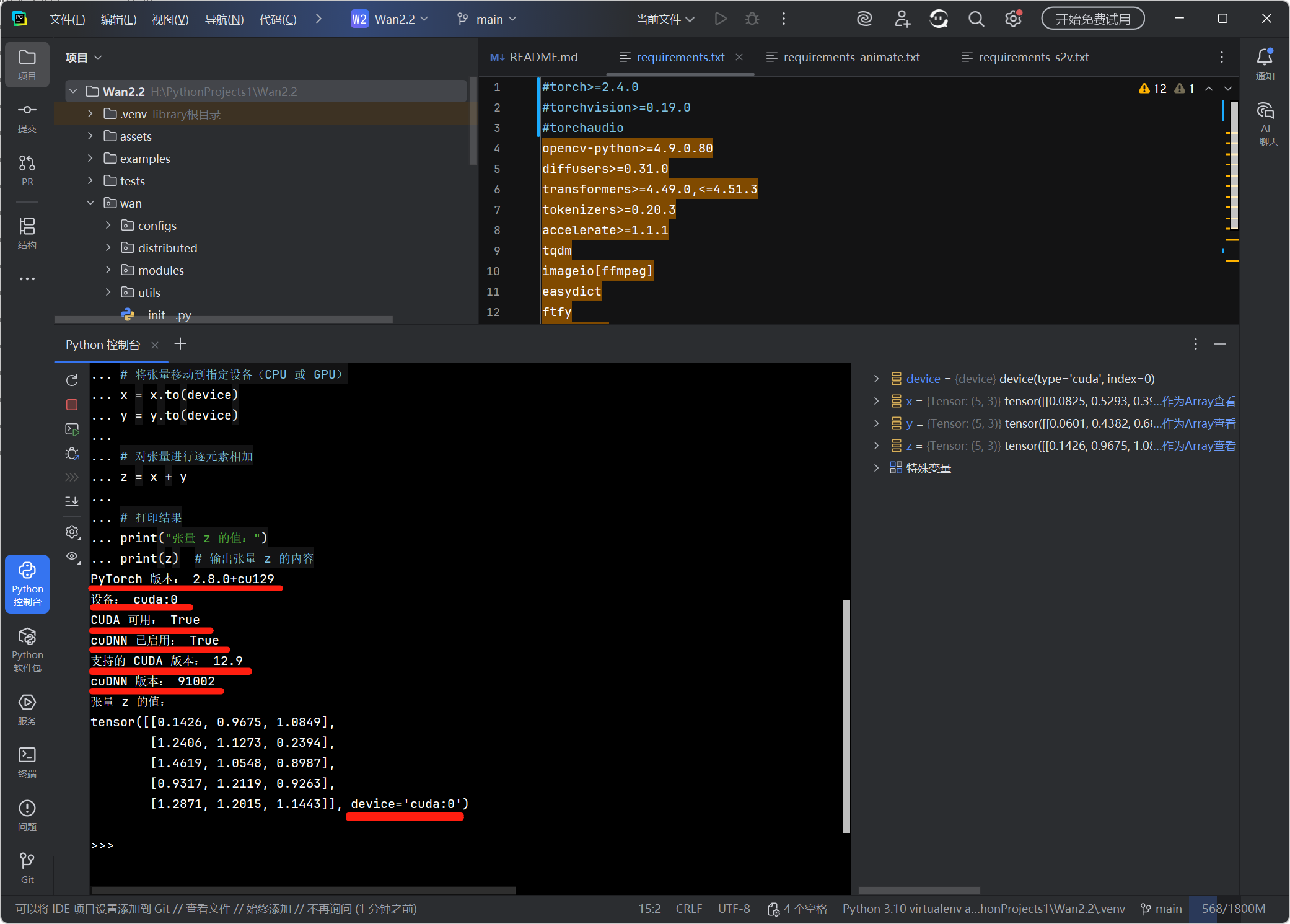
打开 PyCharm 左侧工具栏中的 "Python 控制台" 窗口,完整复制、粘贴 以下代码并按回车键:
import torch # 导入 PyTorch 库 print("PyTorch 版本:", torch.__version__) # 打印 PyTorch 的版本号 # 检查 CUDA 是否可用,并设置设备("cuda:0" 或 "cpu") device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print("设备:", device) # 打印当前使用的设备 print("CUDA 可用:", torch.cuda.is_available()) # 打印 CUDA 是否可用 print("cuDNN 已启用:", torch.backends.cudnn.enabled) # 打印 cuDNN 是否已启用 # 打印 PyTorch 支持的 CUDA 和 cuDNN 版本 print("支持的 CUDA 版本:", torch.version.cuda) print("cuDNN 