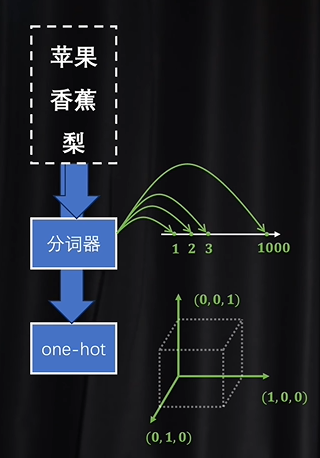
01 One-hot Encoding
One-hot Encoding 是一种以数字表示分类值的方法。
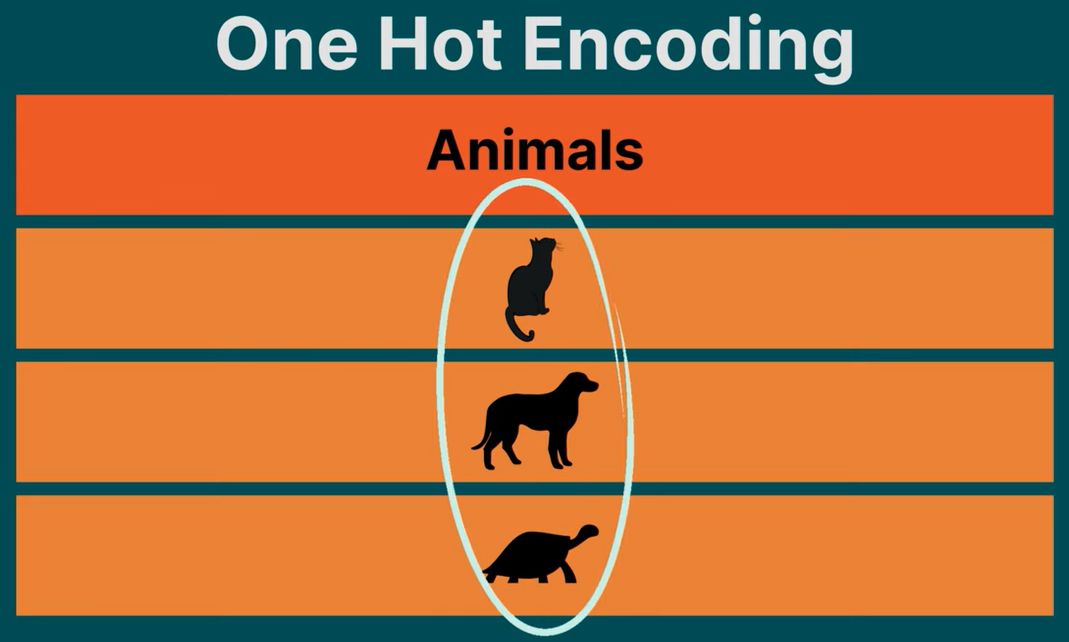
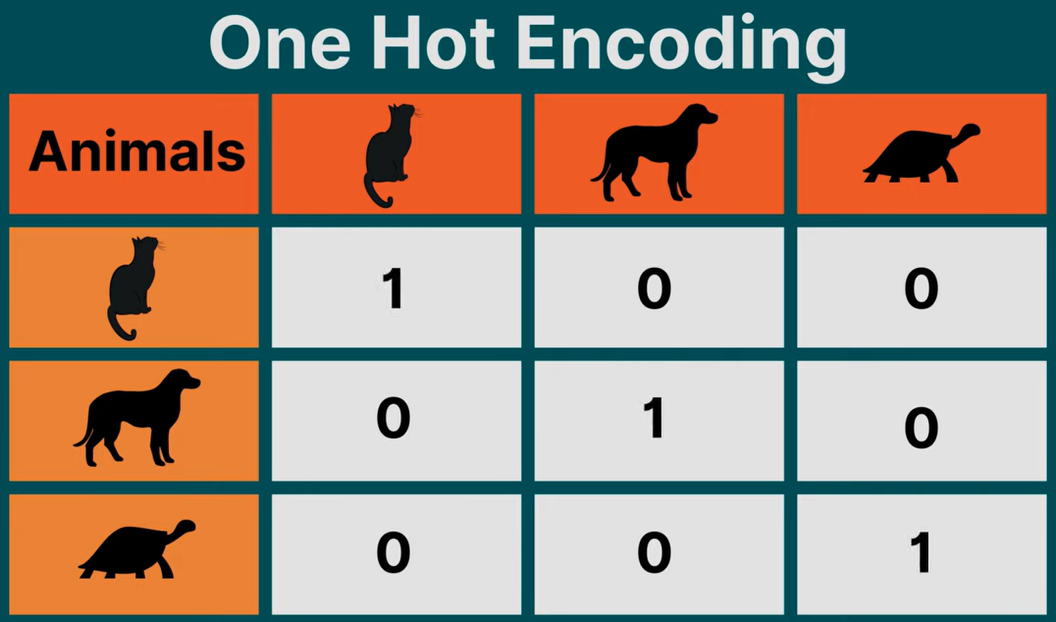
假设我们创建一个数组,该数组的长和宽与我们的元素数量相同,除对角线的数字为 1 以外,其余位置的数字都为 0。
Why not just show them in numbers?
