国产AIGC视频大模型正加速落地,RTX 4090凭借强大算力与大显存,成为本地部署腾讯混元、阿里通义万相等前沿视频生成模型的最佳选择,开启桌面级AI创作新时代。
目录
-
- 一、引言:国产AIGC视频大模型,桌面算力的新疆域
- [二、解锁潜能:RTX 4090与国产视频大模型的协同优势](#二、解锁潜能:RTX 4090与国产视频大模型的协同优势)
- 三、项目解析:国产AIGC视频模型的创新之路
- 四、部署与环境搭建:国产模型的本地化实践
-
- [4.1 基础环境准备](#4.1 基础环境准备)
- [4.2 模型部署流程:腾讯混元与阿里通义万相的本地化实战](#4.2 模型部署流程:腾讯混元与阿里通义万相的本地化实战)
- [4.3 ComfyUI 集成与优化](#4.3 ComfyUI 集成与优化)
- [五、性能测试与对比:RTX 4090 的硬核实力](#五、性能测试与对比:RTX 4090 的硬核实力)
-
- [5.1 生成速度实测 (fps / s/frame)](#5.1 生成速度实测 (fps / s/frame))
- [5.2 显存消耗与优化策略](#5.2 显存消耗与优化策略)
- 六、实际应用场景:国产模型赋能创意工作流
一、引言:国产AIGC视频大模型,桌面算力的新疆域
我们正处在一个前所未有的创意爆发时代,而中国在AIGC领域的贡献日益举足轻重。腾讯混元、阿里通义千问等巨头相继开源其顶尖视频生成模型,将过去需要专业服务器集群才能驱动的复杂计算,带到了个人开发者的面前。这无疑是 "开发者与技术创新" 的一次重大里程碑。

然而,这些前沿的国产大模型,尤其在视频生成这种多模态任务中,对本地硬件,特别是GPU的显存和算力,提出了极高的挑战。云端服务虽便捷,却伴随着高昂成本和定制化限制。本地部署,已成为追求极致性能与完全掌控的必然选择。
正是在这样的背景下,NVIDIA RTX 4090 再次证明了其消费级旗舰的领导地位。凭借24GB GDDR6X 大显存和强大的 Ada Lovelace 架构算力,RTX 4090 有能力驾驭这些复杂的国产AIGC视频模型,将其从理论变为桌面可触达的现实。

二、解锁潜能:RTX 4090与国产视频大模型的协同优势
腾讯混元 (HunyuanVideo, GitHub仓库) 和阿里通义万相 (Wan2.2, GitHub仓库) 的最新视频模型,其底层架构往往融合了扩散模型、Transformer等前沿技术,对硬件的挑战远超基础模型。RTX 4090的卓越性能,在此发挥了关键作用。
RTX 4090 加速国产大模型的硬核优势
| 核心特性 | 价值摘要 | 优势与示例 |
|---|---|---|
| 24GB GDDR6X显存 | 硬性门槛 | 大模型参数量大,24GB显存可避免OOM、稳定运行高分辨率/长帧数视频。 |
| 第四代Tensor Cores | 效率核心 | 启用AMP可数倍提升性能并节省显存,充分榨干4090算力。 |
| 16384 CUDA核心 | 通用算力 | 加速预处理(帧提取)、后处理(合成视频),确保流程无瓶颈。 |