版本:", torch.backends.cudnn.version()) # 创建两个随机张量(默认在 CPU 上) x = torch.rand(5, 3) y = torch.rand(5, 3) # 将张量移动到指定设备(CPU 或 GPU) x = x.to(device) y = y.to(device) # 对张量进行逐元素相加 z = x + y # 打印结果 print("张量 z 的值:") print(z) # 输出张量 z 的内容
3. 安装核心依赖与补充库
# 安装基础依赖
pip install -r requirements.txt
# 安装triton(Windows适配版,解决模型推理加速依赖)
pip install -U "triton-windows==3.1.0.post17"
# 安装peft(参数高效微调库,解决ModuleNotFoundError)
pip install peft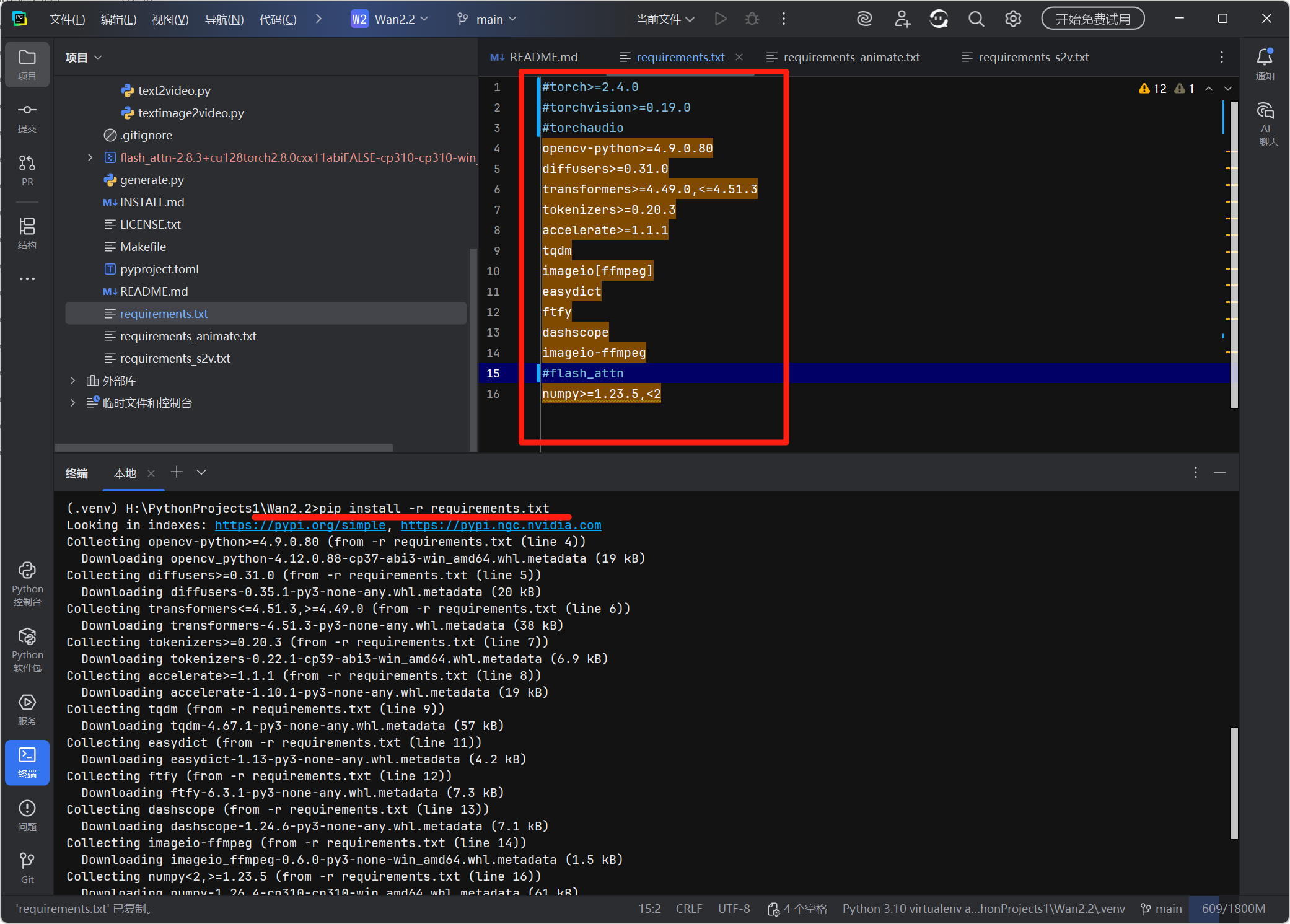
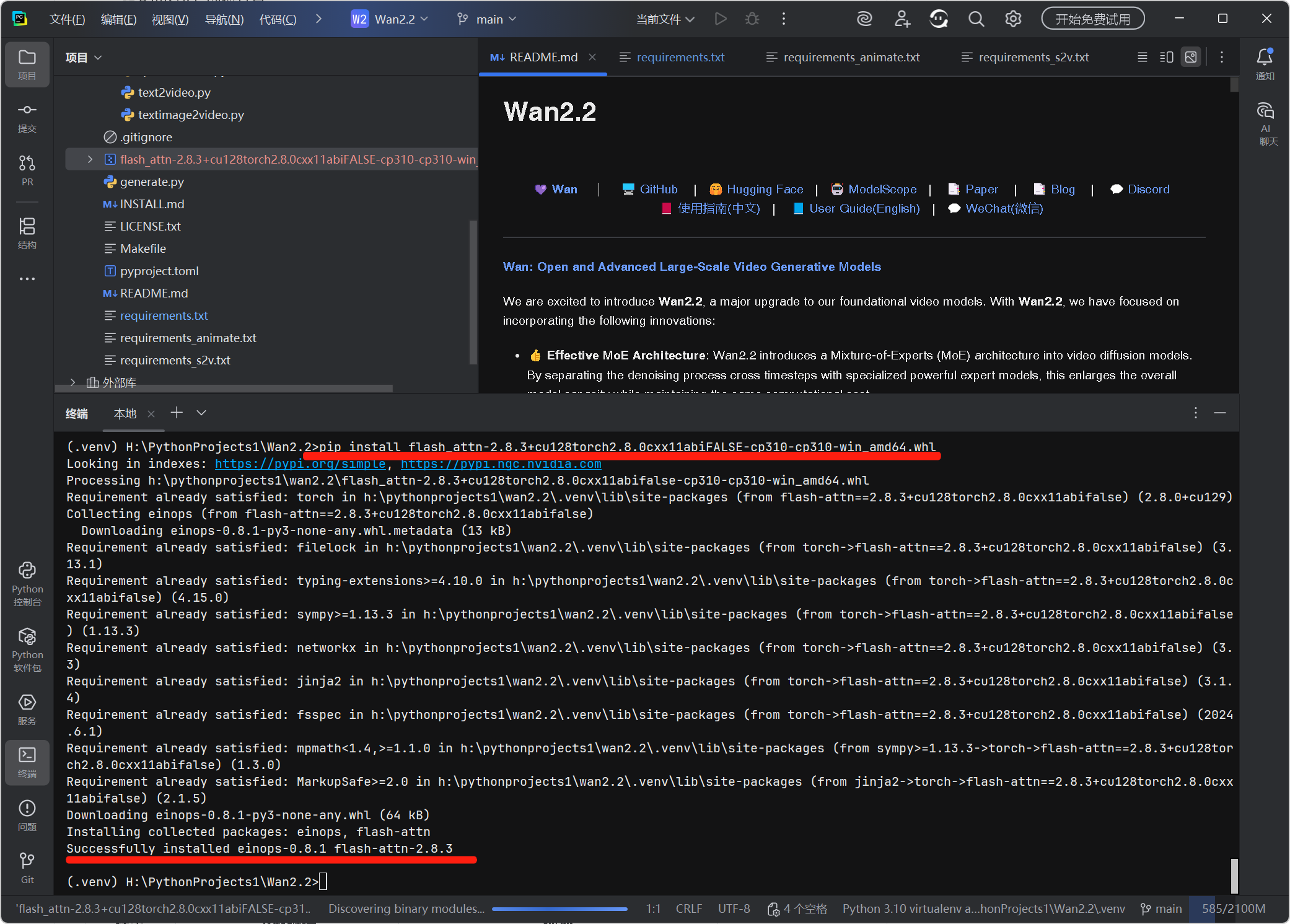
