1.LetNet-5
1. 卷积神经网络的发展背景与LeNet-5
卷积神经网络 (Convolutional Neural Network,简称 CNN)是一种深度学习模型,其中的网络结构 与卷积运算密切相关。CNN 在计算机视觉领域有着广泛的应用,可以用来处理图像、视频等数据。
CNN 的发展可以追溯到 1980 年代 ,当时 Yann LeCun(杨立昆 )和他的同事们 开始研究如何用神经网络来识别手写数字。他们研究发现,使用卷积运算来提取图像中的特征可以提高神经网络的准确率。
在1998年,LeCun 训练的LeNet-5网络 ,标志着CNN的真正面世,但是当时的硬件跟不上。
在2012年 ,Hinton的学生Alex Krizhevsky利用AlexNet 在ILSVRC 2012的ImageNet 数据集上,将传统的70% 多的准确率提升到80%多。(2012年之前图像识别是模式识别+机器学习的方法,从2012年Alex提出这个AlexNet这个网络的时候,使用的是深度神经网络,也就是他用了卷积的一个过程,其实就是LeNet的加强版本。2012年之后ImageNet竞赛主要采用深度学习了。
随着计算机技术的发展,CNN 在近几年来不断演进。许多研究人员都对 CNN 的网络结构、训练方法和应用领域进行了探索。现在,CNN 已经成为计算机视觉和深度学习领域的重要模型。
CNN应用很多例如:
图像分类:将图像分类为不同类别,如狗、猫等。
图像定位:在图像中确定物体的位置,如狗、猫等。
视频分析:分析视频中的内容,如检测运动目标、识别手势等。
语音识别:识别语音中的单词或语句。
CNN在这些任务中取得了很大的进展,其准确率往往高于传统的机器学习方法。随着技术的进步,CNN的应用领域还会有更多的拓展。
LeNet-5模型是由杨立昆 (Yann LeCun)教授于1998年在论文Gradient-Based Learning Applied to Document Recognition 中提出的,是一种用于手写体字符识别 的非常高效的卷积神经网络,其实现过程如下图所示。