Because numbers have an ordinal relationship between them, meaning 3 is greater than 2 and 5 is lower than 8.
如果 3 表示上衣类别,5 表示裤子类别,将 3 和 5 两个数字输入给模型,模型会误以为上衣类别不如裤子类别,事实上这二者并无任何区别。

Any other way to present One-hot encoding?
You can also use dummy variables!
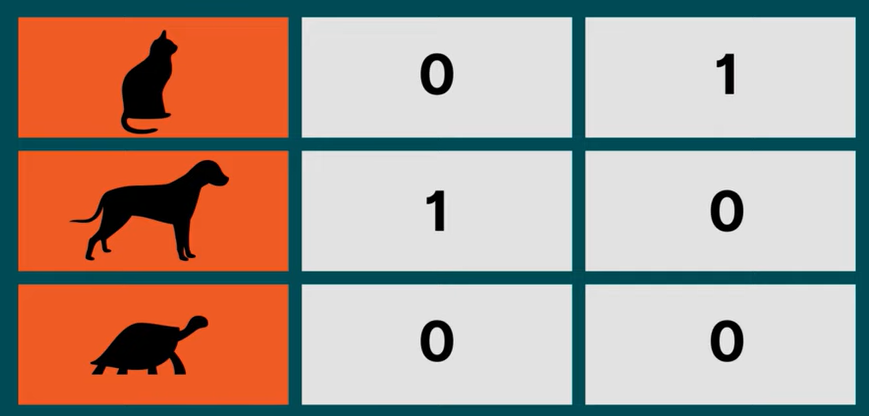
Dummy variables 创建的数组的行数和列数为 N * N-1,而不是 N * N,N 指的是我们的元素数量。在这个数组中,前 N-1 个元素使用对角线的 1 来表示,最后一个元素可以用全 0 表示。
02 Word Embeddings
语言模型是以数字为基础的,当它和人类对话时,听不懂文字,但看得懂数字,因此,我们需要一种方法将文字 转化为数字。
在训练开始之前,为每个词分配一个随机数字,比如 Troll 2 is great! ,我们为其分配的随机数字为 12、-3.05、4.2,又比如 Troll 2 is awesome!,我们为其分配的随机数字为 12、-3.05、-32.1。我们注意到 great 和 awesome 的意思和用法都十分相近,但被分配的随机数字确相差甚远,为了方便我们的训练,即模型学会了 great 也会联想到 awesome,需要为每个单词分配更多的随机数字。比方说,为 great 分配两个随机数字,第一个用以表示 "好" 的含义,第二个用于追踪使用语境,如夸赞、讽刺、批评等。

