第39届神经信息处理系统大会(NeurIPS 2025)将于2025年12月在美国圣地亚哥会议中心(San Diego Convention Center)隆重举行。NeurIPS是人工智能和机器学习领域最具影响力的国际顶级会议之一,涵盖深度学习、分布式机器学习、强化学习、自然语言处理、计算机视觉等多个研究方向。
本推文将介绍一篇被NeurIPS 2025接收的前沿工作《FedFree: Breaking Knowledge-sharing Barriers through Layer-wise Alignment in Heterogeneous Federated Learning》。该论文由上海电力大学杜海舟老师及其团队完成。该论文提出了一种全新的异构联邦学习(HtFL)框架 FedFree,通过逆向分层知识迁移机制与知识增益熵(Knowledge Gain Entropy, KGE),在无需代理数据的情况下实现跨客户端的高效、隐私保护的知识共享。大量实验表明,FedFree在CIFAR-10与CIFAR-100数据集上,相较于现有最先进方法,准确率最高提升可达46.3%,展现了极强的竞争力与可扩展性。
原文链接:https://pan.baidu.com/s/1X71UcQz3nm1r_yVkEcafYA?pwd=h7ub
代码链接:https://pan.baidu.com/s/1X71UcQz3nm1r_yVkEcafYA?pwd=h7ub
本推文的作者为向怡然,审核为杜海舟老师。本推文由论文作者授权发布。
一、研究背景及主要贡献
在现实的边缘计算与分布式智能场景中,客户端设备往往存在显著差异,不仅本地数据呈现非独立同分布(non-IID),而且模型架构也多种多样,从轻量化的卷积神经网络到复杂的ResNet、甚至专用的小模型架构均有分布。这种统计和结构上的双重异构性,给联邦学习带来了巨大的挑战。传统方法虽然在一定程度上尝试缓解这一问题,但仍存在明显局限。例如,基于知识蒸馏的方案依赖代理数据,容易引发隐私泄露风险;基于原型或表示共享的方法难以实现细粒度的层级知识对齐;而架构匹配与压缩策略往往在提升效率的同时丧失关键信息,难以兼顾个性化和性能。论文的贡献可以概括为:
1) 提出逆向分层知识迁移机制:利用高变化率的关键层作为知识源,结合服务器端生成的高斯伪数据,实现无需代理数据的本地到全局知识传递。
2) 提出知识增益熵( KGE ):通过量化全局层与本地层权重分布的熵差,选择性地将"知识密度更高"的全局层反馈给客户端,实现针对性的全局到本地知识对齐。
3) 理论与实验验证:论文在非凸与强凸场景下均给出收敛性证明,并在 CIFAR-10/100 上大幅超越八个代表性基线方法,性能提升最高达 46.3% 。
二、方法
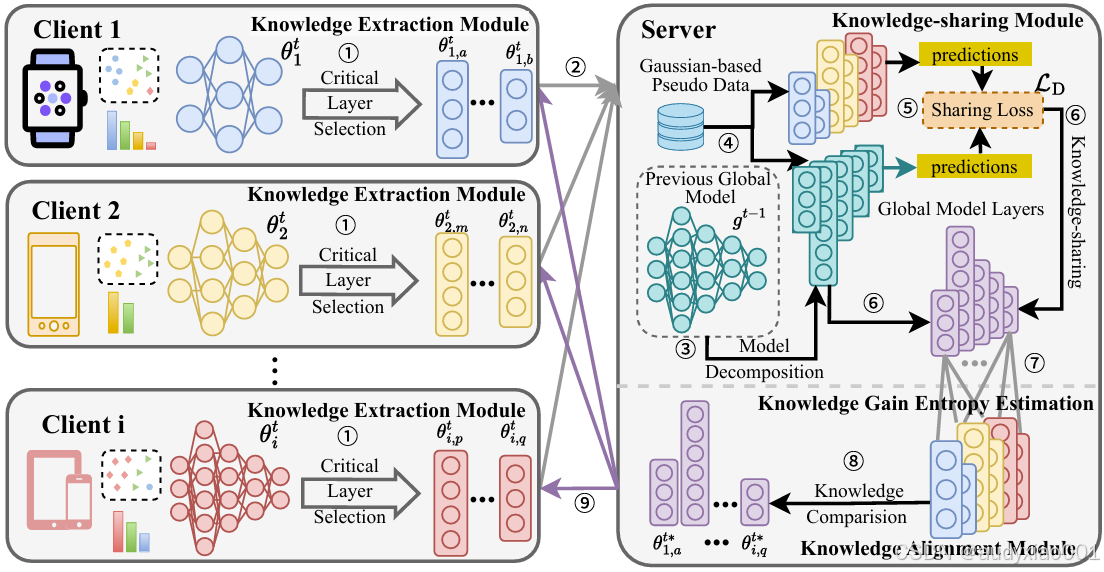
图1 FedFree的整体架构