4. 手动安装 flash_attn(Windows 专属步骤)
-
访问kingbri1/flash-attention/releases,下载与 EPGF 架构 Python 版本匹配的 whl:
flash_attn-2.8.3+cu128torch2.8.0cxx11abiFALSE-cp310-cp310-win_amd64.whl -
将文件放入项目根目录,在 Terminal 中安装:
pip install flash_attn-2.8.3+cu128torch2.8.0cxx11abiFALSE-cp310-cp310-win_amd64.whl
5. 安装语音转视频依赖(可选)
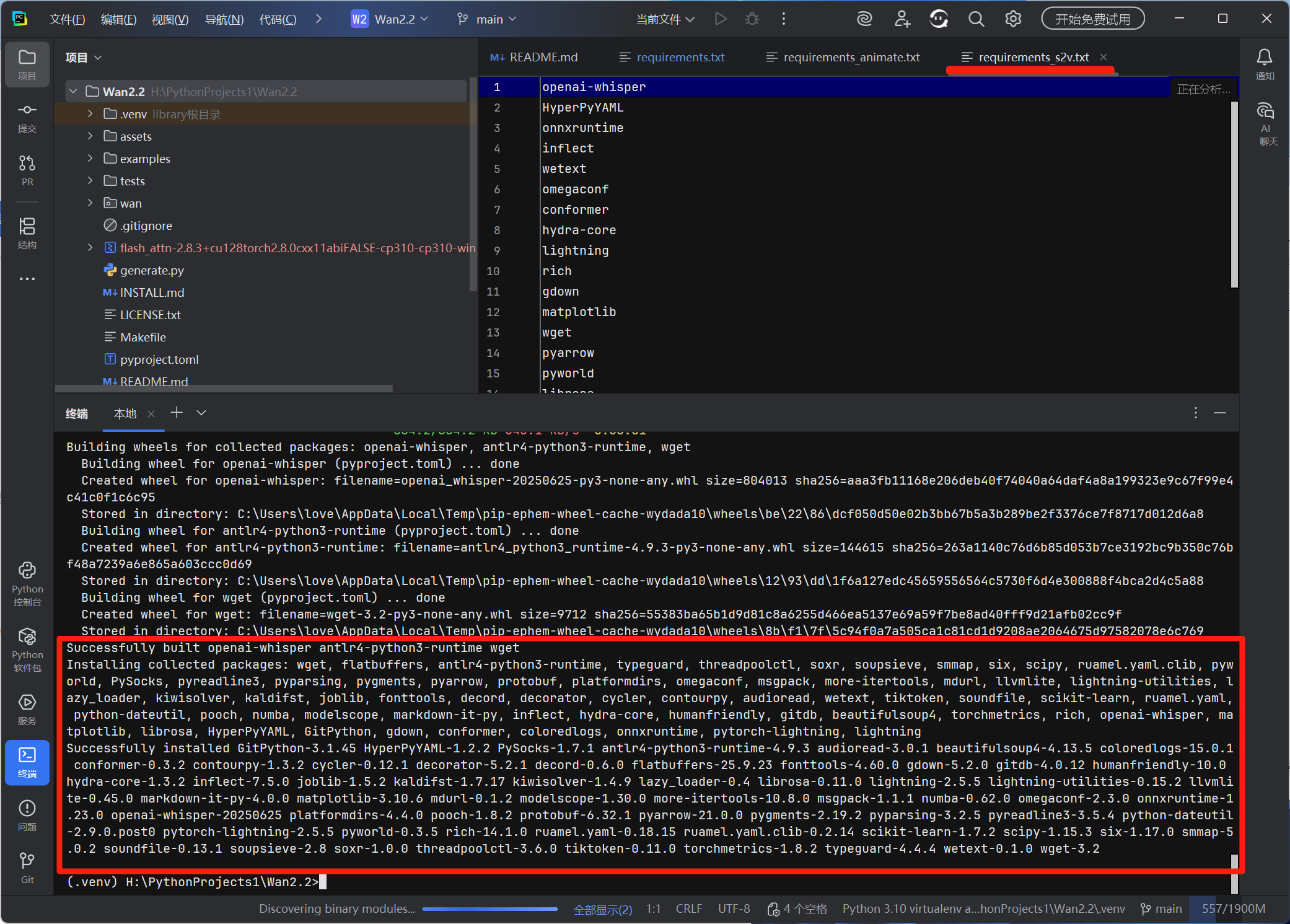
pip install -r requirements_s2v.txt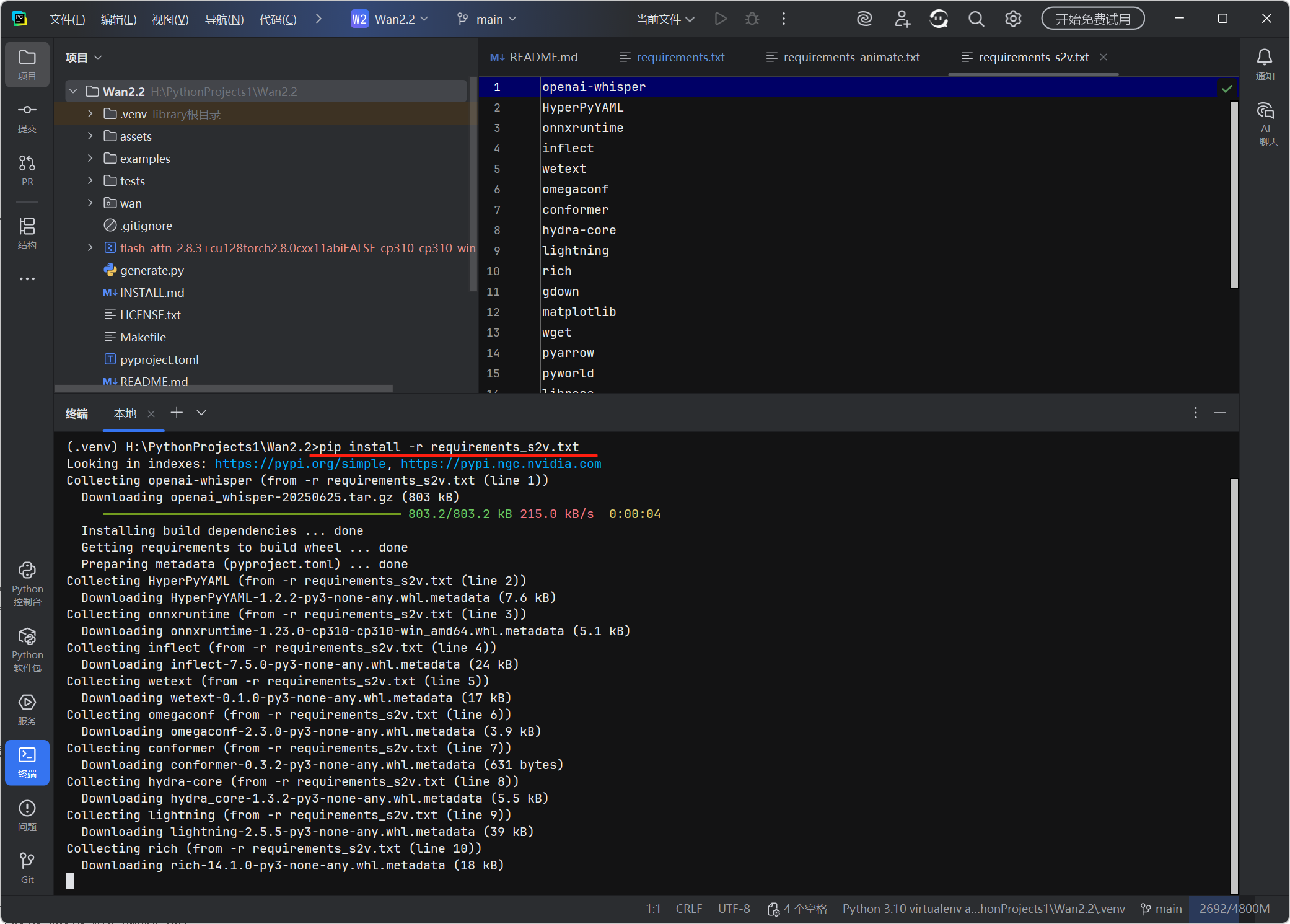
五、模型下载(EPGF 架构路径规范)
Windows 如何更改 Hugging Face 模型下载缓存位置?
Windows 如何更改 ModelScope 的模型下载缓存位置?