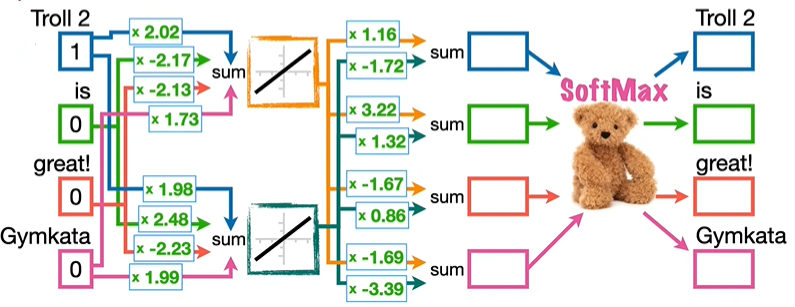
我们创建了一个简单的神经网络来展现如何将哪些数字和哪些词汇相关联,假设这里有两句话 Troll 2 is great! 和 Gymkata 2 is great!,包含四个输入 Troll 2、is、great!、Gymkata。然后,将每个输入连接到至少一个激活函数 ,y = x,这个激活函数仅仅提供相加的功能,激活函数的数量等于我们想要与每个词关联的数字的数量,也就是向量长度 ,并且,这些连接上的权重最终是向量数值。本例中为每个输入分配两个随机数字,也对应两个激活函数,这两个随机数字也就是权重,将会通过反向传播进行优化。
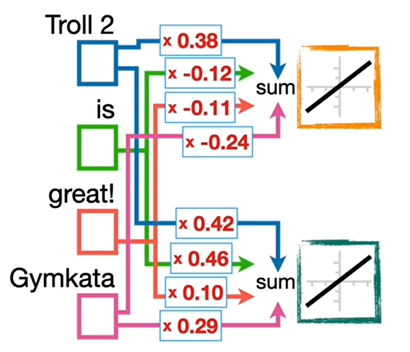
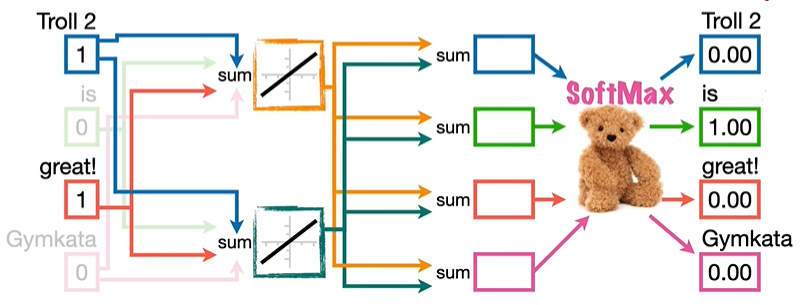
我们利用输入词汇预测下一个词汇,比如输入 Troll 2 预测 is,输入 is 预测 great!,对应的向量数值为 1,其余为 0。将激活函数连接到输出,并在这些连接上添加随机初始化值的权重,通过 SoftMax 函数进行输出。
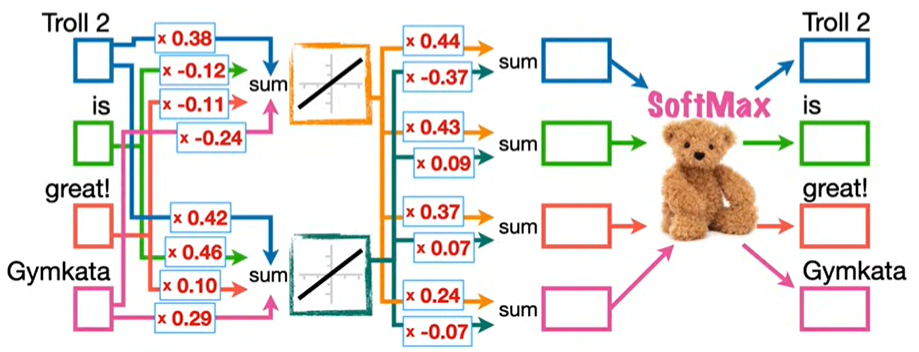
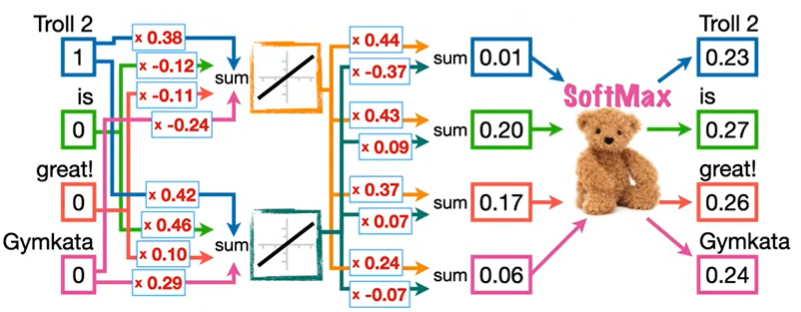
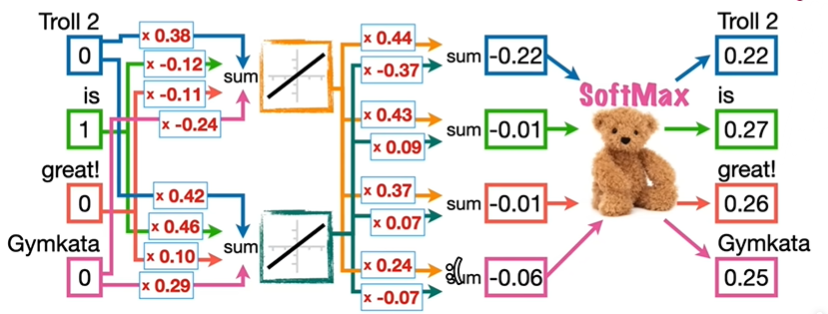
在分配的随机数字条件下,输入 Troll 2 预测 is 成功,输入 is 预测 great! 失败。
我们在二维空间坐标系中画出每个输入的位置,可以看到,Troll 2 和 Gymkata 相差甚远。
