
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. 二叉搜索树的核心概念:什么是 BST?](#一. 二叉搜索树的核心概念:什么是 BST?)
- [二. 二叉搜索树的性能分析:理想与最差情况](#二. 二叉搜索树的性能分析:理想与最差情况)
- [三. 二叉搜索树的实战实现:基于 BinarySearchTree.h](#三. 二叉搜索树的实战实现:基于 BinarySearchTree.h)
-
- [3.1 节点结构定义:BSTreeNode](#3.1 节点结构定义:BSTreeNode)
- [3.2 BST 类核心操作:Insert、Find、Erase](#3.2 BST 类核心操作:Insert、Find、Erase)
-
- [3.2.1 插入操作(Insert)](#3.2.1 插入操作(Insert))
- [3.2.2 查找操作(Find)](#3.2.2 查找操作(Find))
- [3.2.3 删除操作(Erase):最复杂的核心操作](#3.2.3 删除操作(Erase):最复杂的核心操作)
- [四. 实战测试:基于实战代码验证 BST 操作](#四. 实战测试:基于实战代码验证 BST 操作)
- [五. BST 的扩展:key/value 模型(支持映射场景)](#五. BST 的扩展:key/value 模型(支持映射场景))
-
- [5.1 key-value 模型节点与类实现](#5.1 key-value 模型节点与类实现)
- [5.2 key-value 模型实战场景](#5.2 key-value 模型实战场景)
- [场景 2:单词统计(统计水果出现次数)](#场景 2:单词统计(统计水果出现次数))
- 结尾:
前言:
在数据结构中, 二叉搜索树(Binary Search Tree,简称 BST) 是一种兼具 "有序性" 与 "高效操作" 的树形结构,它通过特定的节点值规则,让增删查操作的时间复杂度在理想情况下达到
O(log₂N)但是平均来看还是O(N)。本文将从二叉搜索树的核心概念入手,结合实战代码,逐步拆解其插入、查找、删除三大核心操作,同时分析性能特点与实际应用场景,帮你彻底掌握这一基础数据结构。
一. 二叉搜索树的核心概念:什么是 BST?
二叉搜索树又称二叉排序树,它要么是空树,要么是满足以下值分布规则的二叉树:
- 若左子树不为空,则左子树中所有节点的值 ≤ 根节点的值;
- 若右子树不为空,则右子树中所有节点的值 ≥ 根节点的值;
- 左、右子树也分别是二叉搜索树(递归定义)。
- 二叉搜索树可以支持插入相等的值,也可以不支持插入相等的值,具体看使用场景定义,后续我们学习map/set/multimap/multiset系列容器底层就是二叉搜索树,其中map/set不支持插入相等值,multimap/multiset支持插入相等值
关键特性 :中序遍历为有序序列
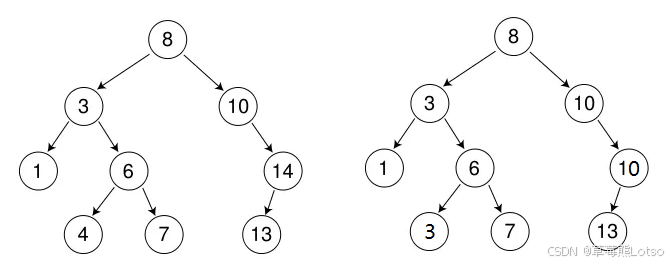
二叉搜索树的核心价值在于 "中序遍历结果是升序序列" 。例如,下图 BST 的中序遍历结果为1 3 4 6 7 8 10 13 14,天然具备 "排序" 属性,这也是其 "二叉排序树" 名称的由来。
关于 "相等值" 的约定
BST 对相等值的处理可灵活定义,具体取决于场景:
不支持相等值插入 (如map/set底层):插入时若值已存在,直接返回失败;
支持相等值插入 (如multimap/multiset底层):相等值需统一插入左子树或右子树(保持逻辑一致,避免后续查找混乱)。
本文实现的 BST 默认不支持相等值插入。
