文章结尾部分有CSDN官方提供的学长 联系方式名片
B站up账号: 麦麦大数据
关注B站,有好处!
编号: F024 KG
视频
neo4j 电影知识图谱+推荐可视化系统 vue + python 协同过滤推荐算法
1 系统简介
系统简介:本系统是一个基于Vue+Flask构建的电影知识图谱可视化与智能推荐系统,集知识图谱展示、电影推荐算法(包括基于用户协同过滤UserCF和基于物品协同过滤ItemCF)以及多维度数据分析于一体。系统核心功能包括:首页展示(系统导航与推荐入口)、电影信息浏览与知识图谱展示、用户协同与物品协同推荐算法模块、电影数据可视化分析(如导演-演员网络、类型热度趋势图、评分分布直方图等),以及用户管理功能。系统通过直观的可视化图表(使用Echarts构建)和互动式知识图谱页面帮助用户理解电影之间的关联、电影潮流趋势及热门题材动态。同时,系统结合协同过滤推荐模型,为用户个性化推荐感兴趣的影片,提升浏览与观影体验。用户可在系统中注册、登录,管理个人资料,查看推荐列表,并对电影进行评分和反馈,提升算法精度与系统互动性。
2 功能设计
系统采用B/S(浏览器/服务器)架构模式,用户通过浏览器访问由Vue.js构建的前端界面,前端核心技术栈包括:Vue.js、Vuex(状态管理)、Vue Router(路由管理)以及ECharts(数据可视化)。前端通过RESTful API与Flask后端交互,完成用户请求的处理与数据返回。