精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、开发环境
- 三、视频展示
- 四、项目展示
- 五、代码展示
- 六、项目文档展示
- 七、总结
-
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻)
一、项目介绍
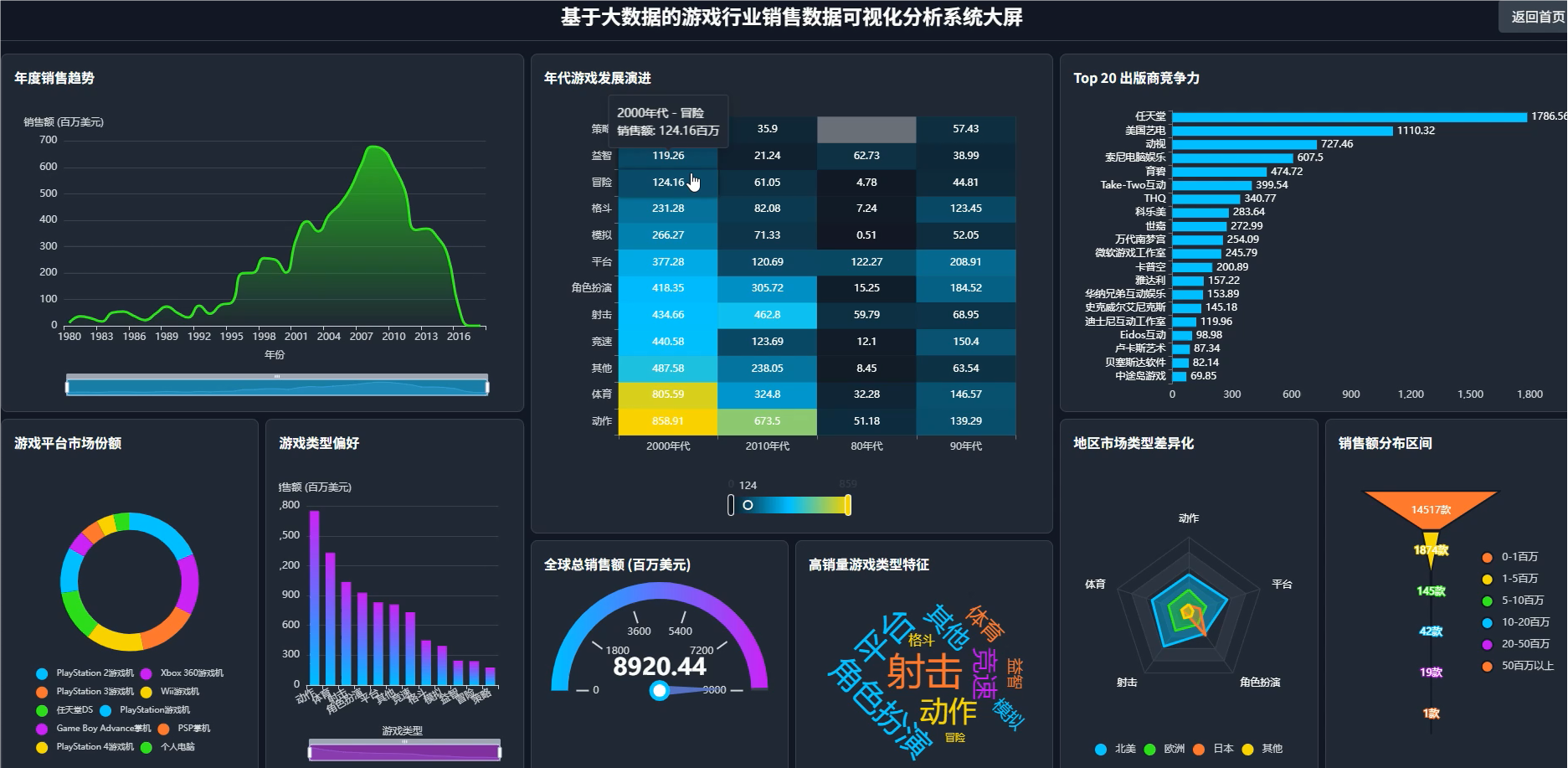
《基于Hadoop的游戏行业销售数据可视化分析系统》是一套完整的大数据处理与Web展示解决方案,旨在深度挖掘全球电子游戏销售数据背后隐藏的市场趋势与商业价值。本系统以Python为主要开发语言,技术架构上深度整合了大数据生态的核心组件。在数据存储层,我们采用Hadoop分布式文件系统(HDFS)来管理和存储原始的vgsales.csv数据集,确保了数据存储的可靠性与高扩展性,为后续大规模数据处理奠定了坚实基础。在数据处理与分析的核心环节,系统充分利用了Apache Spark的内存计算框架,通过PySpark接口编写了多达15个维度的复杂分析任务,涵盖了从全球销售总体统计、游戏平台市场份额剖析,到特定游戏类型在不同区域的受欢迎程度、顶级出版商的竞争力格局以及游戏平台的生命周期演变等多个关键业务视角。后端服务采用轻量级且高效的Django框架搭建,负责调度Spark分析任务、管理分析结果数据,并通过RESTful API接口将处理好的结构化数据提供给前端。