WMNav 是一种将VLM融入世界模型(World Model) 的目标导航框架,支持零样本。
设计一种预测环境状态的记忆策略,采用在线好奇心价值图来量化存储,目标在世界模型预测的各种场景中出现的可能性。
论文地址:WMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
代码地址:https://github.com/B0B8K1ng/WMNavigation
示例效果:

论文复现参考:复现 WMNav 具身导航
一、WMNav 简介
WMNav 是一种面向**零样本目标物体导航(Zero-shot Object Goal Navigation)的创新框架,**
****核心思路是:****将视觉 - 语言模型(Vision-Language Model, VLM)深度融入世界模型(World Model),
无需任务特定训练、预构建地图或环境先验知识,即可在完全未知的室内环境中,高效定位并接近指定类别的目标物体(如床、沙发等)。
- 框架通过 "世界模型(预测与记忆环境状态)" 与 "导航策略(子任务分解 + 两阶段动作选择)" 的闭环,
- 实现 "感知 - 预测 - 规划 - 执行" 的导航流程,突破传统方法对 "训练数据、预建地图" 的依赖,适配 "未知环境 + 未知目标" 的泛化场景。
二、核心特点分析
1. VLM 与世界模型的创新性融合
将 VLM 作为世界模型的核心组件,利用 VLM 预训练的零样本视觉 - 语言理解能力(如场景语义认知、物体空间关系常识),模拟 "执行动作后的环境状态"(如 "左转后是否能看到卧室门")。
- 替代传统方法 "依赖实际环境交互试错" 的模式,减少无效探索与碰撞风险;
- 让智能体无需实际移动,即可预判路径优劣,提升规划效率。
2. 在线好奇心价值图(CVM)的动态记忆机制
设计好奇心价值图(Curiosity Value Map, CVM),通过 "预测得分投影 + 历史记忆融合",量化存储环境中各位置的 "目标存在概率":
- 投影与融合规则:将 VLM 输出的 "各方向目标得分" 投影到俯视图,再与历史 CVM 按 "取最小值" 规则融合,确保 "已探索无目标区域(得分 0)不被重复探索",同时修正 VLM 幻觉导致的错误预测;
- 动态维护优势:无需预建地图,仅通过实时观测在线更新环境记忆,适配未知环境的动态变化。
3. 子任务分解:缓解 VLM 幻觉,提升推理可靠性
将 "长程目标(如'找床')" 拆解为 "短程可验证的子任务(如'沿走廊走→找卧室门')",结合 "子任务完成度 + 视觉观测" 的反馈约束 VLM 推理:
- 避免 VLM 直接进行 "长程无约束推理" 时的幻觉问题(如凭空认为 "左侧有卧室");
- 为导航提供密集反馈,让决策更具连续性(如 "完成'到走廊'子任务后,再规划'找卧室门'")。
