目录
前言
在本专栏内的文章中,多次提及到了ocr,而ocr作为一个用于辅助大模型的扩展工具,其重要性是很明显的,例如kimi,qwen乃至市面上常见的大语言模型网站,当你传入图片,等一些内容都需要通过ocr提取文字来进行相关信息的搜索和上下文联系,以及用户输入内容的联系。
那么本篇章将会介绍如何在编译软件中调用ocr工具,来提升你的大模型的输出能力
如有不清楚还对ocr处于一个不明不白的,可以参考该链接进行快速学习:
AI智能体(Agent)大模型入门【8】--关于ocr文字识别图片识别-CSDN博客
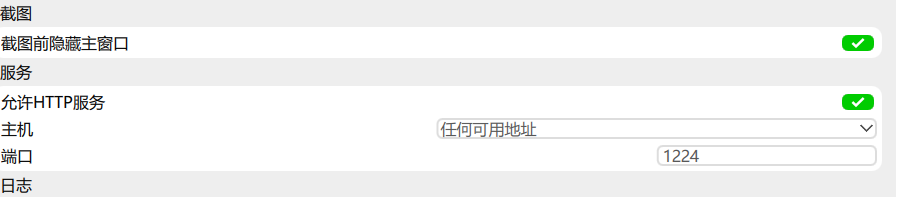
设置
确保你的ocr处于图片状态
代码编写
utils.py工具函数
需要在该模块内编写相关代码
python
def ocr_file_to_text_llms(file_path)->str:
"""
使⽤光学字符识别(OCR)将⽂件转换为⽂本。
该函数通过调⽤LLM(⼀种语⾔处理模型)服务来实现⽂件中的⽂本提取。
它⾸先创建⼀个⽂件对象,然后使⽤该服务提取⽂件内容,并以字符串形式返回。
:param file_path: ⽂件路径,表示需要进⾏OCR处理的⽂件位置。
:return:提取文件内容,以字符串形式返回
"""
# 初始化LLM服务
client = qwen_llm()
# 创建文件对象,指定文件路径和处理目的
file_object = client.files.create(file=Path(file_path),purpose="file-extract")
#获取文件内容
file_content = client.files.content(file_id=file_object.id).json()
#返回提取内容
return file_content["content"]
def get_b64_image_from_path(image_path):
with open(image_path, "rb") as image_file: #
return base64.b64encode(image_file.read()).decode('utf-8')
def is_image(file_path):
try:
with Image.open(file_path) as image:
image.verify()
return True
except:
return False代码很简单,也有解释,唯一就是对于第二个函数就是对带有文字的图片进行打开读取到文字转换为utf-8的格式编码操作。
至于第三个则是判断图片文件,代码很简单和理解。
重点代码ocr.py
这块文件主要就是如何对ocr进行操作的了。
python
# 导入必要的库
import base64
import os
import json
import time
import zipfile
# 导入第三方库requests用于发送HTTP请求
import requests
# 从项目的配置模块中导入RagConfig类,用于获取OCR相关的配置
# 从 utils 模块中导入 get_b64_image_from_path 函数
from .utils import get_b64_image_from_path
# 初始化基础URL和下载目录,以及请求头
base_url = os.getenv("OCR_BASE_URL") # OCR服务的基础URL
download_dir = os.getenv("OCR_DOWNLOAD_DIR") # OCR下载文件的保存目录
headers = {"Content-Type": "application/json"} # 请求头,指定发送的数据类型为JSON
def _upload_file(file_path):
"""
上传文件到服务器。
此函数将文件上传到服务器的 /api/doc/upload 接口。它首先尝试使用文件的原始名称进行上传。
如果上传失败并返回代码101,表示服务器未接收到文件,这可能是由于某些Linux系统上文件名包含非ASCII字符导致的问题。
在这种情况下,函数将尝试使用仅包含ASCII字符的临时文件名重新上传文件。
参数:
file_path (str): 要上传的文件路径。
返回值:
str: 文件成功上传后服务器返回的文件ID。
"""
# 构建文件上传的URL
url = "{}/api/doc/upload".format(base_url)
# 配置上传选项
options_json = json.dumps(
{
"doc.extractionMode": "mixed",
}
)
# 尝试使用文件的原始名称进行上传
with open(file_path, "rb") as file:
response = requests.post(url, files={"file": file}, data={"json": options_json})
response.raise_for_status()
res_data = json.loads(response.text)
# 如果上传失败且返回代码为101,则使用临时文件名重新上传
if res_data["code"] == 101:
# 如果代码为101,表示服务器未接收到上传的文件。
# 在某些Linux系统上,如果文件名包含非ASCII字符,可能会出现此错误。
# 在这种情况下,可以使用仅包含ASCII字符的临时文件名构造上传请求。
file_name = os.path.basename(file_path)
file_prefix, file_suffix = os.path.splitext(file_name)
temp_name = "temp" + file_suffix
# 使用临时文件名重新上传文件
with open(file_path, "rb") as file:
response = requests.post(
url,
# 使用 temp_name 构造上传请求
files={"file": (temp_name, file)},
data={"json": options_json},
)
response.raise_for_status()
res_data = json.loads(response.text)
# 从响应数据中提取文件ID
file_id = res_data["data"]
return file_id
def _process_file(file_id):
"""
轮询任务状态直到OCR任务完成。
参数:
file_id (str): 要处理的文件的唯一标识符。
异常:
AssertionError: 如果获取任务状态失败或任务执行失败。
"""
# 构建请求URL
url = "{}/api/doc/result".format(base_url)
# 打印任务轮询部分的标题
print("===================================================")
print("===== 2. 轮询任务状态直到OCR任务结束 =====")
print("== URL:", url)
# 设置请求头
headers = {"Content-Type": "application/json"}
# 准备请求体
data_str = json.dumps(
{
"id": file_id,
"is_data": True,
"format": "text",
"is_unread": True,
}
)
