
1.摘要
background
视觉语言模型(Vision-Language Models, VLMs)在各种视觉任务中取得了巨大成功,但由于其模型规模庞大和计算要求高,很难部署在移动设备等资源受限的环境中。知识蒸馏(Knowledge Distillation, KD)是一种有效的解决方案,但现有的VLM蒸馏方法通常涉及复杂的多阶段训练或额外的微调,增加了计算开销和优化难度。此外,在只有少量标注数据的半监督场景下,传统的单头知识蒸馏方法会因为来自标注数据的监督信号和来自教师模型的蒸馏信号之间的"梯度冲突"而表现不佳,导致特征学习效果受限。
innovation
1.提出Dual-Head Optimization (DHO)框架:为了解决上述问题,论文提出了一个简单而有效的单阶段知识蒸馏框架------DHO。该框架的核心是为学生模型引入两个独立的预测头:一个监督头(CE Head)专门从有限的标注数据中学习,另一个蒸馏头(KD Head)专门学习教师模型在所有数据(包括未标注数据)上的预测。
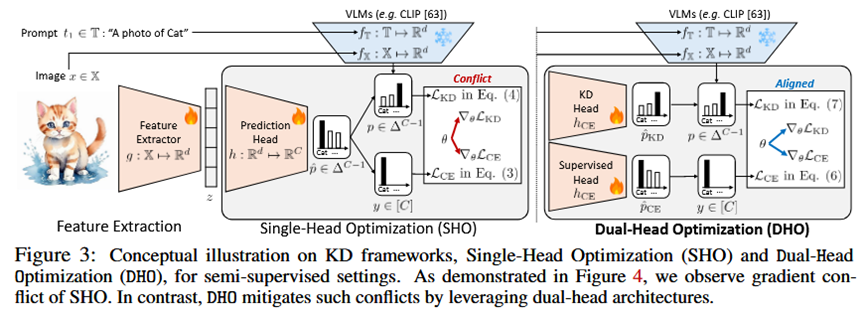
2.缓解梯度冲突:通过分离两个学习目标,DHO有效地缓解了监督信号和蒸馏信号在更新模型参数时的梯度冲突。论文通过梯度分析和实验(图4)证明,与单头基线相比,DHO中两个任务的梯度方向更加一致,从而实现了更稳定、更高效的特征学习。
3.推理时线性插值:在推理阶段,DHO将两个头的输出进行线性组合,从而整合了来自真实标签的知识和来自强大教师模型的泛化知识。这种方式可以根据不同数据集的特性,通过超参数调整两个头的权重,进一步提升模型性能。
4.达到SOTA性能:相比于传统的单头蒸馏方法,DHO在11个不同的数据集上都取得了显著的性能提升。特别是在ImageNet数据集上,仅使用1%和10%的标注数据,DHO就实现了新的SOTA(State-of-the-Art)性能,同时使用的参数更少。
- 方法 Method
总体流程 (Pipeline):
DHO框架包含一个学生模型,该模型由一个共享的特征提取器 (g) 和两个独立的预测头 (h_CE 和 h_KD) 组成。在训练过程中,这两个头分别由不同的损失函数进行优化;在推理过程中,它们的输出被结合起来以获得最终预测。
各部分细节:
1.输入 (Input):
少量有标签的数据集 D(l) = {(x_n, y_n)}
大量无标签的数据集 D(u) = {x_m}
一个预训练好的大型VLM作为教师模型,它能为任何输入图像x生成概率预测p。
2.特征提取 (Feature Extraction):
输入图像x首先通过共享的特征提取器g,生成特征表示z = g(x)。这个主干网络是两个头共享的。
3.双头优化 (Dual-Head Optimization):
监督头 (CE Head, h_CE):这是一个专门用于监督学习的预测头。
输入:特征z。
任务 :仅使用有标签数据 D(l) 进行训练。
损失函数:标准的交叉熵损失 (Cross-Entropy Loss, L_CE),用于最小化模型预测与真实标签y_n之间的差距。
蒸馏头 (KD Head, h_KD):这是一个专门用于知识蒸馏的预测头。
输入:特征z。
任务 :使用所有数据 (D(l) 和 D(u)) 进行训练。
损失函数:KL散度损失 (Kullback-Leibler Divergence Loss, L_KD),用于最小化该头的输出与教师模型输出p之间的分布差异。
4.训练总损失 (Total Loss):
最终的训练损失是两个损失的加权和:L = λ * L_CE + (1-λ) * L_KD。由于梯度只反向传播到各自的头和共享的主干网络,两个任务之间的冲突被有效隔离。
5.推理 (Inference):
在推理时,给定一张测试图片,模型首先提取特征z。然后,两个头分别给出自己的预测。最终的预测结果p̂通过线性插值得到:
p̂ = α * σ(h_CE(z)) + (1-α) * σ(h_KD(z)/β)
其中α是平衡两个头贡献的超参数,β是用于平滑KD头输出的温度系数。
- 实验 Experimental Results
数据集:
实验在11个多样化的图像分类数据集上进行,包括通用物体识别(ImageNet, Caltech101)、细粒度分类(Stanford Cars, Flowers102等)、场景理解(SUN397)、纹理分析(DTD)等。
实验结论:
1.DHO有效性验证 (F1):为了证明DHO优于传统的单头优化(SHO)基线。实验结果(表1,图5)表明,在ImageNet和其它10个数据集的少样本(few-shot)设置下,DHO的性能稳定地超过了所有SHO基线,且几乎不增加额外的计算开销。
2.特征表示增强验证 (F2):为了证明性能提升源于缓解梯度冲突从而学到了更好的特征。通过线性评估(在冻结的特征提取器上只训练一个线性分类器)和t-SNE可视化(图7),实验表明DHO学到的特征具有更好的线性和类别可分性,Top-1准确率比基线高出0.9%。
3.双头插值有效性验证 (F3):为了证明推理时的插值策略是有效的。实验(图8)对比了仅使用CE头、仅使用KD头和使用插值策略的性能。结果显示,插值策略能在两个头的基础上进一步提升性能(平均提升1.6%),因为它能结合两者的优点,纠正单个头的错误。
4.SOTA性能验证 (F4):为了将DHO与现有最先进的方法进行比较。在ImageNet的低资源(low-shot,1%和10%标签)半监督设置下(表4),DHO(使用ViT-L/14作为学生模型)的性能超过了之前所有方法,分别将1%和10%标签下的准确率记录刷新了3%和0.1%,同时使用的模型参数更少。
- 总结 Conclusion
DHO是一个简单、高效且有效的知识蒸馏框架,它在单阶段训练中,通过解耦监督学习和知识蒸馏两个目标,成功地将大型VLM的知识迁移到紧凑模型中。这种方法尤其适用于标注数据稀缺的场景,能够学习到更高质量的特征表示,并在多个基准测试中取得了SOTA性能。