4. 全流程 "无依赖" 设计,适配零样本场景
- 无需任务特定训练:所有 VLM(PredictVLM/ PlanVLM/ ReasonVLM)直接使用预训练模型,无需针对 "目标导航" 微调;
- 无需预构建地图:通过 CVM 在线生成 "探索价值地图",替代传统 "复杂地图构建" 流程;
- 无需环境先验知识:仅依赖 "目标文本 + 第一视角图像" 即可推理,完美适配 "完全未知环境 + 未知目标" 的 ZSON 场景。
三、模型架构
下图展示了WMNav 框架的核心工作流程,围绕 "世界模型(预测与记忆环境状态)" 和 "导航策略(规划与动作选择)" 形成闭环,实现零样本目标物体导航
3.1. 输入模块(Input)
- 输入内容:全景 RGB-D 图像(由多个固定角度的第一视角图像拼接而成)、智能体的位姿(Pose,包含位置与方向信息)。
- 作用:为后续 "环境感知与状态预测" 提供原始视觉与空间信息。
3.2. 世界模型(World Model):环境状态的 "预测 - 记忆" 核心
世界模型负责量化预测目标存在概率 并存储历史探索信息,是 WMNav 区别于传统方法的关键创新,包含 4 个子模块:
(1)PredictVLM:视觉 - 语言模型做状态预测
- 输入:全景 RGB-D 图像。
- 操作:对全景图中每个方向(如 30°、90°、330° 等),预测 "目标存在的好奇心价值"(得分,范围 0-10,得分越高表示该方向越可能存在目标)。
- 输出:带分数的全景图(Scored panoramic image),示例中 330° 方向得 10 分(因直接观测到目标 "床"),其他方向得分较低。
(2)Curiosity Value Map(好奇心价值图):量化存储探索价值
- 操作:将 PredictVLM 输出的 "方向得分" 投影(Project)到俯视图,形成 "目标存在概率的空间分布图"。结合上一时刻状态s_{t-1},更新为当前状态s_t
- (采用 "取最小值" 规则融合历史与当前预测,避免重复探索)。
- 作用:用 "地图化" 的方式记忆环境中各位置的 "探索优先级",指导后续方向选择。
(3)Memory:存储与反投影状态
- 操作:存储当前好奇心价值图的状态s_t,并能将其 投影回(Project Back)到第一视角,辅助筛选 "高价值探索方向"(示例中因 330° 得分最高,故选择该方向)。
(4)Cost:存储子任务与目标标志
- 存储内容:子任务(Subtask,如 "Go to the BED")、目标标志(GoalFlag,如 True 表示检测到目标)。
- 作用:为 "导航策略" 中的 VLM(PlanVLM、ReasonVLM)提供提示信息(记为c_t),缓解 VLM 的 "幻觉问题"(无依据的错误推理)。
