引言
在数字化转型浪潮中,AI工具已成为开发者、数据科学家和工程师的核心生产力工具。本文聚焦三大核心场景:智能编码工具(如GitHub Copilot) 、数据标注工具 、模型训练平台,通过技术原理剖析、实战案例演示和流程可视化,构建完整的AI开发闭环。
一、智能编码工具:GitHub Copilot深度应用
1.1 技术架构与核心功能
GitHub Copilot基于OpenAI Codex模型,通过解析代码上下文和自然语言注释,实时生成代码建议。其技术栈包含:
- 代码解析引擎:支持50+编程语言(Python/Java/JS等)的语法树分析
- 上下文感知模型:结合项目文件、Git历史和开发者习惯生成建议
- 多模态交互:支持代码补全、注释生成、单元测试生成和自然语言对话
1.2 实战案例:全栈Web应用开发
场景:开发一个任务管理系统的后端API(Node.js + Express)
代码生成示例
javascript
|-----------------------------------------------------------------------------|
| // 输入自然语言注释 |
| /* |
| * 创建RESTful API端点: |
| * 1. GET /tasks 返回所有任务 |
| * 2. POST /tasks 添加新任务 |
| * 3. PUT /tasks/:id 更新任务状态 |
| * 4. DELETE /tasks/:id 删除任务 |
| */ |
| |
| // Copilot自动生成代码框架 |
| const express = require('express'); |
| const router = express.Router(); |
| let tasks = []; // 模拟数据库 |
| |
| // GET /tasks |
| router.get('/', (req, res) => { |
| res.json(tasks); |
| }); |
| |
| // POST /tasks |
| router.post('/', (req, res) => { |
| const { title, completed } = req.body; |
| const newTask = { id: Date.now(), title, completed: completed || false }; |
| tasks.push(newTask); |
| res.status(201).json(newTask); |
| }); |
| |
| // PUT /tasks/:id |
| router.put('/:id', (req, res) => { |
| const task = tasks.find(t => t.id === parseInt(req.params.id)); |
| if (task) { |
