作为程序员,我们不想当"偷窥狂",我们只是数据的"搬运工"和"炼金术士"。
大家好,我是你们的老朋友,一个每天都在和Bug谈恋爱的后端程序员。今天,我们来聊一个听起来很神秘,但实际上无处不在的话题------埋点。
想象一下,你开了一家超市(你的App/网站),每天人来人往。但你却不知道:
- 顾客最喜欢在哪个货架前停留?
- 哪个商品被拿起来又放回去的次数最多?
- 收银台为什么总是排长队?
如果你不知道,那你就是个"瞎子"老板。而埋点,就是你在店里安装的"智能监控系统"和"顾客行为分析仪"。下面,就让我带你从入门到精通,彻底搞懂埋点这回事。
第一章:埋点是什么?为什么我们需要它?("监控摄像头"的基本修养)
1. 什么是埋点?
说人话就是:在App或网页的各个关键位置"埋"下一段代码,当用户触发某个行为(比如点击、浏览、支付)时,这个"地雷"就会爆炸(被触发),然后悄咪咪地收集信息并发送给我们的服务器。
它记录的不是"谁"干了什么(我们很注重用户隐私的),而是"有多少人"、"在什么地方"、"以什么方式"干了什么事。
2. 为什么需要埋点?(不当"瞎子"老板)
- 产品决策:数据告诉你,用户根本不喜欢你花一个月做的"炫酷"新功能,而是对那个随手做的小按钮情有独钟。别再自嗨了,听数据的!
- 用户体验优化:发现某个页面流失率特别高?赶紧去查查,是不是加载太慢,还是流程太反人类。
- 运营分析:这次促销活动到底带来了多少新用户?哪个渠道的用户质量最高?是时候用数据"打脸"凭感觉做决策的运营了。
- 监控告警:突然发现"支付成功"的埋点数据断崖式下跌?别等用户投诉了,赶紧查服务是不是挂了!
第二章:前端+Nginx:埋点界的"轻骑兵突袭"
有时候,我们不想动用后端"重型武器",只想快速、简单地收集一些数据。这时候,前端 + Nginx 的组合就是一把利器。
核心思想: 前端通过发起一个HTTP请求(比如一个1x1像素的GIF图片请求,俗称信标)来上报数据,Nginx负责接收并记录这个请求。
上才艺!
1. 前端代码(JavaScript):
javascript
// 一个简单的埋点上报函数
function track(event, data = {}) {
// 组装埋点数据
const trackingData = {
event: event, // 事件名,如 'page_view', 'button_click'
timestamp: Date.now(),
url: window.location.href,
userAgent: navigator.userAgent,
...data // 自定义数据
};
// 创建一个Image对象,利用src发起GET请求
const beacon = new Image();
// 将数据编码在查询参数中
beacon.src = `https://tracking.yourdomain.com/beacon.gif?data=${encodeURIComponent(JSON.stringify(trackingData))}`;
}
// 使用示例:当用户点击"立即购买"按钮时
document.getElementById('buy-button').addEventListener('click', () => {
track('purchase_click', { productId: '12345', price: 99.99 });
});为什么用GIF图? 因为它体积小,兼容性极好,不会阻塞页面,而且天生就是为了被加载而存在的。

2. Nginx配置(nginx.conf):
Nginx在这里扮演了一个"无情的日志记录机器"。
nginx
server {
listen 80;
server_name tracking.yourdomain.com;
# 处理 beacon.gif 请求的Location
location /beacon.gif {
# 这是一个空GIF图片,1x1像素,透明
empty_gif;
