
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
作为一名长期深耕数据采集与自动化领域的技术博主,我深刻体会到爬虫技术在现代互联网生态中的核心价值。从最初简单的网页内容抓取,到如今复杂的分布式数据采集系统,爬虫技术已经发展成为连接现实世界与数字世界的桥梁。在这篇技术深度解析中,我将分享自己多年来在爬虫与自动化领域的实战经验,涵盖从基础原理到高级架构的完整知识体系。
爬虫技术的本质是对互联网信息的系统化采集与处理,它不仅仅是简单的数据抓取工具,更是一个涉及网络协议、数据解析、反爬对抗、性能优化等多维度的复杂系统工程。在实际项目中,我遇到过各种挑战:从网站的反爬机制到数据质量保证,从分布式部署到资源调度优化。这些经历让我认识到,一个优秀的爬虫系统需要平衡效率、稳定性和合规性三大要素。
在自动化技术方面,爬虫与工作流自动化的结合创造了无限可能。通过将爬虫技术与任务调度、异常处理、监控告警等自动化组件集成,我们可以构建出能够自主运行、自我修复的智能数据采集系统。这种系统不仅能够大幅提升工作效率,还能在数据驱动的决策过程中发挥关键作用。
本文将采用理论与实践相结合的方式,通过详细的代码示例和架构分析,帮助读者建立完整的爬虫技术知识体系。无论你是刚入门的开发者,还是希望提升现有系统性能的工程师,都能从本文中获得实用的技术见解和解决方案。
1. 爬虫技术基础原理
1.1 HTTP协议与请求机制
爬虫技术的核心建立在HTTP协议之上。理解HTTP请求的完整生命周期是构建稳定爬虫系统的前提。
python
import requests
import time
from urllib.parse import urljoin, urlparse
import random
class BasicCrawler:
def __init__(self, base_url, delay=1):
self.base_url = base_url
self.delay = delay
self.session = requests.Session()
# 设置通用的请求头,模拟真实浏览器
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
})
def make_request(self, url, method='GET', **kwargs):
"""发送HTTP请求的基础方法"""
full_url = urljoin(self.base_url, url)
try:
response = self.session.request(method, full_url, **kwargs)
response.raise_for_status() # 检查HTTP状态码
return response
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
finally:
# 遵守爬虫礼仪,添加延迟
time.sleep(self.delay + random.uniform(0, 0.5))
def crawl_page(self, url, parser=None):
"""爬取单个页面"""
response = self.make_request(url)
if response and response.status_code == 200:
if parser:
return parser(response.text)
return response.text
return None
# 使用示例
crawler = BasicCrawler('https://example.com')
content = crawler.crawl_page('/page1')关键代码解析:
User-Agent设置:模拟真实浏览器行为,避免被识别为爬虫- 异常处理机制:确保单次请求失败不影响整体流程
- 延迟控制:遵守robots.txt的爬取间隔要求
1.2 数据解析技术
数据解析是爬虫技术的核心环节,常用的解析方式包括正则表达式、XPath和BeautifulSoup。
python
from bs4 import BeautifulSoup
import re
import json
class DataParser:
@staticmethod
def parse_with_bs4(html_content, selector):
"""使用BeautifulSoup解析HTML"""
soup = BeautifulSoup(html_content, 'html.parser')
elements = soup.select(selector)
return [elem.get_text(strip=True) for elem in elements]
@staticmethod
def parse_with_regex(text, pattern):
"""使用正则表达式提取数据"""
matches = re.findall(pattern, text)
return matches
@staticmethod
def parse_json_data(json_text, key_path):
"""解析JSON格式数据"""
try:
data = json.loads(json_text)
# 支持嵌套键路径解析
keys = key_path.split('.')