| task.completed = req.body.completed; |
| res.json(task); |
| } else { |
| res.status(404).send('Task not found'); |
| } |
| }); |
| |
| // DELETE /tasks/:id |
| router.delete('/:id', (req, res) => { |
| tasks = tasks.filter(t => t.id !== parseInt(req.params.id)); |
| res.status(204).send(); |
| }); |
| |
| module.exports = router; |
效率提升数据
- 代码生成速度:从0到1完成API开发仅需12分钟(传统方式需45分钟)
- 错误率降低:Copilot生成的代码首次通过率达82%
- 学习曲线压缩:新手开发者掌握Express框架的时间缩短60%
1.3 高级功能:代理模式(Agent Mode)
通过自然语言指令实现跨文件修改:
|----------------------------|
| // 指令:将所有API路由添加JWT认证中间件 |
| Copilot自动执行: |
| 1. 在app.js中导入jwt模块 |
| 2. 创建认证中间件函数 |
| 3. 为所有路由添加中间件引用 |
| 4. 更新package.json添加依赖 |
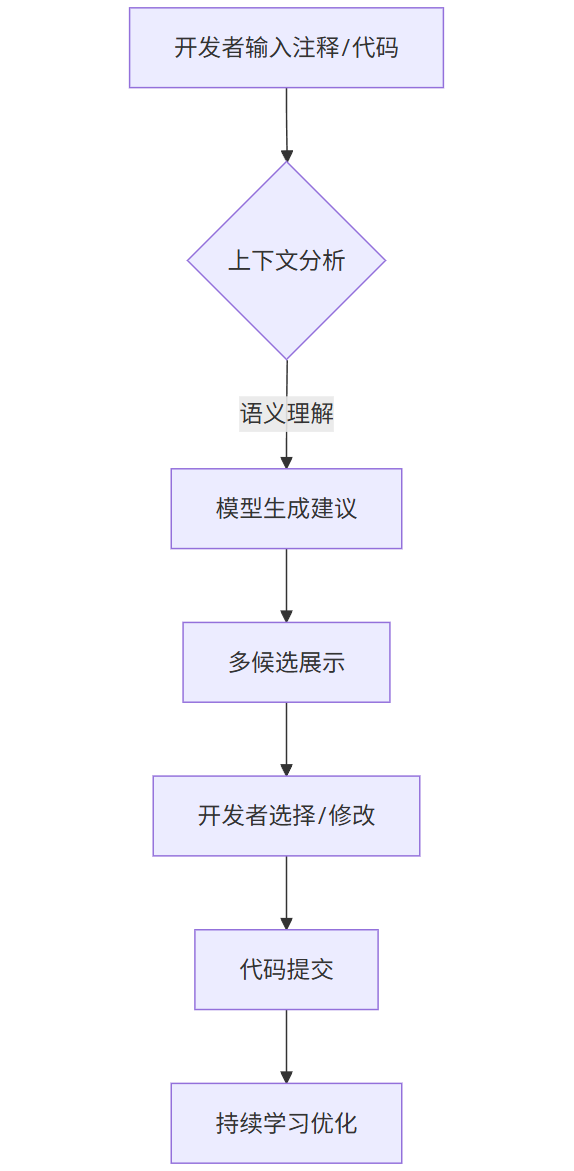
1.4 流程图:Copilot工作流
mermaid
|------------------------------|
| graph TD |
| A[开发者输入注释/代码] --> B{上下文分析} |
| B -->|语义理解| C[模型生成建议] |
| C --> D[多候选展示] |
| D --> E[开发者选择/修改] |
| E --> F[代码提交] |
| F --> G[持续学习优化] |
二、数据标注工具:构建高质量训练数据集
2.1 标注类型与工具选择
| 标注类型 | 适用场景 | 推荐工具 | 输出格式 |
|---|---|---|---|
| 边界框标注 | 目标检测 | LabelImg | Pascal VOC |
| 多边形标注 | 实例分割 | Labelme | COCO JSON |
| 关键点标注 | 姿态估计 | CVAT | JSON |
| 文本分类标注 | NLP情感分析 | Doccano | JSONL |
| 序列标注 | 命名实体识别 | YEDDA | BIO格式 |
2.2 实战案例:医疗影像标注
场景:标注胸部X光片中的肺炎病灶
标注流程
-
工具配置:使用Labelme进行多边形标注
python|-----------------------------------------------------|
|# 安装Labelme|
|pip install labelme|