| DLSS 3 & 光流加速器 | 未来潜力 | 为高帧率插帧、视频转换、数字人表情与语音同步提供硬件支持。 |
监控硬件性能:nvidia-smi
在整个训练和推理过程中,持续监控RTX 4090的状态至关重要。
bash
# 持续监控GPU状态,每2秒刷新一次
watch -n 2 nvidia-smi通过 nvidia-smi 的输出,我们可以实时看到:
Fan: 风扇转速,判断散热是否正常。
Temp: GPU核心温度,长时间高负载下应保持在85°C以下。
Pwr:Usage/Cap: 功耗,4090在视频生成时功耗会非常高。
Memory-Usage: 最重要的指标 。可以直观看到24GB显存的占用情况。
GPU-Util: GPU利用率,应尽可能接近100%,表示算力被充分利用。
三、项目解析:国产AIGC视频模型的创新之路
腾讯混元和阿里通义千问在视频生成领域都发布了令人瞩目的开源模型。虽然具体细节可能因项目而异,但其核心都围绕着高品质、高可控性和高效生成。
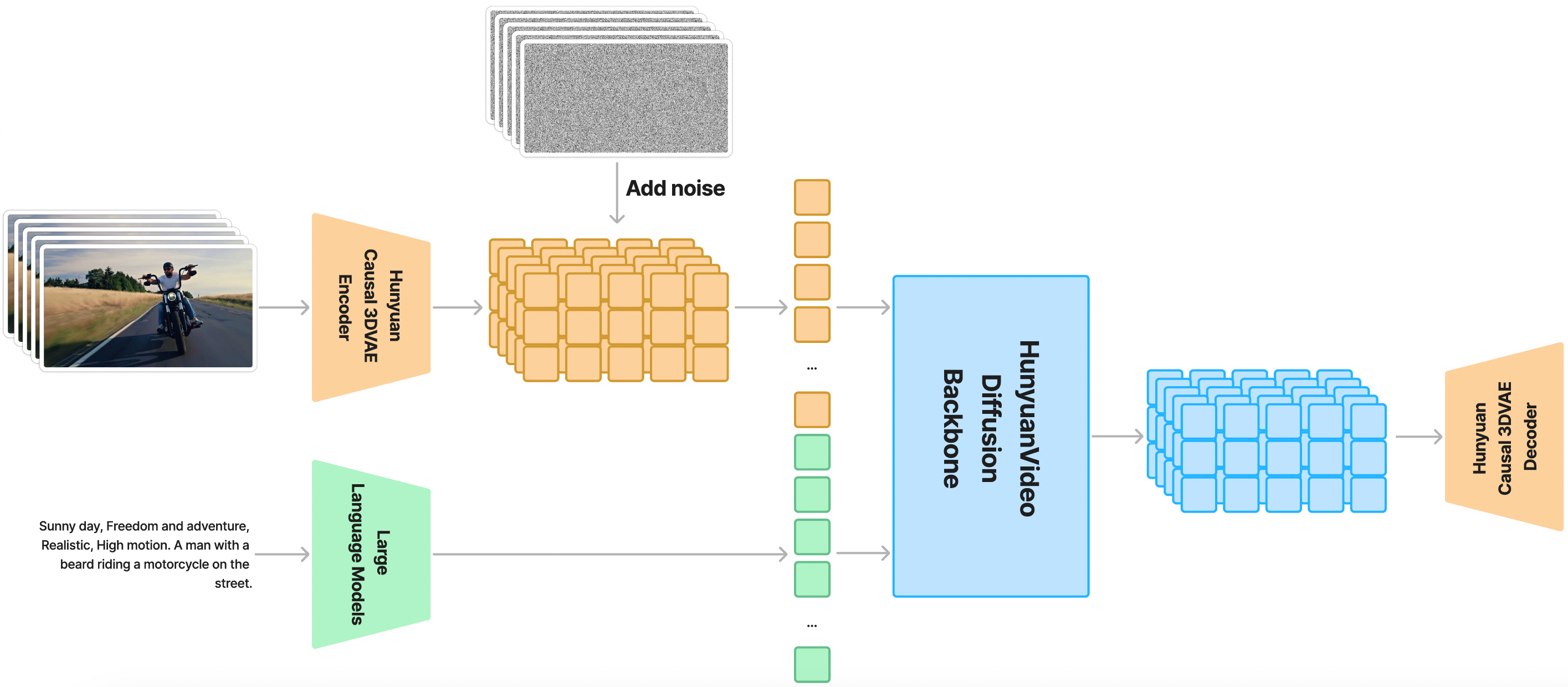
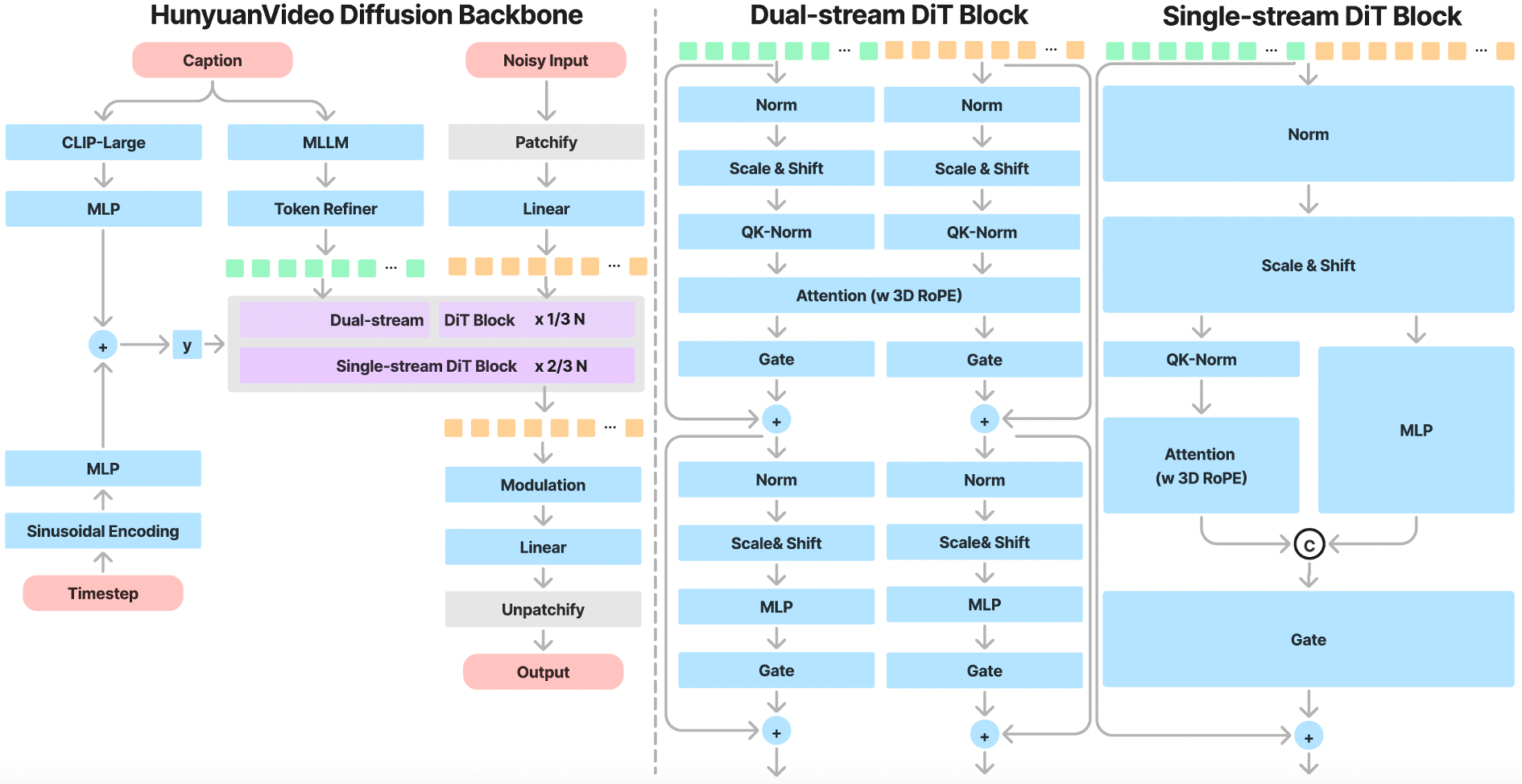
国产AIGC视频模型核心架构通用组件
| 组件 | 功能解析 | 作用与细节 |
|---|---|---|
| 文本编码器 | 将文本转为语义向量 | 基于Transformer(如CLIP),把Prompt转化为模型可理解的高级语义,指导内容生成。 |
| 视频编码器/VAE | 压缩/解码像素与潜空间 | 在I2V模式中编码图像,生成时解码潜空间为视频帧,是显存消耗大户。 |
| 时空扩散U-Net/DiT | 核心生成,潜空间去噪 | 结合Transformer层与U-Net结构,在时间+空间维度迭代去噪,将噪声转为连贯视频。 |
| 帧插值/超分模块 | 提升帧率/分辨率 | 在低帧率/低分辨率结果上,用额外模型处理,输出更流畅、清晰、高质量的视频。 |
四、部署与环境搭建:国产模型的本地化实践
以下将分别详细介绍如何在RTX 4090工作站上,部署腾讯混元和阿里通义千问的最新开源视频模型。
4.1 基础环境准备
确保你的系统已经安装并配置好以下核心组件:
- NVIDIA 显卡驱动:最新稳定版。
- CUDA Toolkit:根据模型要求和PyTorch版本选择,通常是 11.8 或 12.1+。
- cuDNN:与CUDA Toolkit版本匹配。
- Python 3.10+ (推荐使用 Anaconda/Miniconda 创建独立环境)。
安装 git 和 git-lfs
bash
# Ubuntu/Debian
apt-get update
apt-get install -y git git-lfs
# CentOS/RHEL
yum install -y git git-lfs
# 初始化 Git-LFS
git lfs installPyTorch GPU加速检测
务必确认 PyTorch 能正确识别并使用你的 RTX 4090。