FedFree的整体框架由三个紧密衔接的模块构成(见图1)。首先,在客户端侧设置了知识提取模块:每个客户端在完成本地训练后,会根据参数更新幅度选择前k个变化最显著的关键层进行上传,从而在降低通信开销的同时确保共享的内容最具价值。随后,在服务器侧引入知识共享模块以实现本地到全局的知识迁移。服务器无需依赖真实代理数据,而是生成高斯伪数据作为输入,并通过"功能响应一致性"更新全局模型,使其在伪数据上的输出能够贴近各客户端关键层的响应,这种伪数据驱动的蒸馏方式有效突破了代理数据依赖与模型架构不兼容的限制。最后,全局到本地的知识对齐模块通过计算全局层与客户端层之间的知识增益熵(KGE),判定哪些全局层包含更丰富的模式信息,并将其反馈替换到客户端对应位置;在维度不匹配的情况下,则通过参数投影与适配器层实现无缝对齐。通过这三个模块的协同作用,FedFree不仅在保护隐私的前提下实现了层级细粒度的知识共享,还有效增强了客户端模型的个性化表现,相较于传统的模型平均或原型共享方式具有显著优势。
三、实验
论文在PeMS、NYCTaxi、NYCBike和CHITaxi等四个公开数据集上对TraffiCoT-R框架进行了全面评估。
3.1 与基线模型的性能对比
( 1 )实施细节
论文在PyTorch框架下实现了FedFree,并在多种异构场景中进行了实验验证。硬件方面,实验主要使用NVIDIA GTX 2080Ti与Tesla T4GPU。所有模型均从头开始训练,不依赖预训练权重。在优化器设置上,客户端采用SGD,初始学习率为0.01,动量大小为0.9,批量大小为100,每个客户端在每一通信轮内进行5轮本地训练。整个训练过程共包含200轮通信。为了提升泛化能力,作者在数据预处理阶段使用了常见的数据增强策略,同时保持输入图像分辨率的一致性,以保证不同客户端在高度异构环境下的可比性。
( 2 )实验结果
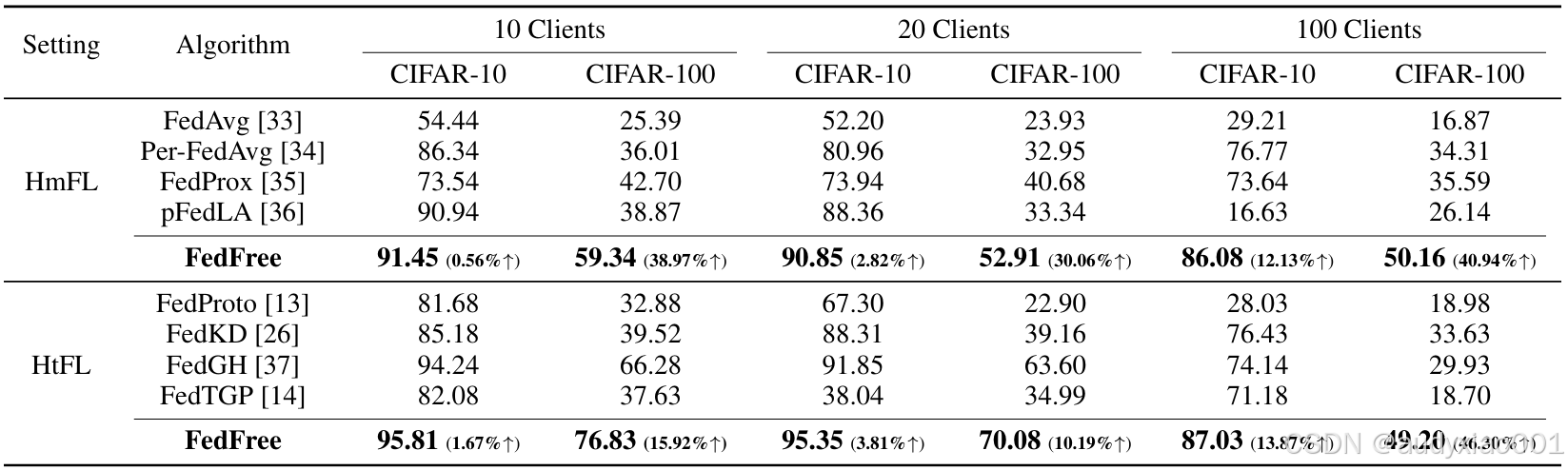
FedFree的性能在CIFAR-10和CIFAR-100上得到了全面评估,实验同时涵盖了同构联邦学习与异构联邦学习的对比。在同构场景下,FedFree与FedAvg、Per-FedAvg、FedProx、pFedLA等方法进行了比较;在异构场景下,则与FedProto、FedKD、FedGH 和 FedTGP等代表性方法对照。实验结果显示,FedFree在多个指标上均显著优于现有方法。在CIFAR-100 的100客户端异构场景中,FedFree相较于FedKD的准确率提升最高达到46.3%,表现出强劲的优势。在CIFAR-10数据集上,FedFree的最高准确率为95.81%,比现有最佳基线方法进一步提高1.67%。消融实验表明,高变化率关键层的选择比随机层上传带来了更显著的性能提升,而基于伪数据的蒸馏机制也明显优于传统参数平均方式。这些结果充分证明了FedFree在准确性、个性化和通信效率上的综合优势。
表 1 在 3 个公开数据集上与最先进的方法的比较
四、总结与展望
论文提出了一种创新性的异构联邦学习框架 FedFree,通过逆向分层知识迁移和知识增益熵机制,实现了无需代理数据的高效知识共享。实验结果表明,FedFree 在 CIFAR-10 与 CIFAR-100 数据集上的表现大幅超越了多种代表性方法,性能提升幅度最高可达 46.3%。同时,方法在不同客户端规模下均保持稳定的表现,展现了良好的可扩展性与鲁棒性。FedFree 不仅突破了异构联邦学习中的知识共享壁垒,还为边缘智能与隐私计算的深度融合提供了一条新路径,也为生成式人工智能时代的大小模型协同工作提供了一种新思路。