二. 二叉搜索树的性能分析:理想与最差情况
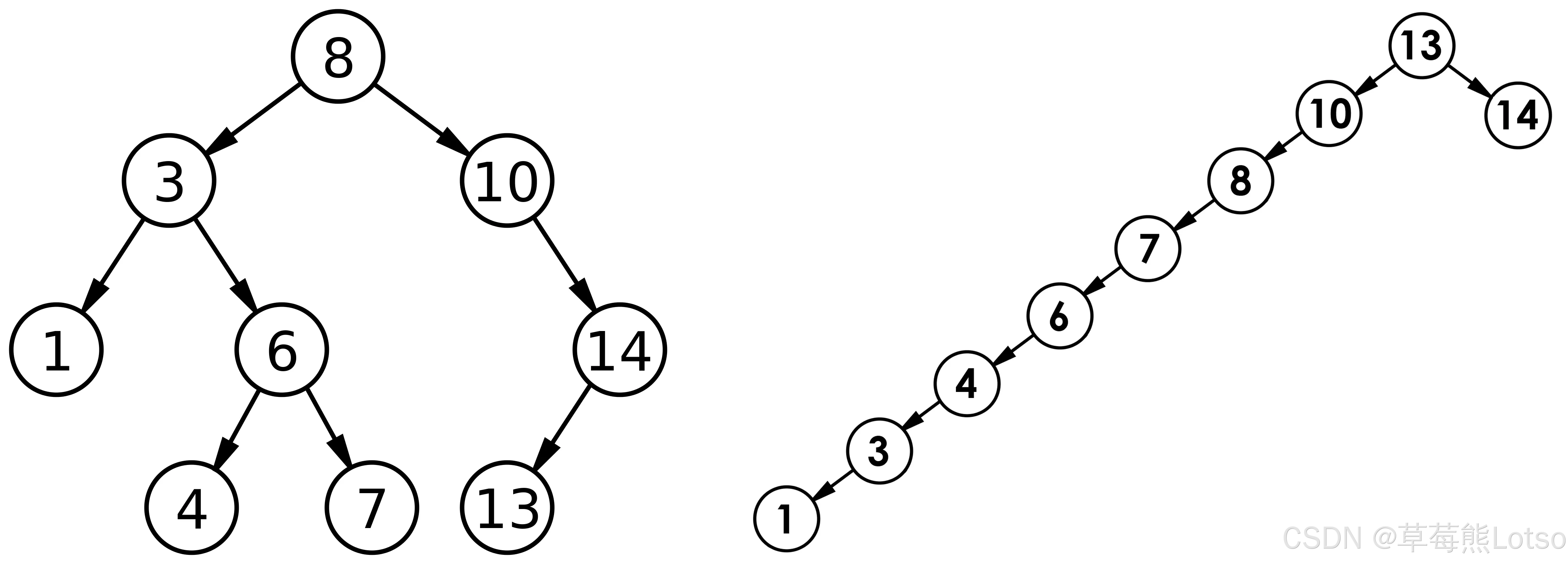
BST 的操作效率直接取决于树的 "高度",而高度由节点插入顺序决定,存在两种极端情况:
| 场景 | 树的形态 | 高度 | 增删查时间复杂度 | 典型插入顺序 | 核心影响因素 |
|---|---|---|---|---|---|
| 理想情况 | 完全二叉树(接近平衡) | log 2 N \log_2 N log2N | O ( log 2 N ) O(\log_2 N) O(log2N) | 随机插入(如8,3,10,1,6) | 插入顺序无序,节点均匀分布在左右子树 |
| 最差情况 | 单支树(退化为链表) | N N N | O ( N ) O(N) O(N) | 有序插入(如1,3,6,8,10) | 插入顺序严格递增/递减,节点仅向单侧延伸 |
综合来看二叉搜索树增删查改时间复杂度
与 "二分查找" 的对比
二分查找虽也能实现O(log₂N)的查找效率,但存在明显缺陷:
- 依赖支持随机访问的结构(如数组),且需提前排序;
- 插入 / 删除效率低:数组中插入 / 删除元素需挪动大量数据,时间复杂度为
O(N)。
而 BST 无需提前排序,且插入 / 删除时仅需修改节点指针,避免了数据挪动,这也是其在动态数据场景中更具优势的原因。
三. 二叉搜索树的实战实现:基于 BinarySearchTree.h
采用 C++ 模板实现,支持泛型K(,核心包含节点结构定义 与BST 类的三大操作(插入、查找、删除),同时提供中序遍历接口验证有序性。
3.1 节点结构定义:BSTreeNode
BST 的节点需存储 "值" 与 "左右子树指针",模板化设计使其可适配 int、string 等多种类型:
cpp
#include<iostream>
using namespace std;
template<class K>
struct BSTreeNode
{
BSTreeNode<K>* _left; // 左子树指针
BSTreeNode<K>* _right; // 右子树指针
K _key; // 节点键值
// 构造函数:初始化指针为空,键值为传入值
BSTreeNode(const K& key)
: _left(nullptr)
, _right(nullptr)
, _key(key)
{}
};3.2 BST 类核心操作:Insert、Find、Erase
BST 类封装了树的根节点_root,并通过私有辅助函数_InOrder实现中序遍历。以下是三大核心操作的详细实现与解析:
3.2.1 插入操作(Insert)
插入的核心逻辑是 "按 BST 规则找到空位置,创建新节点并链接",步骤如下:
- 若树为空(_root == nullptr),直接创建根节点;
- 树非空时,用cur指针遍历树:
- 若
cur->_key < 插入值:向右子树移动(cur = cur->_right); - 若
cur->_key > 插入值:向左子树移动(cur = cur->_left); - 若值相等(不支持插入),返回
false;
- 若
找到空位置后,通过parent指针(记录cur的父节点)将新节点链接到树中。
代码实现(BinarySearchTree.h):
cpp
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
bool Insert(const K& key)
{
// 情况1:树为空,直接创建根节点
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