LeNet-5神经网络架构图
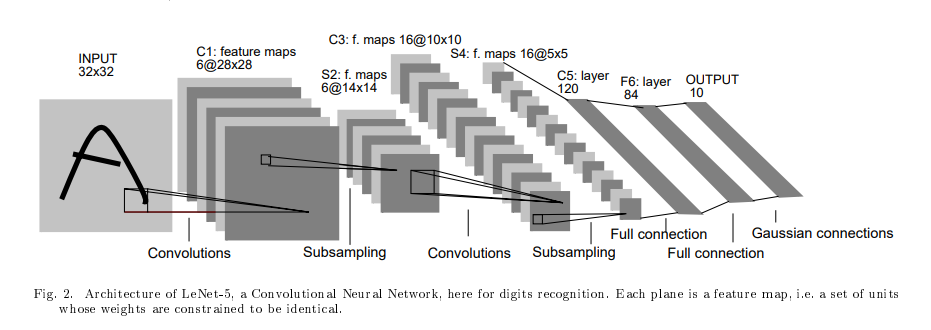
如上图,结构非常简单,基本流程 卷积->池化->卷积->池化->全连接->输出
**降采样层(Subsampling Layer):**也被称为池化层(Pooling Layer),主要用于减少特征图的空间尺寸,降低计算复杂度,并增强模型的平移不变性.
2.网络架构
LeNet-5 CNN 架构有七层。三个卷积层、两个子采样层和两个全链接层,组成了层结构。
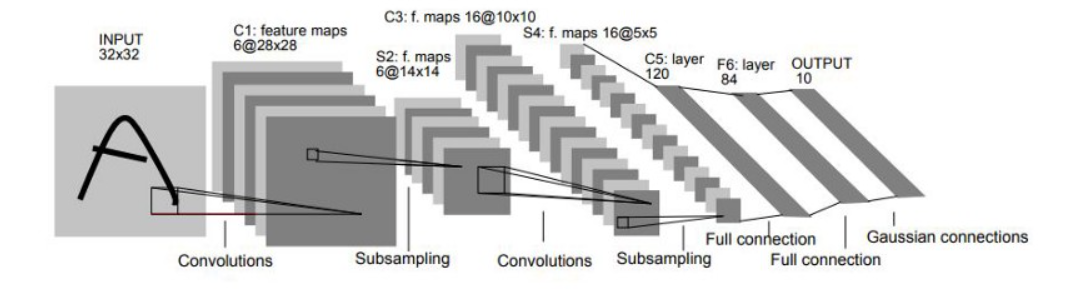
如上图,结构非常简单,基本流程就是 卷积 -> 池化 -> 卷积 -> 池化 -> 全连接 -> 全连接 -> 输出
接下来我们逐层分析:
输入层:
输入图片为单通道 32x32 的图像
若不符合要求,需要进行灰度化,重置大小还有图像参数归一化的操作 (从0~255变成0~1)。
第一层: 卷积层1
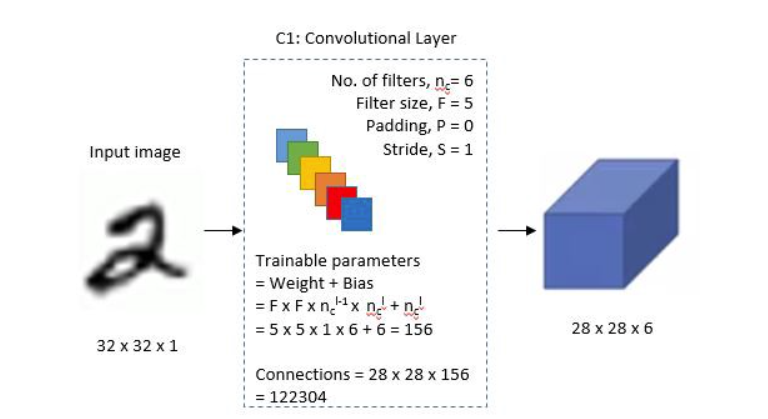
这是一个卷积层,左侧是输入,输入是一个单通道 32x32 的图片
中间部分描述了卷积层的参数:
- No.of filters, n = 6: 这个是滤波器 (卷积核) 个数
- Filter size, F = 5: 这个是滤波器大小
- Padding, P = 0: 这个是填充
- Stride, S = 1: 这是步幅
图片中间,下半部分还计算了可训练参数

最下方的 Connections 代表的是运算量,156 代表的是一次卷积运算的运算量,然后卷积核水平和竖直滑动了 28 次,所以总运算量为
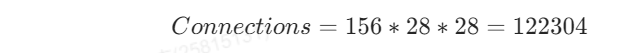
最终该层输出 6 个 28x28 的特征图
第二层: 池化层1
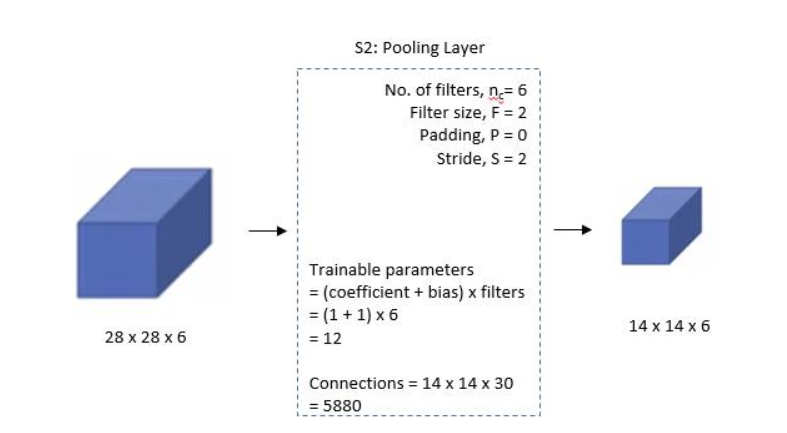
这是一个平均池化层,左侧接收上一层的输入 28x28x6 的特征图
中间是参数
- n = 6: 6个池化核,输出6个通道
- F = 2: 池化核大小
- P = 0: 不填充
- S = 2: 步幅为2,核池化核大小相同
