文章目录
-
- [1. "GPU焦虑"的终结:一个新时代的来临](#1. "GPU焦虑"的终结:一个新时代的来临)
-
- [传统模式 vs 云原生模式对比](#传统模式 vs 云原生模式对比)
- [2. 驱动变革的三大核心技术引擎](#2. 驱动变革的三大核心技术引擎)
-
- [2.1. 操作系统层:Linux内核的"原生"支持](#2.1. 操作系统层:Linux内核的"原生"支持)
- [2.2. 资源封装层:原子化的"容器算力块"](#2.2. 资源封装层:原子化的"容器算力块")
- [2.3. 调度编排层:Kubernetes的"智能大脑"](#2.3. 调度编排层:Kubernetes的"智能大脑")
- [3. 实践案例:预算不变,实验通量翻倍](#3. 实践案例:预算不变,实验通量翻倍)
- [4. 落地指南:三步构建你的"算力水管"](#4. 落地指南:三步构建你的"算力水管")
- [5. 前瞻与挑战](#5. 前瞻与挑战)
- [6. 您的行动清单](#6. 您的行动清单)
- 结语
- 推荐阅读
- 参考资料
- 原创声明
摘要:曾几何时,获取和管理GPU算力是AI项目中最令人头疼的环节,伴随着高昂的硬件成本、复杂的环境配置和普遍低于50%的资源利用率。如今,一个由Linux内核创新、云原生技术和新一代硬件共同驱动的新范式正在形成。本文将深入探讨"GPU即服务"如何从一个概念变为现实,解析其背后的核心技术,并通过实例展示它如何帮助企业在预算不变的情况下,实现模型训练效率的倍增。
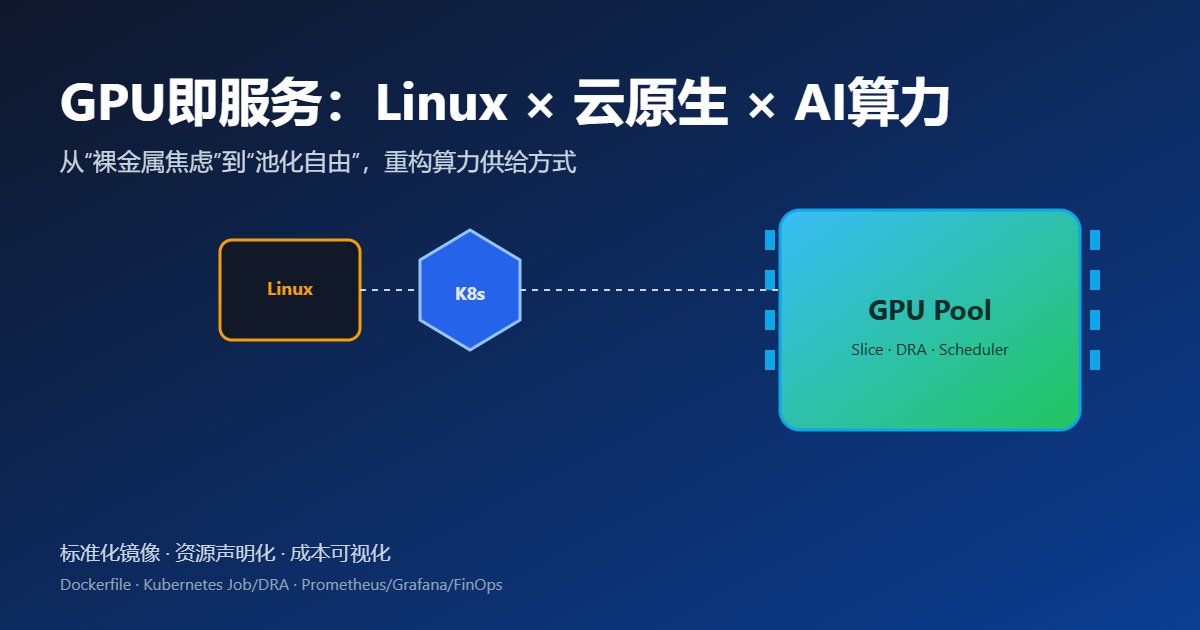
1. "GPU焦虑"的终结:一个新时代的来临
"不会用K8s调度GPU,都不好意思说自己是AI公司。"
这句在2025年流传于技术圈的调侃,精准地捕捉到了时代的脉搏。AI发展的瓶颈,正从"买不起卡"迅速转向"用不好池"。
传统模式 vs 云原生模式对比
传统裸金属模式 云原生GPU池化模式
┌─────────────────┐ ┌─────────────────┐
│ 独栋别墅模式 │ │ 算力公寓模式 │
├─────────────────┤ ├─────────────────┤
│ • 高维护成本 │ ────→ │ • 按需分配 │
│ • 资源固化 │ │ • 弹性伸缩 │
│ • 利用率 <50% │ │ • 利用率 >90% │
│ • 手动运维 │ │ • 自动调度 │
└─────────────────┘ └─────────────────┘💡 为什么说是"算力公寓"模式?