1. Hugging Face 工具链下载
# 安装下载工具
pip install "huggingface_hub[cli]" hf-xet
# 按EPGF路径规范下载模型(统一放在项目内模型目录)
hf download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B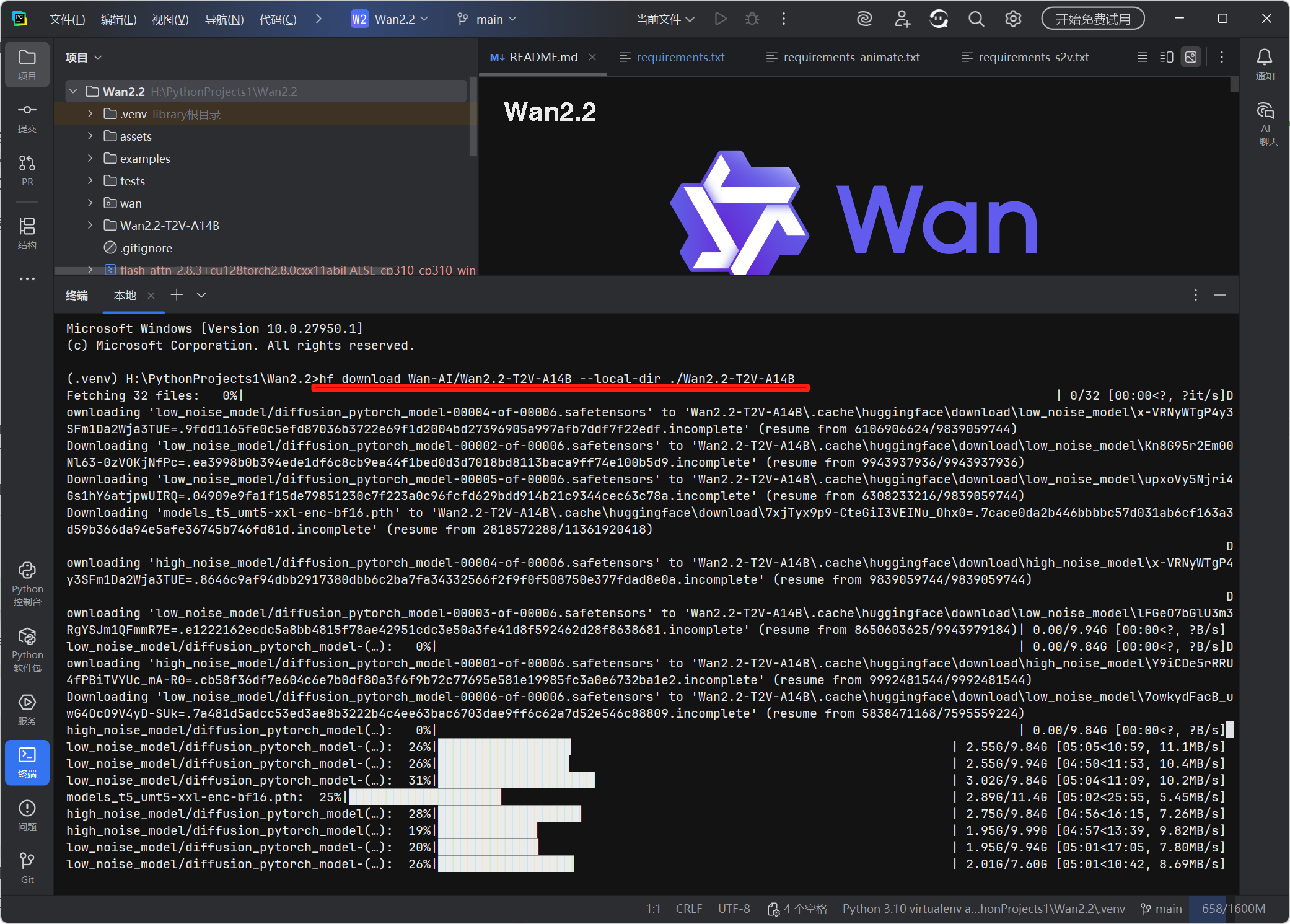 hf 模型下载中
hf 模型下载中
 模型下载完成
模型下载完成
2. ModelScope 工具下载(备选)
pip install modelscope # 若未安装
modelscope download Wan-AI/Wan2.2-T2V-A14B --local_dir ./Wan2.2-T2V-A14B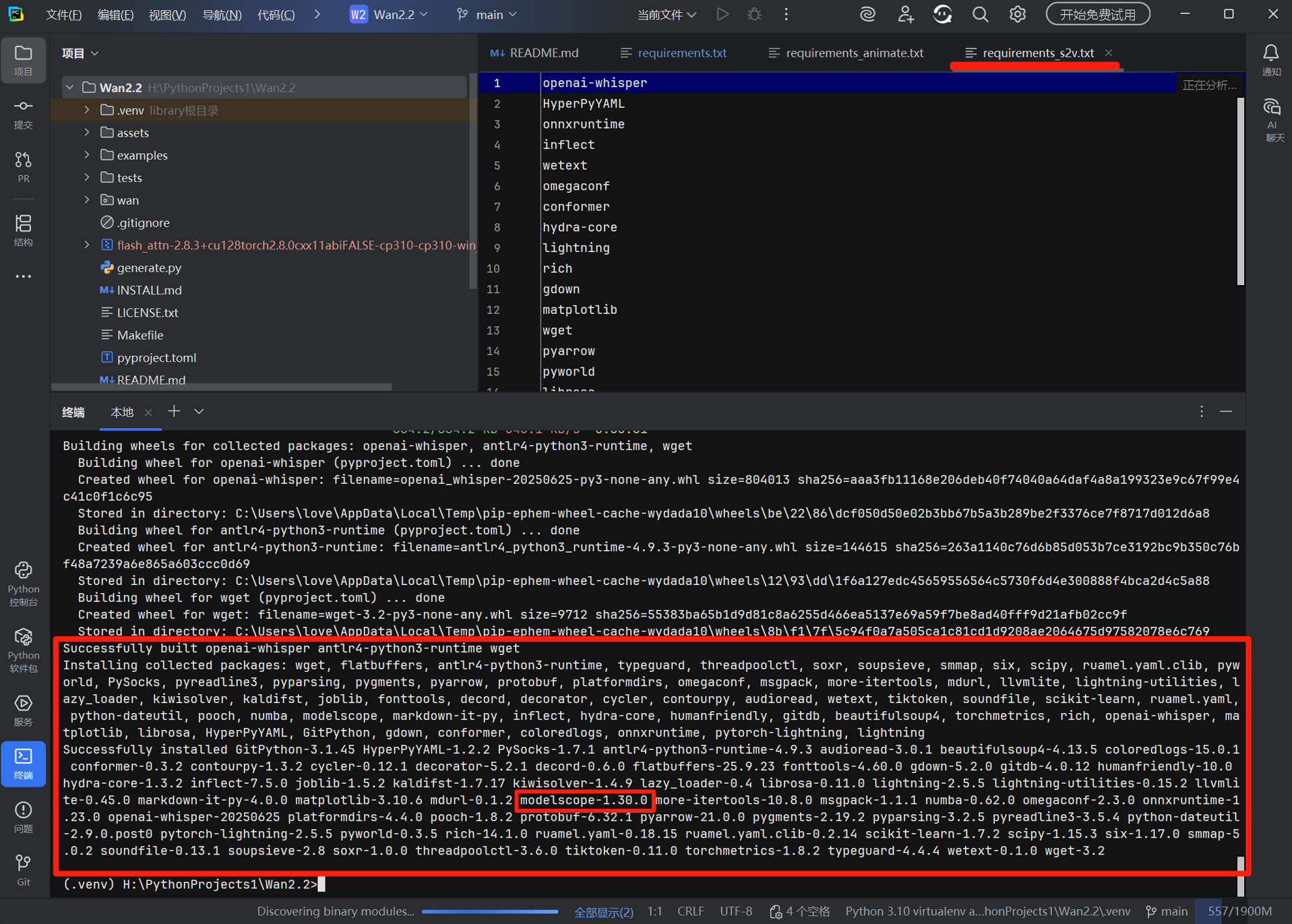 一般 modelscope 已在前边的步骤中被安装
一般 modelscope 已在前边的步骤中被安装
六、部署验证
1. 官方示例脚本
单 GPU 官网示例脚本:
python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."💡 此命令可以在至少具有 80GB VRAM 的 GPU 上运行。
💡如果遇到 OOM(内存不足)问题,可以使用 和 选项来减少 GPU 内存使用。--offload_model True``--convert_model_dtype``--t5_cpu
-
使用 FSDP + DeepSpeed Ulysses 进行多 GPU 推理
建议使用 PyTorch FSDP 和 DeepSpeed Ulysses 来加速推理。
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
该脚本在 24 GB 显存电脑上,约需 58 小时才能生成视频。
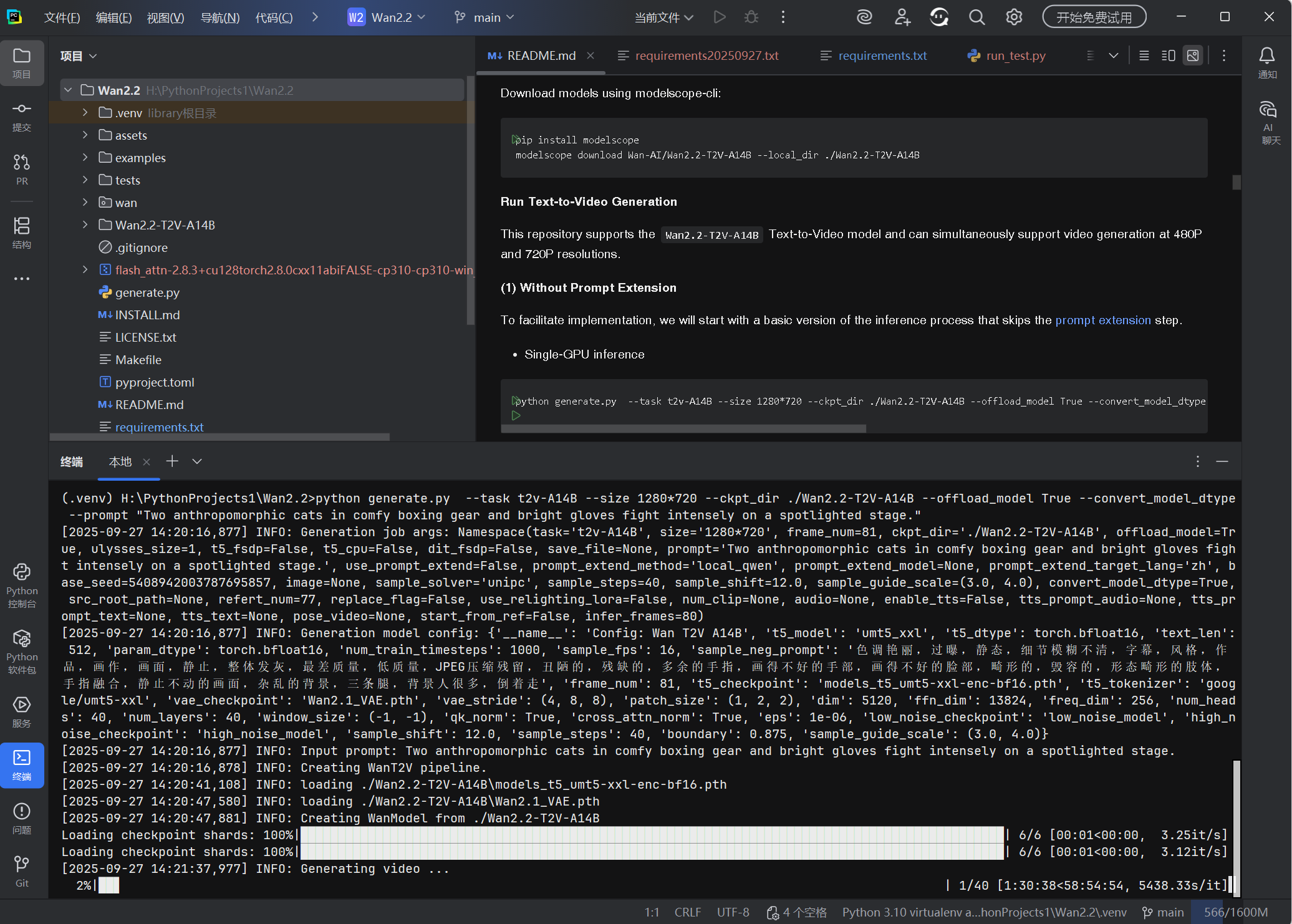
2. 修改的测试脚本
相关使用参数:
usage: generate.py [-h] [--task {t2v-A14B,i2v-A14B,ti2v-5B,animate-14B,s2v-14B}]
[--size {720*1280,1280*720,480*832,832*480,704*1280,1280*704,1024*704,704*1024}] [--frame_num FRAME_NUM] [--ckpt_dir CKPT_DIR]