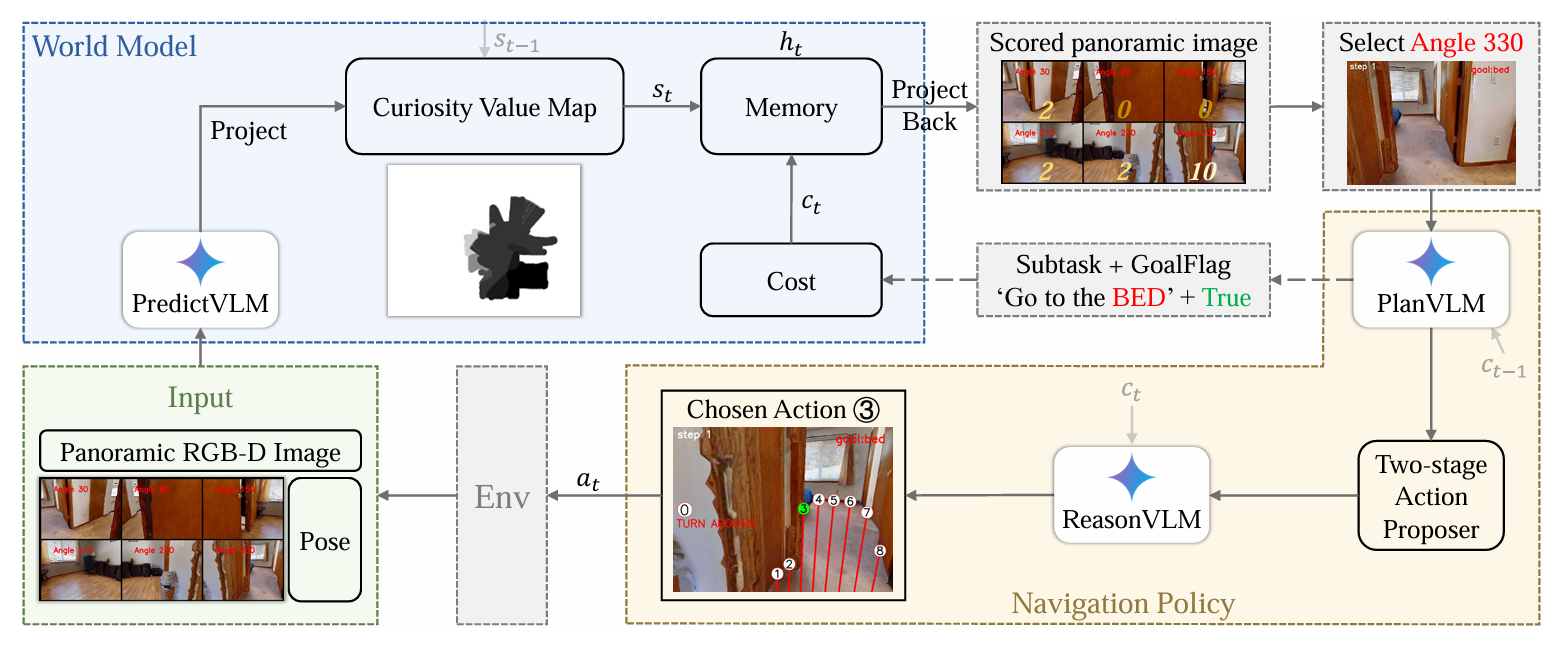
3.3. 导航策略(Navigation Policy):动作决策的 "规划 - 选择" 核心
导航策略基于世界模型的输出,完成 "子任务规划" 与 "动作选择",包含 3 个子模块:
(1)PlanVLM:子任务分解与规划
- 输入:"高价值方向的图像"(示例中为 330° 方向的图像)、Cost 模块提供的 "Subtask + GoalFlag"(如 "Go to the BED" + True)。
- 操作:根据视觉观测与历史任务,生成新的子任务或确认目标,同时传递历史提示c_{t-1}。
- 作用:将长程目标(如 "找床")拆解为短程可验证的子任务(如 "向 330° 方向移动"),避免 VLM 长程推理的幻觉。
(2)Two-stage Action Proposer(两阶段动作提议器)
- 操作:根据 PlanVLM 的子任务,生成 "候选动作序列"(分 "探索阶段" 和 "目标逼近阶段",平衡探索广度与定位精度)。
(3)ReasonVLM:最优动作选择
- 输入:Cost 模块的提示c_t、候选动作序列。
- 操作:结合视觉 - 语言理解,从候选动作中选择最优动作a_t(示例中选择 "动作③")。
3.4. 环境(Env):动作执行与反馈
- 操作:执行 ReasonVLM 选择的动作a_t,并反馈新的全景 RGB-D 图像 和位姿,进入下一个时间步的循环。
整体逻辑:闭环与创新
WMNav 通过 "世界模型(预测 + 记忆环境状态) ↔ 导航策略(规划 + 选择动作) ↔ 环境(执行动作并反馈观测)" 的闭环,实现:
- 无需任务特定训练(依赖 VLM 的零样本能力);
- 无需预构建地图(通过好奇心价值图在线生成探索记忆);
- 缓解 VLM "幻觉问题"(通过子任务分解与 Cost 提示提供密集反馈);
- 平衡 "探索效率" 与 "定位精度"(两阶段动作提议器)。
四、世界模型与VLM的融合框架
4.1. VLM 作为世界模型的 "预测引擎"(PredictVLM)
VLM 因训练了海量第一人称人类视角图像,已习得足够 "室内布局、物体空间关系" 的常识知识,
具备模拟 "人类动作选择后环境结果" 的能力。基于此,WMNav 将 VLM 作为世界模型的预测器(PredictVLM):
- 输入:智能体拍摄的全景 RGB-D 图像(通过多角度旋转拍摄后拼接,覆盖 360° 视野);
- 输出:对每个观测方向(如 30°、90° 等),定量预测 "目标存在的可能性得分"(范围 0 - 10,0 表示 "无路径 / 无目标",10 表示 "直接发现目标")。
- 价值:将 VLM 的 "视觉 - 语言理解能力"(如场景语义认知)转化为导航可用的 "方向价值信号",替代传统 "实际环境试错" 的预测方式,减少无效探索。