Flask后端负责核心业务逻辑的处理,包括推荐算法的运行、用户行为分析、后端接口服务的提供等。后端使用SQLAlchemy连接MySQL数据库,实现用户信息、电影元数据、评分数据和推荐结果的持久化存储与查询。
2.1系统架构图
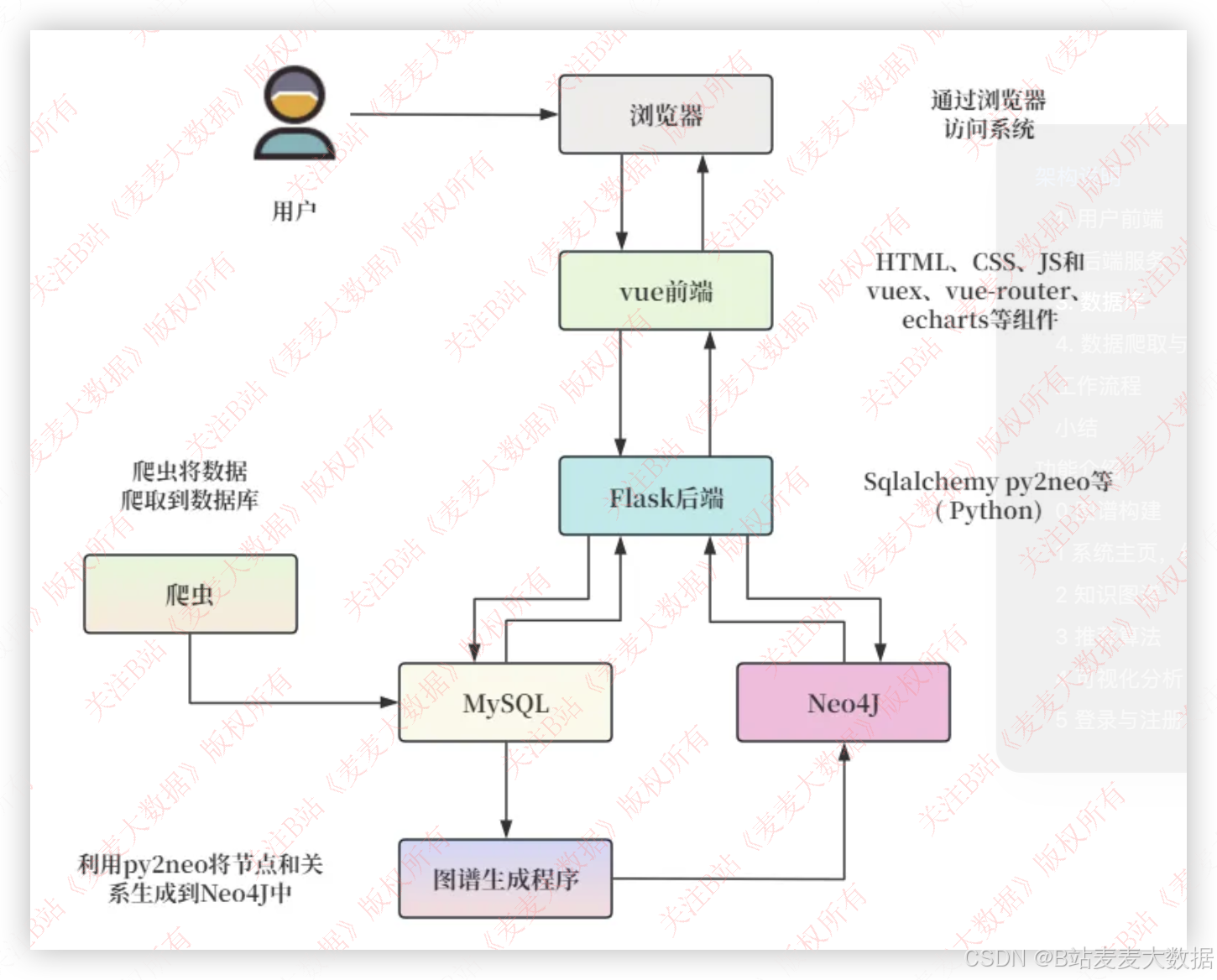
1. 用户前端
用户通过浏览器访问系统,前端采用了基于 Vue.js 的技术栈来构建。
- 浏览器:作为用户与系统交互的媒介,用户通过浏览器进行各种操作,如浏览图书、获取推荐等。
- Vue 前端:使用 Vue.js 框架搭建前端界面,包含 HTML、CSS、JavaScript,以及 Vuex(用于状态管理),vue-router(用于路由管理),和 Echarts(用于数据可视化)等组件。前端向后端发送请求并接收响应,展示处理后的数据。