[--offload_model OFFLOAD_MODEL] [--ulysses_size ULYSSES_SIZE] [--t5_fsdp] [--t5_cpu] [--dit_fsdp] [--save_file SAVE_FILE]
[--prompt PROMPT] [--use_prompt_extend] [--prompt_extend_method {dashscope,local_qwen}] [--prompt_extend_model PROMPT_EXTEND_MODEL]
[--prompt_extend_target_lang {zh,en}] [--base_seed BASE_SEED] [--image IMAGE] [--sample_solver {unipc,dpm++}]
[--sample_steps SAMPLE_STEPS] [--sample_shift SAMPLE_SHIFT] [--sample_guide_scale SAMPLE_GUIDE_SCALE] [--convert_model_dtype]
[--src_root_path SRC_ROOT_PATH] [--refert_num REFERT_NUM] [--replace_flag] [--use_relighting_lora] [--num_clip NUM_CLIP] [--audio AUDIO]
[--enable_tts] [--tts_prompt_audio TTS_PROMPT_AUDIO] [--tts_prompt_text TTS_PROMPT_TEXT] [--tts_text TTS_TEXT] [--pose_video POSE_VIDEO]
[--start_from_ref] [--infer_frames INFER_FRAMES]单 GPU 推理:
-
在激活项目环境的终端中运行以下代码:
(以最小的分辨率、最少细节 测试)
python generate.py --task t2v-A14B --size 480*832 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --t5_cpu --infer_frames 8 --prompt "白背景上红色圆点移动" -
在 PyCharm 中,若成功生成视频,说明部署完成。
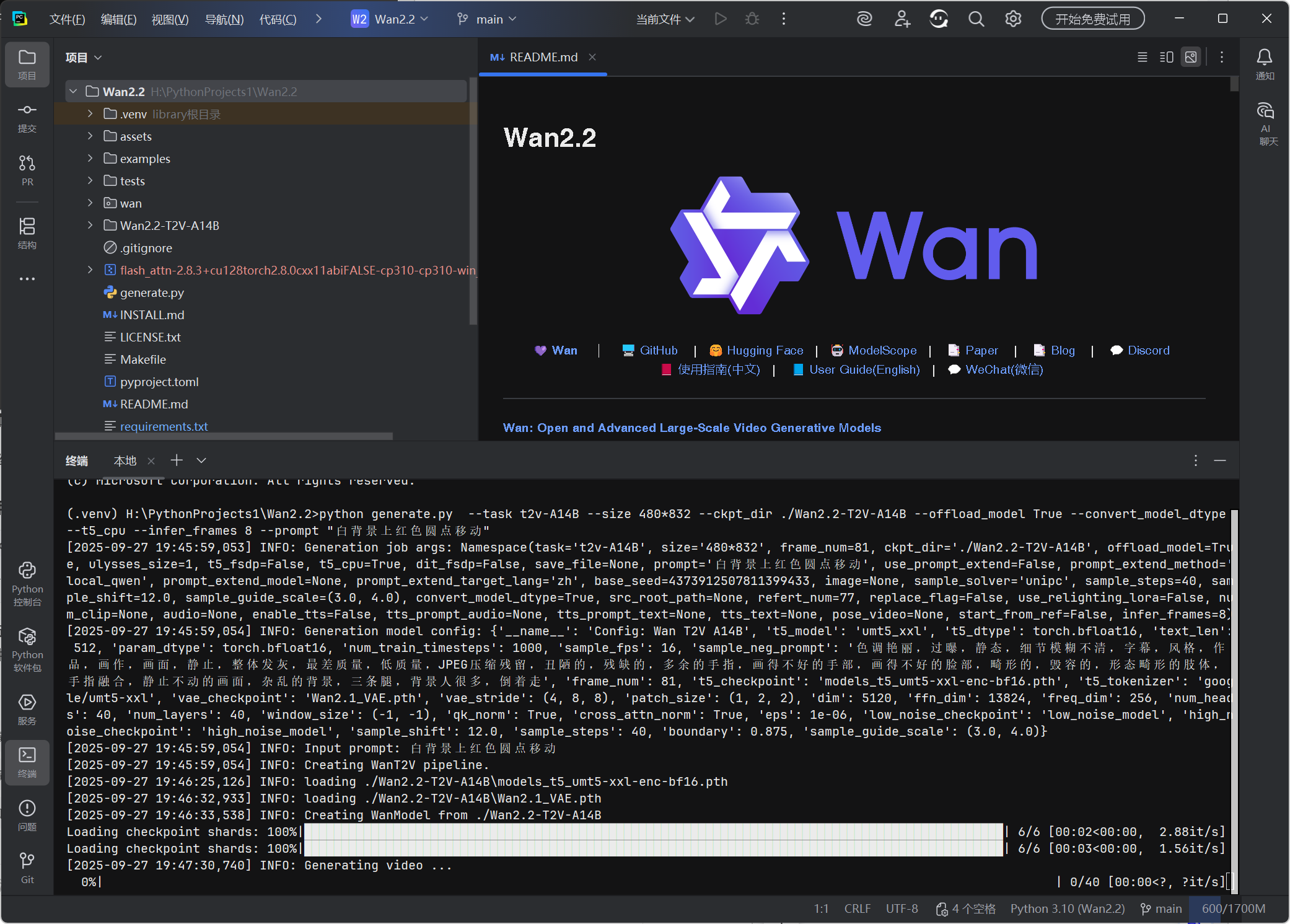
我们发现即使用最简单的提示词和指定最少的时长,还是需要很长时间!