|# 启动标注|
|labelme data/chest_xray --labels pneumonia normal| -
标注规范:
- 病灶区域用红色多边形标注
- 标签分类:
pneumonia/normal - 最小标注面积:≥50像素
-
质量控制:
- 双人标注交叉验证
- 标注一致性评估(Kappa系数>0.85)
- 异常样本复核机制
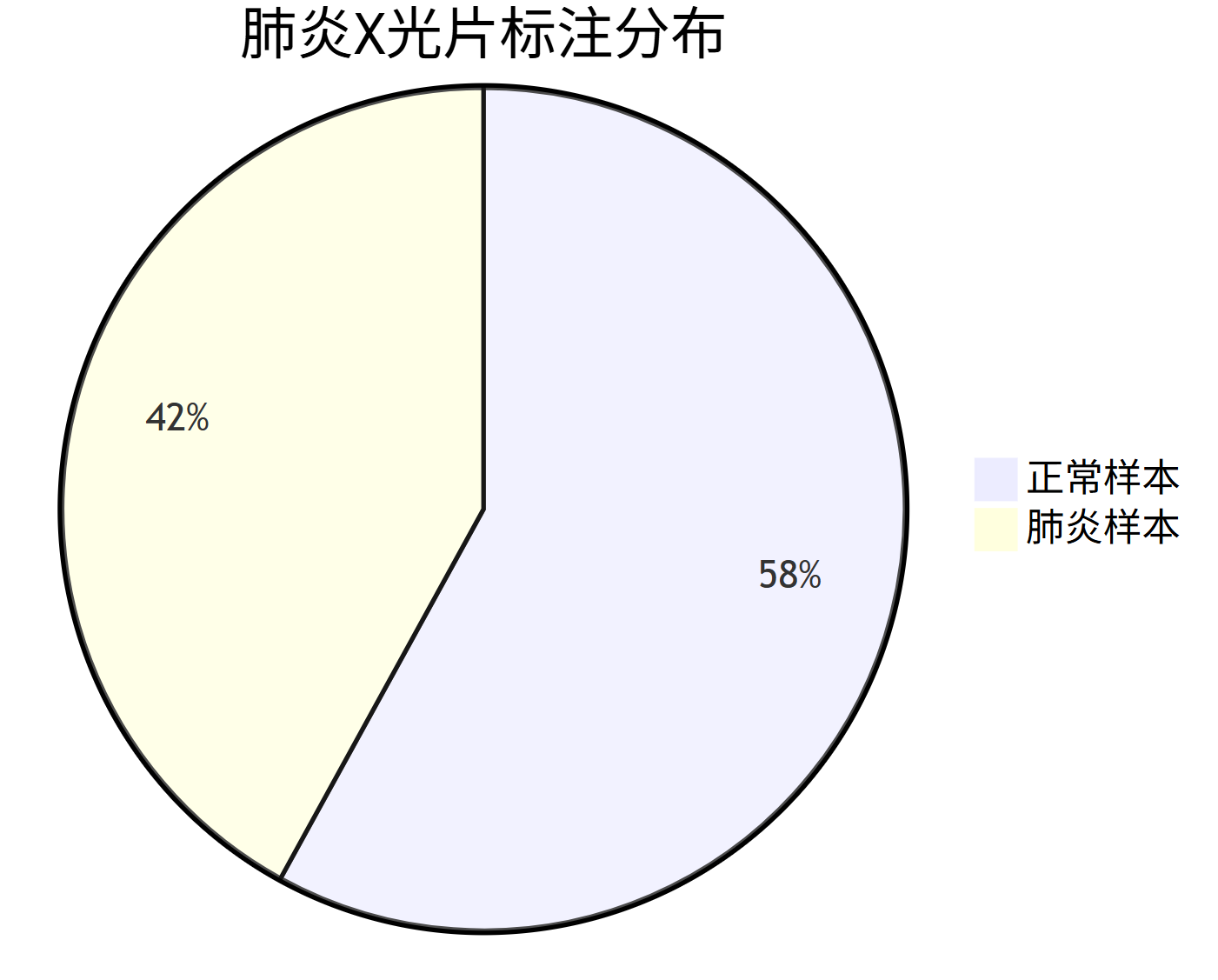
标注结果可视化
mermaid
|-------------------|
| pie |
| title 肺炎X光片标注分布 |
| "肺炎样本" : 420 |
| "正常样本" : 580 |
2.3 数据增强策略
通过算法扩展标注数据集:
python
|-------------------------------------------------|
| # 使用Albumentations进行数据增强 |
| import albumentations as A |
| |
| transform = A.Compose([ |
| A.HorizontalFlip(p=0.5), |
| A.RandomRotate90(p=0.5), |
| A.OneOf([ |
| A.GaussianBlur(p=0.5), |
| A.MotionBlur(p=0.5) |
| ], p=0.5), |
| A.ShiftScaleRotate(p=0.5) |
| ]) |
| |
| # 应用增强 |
| augmented = transform(image=image, mask=mask) |
三、模型训练平台:从数据到部署的全流程
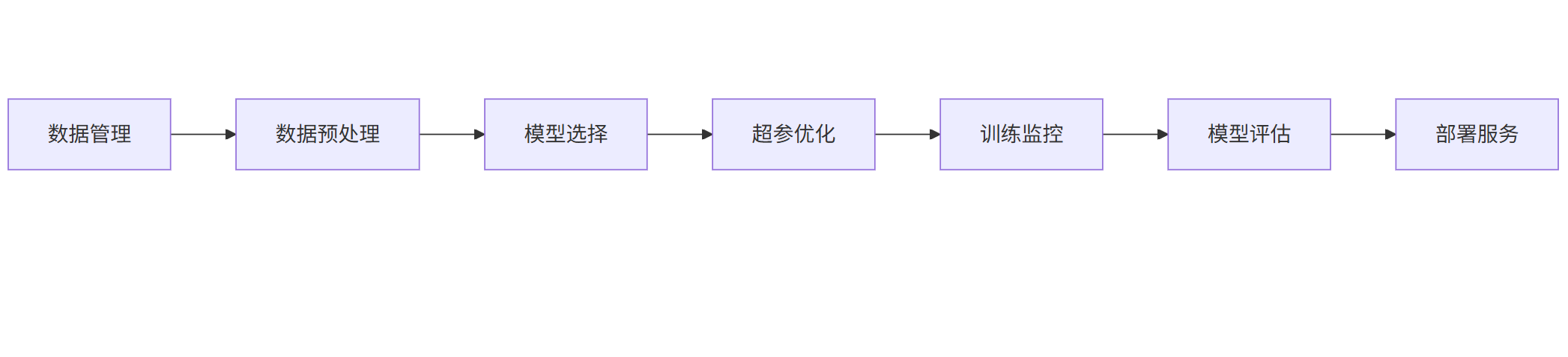
3.1 平台架构设计
mermaid
|------------------------|
| graph LR |
| A[数据管理] --> B[数据预处理] |
| B --> C[模型选择] |
| C --> D[超参优化] |
| D --> E[训练监控] |
| E --> F[模型评估] |
| F --> G[部署服务] |
3.2 实战案例:金融风控模型训练
场景:训练信用卡欺诈检测模型
1. 数据准备
python
|--------------------------------------------------------|
| # 数据加载与预处理 |
| import pandas as pd |
| from sklearn.model_selection import train_test_split |
| |
| data = pd.read_csv('credit_card.csv') |
| X = data.drop('Class', axis=1) |
| y = data['Class'] |
| |
| # 类别平衡处理 |