2. 后端服务
后端服务采用 Flask 框架,负责处理前端请求,执行业务逻辑,并与数据库进行交互。
- Flask 后端:使用 Python 编写,借助 Flask 框架处理 HTTP 请求。通过 SQLAlchemy 与 MySQL 进行交互,通过 py2neo 与 Neo4j 进行交互。后端主要负责业务逻辑处理、 数据查询、数据分析以及推荐算法的实现。
3. 数据库
系统使用了两种数据库:关系型数据库 MySQL 和图数据库 Neo4j。
- MySQL:存储从网络爬取的基本数据。数据爬取程序从外部数据源获取数据,并将其存储在 MySQL 中。MySQL 主要用于存储和管理结构化数据。
- Neo4j:存储图谱数据,特别是用户、图书及其关系(如阅读、写、出版等)。通过利用 py2neo 库将 MySQL 中的数据结构化为图节点和关系,再通过图谱生成程序(可能是一个 Python 脚本)将其导入到 Neo4j 中。
4. 数据爬取与处理
数据通过爬虫从外部数据源获取,并存储在 MySQL 数据库中,然后将数据转换为图结构并存储在 Neo4j 中。
- 爬虫:实现数据采集,从网络数据源抓取相关信息。爬取的数据首先存储在 MySQL 数据库中。
- 图谱生成程序:利用 py2neo 将爬取到的结构化数据(如电影、演员和导演,以及它们之间的关系)从 MySQL 导入到 Neo4j 中。通过构建图谱数据,使得后端能够进行复杂的图查询和推荐计算。