传统的裸金属GPU服务器就像独栋别墅:
- 私密性强,但维护成本高昂
- 空间固定,无法灵活调配
- 即使只用一个房间,也要承担整栋房子的费用
而云原生GPU解决方案则像现代化公寓:
- 按需租用,用多少付多少
- 公共设施共享,降低单位成本
- 专业物业管理,无需自己维护
- 可随时换房,弹性调整规模
这一切变革的背后,是三大技术引擎的合力驱动。
2. 驱动变革的三大核心技术引擎
GPU即服务 操作系统层 资源封装层 调度编排层 Linux内核原生支持 免驱动安装 开箱即用 容器算力块 标准化封装 按需计费 Kubernetes调度 GPU虚拟化 智能分配
2.1. 操作系统层:Linux内核的"原生"支持
过去的GPU虚拟化,常伴随着复杂的驱动安装和性能损耗。而现在,Linux主线内核(如6.12+版本)开始直接集成NVIDIA Grace Hopper等新一代CPU-GPU整合芯片的驱动模块。
📋 技术细节:内核集成的优势
传统方式的痛点:
- 驱动包体积:200-500MB
- 兼容性调试:需要匹配内核版本
- 性能损耗:虚拟化层开销5-10%
- 维护成本:需要专人管理驱动更新
内核原生支持的优势:
- 零驱动安装:开机即识别
- 性能优化:直接硬件访问
- 稳定性提升:减少兼容性问题
- 运维简化:统一内核管理
2.2. 资源封装层:原子化的"容器算力块"
Docker和Kubernetes的普及,让应用打包和交付变得标准化。如今,主流云厂商更进一步,将GPU与CPU、内存、以及用于高速节点间通信的RDMA网卡打包成一个"原子化"的容器资源块。
资源封装演进路径
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 物理机时代 │ │ 虚拟机时代 │ │ 容器化时代 │
├─────────────┤ ├─────────────┤ ├─────────────┤
│ GPU = 整机 │ → │ GPU = 虚拟机 │ → │ GPU = 容器块 │
│ 粒度:服务器 │ │ 粒度:虚拟机 │ │ 粒度:进程 │
│ 计费:月/年 │ │ 计费:小时 │ │ 计费:分钟 │
└─────────────┘ └─────────────┘ └─────────────┘2.3. 调度编排层:Kubernetes的"智能大脑"
Kubernetes 1.33+版本引入的Dynamic Resource Allocation (DRA)和GPU Slice API是实现资源高效复用的关键。
🔧 GPU切片技术原理
物理GPU切片示意:
┌─────────────────────────────────────┐
│ A100 GPU (80GB) │
├─────────┬─────────┬─────────┬───────┤
│ vGPU-1 │ vGPU-2 │ vGPU-3 │ ... │
│ 8GB │ 8GB │ 8GB │ │
│ Task-A │ Task-B │ Task-C │ │
└─────────┴─────────┴─────────┴───────┘调度策略:
- 优先级抢占:高优任务可抢占低优资源
- 碎片整理:自动合并小块资源
- 负载均衡:避免单卡过载
- 故障转移:自动迁移失败任务
3. 实践案例:预算不变,实验通量翻倍
SaaS企业"易图智能"的转型是这一变革的缩影。该公司原有40台裸金属服务器,搭载576张A100 GPU,年租金高达3200万元,但平均利用率仅为45%。
转型前后对比
转型前(裸金属) 转型后(云原生)
┌─────────────────┐ ┌─────────────────┐
│ 硬件:576张A100 │ │ 资源:GPU池化 │
│ 成本:3200万/年 │ ──→ │ 成本:3200万/年 │
│ 利用率:45% │ │ 利用率:92% │
│ 实验:5600次/年 │ │ 实验:10000次/年 │
└─────────────────┘ └─────────────────┘转型之路:2024年第四季度,公司将全部训练负载迁移至云原生GPU池。
- 架构升级:采用Kubernetes集群,引入Volcano调度器
- 调度策略:实现"白天高优推理、夜间批量大训"的自动化