4.2. 世界模型的 "记忆组件":好奇价值地图(CVM)与 Cost 模块
为存储 VLM 的预测状态、支撑后续导航决策,论文设计两类记忆模块:
(1)好奇价值地图(Curiosity Value Map, CVM)
- 功能:量化存储 "环境中各位置目标存在的可能性",实现在线动态记忆更新。
- 技术流程:① 投影 :利用 RGB-D 图像的深度信息 + 智能体位姿,将 PredictVLM 输出的 "各方向得分" 投影到俯视图(鸟瞰图) ,生成 "当前时刻导航价值图";② 融合 :将 "当前时刻导航价值图"与 上一时刻的 CVM 按 "取最小值 " 规则融合,得到当前 CVM。
- 规则逻辑:确保 "已探索且无目标的区域(得分 0)" 不被重复标记为高得分,同时用新观测修正 VLM 可能的 "幻觉性高预测"(如错误认为某区域有目标)。
(2)Cost 模块
- 功能:存储子任务 (如 "沿走廊走")和目标标志(布尔值,指示是否发现目标),为后续 VLM 推理提供反馈。
- 价值:将 "世界模型的状态记忆" 转化为 VLM 可理解的文本提示,无需微调 VLM,即可引导其生成更合理的规划 / 动作选择,缓解 VLM "幻觉问题"(无依据的错误推理)。
4.3. 世界模型与导航策略的协同:子任务分解 + 两阶段动作提议
为让世界模型的 "预测 - 记忆" 有效驱动导航,论文设计两类协同策略:
(1)子任务分解
- 逻辑:利用世界模型的 CVM 筛选 "高得分方向的图像",结合 Cost 模块的 "子任务 + 目标标志",将 "找床" 等长程目标拆解为 "沿走廊走""找卧室门" 等短程可验证子任务。
- 约束规则:
- 若图像中直接发现目标 → 子任务设为 "接近目标";
- 若未发现目标但上一子任务未完成 → 继续执行该子任务;
- 若未发现目标但上一子任务已完成 → 生成新子任务。
- 价值:让 VLM 的推理更聚焦、反馈更密集,避免 "长程无约束推理" 时的幻觉错误。
(2)两阶段动作提议者
- 逻辑:根据 "目标是否被检测到"(由世界模型的 Cost 模块判断),分阶段生成动作:
- 探索阶段(目标未检测):基于世界模型的 CVM 提供 "高探索价值区域",广泛采样动作,确保未知环境中目标不被遗漏;
- 目标逼近阶段(目标已检测) :在目标附近密集采样动作,移除移动距离限制,提升定位精度。
- 价值:平衡 "探索广度" 与 "定位精度",让世界模型的 "区域优先级预测" 与 VLM 的 "动作语义筛选" 协同工作。
五、好奇心价值图的构建与动态维护
这张图展示了 WMNav 框架中 "好奇心价值图(Curiosity Value Map, CVM)" 的生成与更新流程 ,分为三个核心步骤,
从 "视觉预测" 到 "空间映射" 再到 "记忆融合",实现对环境目标存在概率的量化与动态维护:
步骤 1:(a) 预测好奇心价值(Predict Curiosity Value)
- 输入:全景图像(由 6 个固定角度,即 30°、90°、150°、210°、270°、330° 的第一视角图像拼接而成),以及目标任务(如 "导航到床(BED)")。
- 核心操作 :利用视觉 - 语言模型(VLM),按照规则对每个角度的 "目标存在可能性" 打分:
- 规则 1:无可行路径且无目标 → 得 0 分(如 90° 方向是墙,无探索价值);
- 规则 2:直接发现目标(如 330° 方向清晰看到床) → 得 10 分;
- 规则 3:中间情况(如 30° 方向有走廊和门,可能通向有床的区域) → 得 0-10 分(示例中 30° 得 2 分)。
- 输出 :每个角度的得分及解释(如 JSON 格式的
{"30": {"Score": 2, "Explanation": "A hallway and door may allow movement..."}, ...}),将 "视觉理解" 转化为可量化的目标存在概率。
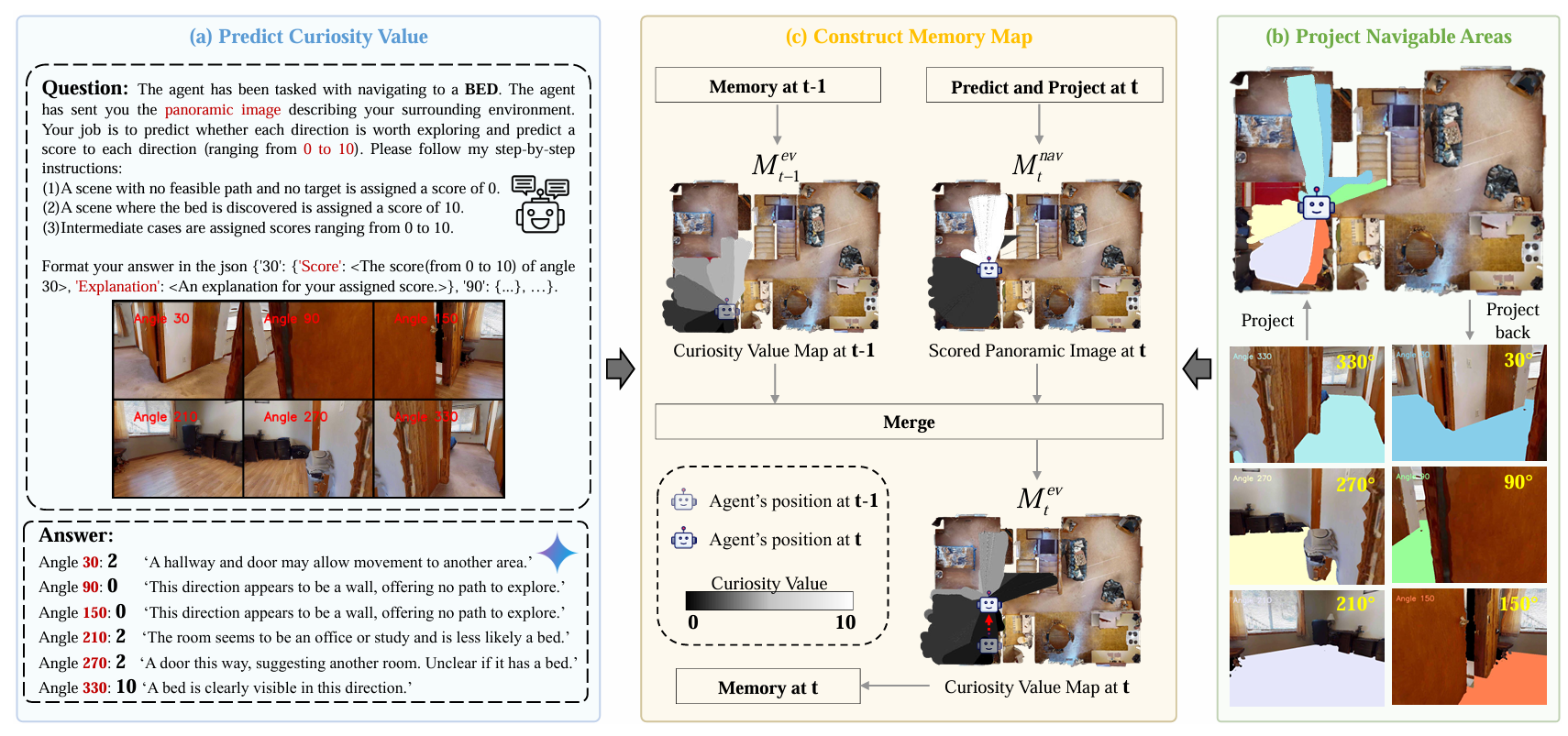
步骤 2:(b) 投影可导航区域(Project Navigable Areas)
- 核心目的:将 "第一视角的局部视觉信息" 映射到 "全局俯视图",建立空间对应关系。
- 操作 :
- 从 "第一视角图像" 向 "俯视图" 投影:将每个角度(如 30°、330° 等)的 "可导航区域"(如走廊、房间)投影到俯视图,生成该视角下的 "可导航区域地图";
- 从 "俯视图" 向 "第一视角" 投影:也可将俯视图的全局信息反投影回第一视角,辅助 agent 理解 "当前视角在全局中的位置"。
- 作用 :打破 "第一视角视野有限" 的限制,让 agent 从全局视角理解环境布局,为后续 "记忆地图构建" 提供空间基础。
步骤 3:(c) 构建记忆地图(Construct Memory Map)
- 输入 :
- t-1时刻的好奇心价值图,即 "历史记忆");
- t时刻的 "预测 + 投影" 结果,即步骤 (a)(b) 得到的 "当前得分与可导航区域的俯视图")。
- 核心操作:融合(Merge) :
- 采用 "取最小值" 的融合规则。
- 逻辑:确保 "已探索且无目标的区域(得分 0)" 不会被重新标记为高得分,避免重复探索;同时,"新观测到的低潜力区域" 会修正历史的 "高潜力预测",减少 VLM 幻觉导致的错误记忆。
- 输出 :t时刻的好奇心价值图,作为在线维护的环境记忆,指导后续导航的 "探索优先级"。
好奇心价值图(Curiosity Value Map, CVM)是 WMNav 框架中世界模型的核心记忆组件,