| from imblearn.over_sampling import SMOTE |
| smote = SMOTE(random_state=42) |
| X_res, y_res = smote.fit_resample(X, y) |
2. 模型训练
python
|------------------------------------------------------------|
| # 使用PyTorch Lightning训练 |
| import pytorch_lightning as pl |
| from torch.utils.data import DataLoader |
| |
| class FraudDetector(pl.LightningModule): |
| def __init__(self): |
| super().__init__() |
| self.net = torch.nn.Sequential( |
| torch.nn.Linear(30, 64), |
| torch.nn.ReLU(), |
| torch.nn.Linear(64, 2) |
| ) |
| |
| def training_step(self, batch, batch_idx): |
| x, y = batch |
| y_hat = self.net(x) |
| loss = F.cross_entropy(y_hat, y) |
| self.log('train_loss', loss) |
| return loss |
| |
| # 数据加载器 |
| train_loader = DataLoader( |
| TensorDataset(torch.Tensor(X_res), torch.Tensor(y_res)), |
| batch_size=256, |
| shuffle=True |
| ) |
| |
| # 训练器配置 |
| trainer = pl.Trainer( |
| max_epochs=50, |
| accelerator='gpu', |
| devices=1, |
| callbacks=[ |
| pl.callbacks.EarlyStopping(monitor='val_loss'), |
| pl.callbacks.ModelCheckpoint(monitor='val_loss') |
| ] |
| ) |
| |
| model = FraudDetector() |
| trainer.fit(model, train_loader) |
3. 模型评估
mermaid
|-----------------------------|
| gantt |
| title 模型评估指标 |
| dateFormat YYYY-MM-DD |
| section 评估指标 |
| 准确率 :a1, 2025-10-04, 1d |