池化过程在过去,是将 2x2 区域的像素相加并乘以一个权重系数再加上一个偏置,得到最终结果,所以上图存在可训练参数
但实际上现在我们的框架的池化层是不包含训练参数的
最终输出 6 个 14x14 特征图
第三层: 卷积层2
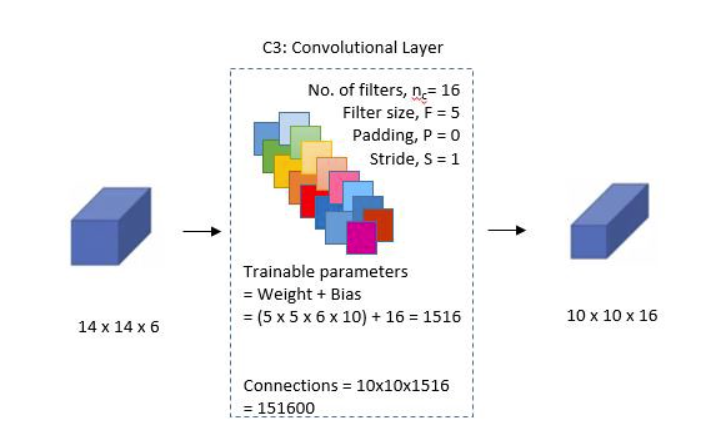
- n = 16: 16个卷积核,输出16个通道
- F = 5: 卷积核大小
- P = 0: 不填充
- S = 1: 步幅为1
这层比较特殊,在原作者制作该层时,卷积核和输入通道是以一种分组的方式进行连接的。每个卷积核将采用部分输入通道做卷积,如图:
X表示选中的输入的通道。没写表示没选中
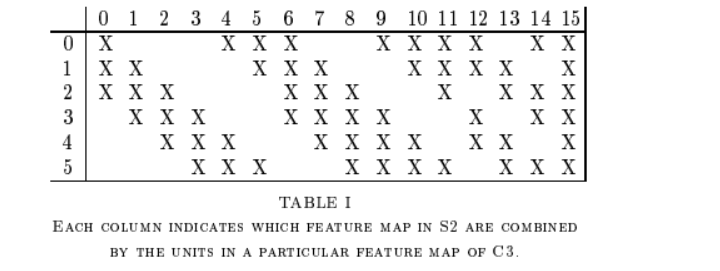
最终输出 16 个 10x10 特征图
第四层: 池化层2
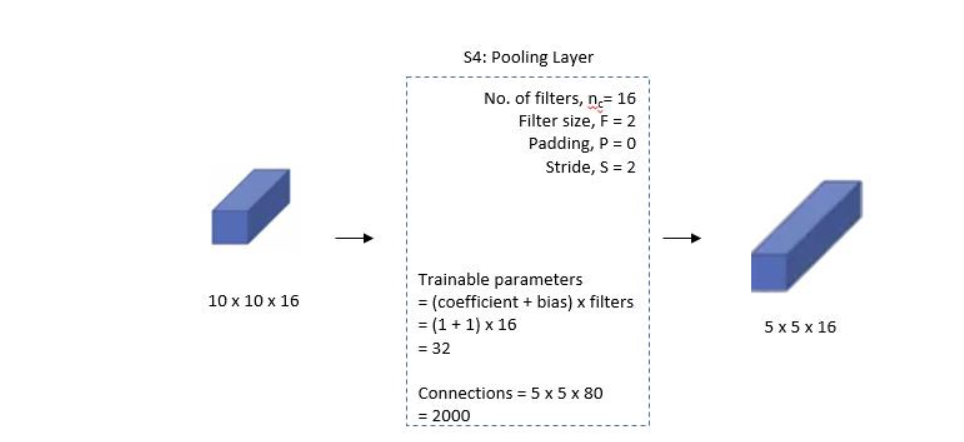
- n = 16: 16个池化核,输出16个通道
- F = 2: 池化核大小
- P = 0: 不填充
- S = 2: 步幅为2,核池化核大小相同
最终输出 16 个 5x5 特征图
第五层: 卷积层3
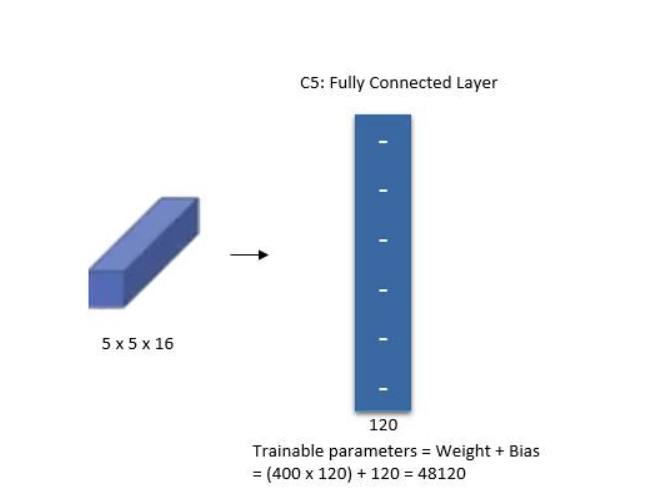
图中写的虽然是全连接,但通过后面的架构图可知,此处实际是一个卷积层(可以使用卷积也可以使用展平方式,效果类似)
输入为 5x5x16,卷积核为 5,输出为 1x1x120
注意: 我们在使用 pytorch 时,这里实际上可以用一个展平(Flatten) 再通过一个全连接,输出 120 个特征。
第六层: 全连接
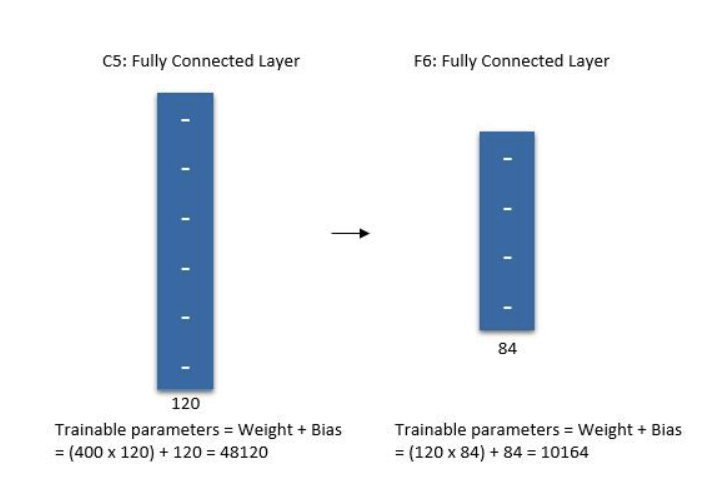
从上一层接收 120 个特征点,输出 84 个特征点
最终输出 84 个特征
第七层: 输出层
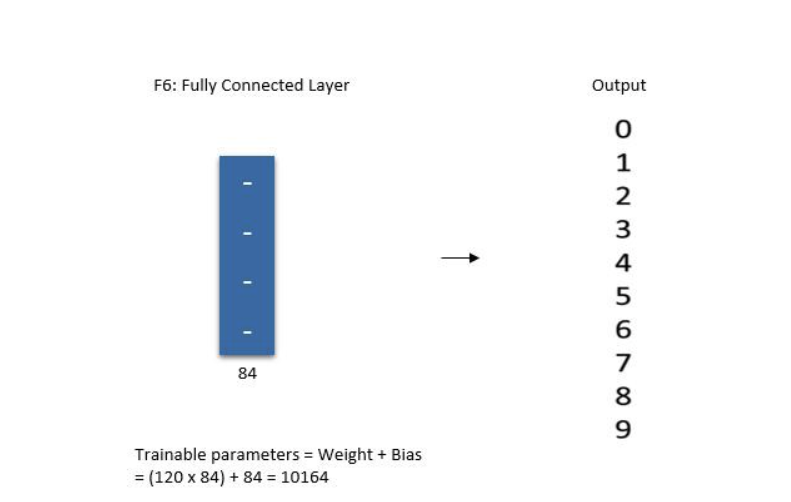
最后层输出 0~9 10 个数字的分布概率
完整架构表
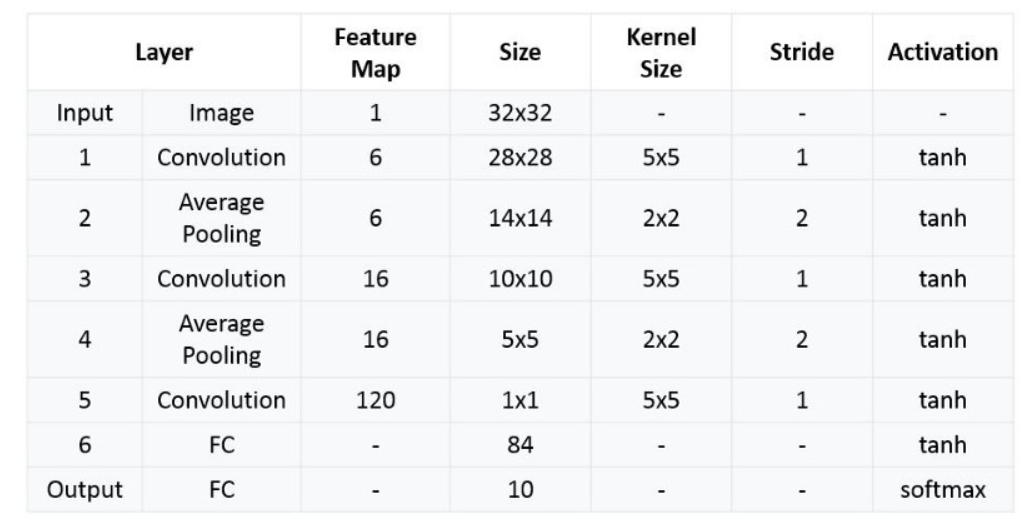
注意: 每一层都有一个激活函数作为非线性激活,这里作者用的是 tanh 和 softmax 函数。
- tanh: 形状类似 sigmoid,但结果分布在 -1 ~ 1 之间
