
2025.8
1.摘要
background
在多模态大语言模型(MLLM)时代,如何为视频-语言理解任务提供最佳的视觉表征是一个悬而未决的问题。当前的方法存在两极分化:一种是将图像/视频转换为分布式嵌入(visual embeddings),这种方法表达能力强,但需要大规模的指令微调数据来与语言模型对齐;另一种是使用视频字幕(caption),这种方法虽然数据高效,但会丢失视频中精细的时空信息(例如物体的精确位置和运动轨迹)。因此,本文旨在回答一个核心问题:在MLLMs中,我们是否仍然需要显式地表示物体?以及如何以一种数据高效的方式,将这些结构化的物体信息有效地整合进模型中?
innovation
1.提出ObjectMLLM框架: 这是一个能够利用现成的计算机视觉算法(如目标检测器)来提取并融合结构化视觉表征(如物体边界框)的框架。
2. 探索并验证了"符号化"表征的优越性: 论文的核心创新点是比较了两种整合物体边界框信息的方式:
嵌入投影(Embedding Projector): 将边界框的连续坐标通过一个可学习的线性层映射到LLM的嵌入空间。这是当前主流的做法。
语言符号化(Language-based Representation): 将连续的坐标进行归一化和量化,然后直接渲染成纯文本字符串(例如 60 58 70 98)。
3. 核心洞见与优势: 令人惊讶的是,实验发现简单地将坐标转为文本的"符号化"方法,其性能显著优于更复杂的嵌入投影方法。
优势: 这种方法更加数据高效(data-efficient),即使在训练数据很少的情况下也能快速学习并取得好效果。
原因: 论文推测,预训练的LLMs在其海量的语言数据训练过程中,已经内在地学习到了对空间关系的理解能力(spatially aware)。将坐标直接表示为它们词汇表中的文本(数字),可以直接复用这种已有的能力,而无需从头学习一个投影层来理解空间含义。
4. 通用性验证: 该框架不仅适用于物体边界框,还能推广到其他结构化视觉信息,如人体姿态关键点,并在相关任务上取得了性能提升。
- 方法 Method
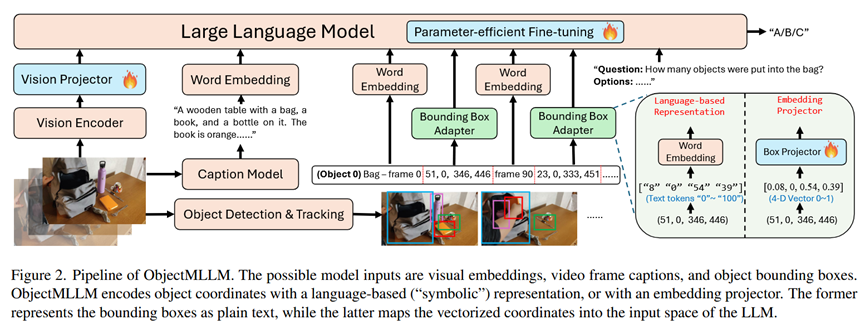
总体 Pipeline:
ObjectMLLM的整体流程如论文图2所示。其输入是多模态的,可以包括:
1.从视频帧中提取的视觉嵌入 (Visual Embeddings)。
2.由视频字幕模型生成的视频帧字幕 (Video Frame Captions)。
3.由目标检测和跟踪算法提取的带标签的物体边界框序列 (Structured Object Bounding Boxes)。
这些不同的模态信息,特别是经过"边界框适配器"处理后的物体信息,被一同送入一个大语言模型(LLM)的主干网络中。模型通过参数高效微调(Parameter-efficient Fine-tuning)来学习理解这些融合后的信息,并最终根据用户提问生成答案。
各部分细节:
1.目标检测与跟踪 (Object Detection & Tracking):
输入: 视频。
过程: 使用一个开放词汇的目标检测器 YOLO-World 在视频的关键帧上检测物体,然后使用 SAM 2 模型在整个视频中对检测到的物体进行跟踪。
输出: 一系列带有类别标签的物体及其在不同时间帧的2D边界框坐标。 (物体标签, frame_t, x1, y1, x2, y2)。
2.物体中心表征 (Object-centric Representation) - 核心模块:
这部分是论文的核心,即"边界框适配器",它将边界框坐标转换为LLM能理解的格式。
方法一:语言符号化表示 (Language-based Representation):
输入: 连续的边界框坐标 x1, y1, x2, y2。
过程:
归一化和量化: 将坐标归一化到 0, 1 范围,然后乘以100并取整,得到 0, 100 范围内的离散整数。
文本渲染: 将这些整数直接转换成文本字符串,例如 "60 58 70 98"。
输出: 一系列可以被LLM的tokenizer直接处理的文本tokens。
方法二:嵌入投影 (Embedding Projector):
输入: 连续的边界框坐标 x1, y1, x2, y2 (归一化后的4D向量)。
过程: 通过一个简单的线性层,将这个4D向量投影成与LLM的词嵌入维度相同的向量。
输出: 一个嵌入向量 (embedding vector)。
3.微调策略 (Fine-tuning Strategy):
采用参数高效微调(如LoRA或LLaMA-Adapter),只训练适配器和LLM骨干网络的一小部分参数。
采用模态逐一训练 (modality-by-modality) 的策略:先用字幕数据训练模型,让模型学会利用字幕后,再加入边界框数据进行进一步微调,最后再加入视觉嵌入。
- 实验 Experimental Results
实验数据集:
使用了6个视频问答(Video QA)基准数据集,包括:
强时空推理: CLEVRER-MC, Perception Test, STAR
因果和意图推理: NExT-QA, IntentQA
人体动作理解: BABEL-QA
实验结论:
1.实验目的:比较两种边界框适配器。
结论: 在CLEVRER-MC和Perception Test上,语言符号化表示方法全面优于嵌入投影方法,尤其是在训练数据较少时优势更明显,证明了其数据高效性。
2.实验目的:分析不同模态(视频、字幕、边界框)的影响。
结论: 在需要精细时空推理的数据集(CLEVRER-MC, Perception Test, STAR)上,加入边界框信息能带来巨大性能提升 。而在侧重于人类行为和因果关系的数据集(NExT-QA, IntentQA)上,字幕信息则更为关键。这说明不同模态信息在不同任务中扮演的角色不同。
3.实验目的:验证该方法能否提升已有的预训练MLLM。
结论: 在强大的预训练VideoLLaMA2模型基础上,额外加入边界框信息进行微调,依然能在时空推理任务上取得显著提升。这表明显式的物体坐标信息是对分布式视觉嵌入的有效补充。
4.实验目的:验证方法的泛化能力。
结论: 将同样的方法应用于表示人体姿态关键点,在BABEL-QA数据集上也取得了性能提升,证明了该框架的通用性。
- 总结 Conclusion
在视频-语言理解任务中,显式地整合以物体为中心的时空信息至关重要 。将这些结构化信息(如边界框)渲染成纯文本是一种极其有效且数据高效的策略,因为它能直接利用并唤醒大语言模型在预训练阶段学到的空间推理能力。这种方法为整合各种计算机视觉模块(检测、姿态估计等)到MLLM中提供了一个简单、通用且强大的接口,让"视觉再次成为视觉-语言模型的一等公民"。