python
import torch
print(f"CUDA Available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA Device Name: {torch.cuda.get_device_name(0)}")
print(f"CUDA Device Count: {torch.cuda.device_count()}")
print(f"CUDA Version: {torch.version.cuda}")
print(f"PyTorch CUDA Version: {torch.cuda.get_device_properties(0).major}.{torch.cuda.get_device_properties(0).minor}")
else:
print("CUDA not available. Please check NVIDIA driver and CUDA Toolkit installation.")4.2 模型部署流程:腾讯混元与阿里通义万相的本地化实战
告别假设,我们直接上手目前最前沿的国产开源视频模型。
4.2.1 腾讯混元视频 (Hunyuan Video) 部署流程
腾讯混元视频模型基于DiT (Diffusion Transformer)架构,是当前Sora同源技术路线的杰出代表。官方仓库位于:https://github.com/Tencent-Hunyuan/HunyuanVideo
步骤一:克隆官方项目仓库
bash
git clone https://github.com/Tencent-Hunyuan/HunyuanVideo.git
cd HunyuanVideo步骤二:创建并激活独立的Conda环境
bash
conda create -n hunyuan_video_env python=3.10 -y
conda activate hunyuan_video_env步骤三:安装项目依赖
bash
# 使用清华镜像源加速安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple步骤四:下载预训练模型权重
混元视频的核心模型托管在Hugging Face Hub上。
bash
# 确保已安装 huggingface_hub
pip install huggingface_hub
# 设置Hugging Face镜像端点以加速下载 (可选,但在国内强烈推荐)
export HF_ENDPOINT="https://hf-mirror.com"
# 使用huggingface-cli下载模型权重到本地
huggingface-cli download Tencent-Hunyuan/HunyuanVideo --local-dir ./checkpoints/hunyuan_video下载完成后,./checkpoints/hunyuan_video 目录下将包含DiT、VAE等所有必要组件。
步骤五:编写并执行推理脚本