result = data
for key in keys:
result = result[key]
return result
except (json.JSONDecodeError, KeyError) as e:
print(f"JSON解析错误: {e}")
return None
# 综合解析示例
def comprehensive_parser(html_content):
"""综合多种解析方法的示例"""
# 1. 使用BeautifulSoup提取结构化数据
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.find('title').get_text() if soup.find('title') else ''
# 2. 使用CSS选择器提取特定元素
articles = soup.select('article.post')
article_data = []
for article in articles:
data = {
'title': article.select_one('h2').get_text(strip=True) if article.select_one('h2') else '',
'content': article.select_one('.content').get_text(strip=True) if article.select_one('.content') else '',
'date': article.select_one('.date').get_text(strip=True) if article.select_one('.date') else ''
}
article_data.append(data)
# 3. 使用正则表达式提取特定模式
emails = re.findall(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', html_content)
return {
'page_title': title,
'articles': article_data,
'emails': emails
}2. 高级爬虫架构设计
2.1 分布式爬虫系统架构
图1:分布式爬虫系统架构图
数据处理层 执行层 控制层 数据解析器 数据清洗 数据存储 爬虫节点1 爬虫节点2 爬虫节点N 调度中心 URL管理器 监控告警 性能分析 自动扩缩容
2.2 反爬虫对抗策略
现代网站普遍采用各种反爬虫技术,爬虫系统需要相应的应对策略。
python
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from fake_useragent import UserAgent
class AntiAntiCrawler:
def __init__(self):
self.ua = UserAgent()
self.driver = None
def setup_selenium(self, headless=True):
"""配置Selenium浏览器驱动"""
options = webdriver.ChromeOptions()
if headless:
options.add_argument('--headless')
# 反检测配置
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
self.driver = webdriver.Chrome(options=options)
# 执行反检测脚本
self.driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
def rotate_user_agent(self):
"""轮换User-Agent"""
return self.ua.random
def simulate_human_behavior(self, element):
"""模拟人类操作行为"""
# 随机延迟
time.sleep(random.uniform(1, 3))
# 模拟鼠标移动
action = webdriver.ActionChains(self.driver)
action.move_to_element(element).perform()
time.sleep(random.uniform(0.5, 1.5))
# 点击元素
element.click()
def handle_captcha(self, captcha_element):
"""处理验证码(基础版本)"""
# 在实际项目中,这里可以集成第三方验证码识别服务
print("检测到验证码,需要人工干预")
input("请手动解决验证码后按回车继续...")
def smart_wait(self, by, value, timeout=10):
"""智能等待元素加载"""
try:
element = WebDriverWait(self.driver, timeout).until(