用于量化存储环境中目标存在的概率 并实现动态更新,其构建与维护逻辑如下:
5.1、构建过程:从 "视觉预测" 到 "全局记忆映射"
-
方向得分预测(PredictVLM 驱动) 智能体通过多角度旋转(如 30°、90° 等)拍摄 RGB-D 图像并拼接为全景图 ,输入给
PredictVLM。PredictVLM利用视觉 - 语言模型(VLM)的零样本理解能力,对每个方向定量预测目标存在的概率,输出 0-10 的分数(0 表示 "无可行路径 / 无目标",10 表示 "直接发现目标")。 -
投影到俯视图(空间映射) 利用 RGB-D 图像的深度信息 和智能体的位姿(位置与朝向) ,将
PredictVLM输出的 "各方向得分" 投影到俯视地图,生成当前时刻的 "导航价值图"------ 把 "第一视角的方向得分" 转化为 "全局空间的目标概率分布"。 -
融合历史与当前记忆 将当前导航价值图与上一时刻的好奇心价值图按**"取最小值" 规则**融合,得到当前时刻的好奇心价值图。
- 规则逻辑:确保 "已探索且无目标的区域(得分 0)" 不会被重复标记为高得分,避免冗余探索;同时,用新观测修正 VLM 可能的 "幻觉性高预测"(如错误认为某区域有目标),保证记忆的可靠性。
5.2、动态维护:在线迭代与反馈驱动
-
实时在线更新 每一个时间步t,都会重复 "
PredictVLM预测→投影到俯视图→与历史 CVM 融合" 的流程,持续更新好奇心价值图。随着智能体在环境中移动、获取新的全景图像,CVM 实时反映环境中各位置 "目标存在概率" 的变化,适配未知环境的动态性。 -
记忆与决策反馈
- 存储与反投影:更新后的 CVM 被存入世界模型的
Memory模块,同时会反投影回全景图像 ,筛选出 "得分最高的方向" 传递给导航策略模块(如PlanVLM、ReasonVLM),为 "子任务规划" 和 "动作选择" 提供依据。 - 提示优化(Cost 模块协同):世界模型的
Cost模块(存储 "上一步子任务" 和 "目标标志")结合 CVM 的信息,优化PlanVLM和ReasonVLM的提示内容,无需微调 VLM 即可提升推理合理性,进一步缓解 VLM "幻觉问题"。
- 存储与反投影:更新后的 CVM 被存入世界模型的
六、基于PlanVLM实现子任务分解
这张图展示了 WMNav 框架中 "子任务分解(Subtask Decomposition)" 模块里**,PlanVLM 生成子任务的**提示(Prompt)设计与输出逻辑 **,
核心是通过 "分阶段规划 + 人类常识规则",将长程导航目标拆解为短程可验证的子任务
6.1. 核心组件与任务背景
- 任务目标 :智能体需导航到指定物体(例中为
bed)。 - 输入信息 :
- 观测图像(
<observed image>):当前位置拍摄的第一视角图像(例中显示 "走廊场景,无直接可见的床")。 - 解释文本(