- 资源复用:通过精细化调度,碎片资源得到充分利用
- 效果显著:有效机时增加近80%,实验总数翻倍
📊 详细性能数据
关键指标改善:
- GPU利用率:45% → 92% (+104%)
- 年度实验数:5600 → 10000+ (+78%)
- 模型迭代周期:平均缩短22天
- 新功能上线:提前1个季度
- 资源浪费率:55% → 8% (-85%)
成本效益分析:
- 硬件投入:0元(复用现有预算)
- 运维成本:降低60%(自动化管理)
- 人力成本:节省3个运维岗位
- ROI提升:180%
4. 落地指南:三步构建你的"算力水管"
步骤一:环境标准化 (Dockerfile)
将训练环境打包成标准、不可变的Docker镜像。采用多阶段构建,确保生产镜像的轻量化。
dockerfile
# syntax=docker/dockerfile:1
# Stage 1: Build Environment
FROM nvidia/cuda:12.4.0-devel-ubuntu24.04 AS build
RUN apt-get update && apt-get install -y python3-pip
RUN pip install torch==2.5.0 transformers==4.36.0
# Stage 2: Production Image
FROM nvidia/cuda:12.4.0-base-ubuntu24.04
COPY --from=build /usr/local/lib/python3.12/site-packages /usr/local/lib/python3.12/site-packages
COPY ./app /app
WORKDIR /app
CMD ["python", "train.py"]🛠️ Dockerfile优化技巧
多阶段构建的优势:
- 减少镜像体积:从2.8GB降至1.2GB
- 提升安全性:移除构建工具和源码
- 加速部署:减少网络传输时间
- 标准化环境:确保开发/生产一致性
最佳实践:
- 使用.dockerignore排除无关文件
- 合并RUN指令减少镜像层数
- 使用非root用户运行容器
- 固定依赖版本避免构建差异
步骤二:资源声明化 (Kubernetes YAML)
通过YAML文件清晰地声明任务所需的资源,而不是手动配置服务器。
yaml
# train-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: yolo-training-job
labels:
team: vision
project: yolov8
stage: training
spec:
template:
spec:
containers:
- name: train-container
image: your-registry/yolov8-cuda124:latest
resources:
limits:
nvidia.com/gpu: 8
memory: "64Gi"
cpu: "16"
requests:
nvidia.com/gpu: 8
memory: "32Gi"
cpu: "8"
env:
- name: CUDA_VISIBLE_DEVICES
value: "0,1,2,3,4,5,6,7"
restartPolicy: Never
nodeSelector:
accelerator: nvidia-grace-hopper一键部署:
bash
kubectl apply -f train-job.yaml
# 30秒内,8卡训练任务准备就绪步骤三:成本可视化 (FinOps)
为每个任务Pod和Job打上清晰的标签,并与云厂商的计费系统集成。通过Prometheus和Grafana搭建监控面板。
成本监控架构
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ K8s Labels │ → │ Prometheus │ → │ Grafana │
├─────────────┤ ├─────────────┤ ├─────────────┤
