ICLR 2023|PIXEL:当语言模型不再用词,而是"看"懂文字
📚 论文信息
-
标题 :Language Modelling with Pixels
-
作者:Phillip Rust, Jonas F. Lotz, Emanuele Bugliarello, Elizabeth Salesky, Miryam de Lhoneux, Desmond Elliott
-
单位:University of Copenhagen、Johns Hopkins University、KU Leuven、Pioneer Centre for AI
-
会议:ICLR 2023
-
🔗 GitHub 项目
一、问题背景:词表瓶颈
当前主流语言模型(如 BERT、GPT 系列)普遍依赖 固定词表 。
这种方法在扩展到多语言、多脚本时面临三大核心问题:
-
🧱 覆盖受限:固定词表难以覆盖上千种语言和文字;
-
💻 计算昂贵:大词表导致 embedding 层和 softmax 输出层规模巨大;
-
⚠️ 鲁棒性差:遇到冷门语言、拼写变体、代码混合时表现显著下降。
这就是业界长期存在的 "词表瓶颈" 问题,也是多语言模型难以进一步扩展的核心障碍。
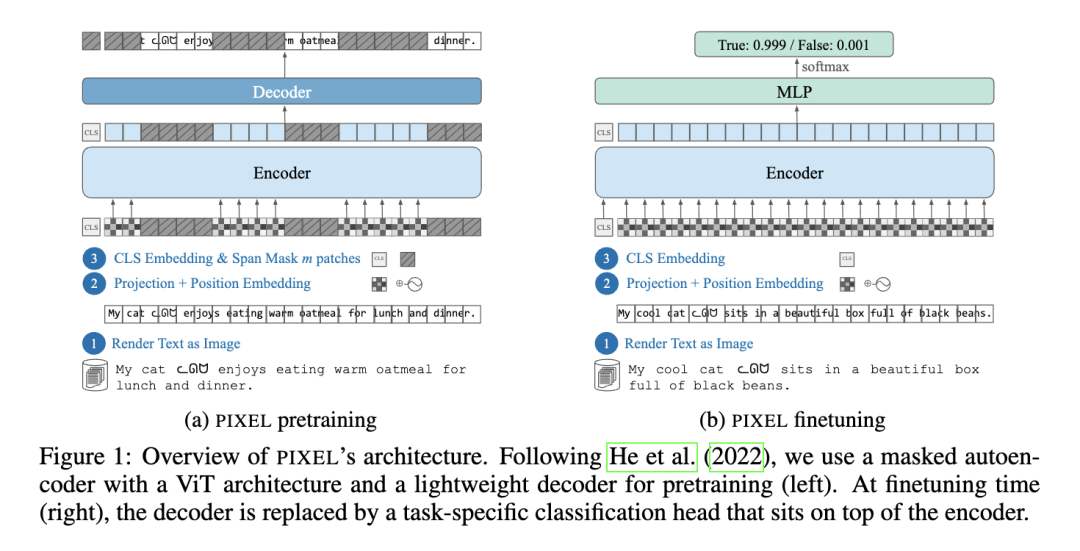
二、创新方法:PIXEL------像素级语言建模
ICLR 2023 的论文提出了 PIXEL ,一种完全不依赖词表的语言模型。
核心思想:把文本变成图像,然后用视觉 Transformer 来理解它。

PIXEL 的技术路径:
-
🖼️ 文本渲染:将文字绘制在固定大小的 RGB 图像上;
-
🧠 ViT 编码:使用 Vision Transformer 处理未遮挡的图像 patch;
-
🧩 像素重建:采用 MAE 方式重建被遮挡的区域完成预训练;
-
🪄 任务迁移:替换解码器为任务头(分类/问答等),直接应用于 NLP 任务。
📌 PIXEL 不再需要 tokenizer,也不存在 OOV(未登录词)问题。