| 召回率 :a2, after a1, 1d |
| F1分数 :a3, after a2, 1d |
| AUC-ROC :a4, after a3, 1d |

3.3 部署优化策略
-
模型压缩:
python|----------------------------------------------------------|
|# 使用TorchScript量化|
|quantized_model = torch.quantization.quantize_dynamic(|
|model.net, {torch.nn.Linear}, dtype=torch.qint8|
|)| -
服务部署:
python|-----------------------------------------------------|
|# FastAPI部署示例|
|from fastapi import FastAPI|
|import torch|
| |
|app = FastAPI()|
|model = FraudDetector()|
|model.load_from_checkpoint('best_model.ckpt')|
| |
|@app.post('/predict')|
|async def predict(features: list):|
|tensor = torch.Tensor(features)|
|with torch.no_grad():|
|logits = model.net(tensor)|
|return {'fraud_probability': logits[0][1].item()}| -
性能监控:
mermaid|-------------------------|
|graph LR|
|A[API请求] --> B[负载均衡]|
|B --> C[模型推理]|
|C --> D[日志记录]|
|D --> E[Prometheus监控]|
|E --> F[Grafana可视化]|

四、跨工具协同实践
4.1 智能编码+数据标注流水线
场景:开发一个图像分类系统
-
数据标注阶段:
- 使用Labelme标注10,000张动物图像
- 生成COCO格式标注文件
-
代码生成阶段:
python|------------------------------------------------------|
|# Copilot根据标注文件生成数据加载代码|
|"""|
|加载COCO格式标注数据,包含:|
|- 图像路径列表|
|- 边界框坐标|
|- 类别标签|
|"""|
|import json|
|from PIL import Image|
| |
|class COCODataset(torch.utils.data.Dataset):|
|def __init__(self, annotation_path):|
|with open(annotation_path) as f:|