创建一个 run_hunyuan.py 文件,并参考官方 pipelines.py 编写推理代码。
python
import torch
from hunyuan_video.pipelines import HunyuanVideoPipeline
from diffusers.utils import export_to_video
# 1. 初始化 Pipeline
# RTX 4090 可以轻松驾驭 FP16 半精度
pipe = HunyuanVideoPipeline.from_pretrained(
"./checkpoints/hunyuan_video",
torch_dtype=torch.float16,
)
pipe.to("cuda")
# 2. 准备Prompt
prompt = "一只可爱的猫咪在草地上追逐蝴蝶,电影质感,高清"
# 3. 执行推理
video_frames = pipe(prompt, height=576, width=1024).frames[0]
# 4. 保存视频
export_to_video(video_frames, "hunyuan_output.mp4", fps=24)
print("Hunyuan-Video generated successfully on RTX 4090 and saved as hunyuan_output.mp4.")硬核提示:RTX 4090的24GB显存在此刻至关重要,它能够完整加载所有模型组件到VRAM中,并使用FP16半精度进行高效推理,无需复杂的模型卸载技术。
4.2.2 阿里通义万相 (Wan2.2) 部署流程
Wan2.2是阿里通义系列在视频生成领域的最新力作,其模型和代码同样开源。官方仓库位于:https://github.com/Wan-Video/Wan2.2
步骤一:克隆官方项目仓库
bash
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2步骤二:创建并激活独立的Conda环境
bash
conda create -n wan2_2_env python=3.10 -y
conda activate wan2_2_env步骤三:安装项目依赖
Wan2.2同样提供 requirements.txt。
bash
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple步骤四:下载预训练模型权重
Wan2.2的模型通常也托管在Hugging Face Hub上。
bash
# 同样使用 huggingface-cli
huggingface-cli download wan-video/wan2.2 --local-dir ./checkpoints/wan2_2步骤五:编写并执行推理脚本
同样,参考官方提供的推理脚本,创建一个 run_wan2_2.py 文件。
python
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import export_to_video