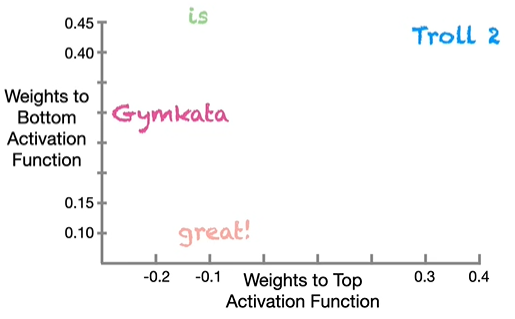
我们利用反向传播,重新调整各项参数,输入 Troll 2 预测 is 成功,输入 is 预测 great! 成功。
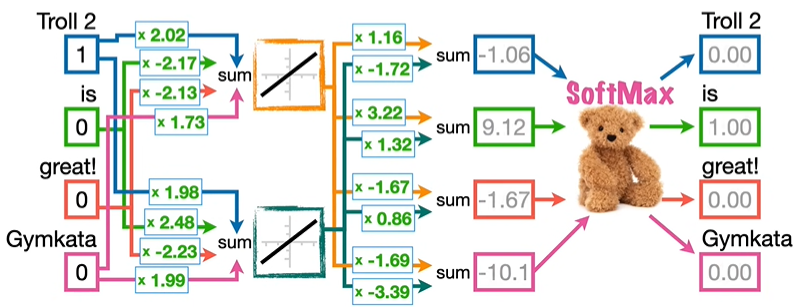
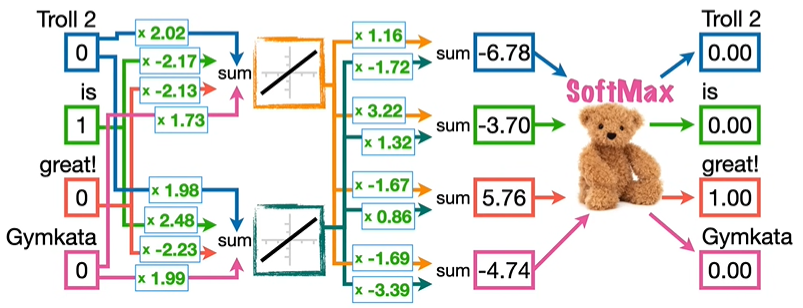
我们在新的二维空间坐标系中画出每个输入的位置,可以看到,Troll 2 和 Gymkata 相差很近。
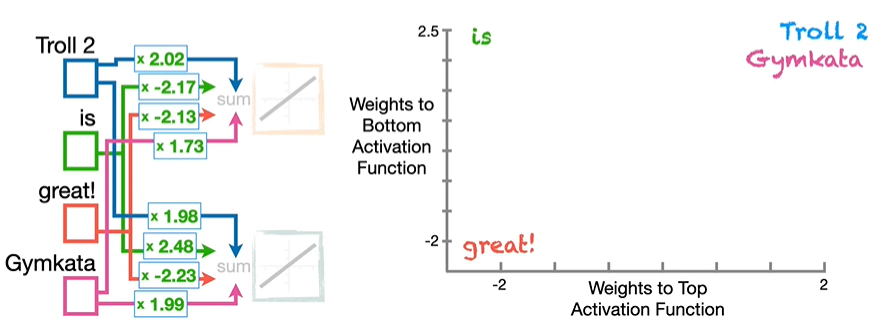
截至目前,我们让模型学会了一个词的使用有助于相似词的使用,但没有提供上下文信息来理解每个词,因此,我们引入 word2vec 方法,一种流行的创建词嵌入方法,用于包含更多的上下文信息。
03 Word2Vec
① Continuous Bag of Words 连续词袋
Continuous Bag of Words 通过使用周围的词来预测中间的词来增加语境,比如,Continuous Bag of Words 使用 Troll 2 和 great! 预测 is。
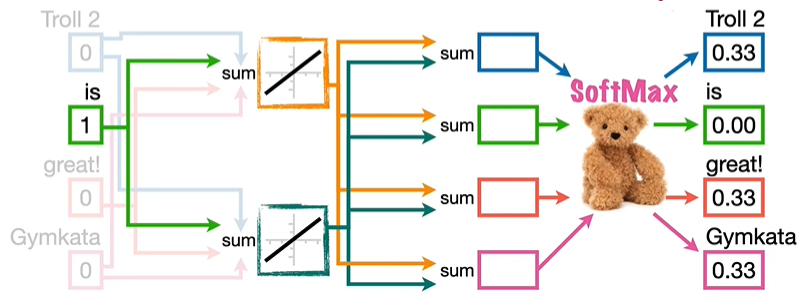
② Skip Gram
Skip Gram 通过使用中间的词来预测周围的词来增加语境,比如,Skip Gram 使用 is 预测 Troll 2 、great! 和 Gymkata。
③ Negative Sampling
本文的示例中,输入和激活函数数量都很少,在实际应用中,人们通常使用 100 个或更多的激活函数来为每个词创建大量的嵌入,而且不是使用两句子进行训练,它们使用整个维基百科!