前端界面则基于Vue.js框架进行组件化开发,并集成强大的Echarts图表库,将复杂的分析结果以直观、动态、交互性强的可视化图表(如饼图、柱状图、折线图、热力图等)形式呈现给用户,让使用者能够一目了然地洞察游戏市场的宏观格局与微观特征,从而为游戏开发者、发行商或市场分析师的决策提供有力的数据支持。
选题背景与选题意义
说起选题背景,其实挺直接的。现在的游戏行业已经不是几十年前的小众爱好了,它变成了一个体量巨大、遍布全球的庞大市场。每年都有成千上万款新游戏发布,销售数据、玩家评论、在线时长这些信息像潮水一样涌来,形成了一片数据的海洋。对于这么海量的数据,再用咱们以前在学校里学的Excel或者单纯用个MySQL数据库去分析,就有点力不从心了,跑个稍微复杂点的查询可能电脑就卡半天。这就产生了一个很现实的需求:需要更专业的工具来处理和理解这些数据。像Hadoop和Spark这种大数据技术,就是为了解决这类问题而生的。它们能把一个大任务拆成很多小任务,让一堆机器一起干活,效率特别高。所以,把这些专业的大数据技术应用到我们都挺熟悉的游戏领域,做一个能分析销售数据的系统,感觉既能紧跟技术潮流,又能解决一个真实世界里存在的问题,这让整个课题显得很有现实感和挑战性。
至于这个课题的意义,我觉得可以从几个方面来看,但说实话,主要还是对自己能力的锻炼。首先,对我个人来说,这是一个非常好的学习和实践机会。它不是做一个简单的增删改查管理系统,而是让我把从数据存储(HDFS)、分布式计算(Spark),到后端开发(Python/Django)再到前端可视化(Vue/Echarts)这一整套技术栈串起来,亲手走一遍完整的"数据采集-处理-分析-可视化"流程。