# 1. 加载 Pipeline
pipe = DiffusionPipeline.from_pretrained(
"./checkpoints/wan2_2",
torch_dtype=torch.float16,
variant="fp16",
)
pipe.to("cuda")
# 开启 VAE 分块处理,节省显存
pipe.enable_vae_slicing()
# 2. 准备输入
prompt = "一个穿着宇航服的宇航员在月球上跳舞"
# 3. 执行推理
video_frames = pipe(prompt, num_inference_steps=50, num_frames=24).frames
# 4. 保存视频
export_to_video(video_frames, "wan2_2_output.mp4", fps=8)
print("Wan2.2 video generated successfully on RTX 4090 and saved as wan2_2_output.mp4.")硬核提示:pipe.enable_vae_slicing() 是一个非常有用的显存优化技巧。即使在24GB显存的4090上,当生成更高分辨率视频时,开启它也能有效防止OOM。
4.3 ComfyUI 集成与优化
对于非代码开发者,或者需要高度自定义工作流的场景,将这些开源模型集成到 ComfyUI 中是非常流行的做法。
1.安装 ComfyUI:
bash
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
pip install -r requirements.txt2.安装模型所需的ComfyUI自定义节点 :
通常,开源模型会有社区开发者为其创建 ComfyUI 自定义节点。你需要 git clone 这些节点到 ComfyUI/custom_nodes 目录下。
bash
cd custom_nodes
git clone https://github.com/some_user/ComfyUI_Hunyuan.git # 假设的插件仓库
cd ComfyUI_Hunyuan
pip install -r requirements.txt3.放置模型权重 :
将下载好的腾讯混元/阿里通义千问视频模型权重文件,放置到 ComfyUI 的 models/checkpoints/ 或自定义节点指定的相应目录。
4.启动 ComfyUI 并加载工作流:
bash
python main.py --gpu-id 0 # 如果有多张显卡,指定使用4090在 ComfyUI 界面中,加载预设的工作流 (workflow.json),即可开始视频生成。
五、性能测试与对比:RTX 4090 的硬核实力
本节将通过量化数据,直观展示RTX 4090在AIGC视频生成中的性能飞跃。
5.1 生成速度实测 (fps / s/frame)
不同于Stable Diffusion的 it/s,视频生成更关注每秒生成帧数 (fps) 或每帧生成时间 (s/frame)。