// 情况2:树非空,遍历找插入位置
Node* parent = nullptr; // 记录cur的父节点(用于后续链接新节点)
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right; // 比当前节点大,向右走
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left; // 比当前节点小,向左走
}
else
{
// 键值已存在,不支持插入,返回false
return false;
}
}
// 创建新节点,并链接到parent的左/右孩子
cur = new Node(key);
if (parent->_key < key)
{
parent->_right = cur; // 插入值比parent大,作为右孩子
}
else
{
parent->_left = cur; // 插入值比parent小,作为左孩子
}
return true;
}
// 中序遍历:验证BST的有序性
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left); // 遍历左子树
cout << root->_key << " "; // 访问当前节点
_InOrder(root->_right); // 遍历右子树
}
Node* _root = nullptr; // 树的根节点,初始为空
};
3.2.2 查找操作(Find)
查找的逻辑与插入类似,按 BST 规则遍历树,步骤如下:
- 从根节点
_root开始,用cur指针遍历; - 若
cur->_key < 目标值:向右走;若cur->_key > 目标值:向左走; - 找到目标值返回
true,遍历到空节点(未找到)返回false。
代码实现(BinarySearchTree.h):
cpp
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right; // 目标值大,向右找
}
else if (cur->_key > key)
{
cur = cur->_left; // 目标值小,向左找
}
else
{
// 找到目标值,返回true
return true;
}
}
// 遍历到空,未找到
return false;
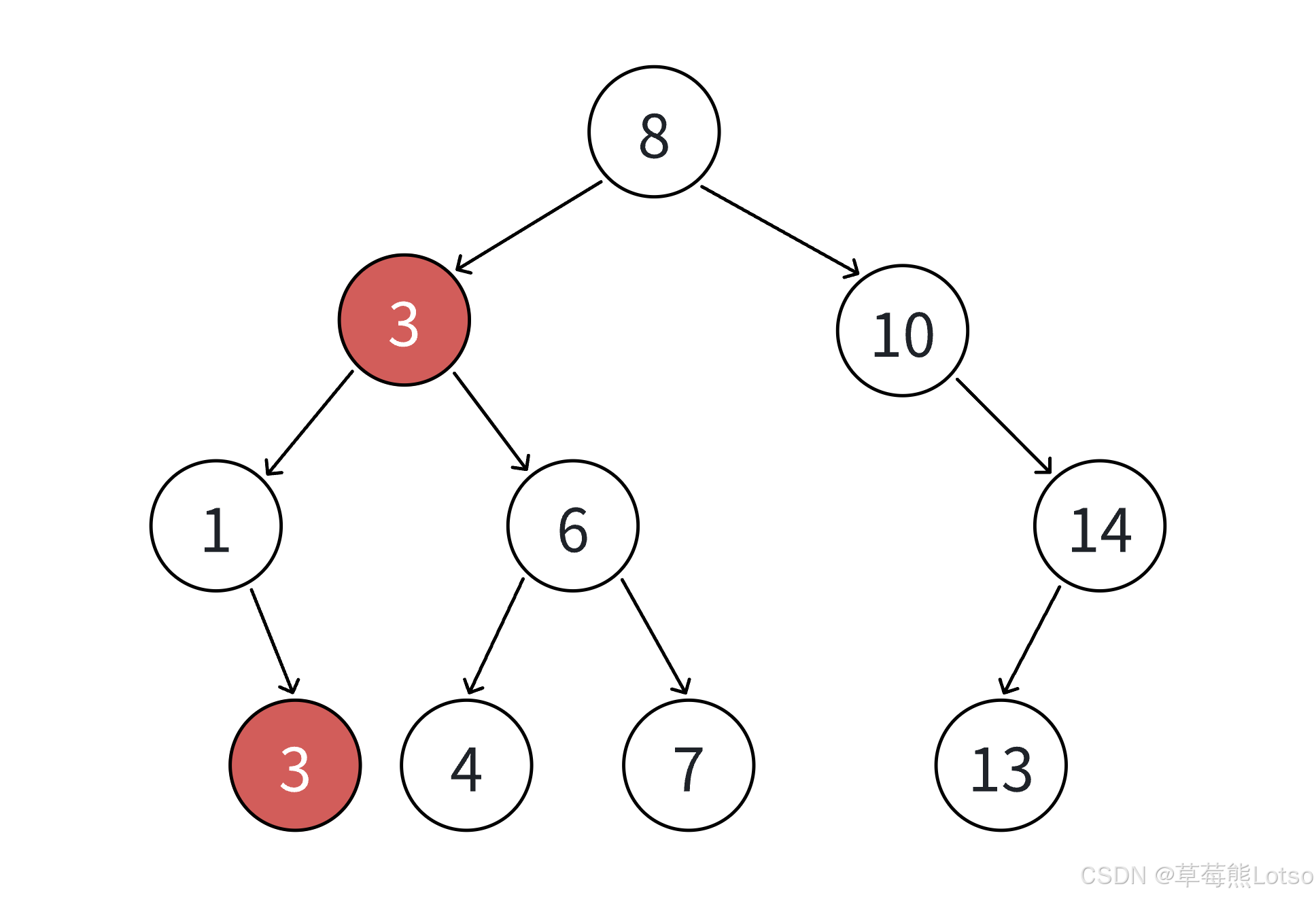
}如果支持插入相等的值,意味着有多个x存在,一般要求查找中序的第⼀个x。如下图,查找3,要找到1的右孩子的那个3返回
3.2.3 删除操作(Erase):最复杂的核心操作
删除的难点在于 "删除节点后,需保持 BST 的规则不变"。根据删除节点(记为cur)的子节点数量,分为 4 种情况,其中前 3 种可合并处理,第 4 种需用 "替换法" 删除:
| 情况 | 子节点状态 | 处理方案 | 关键注意事项 |
|---|---|---|---|
| 1 | 左右子树均为空(叶子节点) | 直接删除cur节点,将parent指向cur的孩子指针置空(可归为情况2或3统一处理) |
需判断cur是否为根节点(若为根,直接将_root置空,无需处理parent) |
| 2 | 左子树为空,右子树非空 | 将parent指向cur的孩子指针,修改为指向cur->_right,随后删除cur节点 |
若cur是根节点,直接让_root = cur->_right,跳过parent判断 |
| 3 | 右子树为空,左子树非空 | 将parent指向cur的孩子指针,修改为指向cur->_left,随后删除cur节点 |