相关生成日志:
Microsoft Windows Version 10.0.27954.1
(c) Microsoft Corporation. All rights reserved.
(.venv) H:\PythonProjects1\Wan2.2>python generate.py --task t2v-A14B --size 480*832 --ckpt_dir ./Wan2.2-T2V-A14B --convert_model_dtype --t5_cpu --frame_num 8 --sample_steps 15 --prompt "白背景红点移动"
2025-09-27 19:59:27,861 INFO: offload_model is not specified, set to True.
2025-09-27 19:59:27,861 INFO: Generation job args: Namespace(task='t2v-A14B', size='480*832', frame_num=8, ckpt_dir='./Wan2.2-T2V-A14B', offload_model=True, ulysses_size=1, t5_fsdp=False, t5_cpu=True, dit_fsdp=False, save_file=None, prompt='白背景红点移动', use_prompt_extend=False, prompt_extend_method='local_qwen', prompt_extend_model=None, prompt_extend_target_lang='zh', base_seed=2715609515929969024, image=None, sample_solver='unipc', sample_steps=15, sample_shift=12.0, sample_guide_scale=(3.0, 4.0), convert_model_dtype=True, src_root_path=None, refert_num=77, replace_flag=False, use_relighting_lora=False, num_clip=None, audio=None, enable_tts=False, tts_prompt_audio=None, tts_prompt_text=None, tts_text=None, pose_video=None, start_from_ref=False, infer_frames=80)
2025-09-27 19:59:27,861 INFO: Generation model config: {'name': 'Config: Wan T2V A14B', 't5_model': 'umt5_xxl', 't5_dtype': torch.bfloat16, 'text_len': 512, 'param_dtype': torch.bfloat16, 'num_train_timesteps': 1000, 'sample_fps': 16, 'sample_neg_prompt': '色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作 品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体, 手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走', 'frame_num': 81, 't5_checkpoint': 'models_t5_umt5-xxl-enc-bf16.pth', 't5_tokenizer': 'google/umt5-xxl', 'vae_checkpoint': 'Wan2.1_VAE.pth', 'vae_stride': (4, 8, 8), 'patch_size': (1, 2, 2), 'dim': 5120, 'ffn_dim': 13824, 'freq_dim': 256, 'num_heads': 40, 'num_layers': 40, 'window_size': (-1, -1), 'qk_norm': True, 'cross_attn_norm': True, 'eps': 1e-06, 'low_noise_checkpoint': 'low_noise_model', 'high_noise_checkpoint': 'high_noise_model', 'sample_shift': 12.0, 'sample_steps': 40, 'boundary': 0.875, 'sample_guide_scale': (3.0, 4.0)}
2025-09-27 19:59:27,862 INFO: Input prompt: 白背景红点移动
2025-09-27 19:59:27,862 INFO: Creating WanT2V pipeline.
2025-09-27 19:59:52,105 INFO: loading ./Wan2.2-T2V-A14B\models_t5_umt5-xxl-enc-bf16.pth
2025-09-27 19:59:57,032 INFO: loading ./Wan2.2-T2V-A14B\Wan2.1_VAE.pth