# 开始轮询任务状态
while True:
# 等待1秒后再次轮询
time.sleep(1)
# 发送POST请求查询任务状态
response = requests.post(url, data=data_str, headers=headers)
# 如果请求失败则抛出异常
response.raise_for_status()
# 解析响应数据
res_data = json.loads(response.text)
# 断言任务状态获取成功
assert res_data["code"] == 100, "获取任务状态失败: {}".format(res_data)
# 打印任务进度
print(
" 进度: {}/{}".format(
res_data["processed_count"], res_data["pages_count"]
)
)
# 如果有处理的数据则打印
if res_data["data"]:
print("{}\n========================".format(res_data["data"]))
# 如果任务已完成则退出循环
if res_data["is_done"]:
state = res_data["state"]
# 断言任务执行成功
assert state == "success", "任务执行失败: {}".format(
res_data["message"]
)
print("OCR任务完成。")
break
def _generate_target_file(file_id):
"""
根据文件ID生成目标文件的下载链接。
该函数使用提供的文件ID构建下载请求,将请求发送到服务器,并处理响应以获取下载URL和文件名。
参数:
- file_id: 文件的唯一标识符。
返回值:
- name: 文件名。
- url: 文件的下载链接。
"""
# 构建下载URL
url = "{}/api/doc/download".format(base_url)
# 打印生成和获取下载链接的过程信息
print("======================================================")
print("===== 3. 生成目标文件,获取下载链接 =====")
print("== URL:", url)
# 下载文件参数
download_options = {
"file_types": [
"txt",
"txtPlain",
"jsonl",
"csv",
"pdfLayered",
"pdfOneLayer",
],
# ↓ `ingore_blank` 是一个拼写错误。如果你使用的是 Umi-OCR 2.1.4 或更早版本,请使用这个错误的拼写。
# ↓ 如果你使用的是最新版本的 Umi-OCR,请使用正确的拼写 `ignore_blank`。
"ingore_blank": False, # 不忽略空白页
}
# 将文件ID添加到下载参数中
download_options["id"] = file_id
# 将参数转换为JSON字符串
data_str = json.dumps(download_options)
# 发送POST请求到服务器
response = requests.post(url, data=data_str, headers=headers)
# 如果响应状态码表示错误,则抛出异常
response.raise_for_status()
# 将响应内容解析为JSON
res_data = json.loads(response.text)
# 断言响应代码为100,否则抛出异常
assert res_data["code"] == 100, "获取下载链接失败: {}".format(res_data)
# 从响应数据中提取下载链接和文件名
url = res_data["data"]
name = res_data["name"]
# 返回文件名和下载链接
return name, url
def _download_file(url, name):
"""
从指定的URL下载文件并保存到本地。
参数:
url (str): 文件的下载链接。
name (str): 下载后保存的文件名。
"""
# 检查并创建保存下载文件的目录
if not os.path.exists(download_dir):
os.makedirs(download_dir)
download_path = os.path.join(download_dir, name)
# 发送HTTP请求获取文件
response = requests.get(url, stream=True)
response.raise_for_status()
# 获取文件总大小
total_size = int(response.headers.get("content-length", 0))
downloaded_size = 0
log_size = 10485760 # 每10MB打印一次进度
# 打开文件以二进制写入模式
with open(download_path, "wb") as file:
# 逐块读取响应内容
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
downloaded_size += len(chunk)
# 每下载10MB更新一次进度
if downloaded_size >= log_size:
log_size = downloaded_size + 10485760
progress = (downloaded_size / total_size) * 100
print(
" 正在下载文件: {}MB | 进度: {:.2f}%".format(
int(downloaded_size / 1048576), progress
)
)
# 提示文件已成功下载
print("目标文件已成功下载: ", download_path)
def _clean_up(file_id):
"""
清理指定文件ID相关的任务。
该函数通过发送GET请求到特定的URL(由base_url和file_id构成)来清理文件。
它首先构建请求URL,然后发送GET请求,并对响应结果进行检查,包括状态码和数据的验证。
参数:
- file_id: 需要进行清理任务的文件ID。
"""
# 构建清理任务的URL
url = "{}/api/doc/clear/{}".format(base_url, file_id)
# 打印清理任务的相关信息
print("============================")
print("===== 5. Clean up task =====")
print("== URL:", url)
# 发送GET请求到构建的URL
response = requests.get(url)
# 对响应状态进行检查,如果状态码不在200范围内,则抛出异常
response.raise_for_status()
# 解析响应文本为JSON格式
res_data = json.loads(response.text)
# 断言响应数据中的code字段等于100,否则抛出异常
assert res_data["code"] == 100, "Task cleanup failed: {}".format(res_data)
# 打印任务清理成功的信息
print("Task cleaned up successfully.")