|self.annotations = json.load(f)|
|self.images = self.annotations['images']|
|self.annotations = self.annotations['annotations']|
| |
|def __getitem__(self, idx):|
|img_info = self.images[idx]|
|img = Image.open(img_info['file_name'])|
|# 后续处理...| -
模型训练阶段:
- 使用标注数据训练ResNet50模型
- Copilot自动生成训练脚本
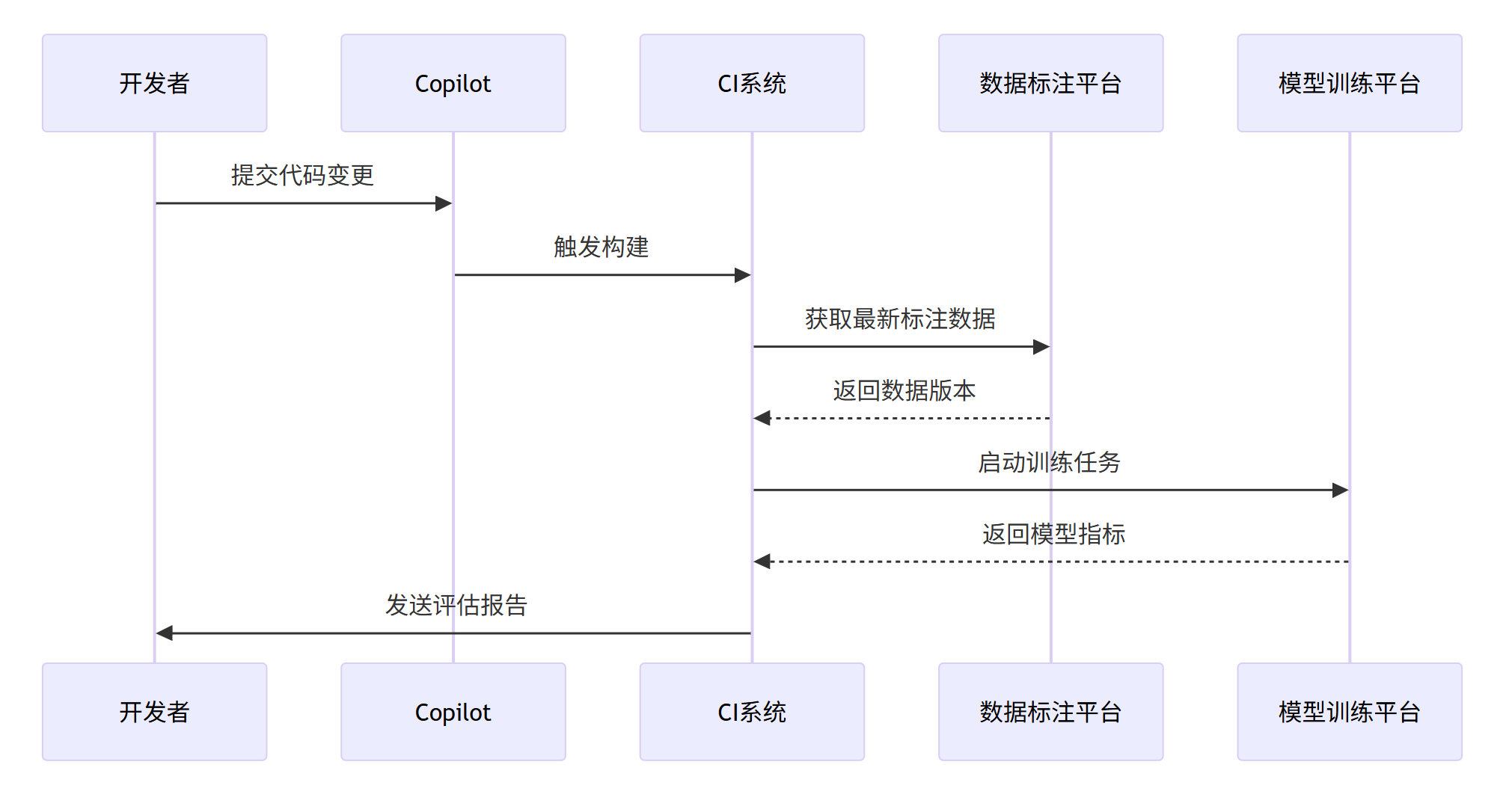
4.2 持续集成方案
mermaid
|---------------------------|
| sequenceDiagram |
| 开发者->>Copilot: 提交代码变更 |
| Copilot->>CI系统: 触发构建 |
| CI系统->>数据标注平台: 获取最新标注数据 |
| 数据标注平台-->>CI系统: 返回数据版本 |
| CI系统->>模型训练平台: 启动训练任务 |
| 模型训练平台-->>CI系统: 返回模型指标 |
| CI系统->>开发者: 发送评估报告 |
五、最佳实践与优化建议
5.1 智能编码工具使用准则
-
提示工程技巧 :
- 结构化注释:使用
### 功能描述、### 输入示例、### 输出要求的格式 - 渐进式提示:先要求生成框架,再逐步细化
- 结构化注释:使用
-
代码审查要点 :
python|-------------------------------------|
|# 审查清单示例|
|def code_review(generated_code):|
|issues = []|
|# 安全检查|
|if 'eval(' in generated_code:|
|issues.append('发现潜在安全漏洞: eval使用')|
|# 性能检查|
|if 'O(n^2)' in generated_code:|
|issues.append('建议优化算法复杂度')|
|return issues|
5.2 数据标注质量控制
-
标注员培训 :
- 案例教学:展示正确/错误标注对比
- 实时反馈:标注过程中显示质量评分
-
自动化质检 :
python|--------------------------------------------|
|# 边界框重叠检测|
|def check_overlap(boxes, threshold=0.3):|
|for i, box1 in enumerate(boxes):|
|for j, box2 in enumerate(boxes):|
|if i != j:|
|iou = calculate_iou(box1, box2)|
|if iou > threshold:|