{Explanation}):说明当前场景的探索价值(例中为 *"This appears to be a hallway, which is a very likely place to find a bedroom."*,即 "这是走廊,很可能找到卧室")。 - 历史子任务(
Last Subtask):上一步规划的子任务(例中为 *"Go to the hallway"*,即 "去走廊")。
- 观测图像(

6.2. Plan Prompt 的 "人类常识规则"(引导 VLM 推理)
为让 VLM 生成更可靠的子任务,Prompt 中嵌入 3 条人类导航的常识逻辑,约束推理方向:
- 目标直接可见:若图像中出现目标(如直接看到床),则直接选 "接近目标" 为下一步。
- 子任务未完成:若目标不可见,但上一个子任务(如 "去走廊")未完成,则继续执行该子任务。
- 子任务已完成:若目标不可见,且上一个子任务已完成,则生成新子任务。
6.3. 示例中的推理与输出
结合配置信息(goal=bed,Last Subtask=Go to the hallway,Explanation=走廊可能有卧室),PlanVLM 的推理逻辑的:
- 目标可见性(Flag) :图像中无床 →
Flag: False。 - 子任务延续性:上一个子任务 "去走廊" 未完成(当前刚到走廊,需继续深入)→ 触发 "规则 2"。
- 输出结果 :
Subtask: "Go down the hallway"(沿走廊继续走),Flag: False。
通过 "子任务分解 + 常识规则",将 "找床" 这类长程目标拆解为 "去走廊→沿走廊走→找卧室门→找床" 等短程子任务,每一步都可通过 "图像观测 + 子任务完成度" 验证,从而:
- 缓解 VLM 的 "幻觉问题"(避免无依据的长程错误规划);
- 为导航提供密集的反馈与修正机会,提升长程导航的可靠性。
七、两阶段动作策略
这张图展示了 WMNav 框架中 "两阶段动作提议者(Two-stage Action Proposer)"的工作流程,
核心是通过 "探索阶段" 和 "目标逼近阶段" 的动态切换,平衡 "探索效率" 与 "定位精度",其各模块与逻辑如下:
7.1.阶段切换逻辑
以 "目标是否被检测到(Goal detected)" 为触发条件:
- 探索阶段(Exploration Stage) :目标未被检测到时,智能体需广泛探索高潜力区域,寻找目标;
- 目标逼近阶段(Goal-approaching Stage) :目标被检测到时,智能体需密集采样动作、精确定位目标,并判断是否停止。

7.2.左侧:探索阶段(Exploration Stage)
1. Action Proposer(动作提议器)
- 输入 :