# 打印过程完成的信息
print("======================\nProcess completed.")
def ocr_file_to_text(file_path):
"""
将给定的文件通过OCR转换为文本。
首先上传文件并处理,然后生成目标文件并下载。
最后,清理环境并返回下载文件的路径。
参数:
file_path (str): 文件路径。
返回:
str: 下载文件的路径。
"""
# 上传文件并获取文件ID
file_id = _upload_file(file_path)
# 处理上传的文件
_process_file(file_id)
# 生成目标文件并获取文件名和URL
name, url = _generate_target_file(file_id)
# 下载目标文件
_download_file(url, name)
# 清理上传的文件和生成的临时文件
_clean_up(file_id)
# 获取文件名和扩展名
file_name, file_extension = os.path.splitext(file_path)
# 获取不带扩展名的文件名
file_name_without_extension = os.path.basename(file_name)
# 重组文件名
f_name = file_name_without_extension + file_extension
# 解压下载的文件
with zipfile.ZipFile(f"{download_dir}/{name}", 'r') as zip_ref:
# 提取特定命名规则的文件
temp_name = f'[OCR]_{file_name_without_extension}.layered{file_extension}'
zip_ref.extract(temp_name, download_dir)
# 重命名提取的文件
os.rename(download_dir + '/' +temp_name, download_dir + '/' +f_name)
# 返回重命名后的文件路径
return download_dir + '/' + f_name
def get_b64_image_from_path(image_path):
"""
将指定路径的图像编码为Base64字符串。
这个函数读取图像文件的内容,并将其转换为Base64编码的字符串。Base64编码是一种将二进制数据转换为文本字符串的方法,
常用于在HTTP请求中传输图像数据。
参数:
image_path (str): 图像文件的路径。
返回:
str: Base64编码的图像字符串。
"""
# 打开图像文件,以二进制模式读取
with open(image_path, "rb") as image_file:
# 读取图像文件内容,使用Base64进行编码,并将结果转换为UTF-8格式的字符串
return base64.b64encode(image_file.read()).decode('utf-8')
def ocr_image_to_text(file_path):
"""
使用OCR技术将图像文件转换为文本。
该函数通过调用远程API,将图像文件(由文件路径指定)转换为文本数据。
它首先将图像转换为Base64编码的字符串,然后通过HTTP POST请求发送到OCR API进行处理。
参数:
- file_path (str): 图像文件的路径。
返回:
- str: 转换后的文本数据,如果转换失败则可能返回None。
"""
import requests
import json
# 从指定路径获取图像并转换为Base64编码的字符串
data_base64 = get_b64_image_from_path(file_path)
# 构建API的URL
url = f"{base_url}/api/ocr"
# 构建要发送的数据,包括图像的Base64编码和指定的选项
data = {
"base64": data_base64,
# 可选参数示例
"options": {
"data.format": "text",
}
}
# 将数据转换为JSON格式
data_str = json.dumps(data)
# 发送POST请求到OCR API
response = requests.post(url, data=data_str, headers=headers)
# 确保请求成功,否则抛出异常
response.raise_for_status()
# 解析响应数据为字典
res_dict = json.loads(response.text)
# 返回转换后的文本数据
return res_dict.get("data")至于代码我就不解释了,因为文件内带有,有关于开局那三个除了ocr_url填写为localhost:3306:127.0.0.1.1224基本上就是本地地址加ocr启动的端口号,我填写的可能是错的
注:该代码只有当umi-ocrt启动了服务才能使用
后言
关于ocr就介绍到这里,在下一篇章将会详细介绍如何继续之前的fatsapi完善后端代码大模型页面聊天的请求功能。