因此,Word2Vec 不是只有四个单词和短语的词汇量,而是可能拥有大约 300 万词的词汇表,因此,我们需要优化的这个神经网络中的权重总数是 300万 * 100 * 2 = 6 亿。
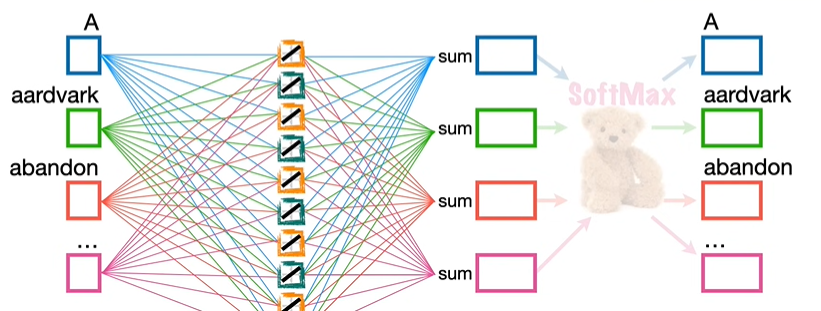
一个减少参数量的好方法是采用负采样,负采样通过随机选择一部分单词,即我们不想预测的那些用于优化的词,比如我们想要利用 aardvark 预测 A,那么输入只有 aardvark 是 1,其余都是 0,0 乘以任何数都等于 0,因此忽略其它输入的参数,参数量直接减少 3 亿。
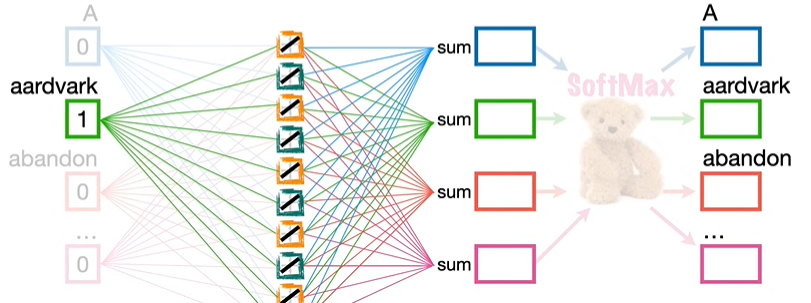
在输出中,我们可以选择不想预测的输出,比如 abandon,因此,在反向传播中,只关注 A 和 abandon 的数值,参数量进一步下降,来到了 300 个,这就是 word2vec 的有效创建。
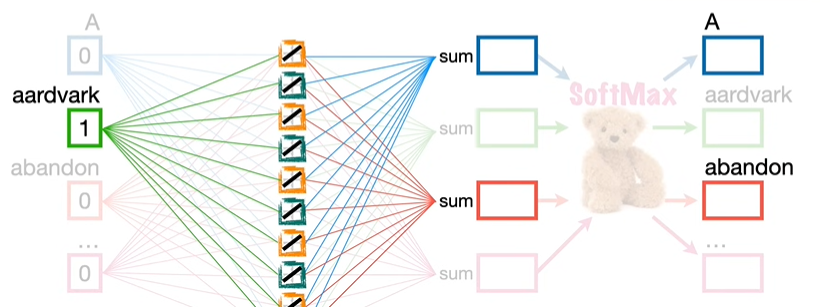
缺点:

04 Glove
Word2Vec 有一个缺点,没有考虑全局信息,Word2Vec 只是用单独的局部上下文来生成单词,这里引入 Glove,通过全局向量解决问题。
具体而言,我们构建一个单词共现矩阵 ,对于每一个单词,我们尝试理解哪些单词处于其它单词的上下文中,比如,我们统计 hoax 在 covid 上下文中出现的次数,believe 在 hoax 上下文中出现的次数,然后获得这些单词的向量矩阵。
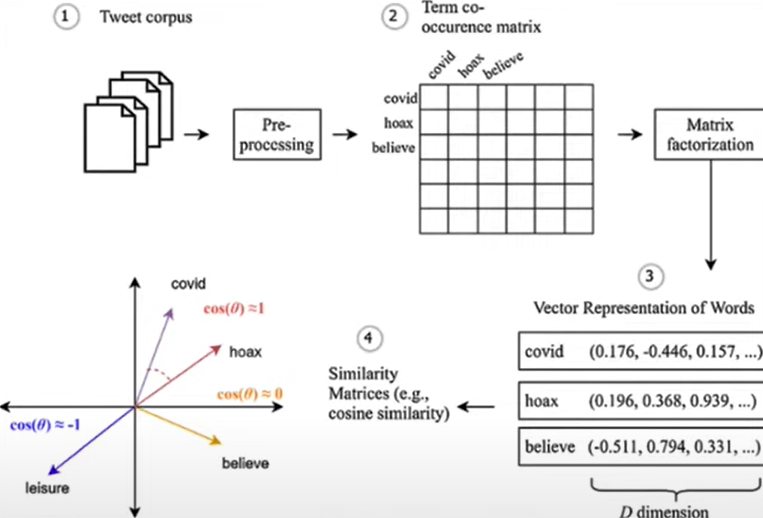
假设我们这里有两个单词,ice 和 steam,我们想要确定 solid、gas、water、fashion 在全局向量的含义上更接近哪些单词,通过计算概率来进行判断。

我们观察第三行,可以发现,solid 在 ice 的上下文中出现的概率很高,gas 在 steam 的上下文中出现的概率很高,说明在全局信息中,solid 和 ice 高度相关,gas 和 steam 高度相关,而 water 和 ice、steam 都没有什么关联,这正是我们想要的结果!