与情况2对称,根节点处理逻辑为_root = cur->_left |
| 4 | 左右子树均非空 | 1. 找cur右子树的"最小节点"(最左节点)或左子树的"最大节点"(最右节点); 2. 将替换节点的键值(及值,若为key-value模型)赋给cur; 3. 删除替换节点(替换节点满足情况2或3,直接处理) |
替换节点的父节点指针需正确修改(如替换节点是父节点左孩子,需将父节点左指针指向替换节点的右子树) |
代码实现(BinarySearchTree.h):
cpp
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
// 第一步:找到要删除的节点cur
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
// 第二步:找到节点,按子节点情况处理删除
// 情况2:左子树为空,右子树非空
if (cur->_left == nullptr)
{
// 若cur是根节点,直接让根指向右子树
if (cur == _root)
{
_root = cur->_right;
}
else
{
// 判断cur是parent的左/右孩子,链接对应子树
if (cur == parent->_left)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur; // 释放节点内存
return true;
}
// 情况3:右子树为空,左子树非空
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (cur == parent->_left)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
return true;
}
// 情况4:左右子树均非空(替换法删除)
else
{
// 找cur右子树的最小节点(最左节点)作为替换节点
// 还可以找左子树的最大节点(最右节点)
// 这里是找右子树最左节点
Node* replaceParent = cur; // 替换节点的父节点
Node* replace = cur->_right;
while (replace->_left) // 一直向左走,直到左子树为空
{
replaceParent = replace;
replace = replace->_left;
}
// 替换:将replace的键值赋给cur(值替换,指针不变)
cur->_key = replace->_key;
// 删除replace节点(replace的左子树为空,符合情况2)
if (replaceParent->_left == replace)
replaceParent->_left = replace->_right;
else
replaceParent->_right = replace->_right;
delete replace;
return true;
}
}
}
// 未找到要删除的节点
return false;
}关键说明 :情况 4 中选择 "右子树最小节点" 作为替换节点,是因为该节点的值是cur右子树中最小的,替换后仍满足 BST 规则(左子树≤根≤右子树);同理,选择 "左子树最大节点" 也可,逻辑对称

四. 实战测试:基于实战代码验证 BST 操作
test.cpp通过引入BinarySearchTree.h,实现 BST 的插入、删除与中序遍历验证,代码如下:
cpp
#include"BinarySearchTree.h"