EC.presence_of_element_located((by, value))
)
return element
except:
print(f"元素加载超时: {by}={value}")
return None
# 高级爬虫类
class AdvancedCrawler(BasicCrawler):
def __init__(self, base_url, use_selenium=False):
super().__init__(base_url)
self.use_selenium = use_selenium
if use_selenium:
self.anti_crawler = AntiAntiCrawler()
self.anti_crawler.setup_selenium()
def crawl_dynamic_content(self, url, wait_for=None):
"""爬取动态加载内容"""
if not self.use_selenium:
return self.crawl_page(url)
self.anti_crawler.driver.get(urljoin(self.base_url, url))
if wait_for:
element = self.anti_crawler.smart_wait(By.CSS_SELECTOR, wait_for)
if element:
return self.anti_crawler.driver.page_source
return self.anti_crawler.driver.page_source3. 自动化工作流设计
3.1 任务调度与监控
图2:自动化任务调度流程图
调度器 工作节点 监控系统 数据库 检查任务队列 分配爬虫任务 执行爬虫逻辑 存储采集数据 上报执行状态 心跳检测 返回状态 loop 健康检查 任务完成通知 清理任务记录 任务失败告警 重试或标记失败 alt 任务成功 任务失败 生成监控报告 调度器 工作节点 监控系统 数据库
3.2 自动化运维脚本
python
import schedule
import time
import logging
from datetime import datetime
import smtplib
from email.mime.text import MimeText
import json
class AutomationManager:
def __init__(self, config_file='config.json'):
self.config = self.load_config(config_file)
self.setup_logging()
def load_config(self, config_file):
"""加载配置文件"""
try:
with open(config_file, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
return {
'monitoring': {'interval': 300},
'alerts': {'enabled': True},
'backup': {'enabled': False}
}
def setup_logging(self):
"""配置日志系统"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('automation.log'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def schedule_tasks(self):
"""安排定时任务"""
# 每日数据采集任务
schedule.every().day.at("02:00").do(self.daily_crawl_task)
# 每小时健康检查
schedule.every().hour.do(self.health_check)
# 每30分钟监控数据质量
schedule.every(30).minutes.do(self.data_quality_check)
def daily_crawl_task(self):
"""每日爬虫任务"""
self.logger.info("开始执行每日爬虫任务")
try:
# 执行爬虫逻辑
crawler = AdvancedCrawler(self.config['target_url'])
results = crawler.crawl_sitemap()
# 数据验证
if self.validate_data(results):
self.backup_data(results)
self.logger.info("每日爬虫任务完成")
else:
self.send_alert("数据验证失败", "采集的数据未通过质量检查")
except Exception as e:
self.logger.error(f"每日爬虫任务失败: {e}")
self.send_alert("爬虫任务异常", str(e))