# 关键一步:将请求参数记录到访问日志
access_log /var/log/nginx/tracking.log tracking_log;
# 返回204 No Content,或者返回上面empty_gif生成的1px图片
return 204;
}
}
# 定义一个自定义的日志格式,专门用来记录埋点数据
log_format tracking_log '[$time_local] $arg_data';流程拆解:
- 用户点击按钮。
- 前端JS执行
track函数,创建一个Image,其src指向我们的Nginx服务器,并将数据挂在URL参数上。 - Nginx收到
/beacon.gif?data=...的请求。 - Nginx执行
empty_gif模块(需内置)返回一个1像素GIF,或者直接返回204。 - 最关键的一步 :Nginx将我们自定义的参数(
$arg_data)按照tracking_log的格式,写入到/var/log/nginx/tracking.log文件中。 - 后续,我们就可以用脚本(如Logstash、Fluentd)或者大数据工具(如Spark)来消费这个日志文件,进行数据清洗和入库了。
优点: 简单、快速、高并发、对后端无压力。 缺点: 数据有丢失风险(比如Nginx磁盘写满了)、数据实时性较差。
第三章:统一网关:埋点界的"中央情报局"
当你的公司业务庞大,服务众多时,让每个业务方自己处理埋点太混乱了。这时,就需要一个统一网关来集中管理所有流量,埋点只是它的"顺手之举"。
核心思想: 所有流量(包括业务请求和埋点请求)都必须经过网关。网关就像一个"安检口",可以检查每一个请求,并把它相关的信息记录下来。
我们以 Spring Cloud Gateway 为例:
java
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//处理文件上传:如果是文件上传则不记录日志
MediaType mediaType =exchange.getRequest().getHeaders().getContentType();
boolean flag = RequestHelper.isUploadFile(mediaType);
//忽略路径处理:获得请求路径然后与logProperties的路进行匹配,匹配上则不记录日志
String path = exchange.getRequest().getURI().getPath();
List<String> ignoreTestUrl = logProperties.getIgnoreUrl();
for (String testUrl : ignoreTestUrl) {
if (antPathMatcher.match(testUrl, path)){
flag = true;
break;
}
}
//无需记录日志:直接放过请求
if (flag){
return chain.filter(exchange);
}
//需记录日志:对ServerHttpRequest进行二次封装,解决requestBody只能读取一次的问题
CacheServerHttpRequestDecorator decorator = new CacheServerHttpRequestDecorator(exchange.getRequest());
//把当前的请求体进行改变,用于传递新放入的body
//需记录日志:对ServerHttpResponse进行二次封装
CacheServerHttpResponseDecorator serverHttpResponseDecorator =
new CacheServerHttpResponseDecorator(
exchange,
logSource,
snowflakeIdWorker.nextId(),
applicationName+":"+port);
return chain.filter(exchange.mutate().request(decorator).response(serverHttpResponseDecorator).build());