int main()
{
// 测试数据:插入序列
int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
BSTree<int> t;
// 1. 插入所有元素
for (auto& e : a)
{
t.Insert(e);
}
cout << "插入后中序遍历(应有序):";
t.InOrder(); // 输出:1 3 4 6 7 8 10 13 14
// 2. 删除测试:逐步删除节点,验证有序性
t.Erase(3); // 删除左子树非空、右子树非空的节点(情况4)
cout << "删除3后中序遍历:";
t.InOrder(); // 输出:1 4 6 7 8 10 13 14
t.Erase(8); // 删除根节点(左右子树非空,情况4)
cout << "删除8后中序遍历:";
t.InOrder(); // 输出:1 4 6 7 10 13 14
t.Erase(1); // 删除叶子节点(左右子树为空,情况1)
cout << "删除1后中序遍历:";
t.InOrder(); // 输出:4 6 7 10 13 14
t.Erase(10); // 删除右子树非空、左子树非空的节点(情况4)
cout << "删除10后中序遍历:";
t.InOrder(); // 输出:4 6 7 13 14
// 3. 清空树(删除所有元素)
for (auto& e : a)
{
t.Erase(e);
}
cout << "清空后中序遍历(空行):";
t.InOrder(); // 输出空行
return 0;
}结果符合预期,证明 BST 的插入、删除操作均保持了 "中序遍历有序" 的核心特性。

五. BST 的扩展:key/value 模型(支持映射场景)
上述实现是 "key 模型"(仅存储键值,用于判断 "存在性",不能修改),但实际场景中常需 "key-value 模型"(键值对应数据,如字典、统计次数,可以修改value)。BinarySearchTree.h可扩展为模板template<class K, class V>,节点同时存储_key和_value。

5.1 key-value 模型节点与类实现
cpp
// key-value模型节点
template<class K, class V>
struct BSTreeNode
{
K _key;
V _value;
BSTreeNode<K, V>* _left;
BSTreeNode<K, V>* _right;
BSTreeNode(const K& key, const V& value)
: _key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{}
};
// key-value模型BST类
template<class K, class V>
class BSTree
{
typedef BSTreeNode<K, V> Node;
public:
// 插入:需传入key和value
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false; // 不支持重复key
}
}
cur = new Node(key, value);
if (parent->_key < key)
parent->_right = cur;
else
parent->_left = cur;
return true;
}
// 查找:返回节点指针,可通过节点访问value