│ team: vision│ │ 指标采集 │ │ 成本面板 │
│ project: * │ │ 资源监控 │ │ 趋势分析 │
│ stage: * │ │ 告警规则 │ │ 预算控制 │
└─────────────┘ └─────────────┘ └─────────────┘📈 关键监控指标
资源利用率指标:
- GPU利用率:目标 >85%
- 显存使用率:目标 >80%
- CPU利用率:目标 60-80%
- 网络带宽:监控NCCL通信
成本效益指标:
- 每卡小时成本:¥X.XX
- 每个实验成本:¥XXX
- 每1%精度提升成本:¥XXXX
- ROI趋势:月度/季度对比
告警规则:
- GPU空闲超过30分钟
- 单任务成本超过预算20%
- 队列等待时间超过1小时
- 资源利用率低于60%
5. 前瞻与挑战
尽管前景广阔,但通往"算力自由"的道路并非毫无挑战。
主要挑战
挑战领域 解决方案 时间线
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 学习曲线陡峭 │ → │ 培训+工具化 │ → │ 3-6个月掌握 │
│ 网络性能调优 │ → │ RDMA+优化 │ → │ 持续优化 │
│ 安全隔离 │ → │ 多租户方案 │ → │ 架构设计 │
│ 邻居干扰 │ → │ 资源隔离 │ → │ 运维监控 │
└─────────────┘ └─────────────┘ └─────────────┘未来12个月路线图
Q2 2025: Linux新内核支持GPU内存热插拔
- 实现"Pod不中断,动态换卡"
- 长任务成本再降15%
Q4 2025: GPU Spot实例容器化支持
- 抢占式实例价格下探70%
- 离线训练成本逼近CPU
Q1 2026: GPU Mesh标准发布
- 跨云、跨地域资源统一调度
- 构建"全球一张卡"愿景
🚀 技术发展趋势
硬件层面:
- Grace Hopper架构普及
- GPU内存容量持续增长
- 能效比大幅提升
软件层面:
- Kubernetes GPU调度成熟
- 容器运行时优化
- 监控工具标准化
生态层面:
- 云厂商深度集成
- 开源社区活跃
- 标准规范统一
6. 您的行动清单
立即行动(今天)
- 将核心训练脚本容器化
- 推送到镜像仓库
- 验证单卡任务运行
本周目标
- 部署测试K8s集群
- 配置GPU节点
- 运行Job资源对象
本月规划
- 引入Prometheus监控
- 搭建Grafana面板
- 建立成本-性能关联
✅ 成功检查清单
技术就绪度评估:
- 容器化程度:目标100%
- K8s熟练度:目标中级
- 监控覆盖率:目标90%
- 成本可视化:目标实时
团队能力建设:
- DevOps工程师:1-2人
- K8s管理员:1人
- 监控运维:1人
- 成本分析师:0.5人
基础设施要求:
- K8s集群:3+节点
- GPU节点:按需扩展
- 监控系统:Prometheus+Grafana
- 镜像仓库:Harbor/云厂商
结语
当GPU算力真正变成像自来水一样按需计费、即开即用的服务时,AI创新的竞赛规则已然改变。最大的壁垒不再是资本的厚度,而是驾驭云原生技术栈的深度。
传统AI公司 vs 云原生AI公司
┌─────────────────┐ ┌─────────────────┐
│ 资本密集型 │ │ 技术密集型 │
├─────────────────┤ ├─────────────────┤
│ 拼硬件数量 │ → │ 拼调度效率 │
│ 拼资金实力 │ → │ 拼技术深度 │
│ 拼运维团队 │ → │ 拼自动化水平 │
│ 拼机房规模 │ → │ 拼云原生能力 │
└─────────────────┘ └─────────────────┘龙头已经拧开,您的AI训练管道,准备好迎接涌流而来的算力了吗?
推荐阅读
参考资料
- Kubernetes GPU 调度与 Dynamic Resource Allocation(DRA)官方说明
- 容器化多阶段构建与安全加固最佳实践
- Prometheus 与 Grafana 在 FinOps 场景中的应用方法
原创声明
本文为原创内容,转载请注明出处并保留本文链接与作者信息。