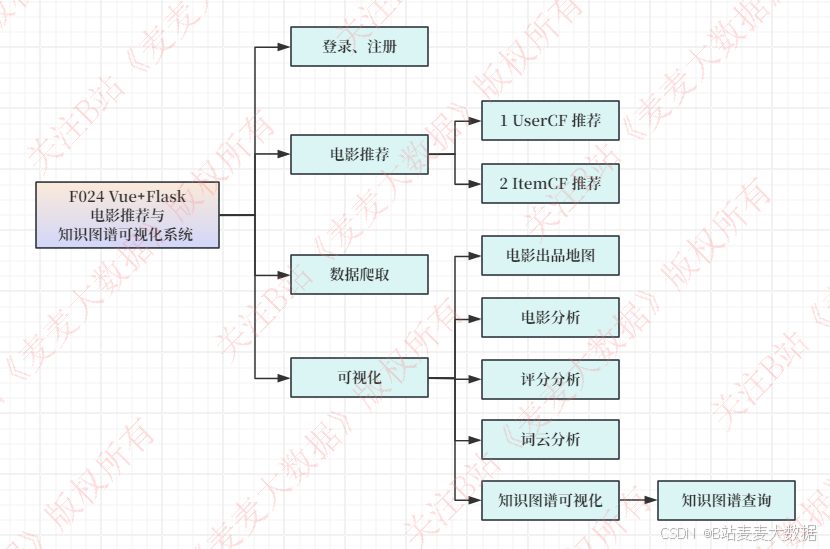
3 功能展示
功能模块图
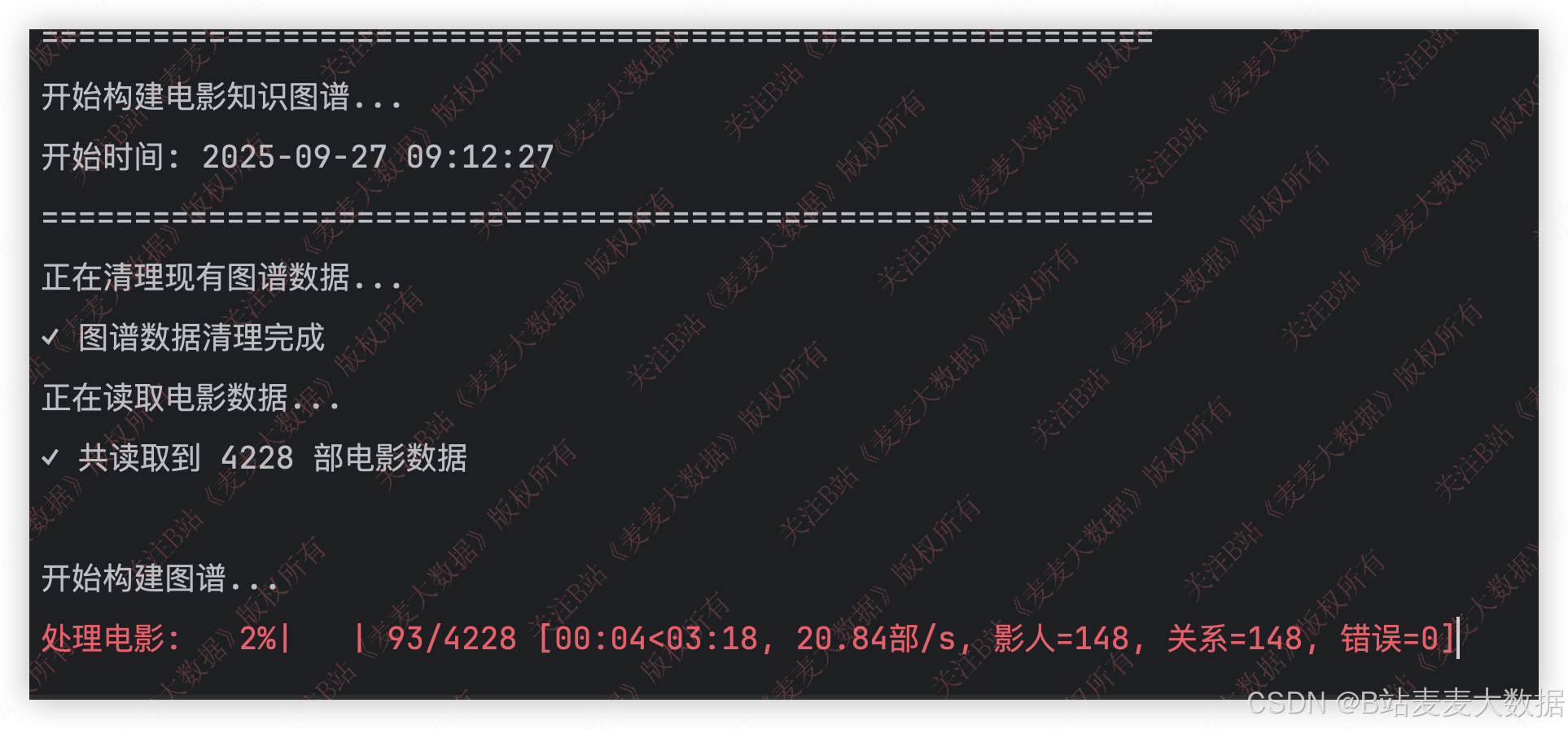
3.1 知识图谱
利用python读取数据并且构建图谱到neo4j中,
支持可视化
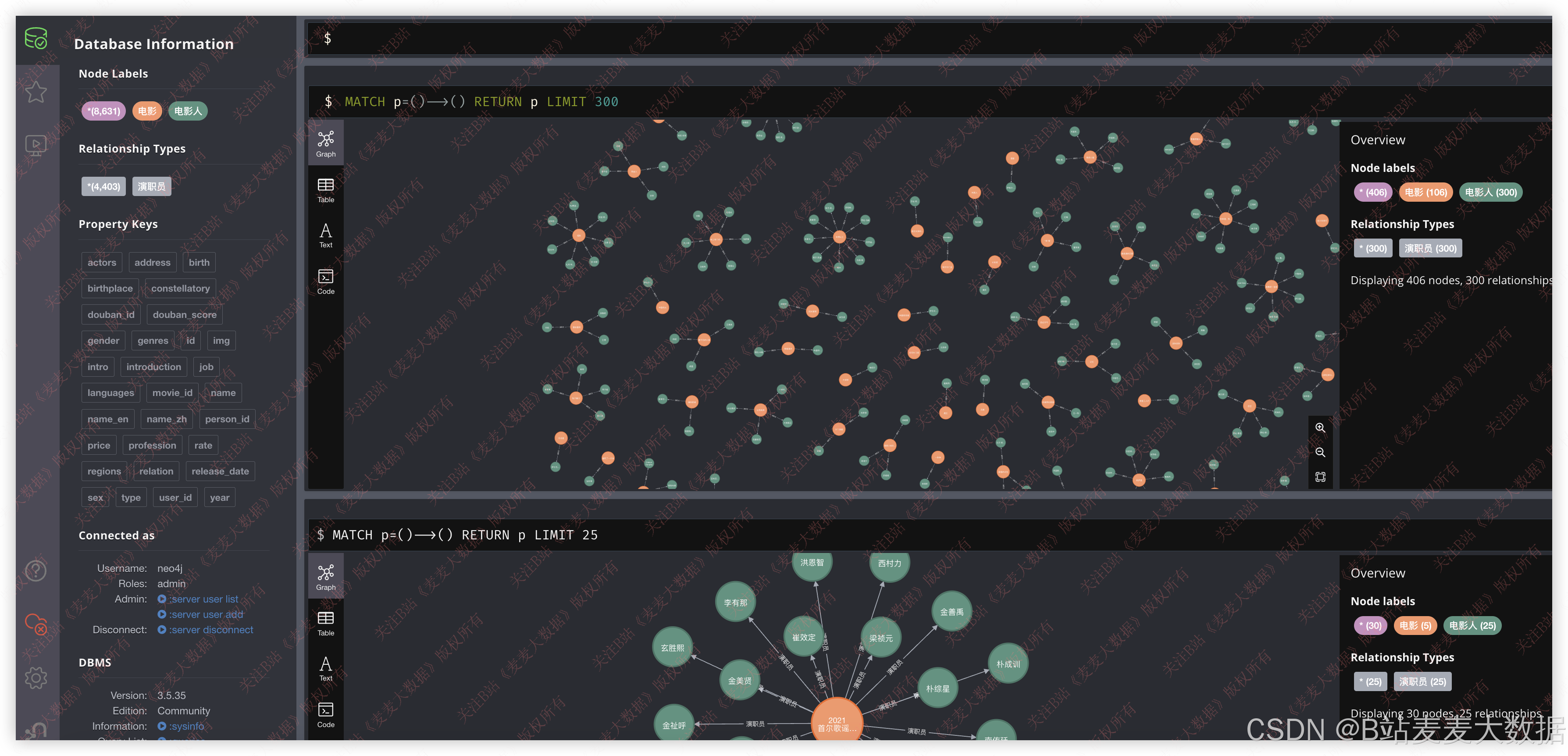
在系统内的可视化界面:
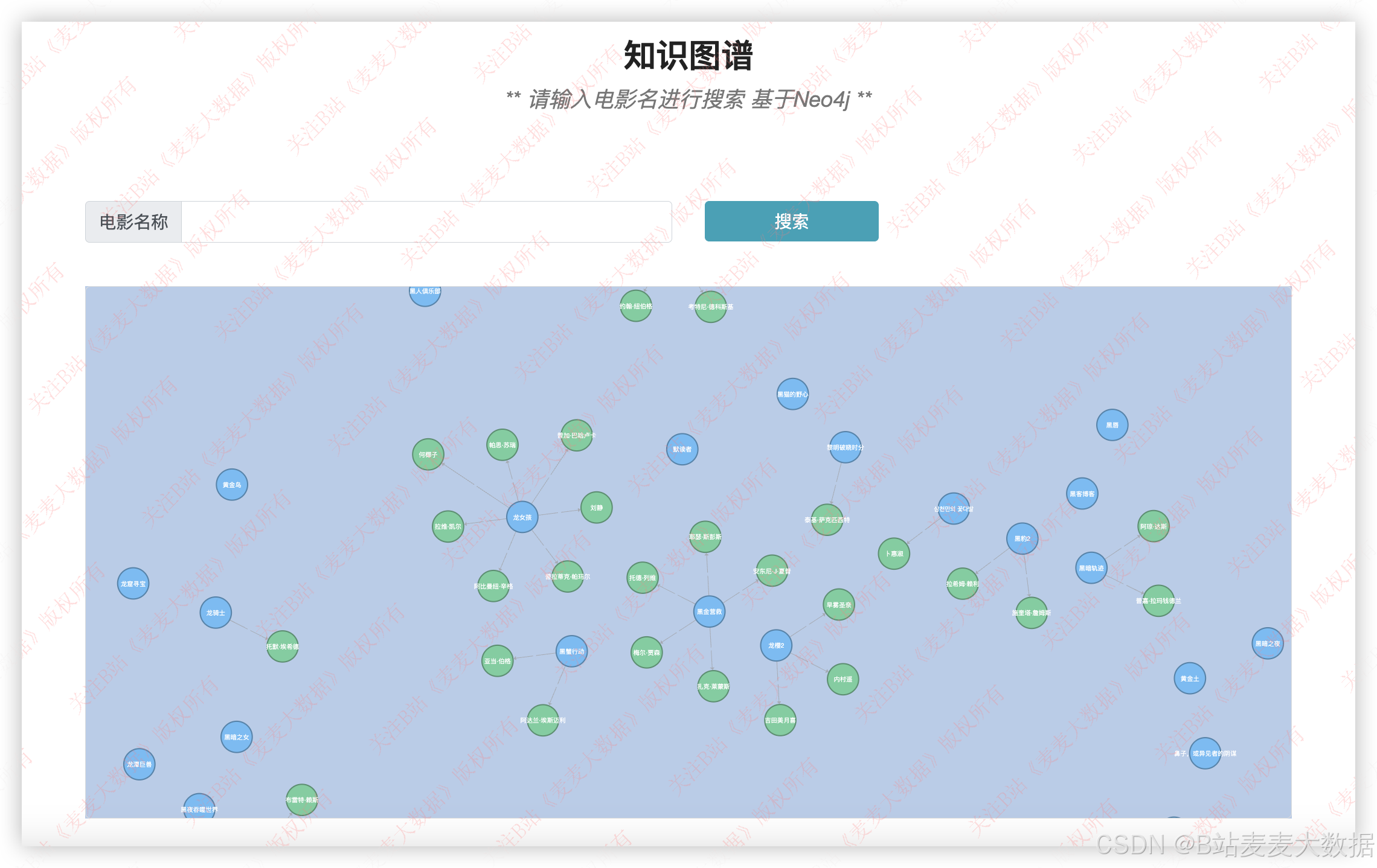
支持模糊搜索,比如搜索关键词:

3.2 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击去登录后者去注册可以切换,背景是一个视频,循环播放。