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
cur = cur->_right;
else if (cur->_key > key)
cur = cur->_left;
else
return cur; // 返回节点,后续可操作value
}
return nullptr;
}
//erase跟上面没区别,这里就不展示了
// 中序遍历:输出key和value
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << " ";
_InOrder(root->_right);
}
Node* _root = nullptr;
};5.2 key-value 模型实战场景
场景 1:简单字典(中英互译)
cpp
int main()
{
//简单字典
key_value::BSTree<string, string> dict;
dict.Insert("sort", "排序");
dict.Insert("string", "字符串");
dict.Insert("insert", "插入");
dict.Insert("erase", "删除");
dict.Insert("move", "移动");
dict.Insert("tree", "树");
dict.Insert("tree", "树*****");//插入失败,可以看看插入的逻辑,主要是key判断
// 内置类型转换成类类型 -> 构造函数
// 类类型转换成内置类型 -> operator 内置类型
string str;
int i = 0;
//while ((cin >> str).operator bool())
while(cin>>str)
{
auto* node = dict.Find(str);
if (node)
{
cout << "->" << node->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
return 0;
}
场景 2:单词统计(统计水果出现次数)
cpp
int main()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
key_value::BSTree<string, int> CountTree;
for (auto& str : arr)
{
//BSTreeNode<string, int>* ret = countTree.Find(str);
auto ret = CountTree.Find(str);
// 第一次出现,插入<水果, 1>
if (ret == nullptr)
{
CountTree.Insert(str, 1);
}
else
{
// 已出现,次数+1
ret->_value++;
}
}
// 中序遍历:按水果名称升序输出次数
CountTree.InOrder();
return 0;
}
结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:二叉搜索树(BST)以 "左小右大" 的规则,实现了动态数据的有序管理,中序遍历的有序性与指针操作的灵活性是其核心优势。插入、查找逻辑直观,删除操作的场景化处理(尤其是替换法)则是掌握关键,但其性能受插入顺序影响大,单支树退化问题也为后续平衡树(AVL、红黑树)的学习埋下伏笔。作为基础树形结构,BST 是理解复杂数据结构设计逻辑的重要基石。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