- softmax: 求概率分布的函数,输出结果和为 1
3.MNIST数据集
MNIST数据集(Modified National Institute of Standards and Technology database)是一个广泛使用的手写数字图像数据库,常用于机器学习和计算机视觉的测试和训练。这个数据集包含了从0到9的手写数字的灰度图像,每张图像的大小为28x28像素。MNIST数据集共有70000张图像,其中60000张用于训练,10000张用于测试。
下载的MNIST训练集如下图所示。
下面解析一下数据集,以train-images-idx3-ubyte为例,
第一个数的32位的整数(魔数,图片类型的数)
第二个数32位的整数(图片的个数,这里训练集是60000个图片)
第三和第四个也是32位的整数(分别代表图片的行数和列数)
接下来的数据都是一个字节的无符号整数(即像素,值域范围0~255)
letnet5代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torchsummary import summary
#device 判断一下我的设备是否可用GPU
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
#定义letnet5网络
class LetNet5(nn.Module):
def __init__(self):
super(LetNet5,self).__init__()
#定义网络
# in_channels 输入图像的通道数
#out_channels:经过卷积运算产生的输出通道数
# kernel_size:卷积核大小,整数或元组类型(表示长和宽卷积核的大小)。
self.conv1=torch.nn.Conv2d(in_channels=1,out_channels=6,kernel_size=(5,5),stride=1,padding=2)
self.pool1=torch.nn.AvgPool2d(kernel_size=2,stride=2)