登录需要验证用户名和密码是否正确,如果不正确会有错误提示 。
注册需要验证用户名是否存在 ,如果错误会有提示。
3.3 主页
主页的布局采用了左侧是菜单,右侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。
数据统计包含了系统内各种类型的电影还有各个国家电影的统计情况:

3.4 推荐算法
算法一 UserCF :

算法二 ItemCF :

3.5 数据分析
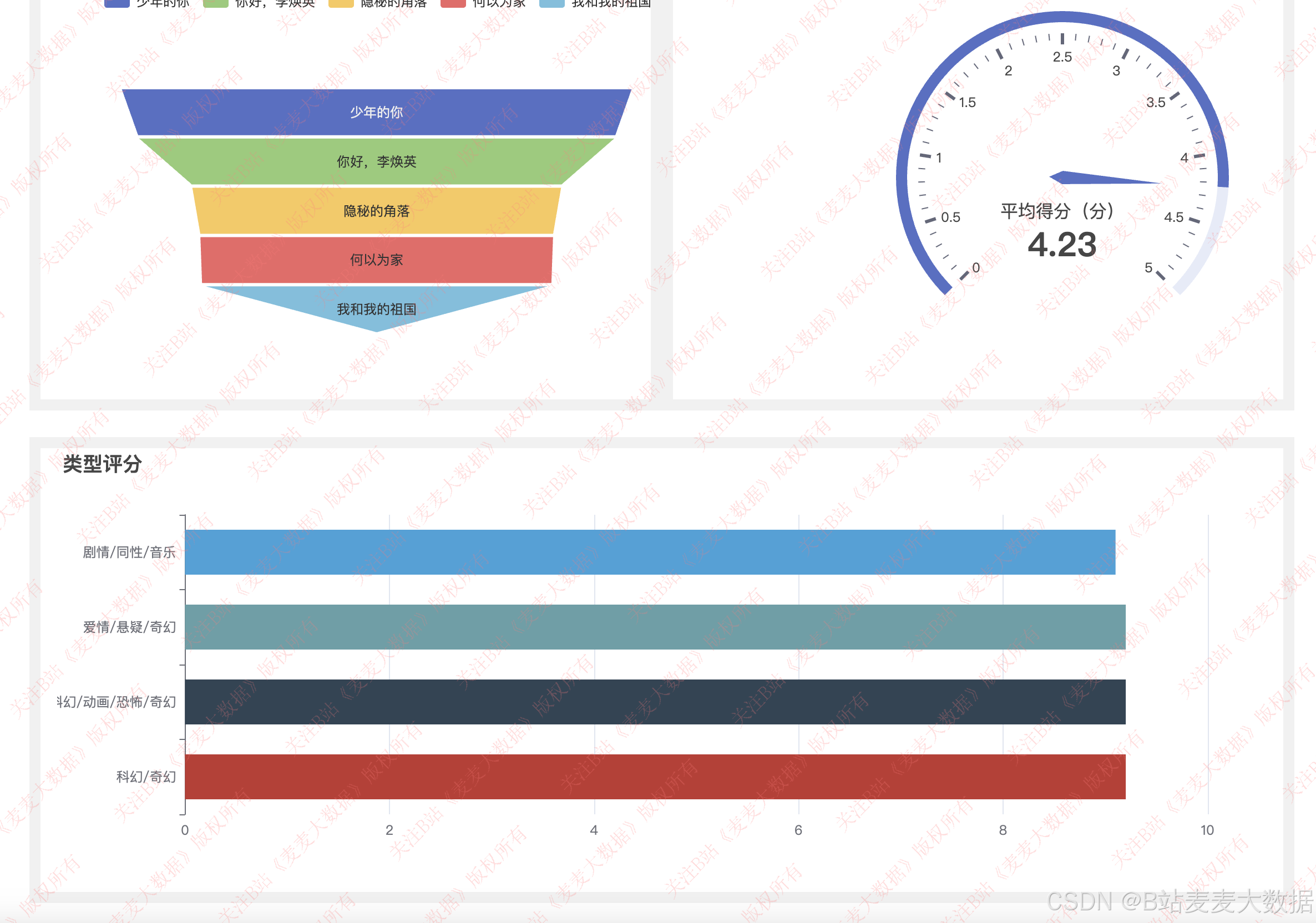
电影分析:
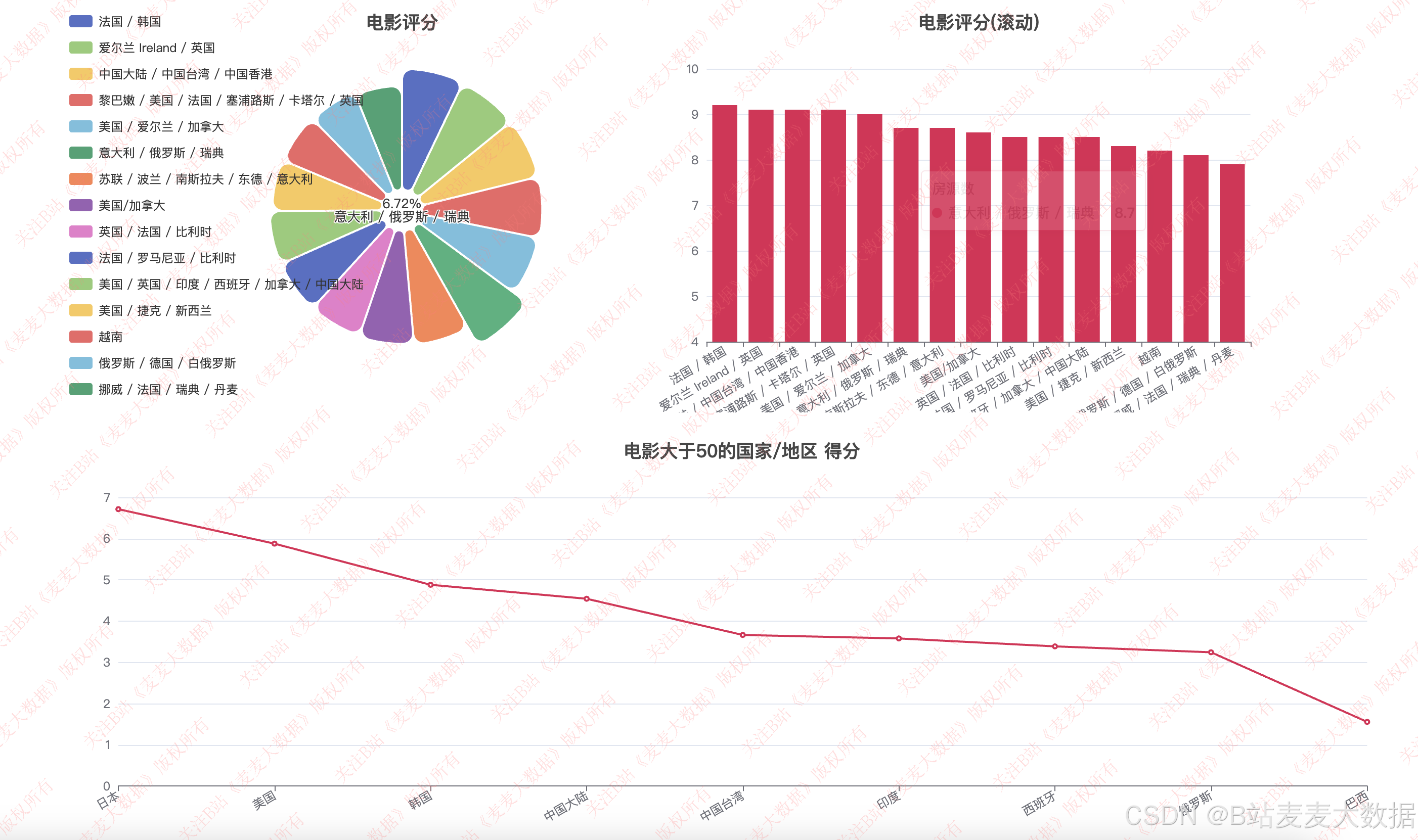