}
@Override
public int getOrder() {
return Ordered.HIGHEST_PRECEDENCE;
}
}流程拆解:
- 客户端(Web/App)发起一个业务请求,如
GET /api/products/123。 - 请求首先到达统一网关(Spring Cloud Gateway)。
- 网关的
TrackingGlobalFilter开始工作。 - 过滤器检查请求路径,发现是
/api/开头,判定为需要埋点的请求。 - 过滤器异步地(为了性能!)将请求的元数据(路径、IP、UA等)打包成一个消息,发送到Kafka消息队列。
- 过滤器立刻放行请求,让它继续去后端的业务服务。
- 后端业务服务处理完请求,返回响应,用户无感知。
- 另一个专门的数据消费服务从Kafka里读取埋点消息,进行存储和处理。
大体流程如下:
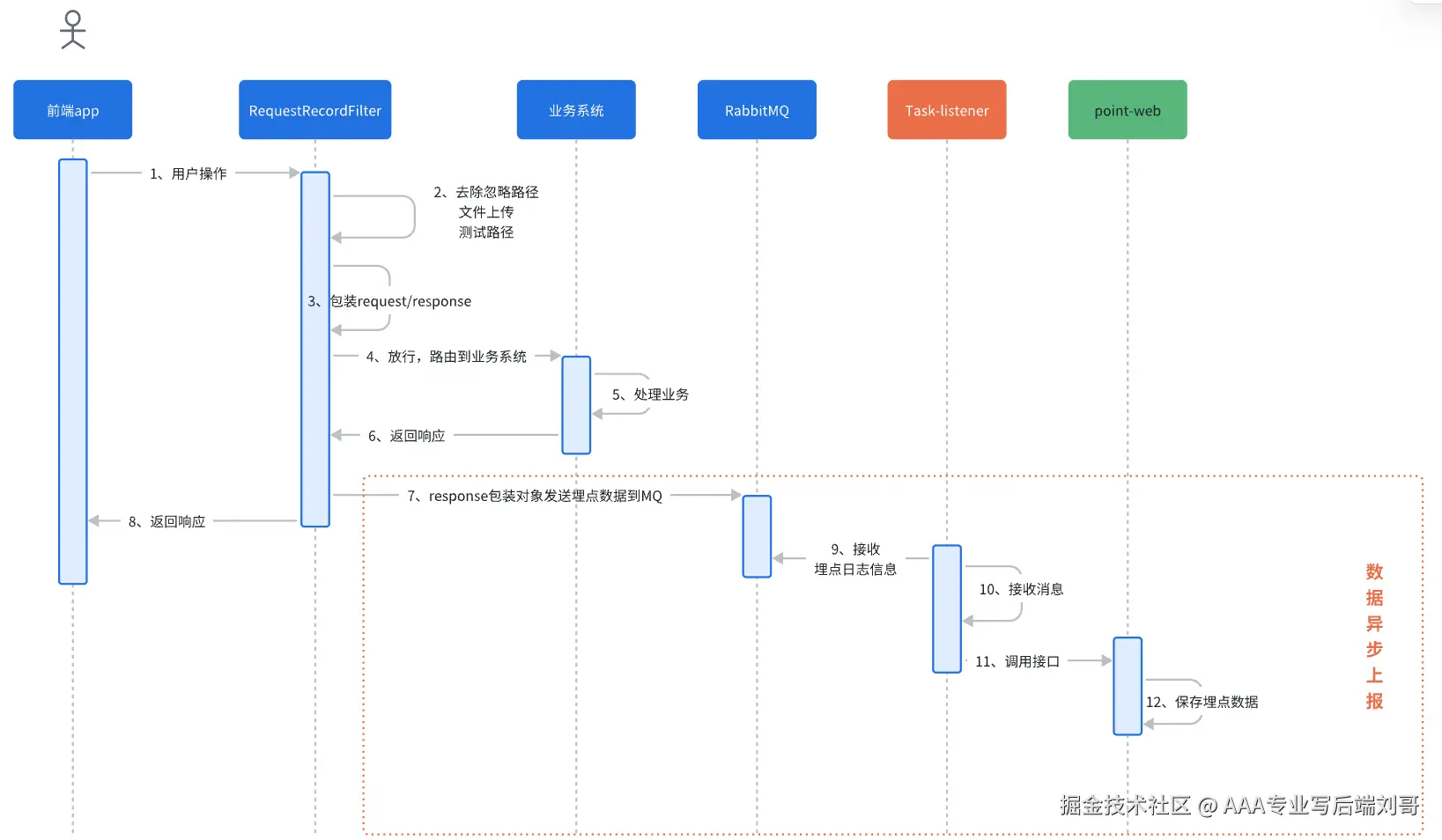
优点: 统一管理,数据全面(可以拿到完整的API请求上下文),与业务解耦,数据通过消息队列异步处理,性能好,可靠性高。 缺点: 架构复杂,需要引入网关、消息队列等组件。
第四章:数据存储:把"原油"炼成"黄金"
数据收集上来了,但这些"原油"不能直接喝,得存起来炼化。这里介绍两种主流的存储方案。
1. 大数据平台"全家桶"(HDFS + Hive / Spark)
这适合海量数据(PB级别)的离线分析。
-
流程:
- Nginx日志或者网关发到Kafka的数据,被Flume 或Logstash 这样的采集工具定时/实时地拉到HDFS(分布式文件系统)上。
- 使用 Hive 或 Spark SQL 对HDFS上的原始数据进行ETL(抽取、转换、加载)清洗,转换成结构化的Parquet/ORC文件。
- 数据分析师通过写Hive SQL或者Spark任务,对清洗后的数据进行分析,生成报表。
-
本质:可以理解为你把所有的监控录像带(日志文件)都存进了一个巨大的、永不损坏的仓库(HDFS),然后专门请了一个分析团队(Hive/Spark)来一帧一帧地看录像做分析。
2. 云原生时序数据库(ClickHouse)
这适合需要快速查询和实时分析的场景。
-
流程:
- 埋点数据直接通过SDK或者从Kafka,写入到 ClickHouse 数据库。
- ClickHouse以其恐怖的列式存储和向量化执行引擎,让你能够在上亿条数据中,秒级完成复杂的聚合查询。
-
为什么是ClickHouse?
- 快! 专门为OLAP(在线分析处理)而生。
- 压缩比高,节省存储成本。
- SQL友好,学习成本低。
sql
-- 例如,在ClickHouse中查昨天哪个页面的PV最高
SELECT
path,
count(*) as pv
FROM tracking_events
WHERE event_date = yesterday()
GROUP BY path
ORDER BY pv DESC
LIMIT 10;存储选择小结:
- 小公司/初创项目:Nginx日志 + 脚本入库到MySQL/PostgreSQL,或者直接用现成的第三方服务(如友盟、Google Analytics)。
- 中型公司,追求实时性:Kafka + Flink/Spark Streaming + ClickHouse。
- 大型公司,海量数据:Kafka + Flink + HDFS/Hive(离线) + ClickHouse/Druid(实时) 的Lambda架构。
结语
好了,朋友们,我们的"埋点掘金之旅"到这里就告一段落了。
我们从一个"瞎子"老板,到学会了:
- 为什么要埋点(为了不当瞎子)。
- 如何用轻量级的前端+Nginx方案快速上手。
- 如何用高大上的统一网关进行规模化、体系化的数据收集。
- 如何把海量数据存储下来并进行分析,最终把"原油"变成驱动业务增长的"黄金"。
希望这篇博客能让你对埋点的全链路有一个清晰而有趣的认识。现在,是时候去给你的项目装上"监控摄像头"了!记住,我们不是"偷窥",我们是在用数据创造更美好的产品。