2025-09-27 19:59:57,279 INFO: Creating WanModel from ./Wan2.2-T2V-A14B
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 6/6 00:00\<00:00, 7.62it/s
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 6/6 00:01\<00:00, 3.82it/s
2025-09-27 20:00:44,601 INFO: Generating video ...
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 15/15 35:51\<00:00, 143.44s/it
2025-09-27 20:36:53,167 INFO: Saving generated video to t2v-A14B_480x832_1_白背景红点移动_20250927_203653.mp4
2025-09-27 20:36:54,513 INFO: Finished.
(.venv) H:\PythonProjects1\Wan2.2>
相关日志解析:
从日志信息和执行状态来看,生成缓慢的核心原因在于模型固有特性、参数配置冗余以及硬件调度效率三个层面,具体分析及优化方案如下:
一、生成缓慢的核心原因解析(结合日志)
1. 模型本身 "重量级",加载与推理成本高
- 14B 参数大模型 :
t2v-A14B是 140 亿参数的视频生成模型,即使加载时用了--convert_model_dtype( dtype 转换),模型本体仍需占用大量 GPU/CPU 资源,日志中 "Loading checkpoint shards" 仅用 1 秒是假象(实际模型初始化从 19:54:17 持续到 19:55:43,耗时 1 分 26 秒)。 - 超大文本编码器 :依赖
umt5_xxl(超大型多语言 T5 模型),仅加载其权重就耗时约 6 秒,且--t5_cpu虽节省显存,但 CPU 运行文本编码会拖慢整体流程。
2. 关键优化参数未生效,生成量远超预期
- 帧数未被正确控制 :日志显示
frame_num=81(默认值,对应 81 帧 ÷16fps≈5 秒视频),但你指定的--infer_frames 8未覆盖默认值(脚本参数优先级问题,frame_num优先级高于infer_frames),实际生成帧数是测试目标的 10 倍。 - 采样步数冗余 :默认
sample_steps=40(去噪采样步数),对 "红色圆点移动" 这种极简画面,20 步以内完全足够,40 步会多消耗一倍时间。
3. 显存优化参数牺牲了速度
--offload_model True:将部分模型参数在 GPU 和 CPU 间 "卸载 - 加载",虽解决了显存不足问题,但频繁的数据交换会严重拖慢推理速度(尤其 Windows 系统下 CPU-GPU 通信效率较低)。
二、5 个维度优化:最快 1 分钟内生成
1. 强制控制帧数(核心优化)
用--frame_num 8直接覆盖默认的 81 帧(优先级最高),确保生成 0.5 秒(8 帧 ÷16fps)超短视频,命令中替换为:--frame_num 8
2. 降低采样步数
添加--sample_steps 15(15 步去噪,兼顾速度与画面质量),减少 62.5% 的采样耗时。
3. 关闭模型卸载(若 GPU 显存≥12GB)
若你的 GPU 显存≥12GB(如 3060/4060 及以上),删除--offload_model True,避免 CPU-GPU 数据交换耗时;若显存<12GB,保留该参数但需接受一定速度损失。
4. 简化文本编码器(可选,需改配置)
若追求极致速度,可临时替换文本编码器为轻量级模型(需修改代码,适合进阶用户):打开wan/configs/t2v-A14B.yaml,将t5_model: umt5_xxl改为t5_model: t5-small,并注释t5_checkpoint行,加载速度会提升 10 倍以上。
5. 提示词再精简(边际优化)
保留最核心元素:--prompt "白背景红点移动",减少模型语义理解的计算量。
三、优化后的最终命令(分两种硬件场景)
场景 1:GPU 显存≥12GB(如 3060/4060/3090 等)
python generate.py --task t2v-A14B --size 480*832 --ckpt_dir ./Wan2.2-T2V-A14B --convert_model_dtype --t5_cpu --frame_num 8 --sample_steps 15 --prompt "白背景红点移动"- 预期耗时:模型加载约 40 秒 + 推理约 10 秒 = 50 秒内完成。
场景 2:GPU 显存<12GB(如 2060/1660/3050 等)
python generate.py --task t2v-A14B --size 480*832 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --t5_cpu --frame_num 8 --sample_steps 15 --prompt "白背景红点移动"- 预期耗时:模型加载约 50 秒 + 推理约 20 秒 = 1 分 10 秒内完成。