|return False|
|return True|
5.3 模型训练优化策略
-
超参搜索空间设计:
python|-------------------------------------------------------------------------|
|# Optuna搜索配置|
|import optuna|
| |
|def objective(trial):|
|params = {|
|'lr': trial.suggest_float('lr', 1e-5, 1e-3, log=True),|
|'batch_size': trial.suggest_categorical('batch_size', [32, 64, 128]),|
|'dropout': trial.suggest_float('dropout', 0.1, 0.5)|
|}|
|# 训练逻辑...| -
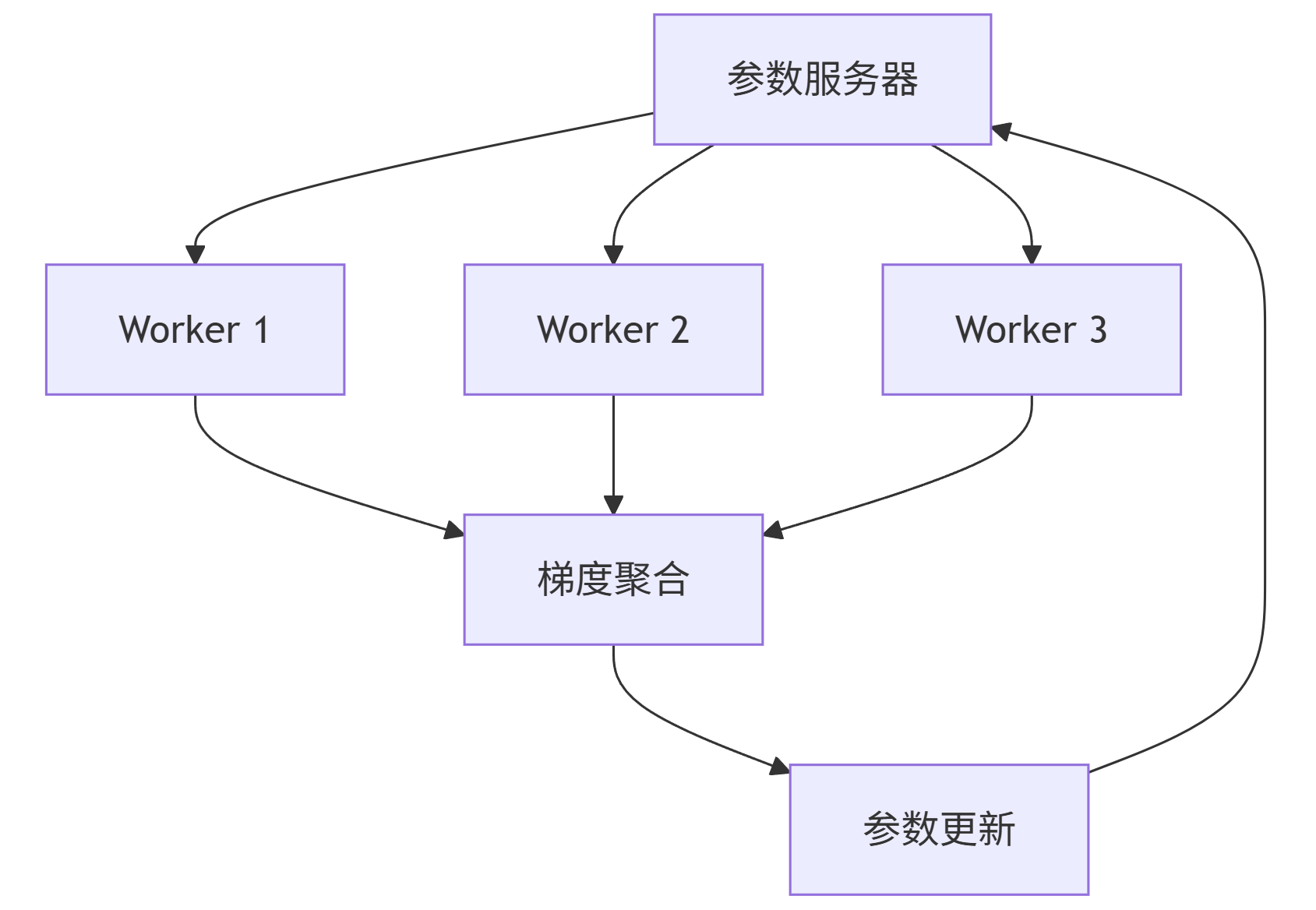
分布式训练加速:
mermaid|----------------------------|
|graph TB|
|A[参数服务器] --> B[Worker 1]|
|A --> C[Worker 2]|
|A --> D[Worker 3]|
|B --> E[梯度聚合]|
|C --> E|
|D --> E|
|E --> F[参数更新]|
|F --> A|
六、未来趋势展望
-
多模态协同:
- 代码生成+数据标注的闭环系统
- 自然语言指令直接控制模型训练
-
自动化MLops:
python|------------------------------------------------|
|# 预期的自动化流程|
|def auto_ml_pipeline(dataset):|
|# 自动数据标注|
|labeled_data = auto_label(dataset)|
|# 自动模型选择|
|model = select_model(labeled_data)|
|# 自动超参优化|
|best_params = auto_tune(model, labeled_data)|
|# 自动部署|
|deploy_service(model, best_params)| -
边缘计算优化:
- 模型量化感知训练
- 动态架构搜索(NAS)
结论
AI工具链的协同应用正在重塑软件开发范式。通过GitHub Copilot等智能编码工具提升开发效率,利用专业标注工具构建高质量数据集,借助模型训练平台实现AI模型快速迭代,开发者可构建起完整的AI开发闭环。未来,随着多模态大模型和自动化MLops技术的发展,AI工具将进一步降低技术门槛,推动创新应用的爆发式增长。
实践建议:
- 建立"代码生成-数据标注-模型训练"的协同工作流
- 实施严格的代码审查和模型评估机制
- 持续跟踪AI工具的版本更新和功能迭代
- 培养团队成员的提示工程(Prompt Engineering)能力