# 第二次卷积
self.conv2 = torch.nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5, 5), stride=1)
# 第二层池化
self.pool2 = torch.nn.AvgPool2d(kernel_size=2, stride=2)
# torch.nn.Flatten展平
# 参数含义:start_dim :指定开始展平的维度,默认值为1 ,即从除了批次维度(第
# 0维)外的第一个维度开始展平。
# end_dim :指定展平结束的维度,默认值为 - 1 ,表示展平到最后一个维度
self.flatten=torch.nn.Flatten(start_dim=1,end_dim=-1)
#使用全连接
self.fc1=torch.nn.Linear(in_features=400,out_features=120)
self.fc2=torch.nn.Linear(in_features=120,out_features=84)
self.fc3 = torch.nn.Linear(in_features=84, out_features=10)
def forward(self,x):
#第一层卷积操作
x=self.conv1(x)
#池化加激活
x=self.pool1(F.tanh(x))
x = self.pool2(F.tanh(self.conv2(x)))
# x=x.view(-1,400)
x=self.flatten(x)
x=F.tanh(self.fc1(x))
x = F.tanh(self.fc2(x))
x = self.fc3(x)
return x
#申请模型对象
model=LetNet5()
x=torch.rand(5,1,28,28)
y=model(x)
result=F.softmax(y,dim=1)
print(np.argmax(result.detach().numpy(),axis=1))
# torch.summary 输出的结果,没有层的概念,-1只是单纯表示batch_size不确定
# Conv2d-1 [-1, 6, 28, 28] 156
summary(model.to(device),input_size=(1,28,28))