05 FastText
Word2Vec 还有一个缺点,无法预测它没见过的词汇,比如,可以转换 tensor 和 flow,但不能转换二者的复合体 tensorflow,因此词汇量不足。
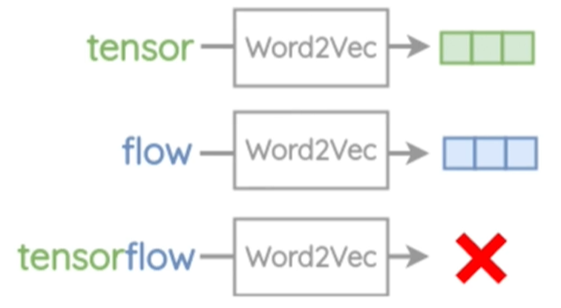
对于eat、eats、eaten、eater、eating等一些具有相同内部结构的词,Word2Vec 不做任何的参数共享,每个单词都是根据其上下文单独学习,我们可以利用单词的内部结构,提高效率,我们引入 FastText Word Embeddings,这种方法尤其对于一些学术词汇、文化词汇特别有效。

与 Word2Vec 不同的是,FastText 利用滑动窗口法,将词汇进行特定长度的拆分,比如将其分割成 3、4、5、6 Grams,然后在 Skip Gram 架构中使用它们。

- FastText can handle OOV better than Word2Vec.
- FastText is often a first choice when you want to train custom word embeddings for your domain.
- FastText is a technique (similar to word2vec) as well as a library.
缺点:

此问题在 LSTM、Bert 和 GPT 中得到妥善解决。
注,tokenizers 和 embedding algrithms 都是对 token 进行数字化处理,二者思路不同,前者是将所有 token 投射到一维空间,后者是将所有 token 投射到 n 维空间,都没办法保证上下文的一个信息,而我们知道,在 transformer 当中,上下文对同一个 token 的影响是很大的,因此,我们引入位置编码技术。