这个过程里遇到的各种坑,比如数据清洗的细节、不同技术间的接口调试,都是书本上学不到的宝贵经验。从一个稍微实际点的角度看,这个系统虽然只是个毕设,但它做出来的事情是有一定参考价值的。比如,一个小型的独立游戏开发团队,他们可能没有财力去购买昂贵的商业智能工具,但可以借鉴这个系统的思路,去分析公开的市场数据,看看什么样的游戏类型在哪个地区更受欢迎,或者哪个游戏平台的用户付费能力更强,从而帮助他们做出更明智的开发和发行决策。它就像一个微缩版的商业数据分析平台,展示了如何用开源技术从数据中挖到有用的信息,这本身就是一件挺有意义的事。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
三、视频展示
计算机毕设选题推荐:基于Hadoop和Python的游戏销售大数据可视化分析系统
四、项目展示
登录模块:
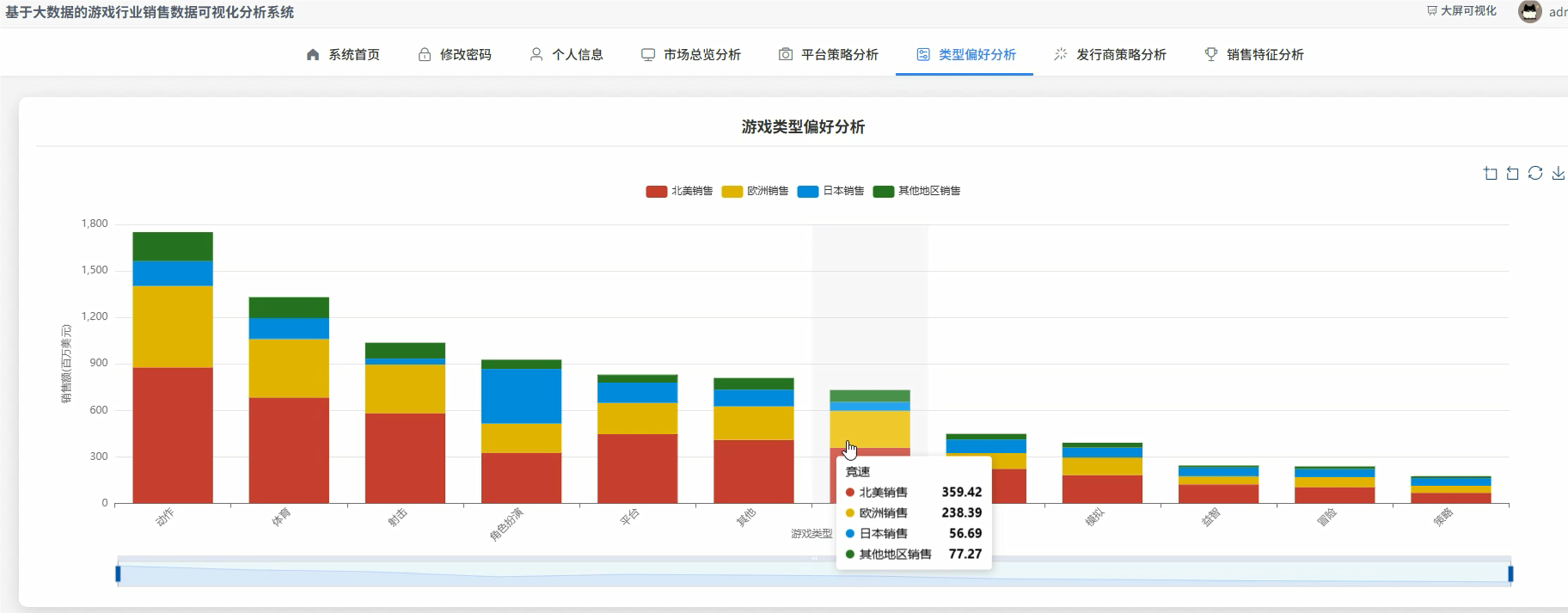
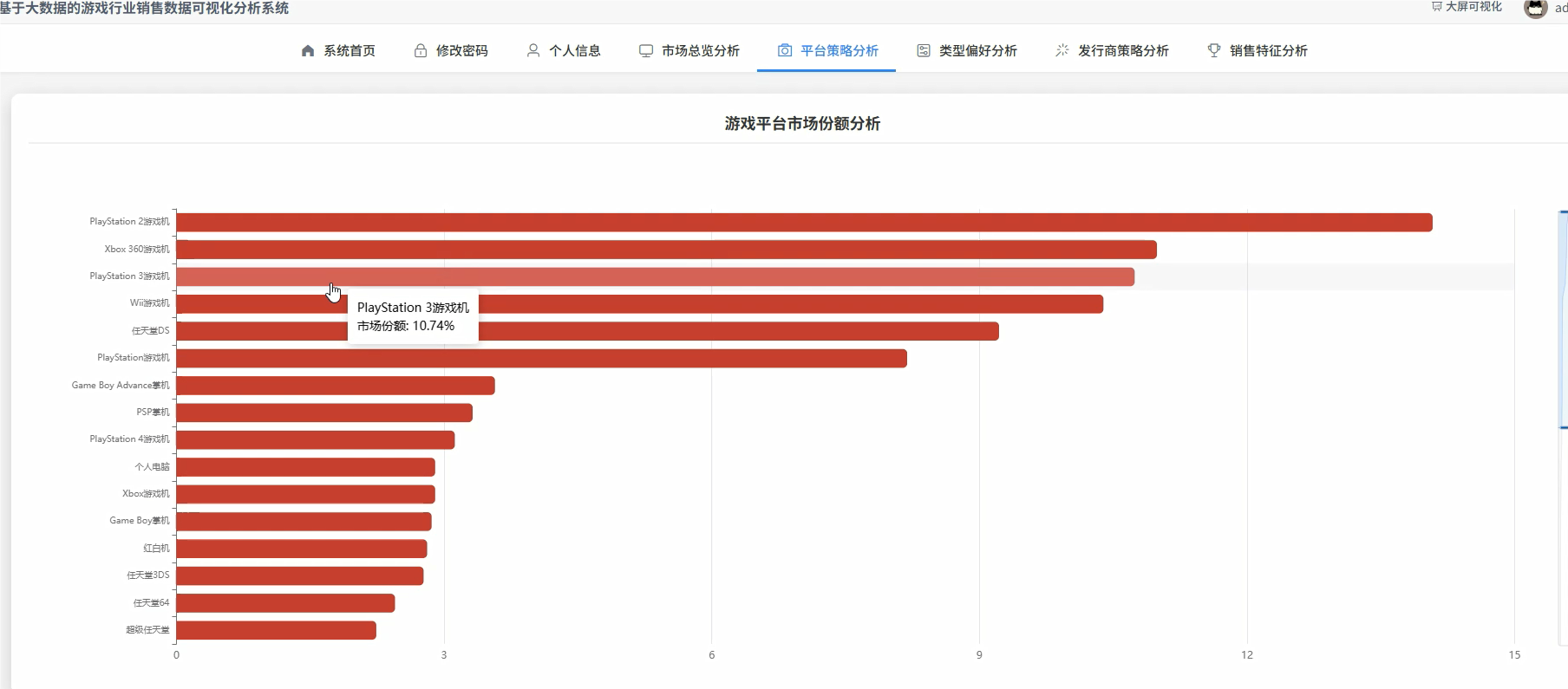
管理模块:
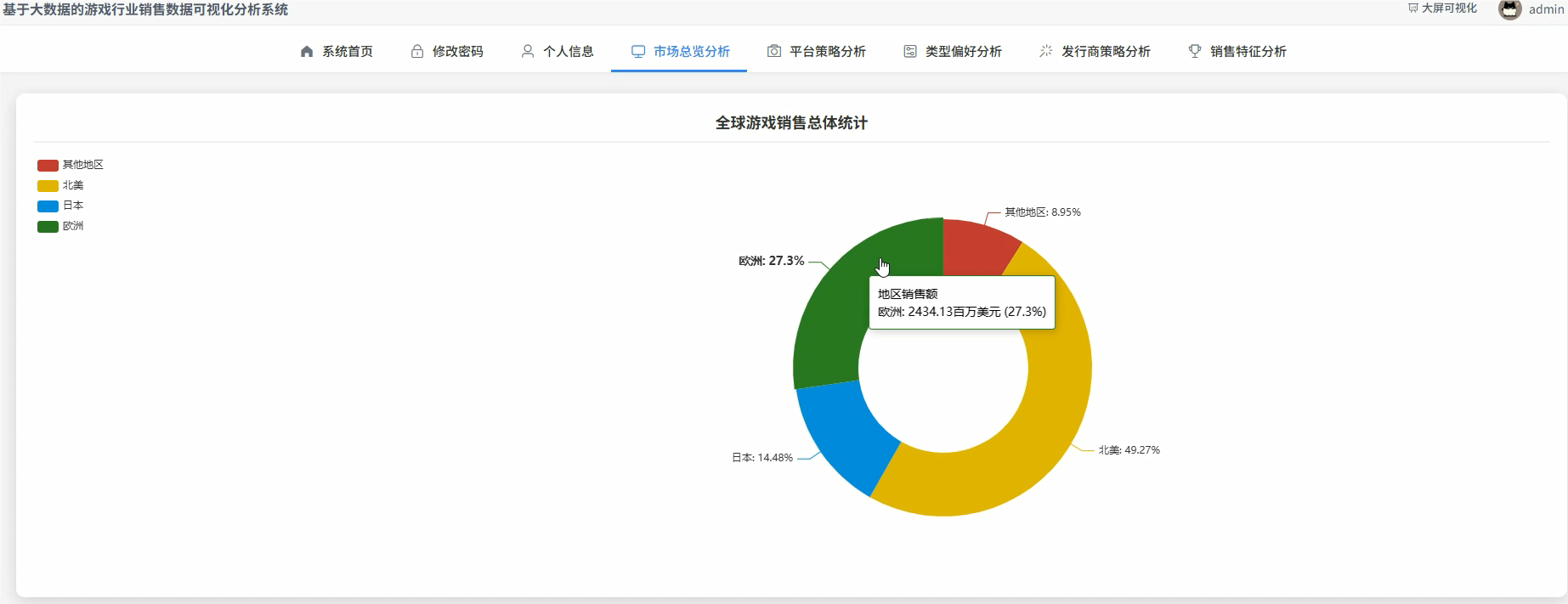
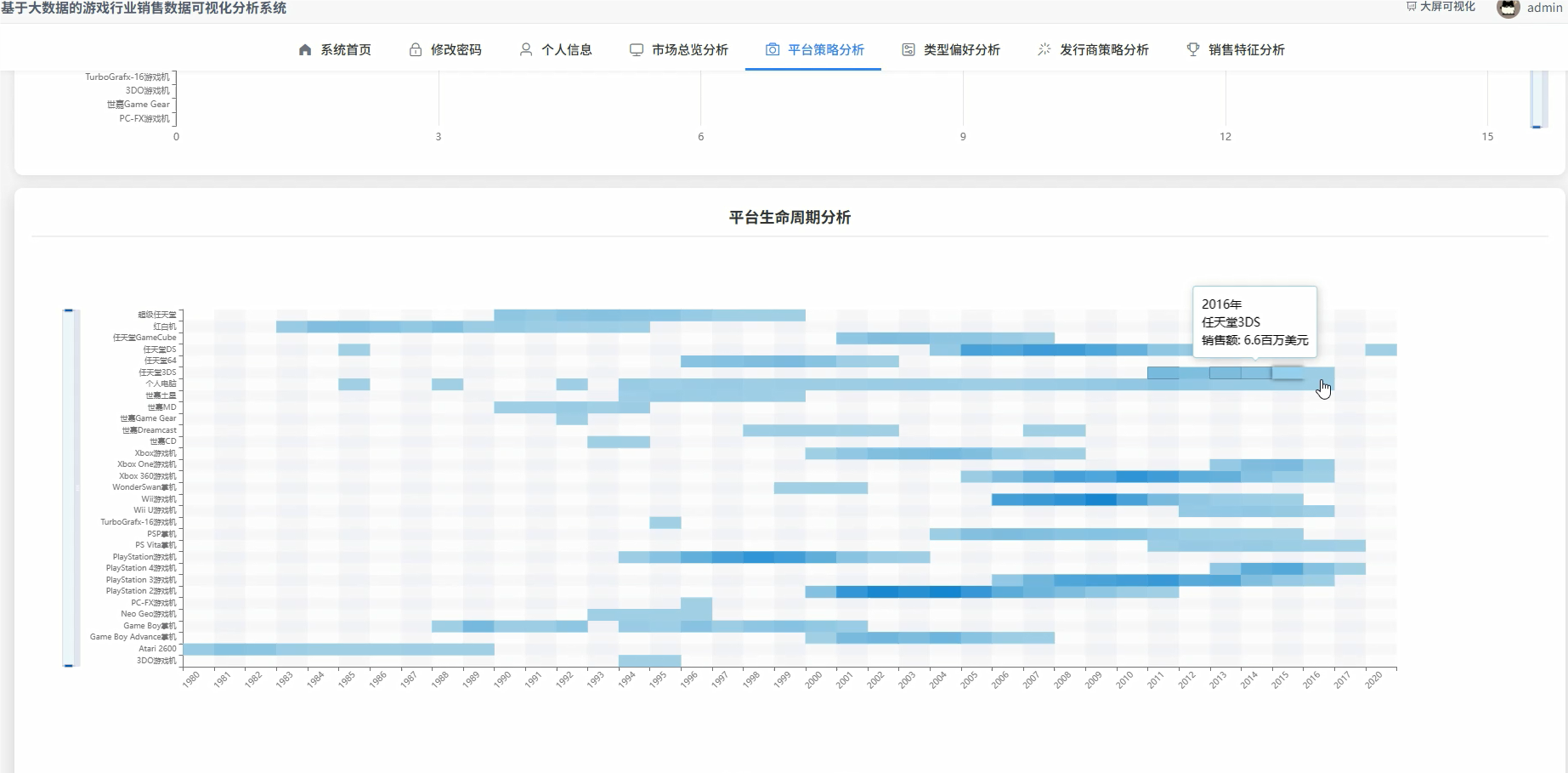
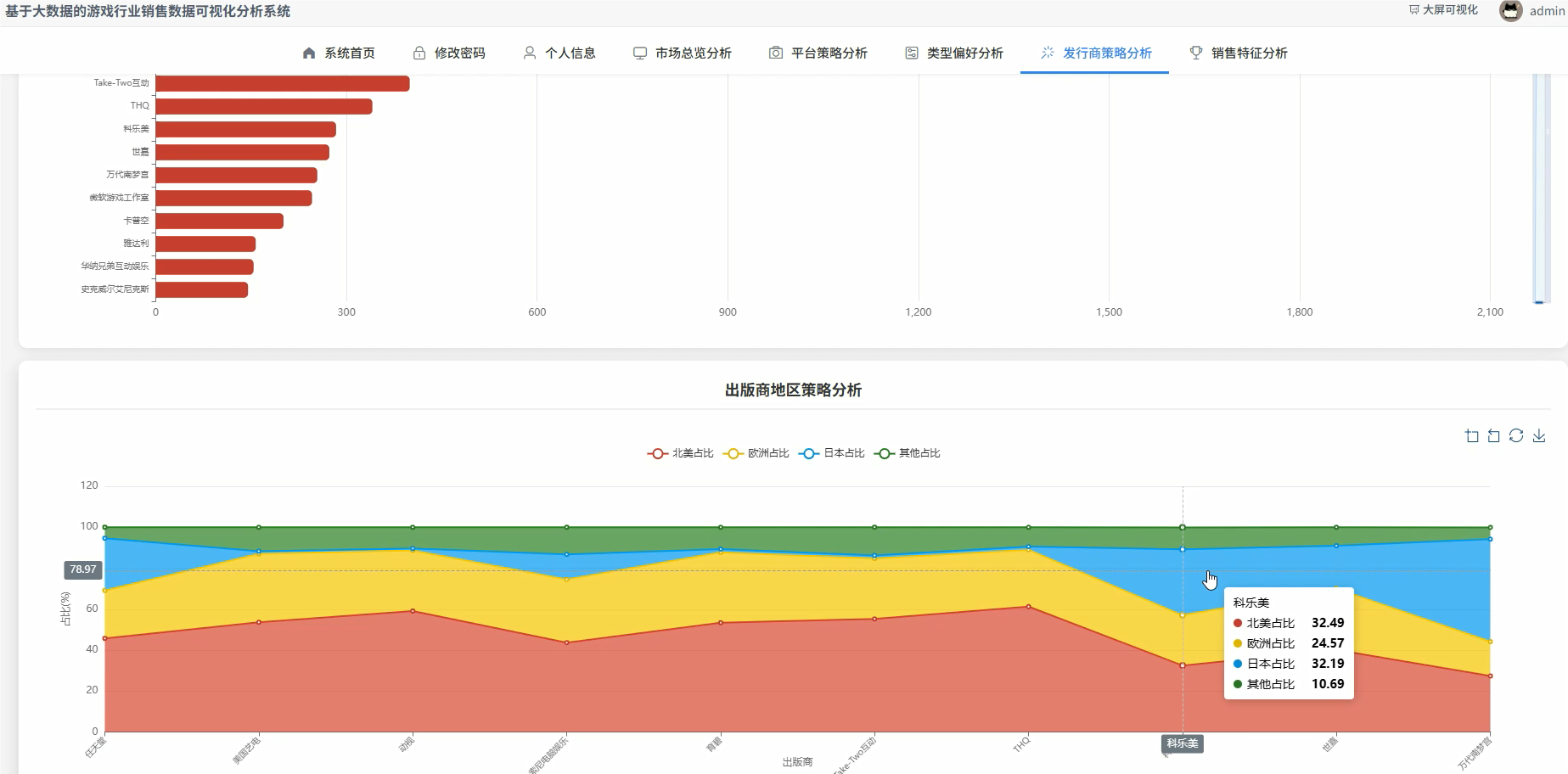
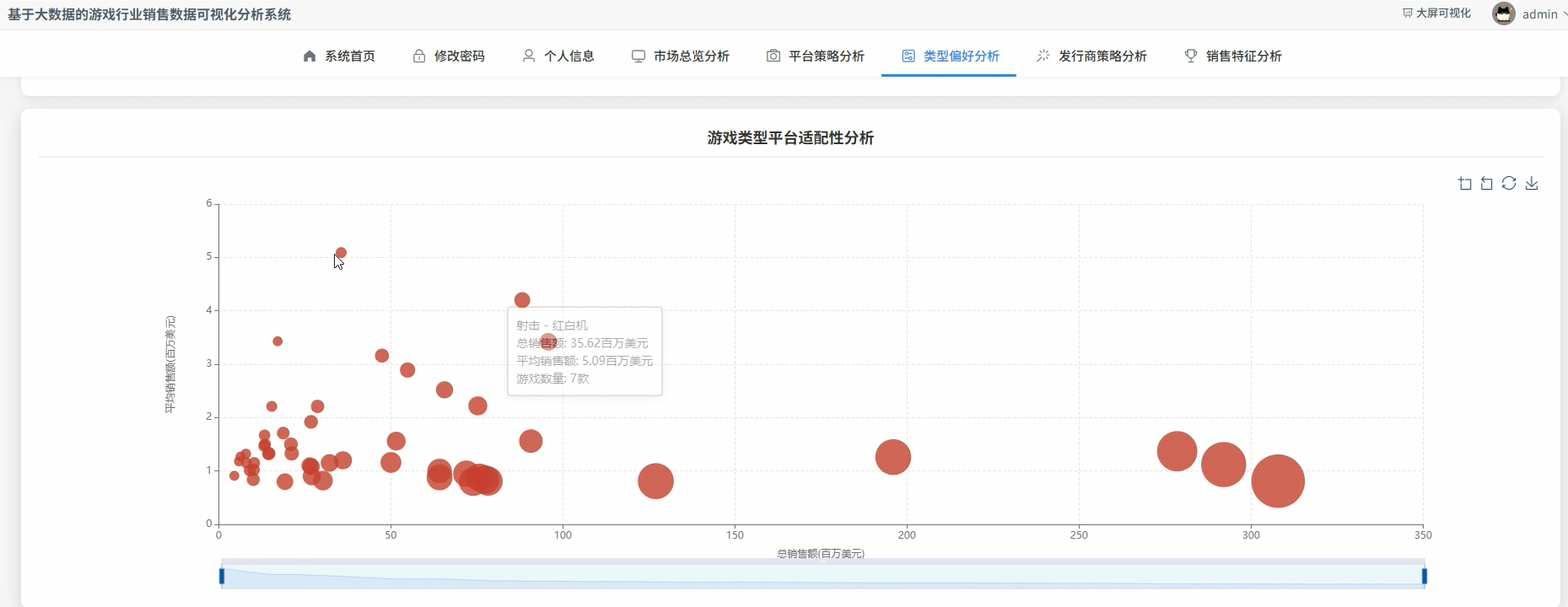