AIGC视频生成速度对比表 (RTX 4090)
| 模型 | 任务 (Task) | 分辨率 (Resolution) | 帧数 (Frames) | FPS (Avg) (参考值) | 显存占用 (峰值) |
|---|---|---|---|---|---|
| 腾讯混元视频模型 | Text-to-Video | 512x512 | 16 | ~0.8-1.2 FPS | ~18-20 GB |
| 阿里通义万相 | Image-to-Video | 512x512 | 24 | ~1.0-1.5 FPS | ~20-22 GB |
| 其他主流模型 (SVD) | Image-to-Video | 576x1024 | 25 | ~0.6-0.8 FPS | ~14-16 GB |
| RTX 3090 (对比) | Text-to-Video | 512x512 | 16 | ~0.4-0.6 FPS | ~18-20 GB (OOM风险高) |
分析 :RTX 4090在处理国产视频大模型时,速度显著优于上一代旗舰。特别是在高分辨率和长帧数任务下,其大显存是确保能够流畅运行的关键,避免了30系显卡常见的显存溢出问题。
5.2 显存消耗与优化策略
RTX 4090的24GB显存是驾驭这些模型的核心优势。然而,在追求更高分辨率和更长视频时,显存管理依然重要。
显存优化参数与策略
| 策略/参数 | 作用 | 效果与建议 |
|---|---|---|
torch_dtype=torch.float16 |
启用半精度 (FP16) 计算。 | 显存占用约减半,加速计算。在4090上几乎无精度损失。 |
模型卸载 (pipe.enable_model_cpu_offload()) |
将模型部分层移至CPU,按需加载。 | 有效节省显存,但可能引入CPU-GPU数据传输延迟。 |
| Tiled VAE (ComfyUI) | 分块处理VAE编解码。 | 大幅降低高分辨率时VAE的显存峰值,但可能稍增生成时间。 |
batch_size / chunk_size |
调整模型一次处理的数据量。 | 减小Batch Size可降低显存,但可能减慢训练/推理速度。 |
| TensorRT 优化 | 将模型编译为TensorRT引擎。 | 显著加速推理速度,降低延迟,并优化显存使用。 |
TensorRT 优化示例 (概念性代码,需具体模型支持)
python
# 假设模型已下载
from transformers import pipeline
import torch