任何能排版的语言,理论上都能直接建模。
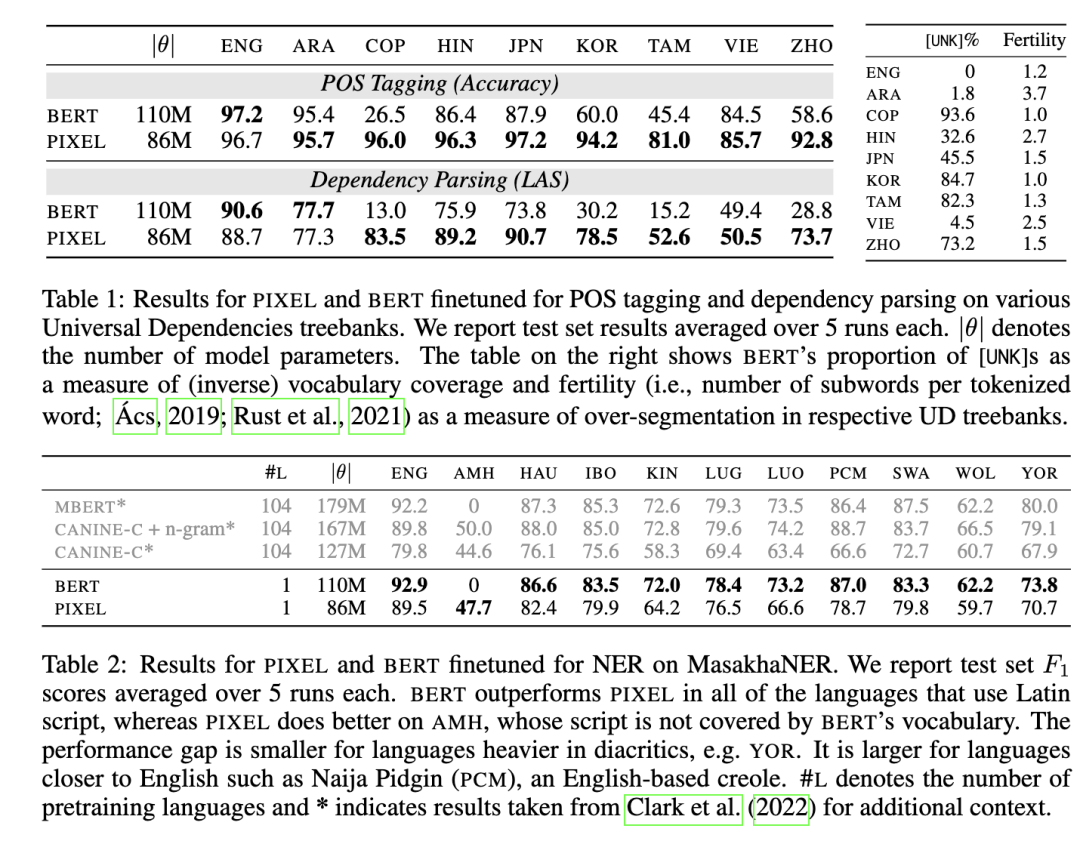
三、实验验证:跨语言 + 抗噪声 + 可迁移
研究团队在 32 种语言、14 种文字脚本 上验证了 PIXEL,并与同规模 BERT 直接对比(预训练语料相同,仅英语)。
1. 多语言与跨脚本能力
-
在阿拉伯语、中文、日文、科普特语等非拉丁文字上,PIXEL明显优于 BERT;
-
Coptic 语言 POS 准确率:BERT 仅 26.5%,PIXEL 高达 96%;
-
对未见过的脚本也能有效迁移,表现稳定。
2. 鲁棒性与混合语言处理
-
面对字符级攻击、相似字符替换等噪声,PIXEL 几乎不受影响;
-
在代码混合(code-switching)场景下,PIXEL 表现优于或接近 mBERT。
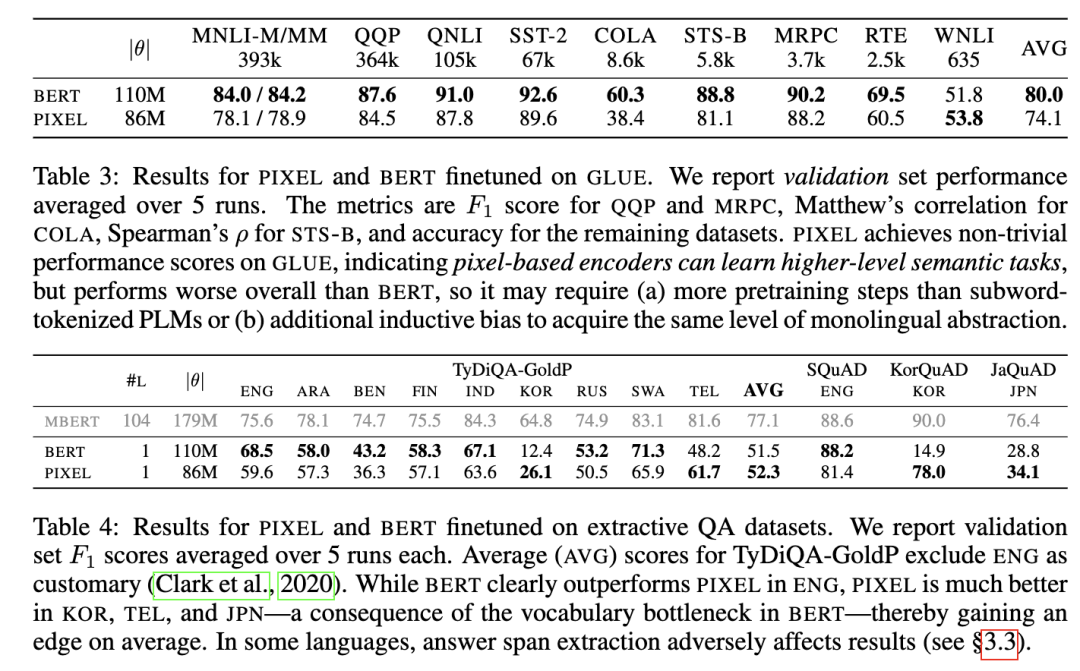
3. 语义任务表现
-
在英文 GLUE 任务上,PIXEL 虽略低于 BERT,但依然取得了良好表现;
-
证明像素建模不仅能理解字符,还能捕捉语义。

四、优势与局限
✅ 优势:
-
不依赖词表,天然支持多语言;
-
跨脚本迁移能力强;
-
抗噪声、抗拼写变体、抗混合语言;
-
兼容多种 NLP 任务(POS、NER、QA、NLI 等)。
⚠️ 局限:
-
对主流拉丁文字(如英文)语义任务略逊 BERT;
-
模型语义建模能力尚需加强;
-
训练推理成本相对较高。
五、研究意义与未来方向
PIXEL 并非对 BERT 的简单替代,而是对 "语言建模基础假设" 的重新思考。
它绕过词表,直接用视觉方式表示语言,为大规模多语言、多脚本建模提供了新路径。
未来研究方向:
-
🌍 多语言预训练,进一步提升跨语义迁移能力;
-
🤝 融合视觉-语言模型(如 CLIP、SAM);
-
🧠 优化训练机制,提升语义理解深度;
-
💬 应用于低资源语言、OCR-NLP 融合场景。
📝 一句话总结:PIXEL 让模型"看懂"文字,为突破词表瓶颈、支持全球语言建模,提供了更通用的解决方案。