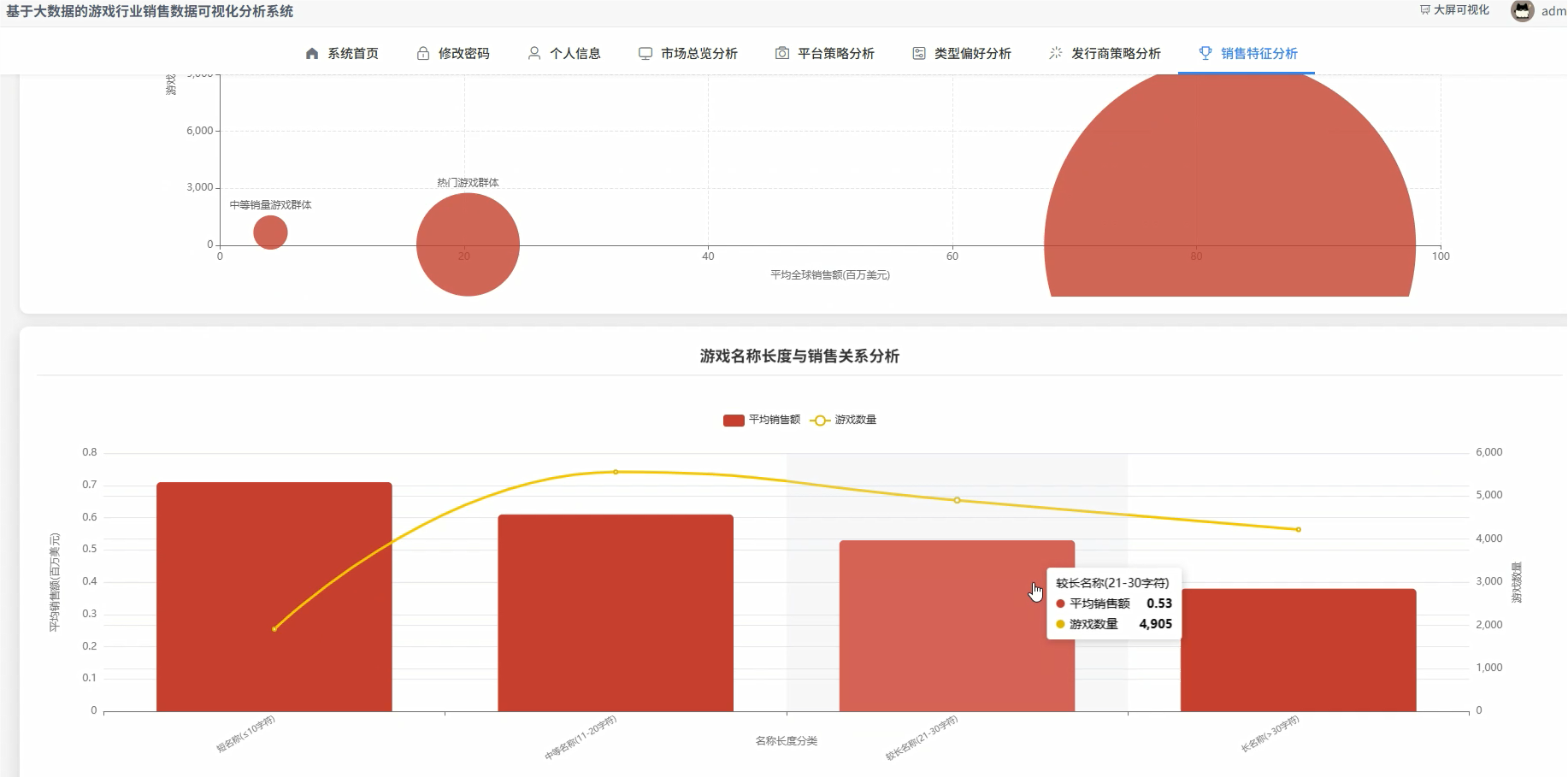
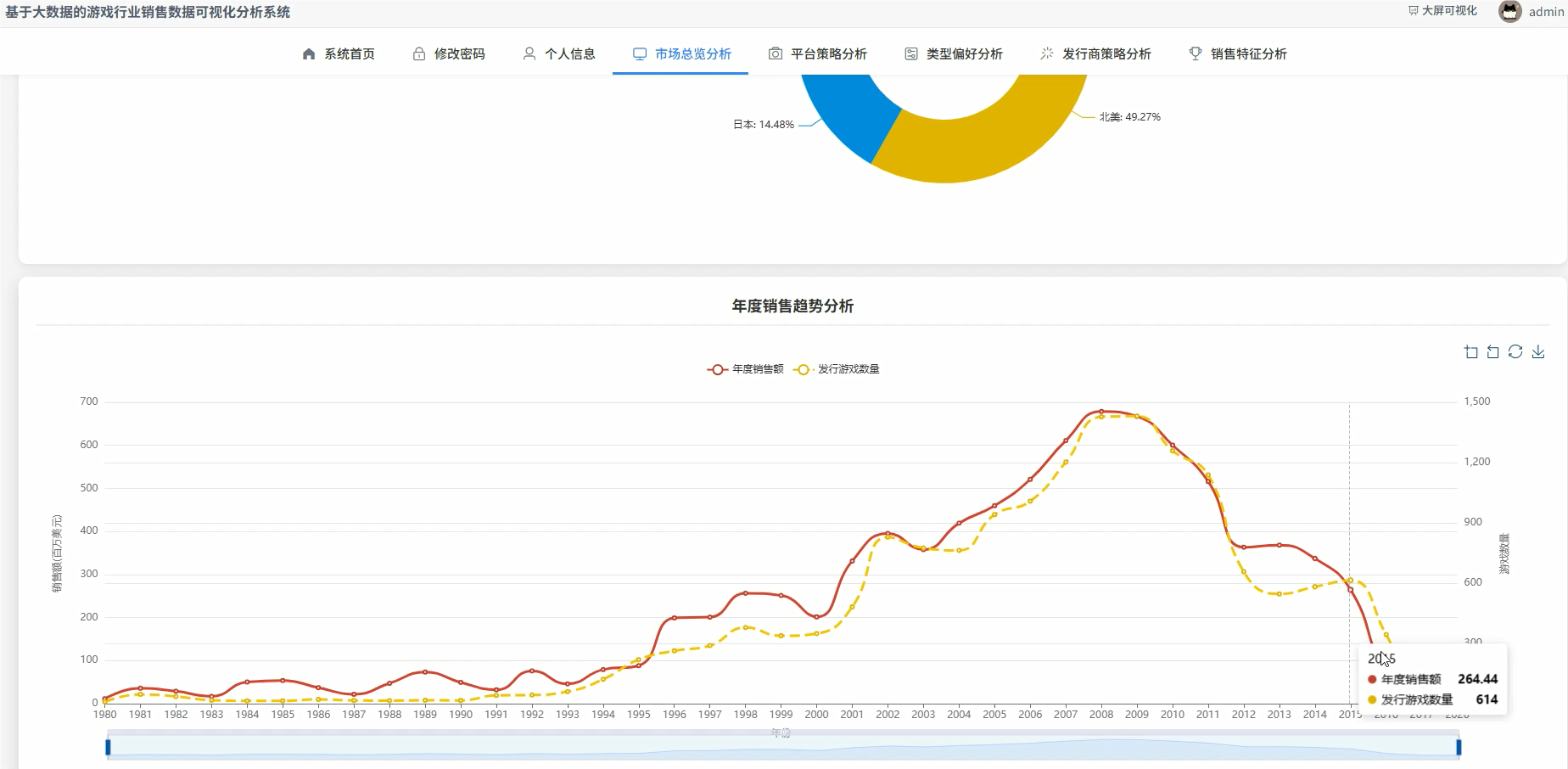
五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum, count, round as spark_round, desc
from pyspark.sql.window import Window
# 假设df是已经加载并预处理好的DataFrame
# df = spark.read.csv("hdfs://path/to/vgsales.csv", header=True, inferSchema=True)
def core_functions_analysis(df):
# 初始化SparkSession
spark = SparkSession.builder.appName("GameSalesCoreAnalysis").getOrCreate()
# 核心功能一:游戏类型偏好与地区差异化分析
# 这个功能分析了不同游戏类型在全球以及北美、欧洲、日本等主要市场的销售表现
# 通过聚合计算,可以直观看出各类游戏在全球的吸金能力以及在不同文化区域的受欢迎程度
genre_sales_df = df.groupBy("Genre") \
.agg(
spark_round(sum("Global_Sales"), 2).alias("TotalGlobalSales"),