Navigable Area(可导航区域):蓝色标注的 "当前视角下可安全行走的区域";Exploration State Map(探索状态图):黑色背景 + 绿色区域表示 "已探索过的区域",用于避免重复探索。
- 操作流程 :
Sample(采样):从Navigable Area中,按固定角度间隔采样初始动作序列(图中底部左侧带编号的射线,代表不同方向 / 距离的动作);Filter(过滤):结合Exploration State Map,过滤 "已探索区域对应的动作",得到候选动作(Candidate Actions)(图中底部右侧仅保留动作①、②,排除已探索的无效动作)。
2. Action VLM(动作视觉语言模型)
- 输入 :
Image Prompt(图像提示):当前视角的第一人称图像;Text Prompt(文本提示):任务描述(示例中为 *"TASK: Go to the hallway <Subtask>. 最终目标:导航到最近的沙发并尽可能靠近,从图像提示中选动作"*)。
- 输出 :VLM 基于 "视觉 - 语言理解" 选择最优动作(示例中选
Action ①),随后执行(Execute)该动作。
7.3.右侧:目标逼近阶段(Goal-approaching Stage)
1. Goal Proposer(目标提议器)
- 输入 :
Navigable Area(目标周围的可导航区域,更聚焦目标附近空间)。 - 操作流程 :
Sample(密集采样):在目标附近的可导航区域内,密集生成候选动作(图中带编号的射线更密集,覆盖目标周围更细致的位置),为 "精确定位" 提供充足选择。
2. Goal VLM(目标视觉语言模型)
- 输入 :
Image Prompt(图像提示):目标附近的第一人称图像;Text Prompt(文本提示):任务描述(示例中为 *"导航到沙发,先确认图像中是否有沙发;若有,选最佳位置;若无,返回失败信息"*)。
- 输出 :VLM 基于 "目标验证 + 位置选择",输出最优位置(示例中选
Position ⑤),随后智能体沿该动作逼近目标,直到满足 "与目标距离<阈值" 的停止条件。
7.4.设计核心与价值
- 两阶段分工:探索阶段 "广撒网" 找目标,避免遗漏;逼近阶段 "精准捞" 定位目标,提升效率。
- VLM 的作用 :全程无需 "任务特定训练",仅通过 "图像 + 文本提示" 驱动动作选择,利用 VLM 的零样本视觉理解 + 常识推理能力,适配 "未知环境 + 未知目标" 的 ZSON(零样本目标物体导航)场景。
八、模型效果
HM3D数据集,对比零样本目标导航结果:
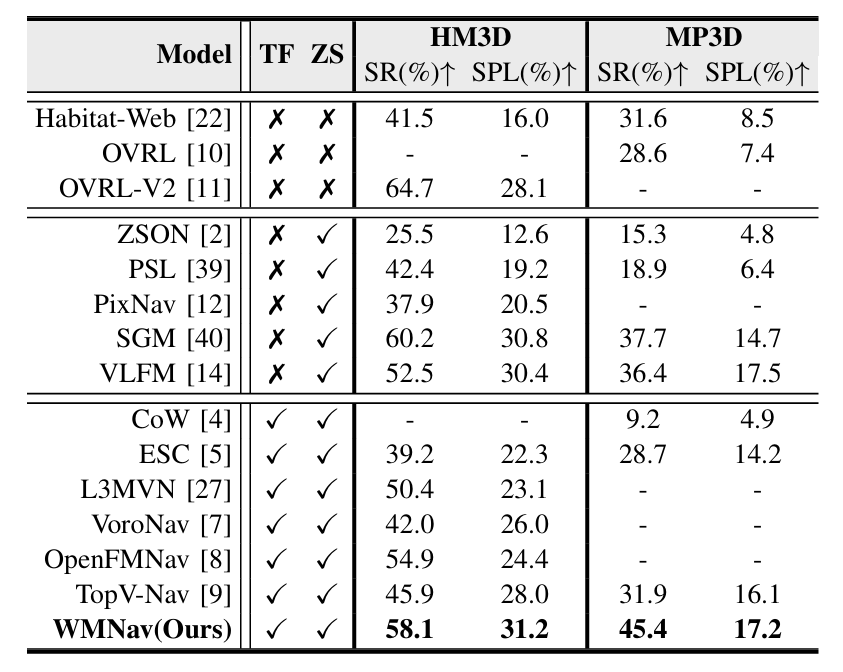
- TF 指的是训练免费
- ZS 指的是零样本
下面是示例效果:

分享完成~