def health_check(self):
"""系统健康检查"""
checks = [
self.check_database_connection,
self.check_disk_space,
self.check_network_status
]
for check in checks:
if not check():
self.send_alert("系统健康检查失败", f"检查项 {check.__name__} 失败")
def send_alert(self, subject, message):
"""发送告警通知"""
if not self.config['alerts']['enabled']:
return
try:
# 邮件告警配置
msg = MimeText(message, 'plain', 'utf-8')
msg['Subject'] = subject
msg['From'] = self.config['smtp']['from_addr']
msg['To'] = ', '.join(self.config['alerts']['recipients'])
with smtplib.SMTP(self.config['smtp']['server']) as server:
server.login(self.config['smtp']['username'],
self.config['smtp']['password'])
server.send_message(msg)
self.logger.info(f"告警发送成功: {subject}")
except Exception as e:
self.logger.error(f"告警发送失败: {e}")
def run(self):
"""启动自动化管理器"""
self.logger.info("自动化管理器启动")
self.schedule_tasks()
while True:
schedule.run_pending()
time.sleep(1)
# 配置示例
config = {
"target_url": "https://example.com",
"monitoring": {"interval": 300},
"alerts": {
"enabled": True,
"recipients": ["admin@example.com"]
},
"smtp": {
"server": "smtp.example.com",
"username": "alert@example.com",
"password": "password",
"from_addr": "alert@example.com"
}
}
# 保存配置
with open('config.json', 'w') as f:
json.dump(config, f, indent=2)
# 启动自动化系统
manager = AutomationManager()
manager.run()4. 数据可视化与分析
4.1 爬虫性能监控仪表盘
图3:爬虫性能监控仪表盘
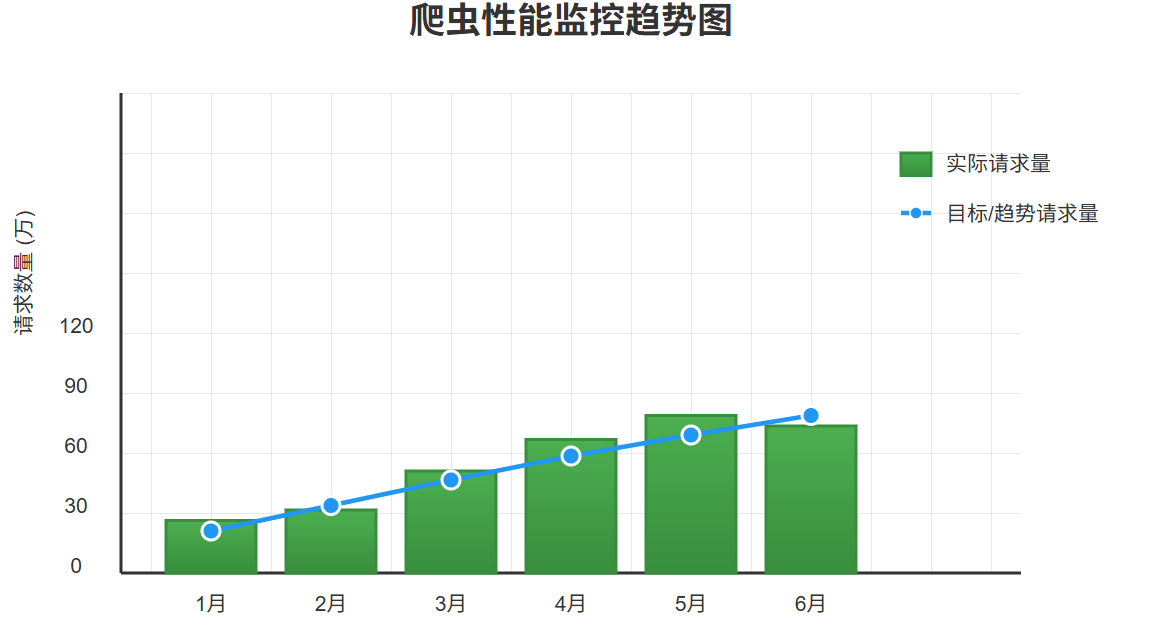
4.2 数据质量分析图表
图4:数据采集质量分布图
5. 技术对比与选型指南
5.1 主流爬虫框架对比
表1:Python爬虫框架功能对比
| 特性维度 | Scrapy | Requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|---|
| 学习曲线 | 中等 | 简单 | 中等 | 中等 |
| 性能 | 高 | 高 | 低 | 中等 |
| 动态内容 | 有限 | 无 | 支持 | 优秀 |
| 分布式 | 原生支持 | 需自定义 | 复杂 | 复杂 |
| 反爬能力 | 中等 | 低 | 高 | 高 |
| 社区生态 | 丰富 | 丰富 | 丰富 | 成长中 |
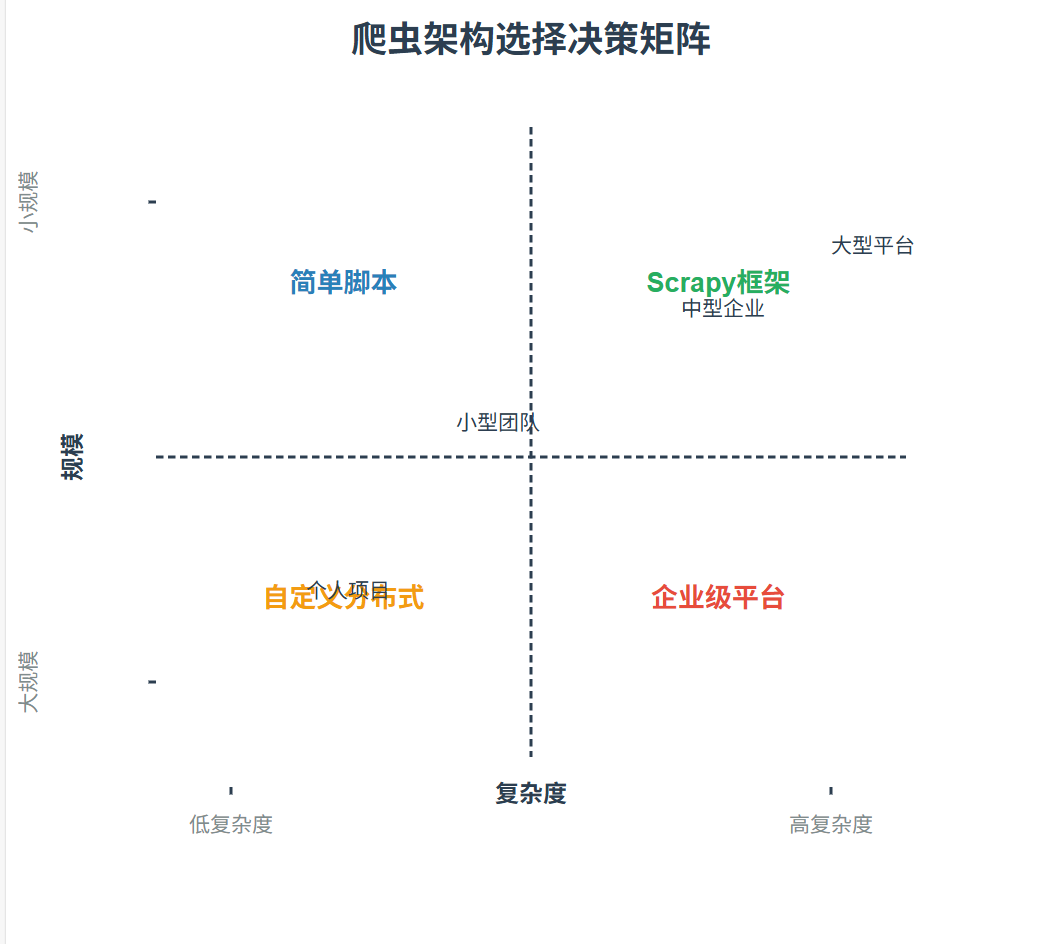
5.2 架构选择决策矩阵
图5:爬虫架构选择象限图
6. 最佳实践与经验分享
技术箴言 :"优秀的爬虫不是最快的,而是最稳定的。在数据采集的世界里,可靠性远比速度更重要。"
6.1 合规性与道德考量
在爬虫开发过程中,必须始终关注法律合规性和道德规范:
- 遵守robots.txt:尊重网站的爬虫政策
- 控制访问频率:避免对目标网站造成压力
- 数据使用授权:确保采集的数据有合法使用权限
- 隐私保护:不采集敏感个人信息
6.2 性能优化技巧
python
import asyncio
import aiohttp
from concurrent.futures import ThreadPoolExecutor
import redis
import hashlib
class OptimizedCrawler:
def __init__(self, max_concurrent=10):
self.max_concurrent = max_concurrent