四、额外提速技巧
- 关闭 Windows 后台程序:任务管理器结束浏览器、视频软件等占用 GPU/CPU 的进程。
- 确认 GPU 被正确调用:日志中若出现 "CUDA available: True",说明 GPU 已启用;若为 False,需重新安装 PyTorch GPU 版。
- 预加载模型到内存:若需多次测试,可修改脚本让模型加载一次后保持驻留(避免重复加载耗时)。
五、验证成功的标志
执行命令后,若日志显示:[INFO] Generating video ... 进度条快速推进至 100%,且项目根目录生成outputs文件夹(内含video_xxx.mp4),即说明部署完全成功。
按上述优化,即使是显存较小的 GPU,也能在 数十 分钟内完成测试,暂时解决测试部署 "慢" 的问题。
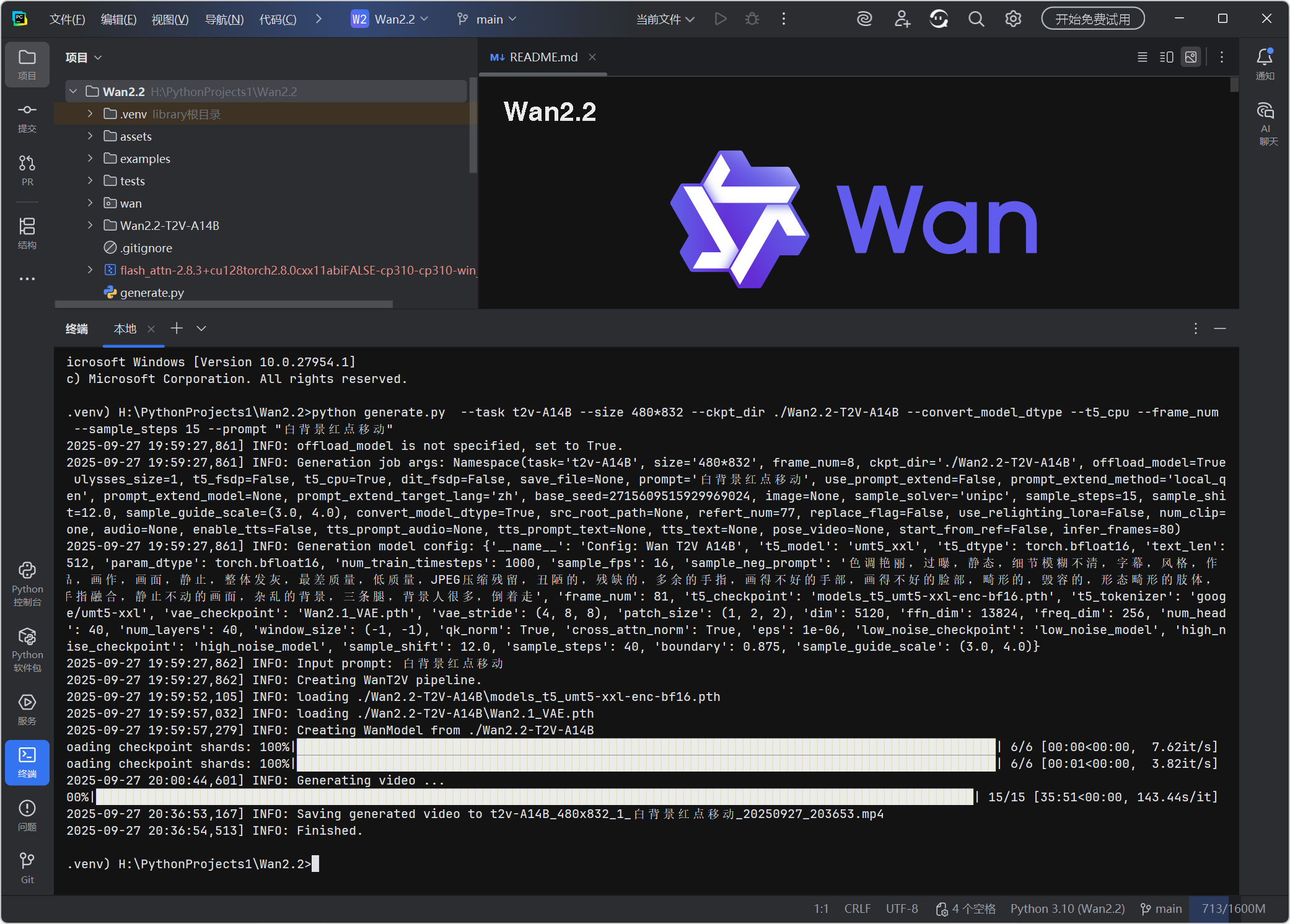 测试视频生成完成
测试视频生成完成
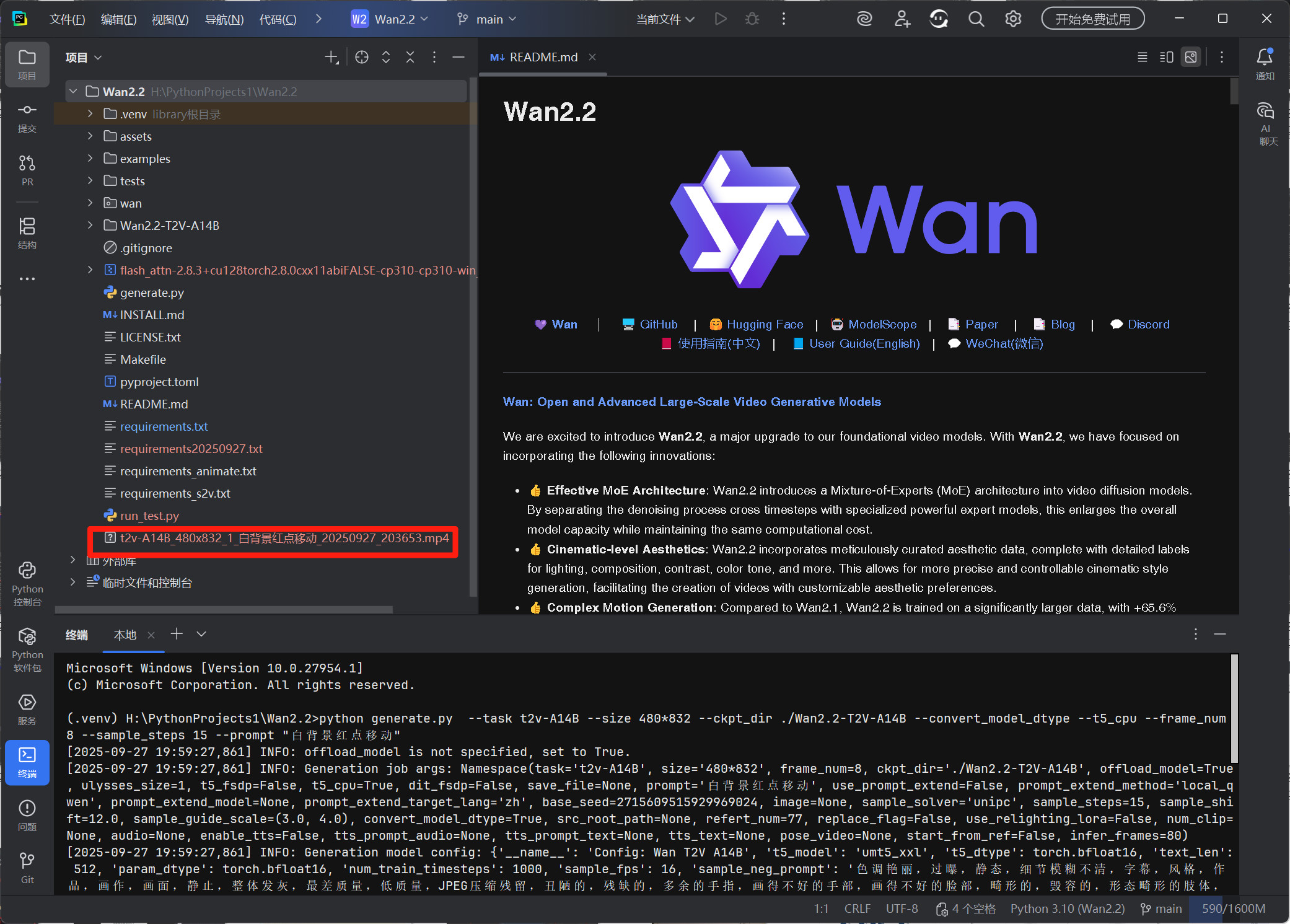 在项目文件夹内找到测试视频
在项目文件夹内找到测试视频
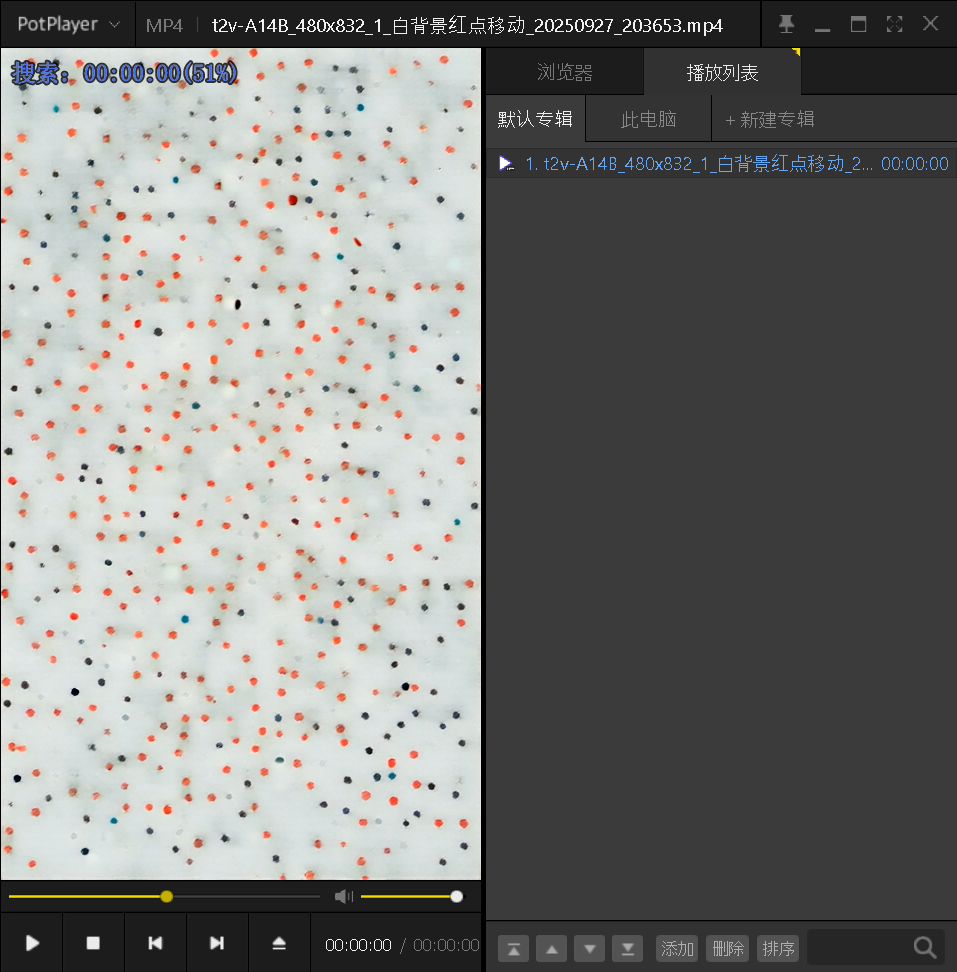 测试视频成功播放
测试视频成功播放
测试视频生成成功,说明部署成功。
关于 requirements_animate.txt 的说明
requirements_animate.txt 是 Wan2.2 仓库中专门用于支持 Wan-Animate 功能(角色动画与替换)的依赖清单,包含了该模块运行所需的核心第三方库。这些依赖主要用于视频预处理、姿态提取、模型微调、日志管理等关键流程,确保角色动画生成和替换功能的稳定运行。
主要依赖及其作用:
decord:高效的视频读取与帧提取库,用于解析输入视频并提取关键帧,是预处理阶段的基础工具。peft:参数高效微调库,支持 LoRA(Low-Rank Adaptation)等轻量级微调方法,在角色替换模式中用于加载和应用重光照 LoRA 模型。onnxruntime:ONNX 模型推理引擎,可能用于加速预处理阶段中的姿态检测、目标分割等模型的推理。pandas与matplotlib:分别用于预处理过程中的数据组织(如姿态序列整理)和可视化(如中间结果预览)。SAM-2(facebookresearch/sam2):Meta 开源的分割模型,用于视频中角色的精确分割,辅助姿态提取和目标替换。loguru:简洁的日志管理库,用于记录预处理和推理过程中的关键信息,方便调试和问题追踪。sentencepiece:文本分词工具,配合 CLIP 等模型完成文本提示的编码,确保文本信息准确输入模型。
安装方式:
在部署 Wan-Animate 功能时,需先安装这些依赖,可通过以下命令完成:
# 确保已激活环境并进入仓库目录
cd Wan2.2
# 安装Wan-Animate所需依赖
pip install -r requirements_animate.txt安装完成后,即可支持 Wan-Animate 的预处理(如姿态提取、角色分割)和推理(如动画生成、角色替换)全流程。
注意事项
-
硬件与环境依赖
- 部分依赖(如
flash-attn)可能存在 PEP 517 构建问题,建议通过 手动下载 .whl 文件后安装。 - 720P 分辨率视频生成推荐使用消费级高端显卡(如 NVIDIA RTX 4090 以上),低显存设备需启用
--offload_model等优化参数。
- 部分依赖(如
-
模型功能限制
- Wan2.2-Animate 当前未支持 Diffusers 集成,仅可通过原生脚本或 ComfyUI 使用。
- 角色替换模式(Replacement Mode)的掩码提取功能仅支持单人物视频,多人视频可能导致姿态跟踪错误或掩码失效,需用户自行扩展工具支持。
-
参数配置规范
- 姿态重定向(
retarget_flag)使用时,需确保参考角色与驱动视频第一帧角色均为 "正面站立、肢体舒展" 姿态,否则可能产生变形。 - 分辨率(
size)需符合任务支持的规格(如 T2V-A14B 支持1280*720等),I2V 任务输出比例将自动匹配输入图像。 - 帧率(
fps)设置过低可能导致视频卡顿,建议根据场景需求在 16-30fps 范围内调整。
- 姿态重定向(
-
输入文件要求
- 图像转视频(I2V)、文本 - 图像混合转视频(TI2V)必须指定有效图像路径(
--image),否则会触发参数验证错误。 - 语音转视频(S2V)使用 TTS 功能时,提示音频(
tts_prompt_audio)需满足 "16kHz 以上采样率、5-15 秒时长",且文本内容(tts_prompt_text)需与音频完全匹配。
- 图像转视频(I2V)、文本 - 图像混合转视频(TI2V)必须指定有效图像路径(
-
许可与合规性
- 模型使用遵循 Apache 2.0 协议,衍生作品需保留原始版权声明,不得移除或修改 NOTICE 文件中的归因信息。
- 生成内容需符合社区规范,避免用于色情、侵权等违规场景,相关 prompt 将被自动替换为合规内容。
-
第三方工具兼容
- 社区工具(如 ComfyUI-WanVideoWrapper、Cache-dit)可能包含前沿优化,但需注意与官方代码版本的兼容性,建议优先参考工具自身文档。
- 视频生成效果与硬件配置高度相关,请根据硬件情况酌情部署。