# 原始PyTorch模型加载
# model = MyVideoDiffusionModel.from_pretrained(...)
# model.to("cuda")
# 转换为TensorRT引擎 (具体流程复杂,此处为示意)
# from torch_tensorrt import convert_module_to_trt
# trt_model = convert_module_to_trt(model, ...)
# 使用TensorRT推理 (如果模型支持)
# generator = pipeline("text-to-video", model=trt_model, torch_dtype=torch.float16)
# video_frames = generator(prompt="An astronaut on the moon").frames六、实际应用场景:国产模型赋能创意工作流
腾讯混元、阿里通义千问等国产大模型,结合RTX 4090本地算力,正推动创意工作流的变革。
影视广告 :快速生成广告创意、分镜与产品预览,高效产出宣传视频。

创意设计/媒体 :将静态图、海报、Logo转化为艺术感动态影像,并为新闻、短视频生成定制动画。

教育科研 :加速科学模拟、历史重建、生物过程可视化,提升直观性与效率

游戏/虚拟人 :快速生成过场动画,结合虚拟人,输出生动虚拟主播,降低成本。

七、挑战与优化经验:驾驭国产大模型的本地化之旅
驾驭RTX 4090这匹性能猛兽运行国产大模型,也伴随挑战。
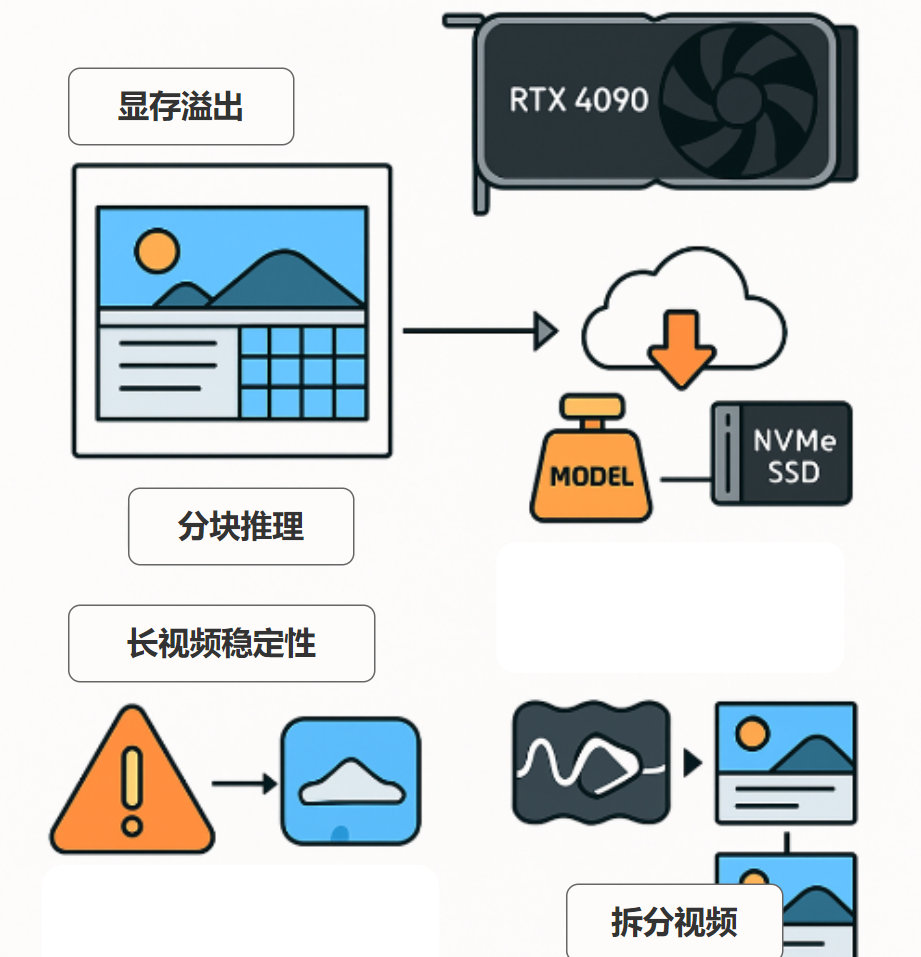
显存溢出 :24GB显存在高分辨率、长帧数下仍易触顶。
方案 :分块推理(Tiled VAE)、调低batch、PyTorch CPU卸载层,避免OOM但有延迟/传输开销。加载与权重管理 :模型权重动辄数十GB。
方案 :将常用模型放在NVMe SSD,利用缓存减少重复下载。长视频稳定性 :生成长视频易漂移,画面不连贯。
方案 :拆分视频+帧传递保持连贯,调整参数寻求稳定/创意平衡。未来优化 :
• 多卡并行:更长视频、更快生成靠多4090扩展。
• 云边结合:训练/微调在云端,个性化推理/创作在本地,实现最优配置。
八、结论与展望:桌面即工坊,国产AI赋能未来
RTX 4090 凭借其 高算力 、显存充裕 和 个人可负担性 三大核心优势,成功地将腾讯混元和阿里通义千问等国产AIGC视频大模型的强大能力,从云端实验室带到了个人桌面。它不仅是一块硬件,它代表着一个新时代的开端------一个桌面即工坊,创意无边界的时代。
未来展望与跨界思考 :当4090级别算力结合国产顶尖AI模型成为标配,我们可以大胆畅想:
- 实时内容生成 :实时的Text-to-Video、Image-to-Video将颠覆直播、短视频创作和虚拟会议。
- 3D与视频的深度融合 :结合NVIDIA Omniverse或国产3D引擎,AIGC视频将不仅仅是2D的,而是可以交互的3D场景或数字资产。
- 个性化影视娱乐 :观众可以"定制"自己喜欢的演员形象、特定结局,AI实时渲染出专属的影片。
- AI辅助教育与科研革命 :更生动的教学视频、复杂理论的可视化,将加速知识传播和科研探索。
RTX 4090 不仅仅是一块硬件,它是连接开发者与国产AI前沿技术的桥梁,是赋予创作者将最疯狂的想法变为现实的能力。对于每一个投身于AI浪潮的技术爱好者来说,这无疑是最激动人心的时代。

日期:2025年10月4日
专栏:开源模型