self.redis_client = redis.Redis(host='localhost', port=6379, db=0)
async def async_crawl(self, urls):
"""异步并发爬取"""
connector = aiohttp.TCPConnector(limit=self.max_concurrent)
timeout = aiohttp.ClientTimeout(total=30)
async with aiohttp.ClientSession(connector=connector, timeout=timeout) as session:
tasks = [self.fetch_url(session, url) for url in urls]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
async def fetch_url(self, session, url):
"""异步获取单个URL"""
try:
async with session.get(url) as response:
content = await response.text()
# 内容去重
content_hash = hashlib.md5(content.encode()).hexdigest()
if not self.is_duplicate(content_hash):
return content
return None
except Exception as e:
print(f"异步爬取失败 {url}: {e}")
return None
def is_duplicate(self, content_hash):
"""基于Redis的内容去重"""
key = f"content:{content_hash}"
if self.redis_client.exists(key):
return True
self.redis_client.setex(key, 86400, 1) # 24小时缓存
return False
def batch_process(self, data_list, processor, batch_size=100):
"""批量数据处理"""
with ThreadPoolExecutor(max_workers=4) as executor:
batches = [data_list[i:i + batch_size] for i in range(0, len(data_list), batch_size)]
results = list(executor.map(processor, batches))
return [item for sublist in results for item in sublist]
# 性能优化示例
async def main():
urls = [f"https://example.com/page{i}" for i in range(1, 101)]
crawler = OptimizedCrawler(max_concurrent=20)
results = await crawler.async_crawl(urls)
valid_results = [r for r in results if r is not None]
print(f"成功爬取 {len(valid_results)} 个页面,去重后 {len(valid_results)} 个唯一内容")
# 运行异步爬虫
# asyncio.run(main())总结
作为在爬虫与自动化领域深耕多年的技术实践者,我见证了这项技术从简单的数据抓取工具发展到如今复杂的智能系统工程的完整演进过程。通过本文的系统性阐述,我希望能够为读者提供一个全面而实用的技术指南,帮助大家在各自的业务场景中构建高效、稳定的数据采集与自动化解决方案。
爬虫技术的核心价值在于它将散落在互联网各个角落的信息转化为结构化的知识资产。在这个过程中,我们不仅需要关注技术实现,更要重视系统的可维护性、扩展性和合规性。一个优秀的爬虫系统应该像精密的钟表一样,各个组件协同工作,在长时间运行中保持稳定可靠。
在自动化方面,真正的智能化不仅仅是任务的自动执行,更是系统的自我优化和决策能力的体现。通过将机器学习、异常检测、智能调度等先进技术融入传统自动化流程,我们可以构建出能够适应复杂环境变化的智能系统。这种系统不仅能够提升工作效率,更能为业务决策提供高质量的数据支持。
技术发展日新月异,爬虫与自动化领域也在不断演进。作为技术从业者,我们需要保持持续学习的态度,紧跟技术发展的步伐。同时,我们也要牢记技术服务的本质,始终将合规性、伦理性和社会责任放在重要位置。
未来,随着人工智能技术的进一步发展,爬虫与自动化将更加智能化、个性化。我期待与各位技术同仁一起,在这个充满挑战和机遇的领域中继续探索,共同推动技术的进步和应用。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!