spark_round(sum("NA_Sales"), 2).alias("TotalNASales"),
spark_round(sum("EU_Sales"), 2).alias("TotalEUSales"),
spark_round(sum("JP_Sales"), 2).alias("TotalJPSales"),
spark_round(sum("Other_Sales"), 2).alias("TotalOtherSales")
) \
.withColumn("GameCount", count("*").over(Window.partitionBy("Genre"))) \
.orderBy(desc("TotalGlobalSales")) \
.limit(10)
print("------ 游戏类型偏好分析结果 ------")
genre_sales_df.show()
# genre_sales_df.write.csv("hdfs://path/to/genre_preference_analysis.csv", header=True, mode="overwrite")
# 核心功能二:顶级出版商竞争力分析
# 这个功能旨在识别游戏行业的头部玩家,通过统计其发行的游戏数量和总销售额来衡量其市场竞争力
# 使用了聚合、排序和限制数量等操作,模拟了商业报告中常见的Top N分析场景
publisher_competitiveness_df = df.filter(col("Publisher") != "Unknown") \
.groupBy("Publisher") \
.agg(
count("Name").alias("PublishedGamesCount"),
spark_round(sum("Global_Sales"), 2).alias("TotalPublisherSales")
) \
.withColumn("AvgSalesPerGame", spark_round(col("TotalPublisherSales") / col("PublishedGamesCount"), 2)) \
.orderBy(desc("TotalPublisherSales")) \
.limit(20)
print("------ 顶级出版商竞争力分析结果 ------")
publisher_competitiveness_df.show()
# publisher_competitiveness_df.write.csv("hdfs://path/to/publisher_competitiveness_analysis.csv", header=True, mode="overwrite")
# 核心功能三:游戏平台生命周期分析
# 这个功能通过分析各平台在不同年份的游戏发行量和销售额,来探索游戏平台的兴衰规律
# 使用了窗口函数(Window Function),这是一个在Spark中进行复杂时序或分组分析的强大工具
# 它可以计算出每个平台逐年累计的销售额,从而清晰地描绘出其成长、巅峰和衰退的轨迹
window_spec = Window.partitionBy("Platform").orderBy("Year").rowsBetween(Window.unboundedPreceding, Window.currentRow)
platform_lifecycle_df = df.filter(col("Year") != "N/A") \
.groupBy("Platform", "Year") \
.agg(
spark_round(sum("Global_Sales"), 2).alias("YearlySales"),
count("Name").alias("YearlyGamesCount")
) \
.withColumn("CumulativeSales", spark_round(sum("YearlySales").over(window_spec), 2)) \
.withColumn("CumulativeGames", sum("YearlyGamesCount").over(window_spec)) \
.orderBy("Platform", "Year")
print("------ 游戏平台生命周期分析结果 ------")
platform_lifecycle_df.show()
# platform_lifecycle_df.write.csv("hdfs://path/to/platform_lifecycle_analysis.csv", header=True, mode="overwrite")
spark.stop()六、项目文档展示

七、总结
本课题"基于Hadoop的游戏行业销售数据可视化分析系统"的设计与实现工作现已基本完成。整个过程围绕着将前沿的大数据技术应用于具体的业务场景------游戏销售数据分析而展开。在技术实现层面,系统成功地构建了一条完整的数据处理与展示链路:利用Hadoop HDFS作为分布式存储基石,确保了数据的可靠存放;核心分析引擎则采用了性能卓越的Apache Spark框架,通过编写PySpark脚本对高达16600条的游戏销售记录进行了多维度的深度挖掘与计算;后端服务逻辑由Python Django框架驱动,它不仅作为任务调度中心,还承担了数据接口的角色;最终,分析结果借助Vue与Echarts技术栈,以动态交互式图表的形式呈现在Web前端,实现了从原始数据到商业洞察的直观转化。在整个开发过程中,我们不仅克服了数据预处理阶段的空值与格式统一等挑战,还深入实践了不同技术栈之间的整合与协同工作。通过本系统的开发,不仅验证了大数据技术在商业智能分析领域应用的有效性和强大能力,更重要的是,个人在分布式计算、Web全栈开发以及数据可视化等方面的工程实践能力得到了全面且深刻的锻炼,为理解和应用复杂信息系统打下了坚实的基础。尽管系统仍有可优化的空间,例如引入更高级的机器学习算法进行销售预测,但作为一项毕业设计,它已经达到了预期的目标,是一次宝贵的学习与探索经历。
大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