评分分析:
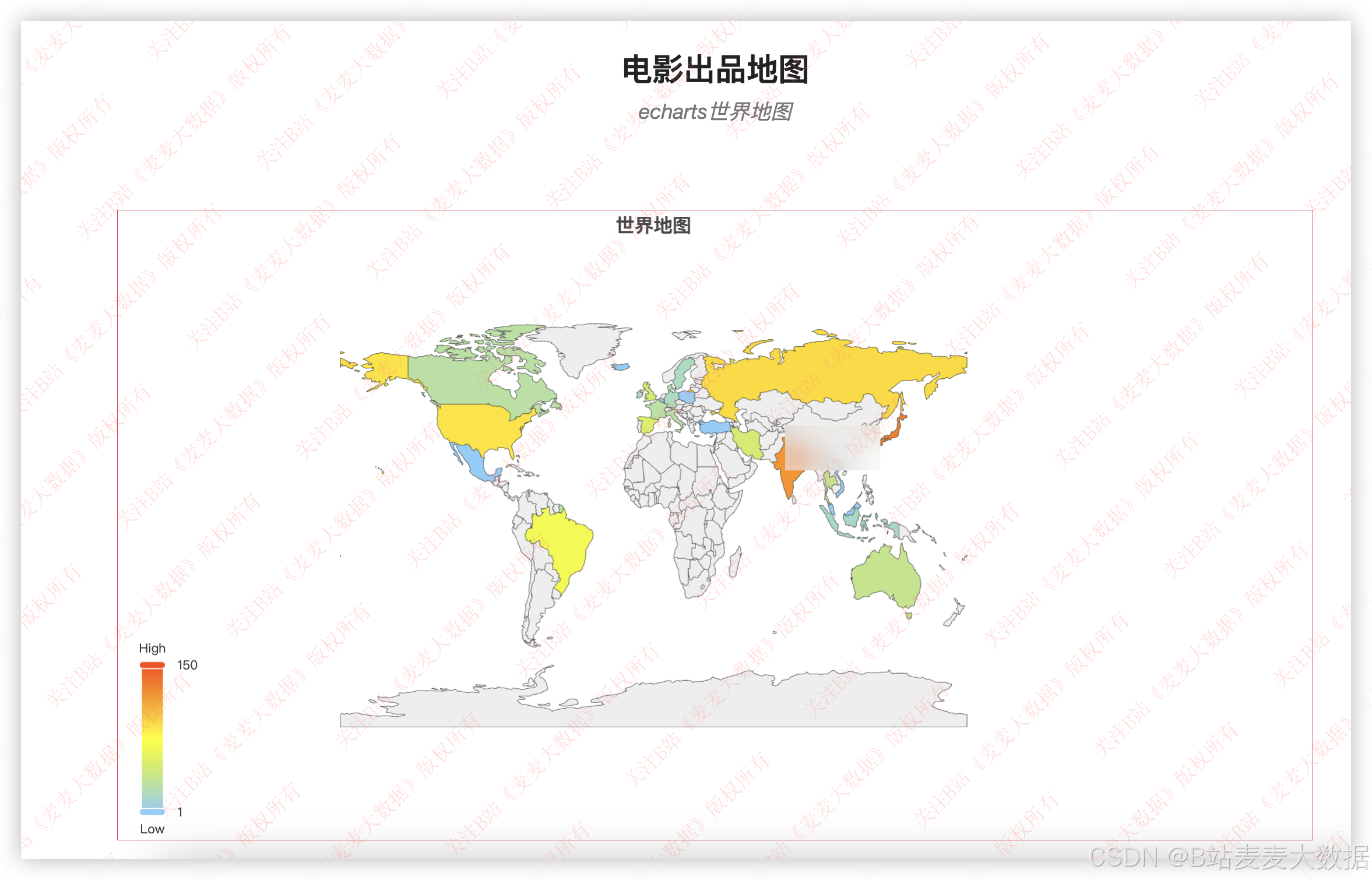
电影地图:
词云分析:

3.7 登录和注册
4程序代码
4.1 代码说明
代码介绍:基于用户的协同过滤)是一种经典的推荐算法,主要思想是:用户喜欢相似的物品,那么相似的用户也会喜欢相似的物品。具体来说,UserCF通过分析用户的历史行为数据(如评分、点击、观看等)来计算用户之间的相似度,找到和目标用户兴趣相似的其他用户,然后将这些相似用户喜欢的物品推荐给目标用户。
在豆瓣电影数据中,users 对 movies 进行评分(1~5分),我们可以使用UserCF算法计算用户间的相似度(如余弦相似度),并基于相似用户喜欢但当前用户未评分的电影为当前用户推荐。
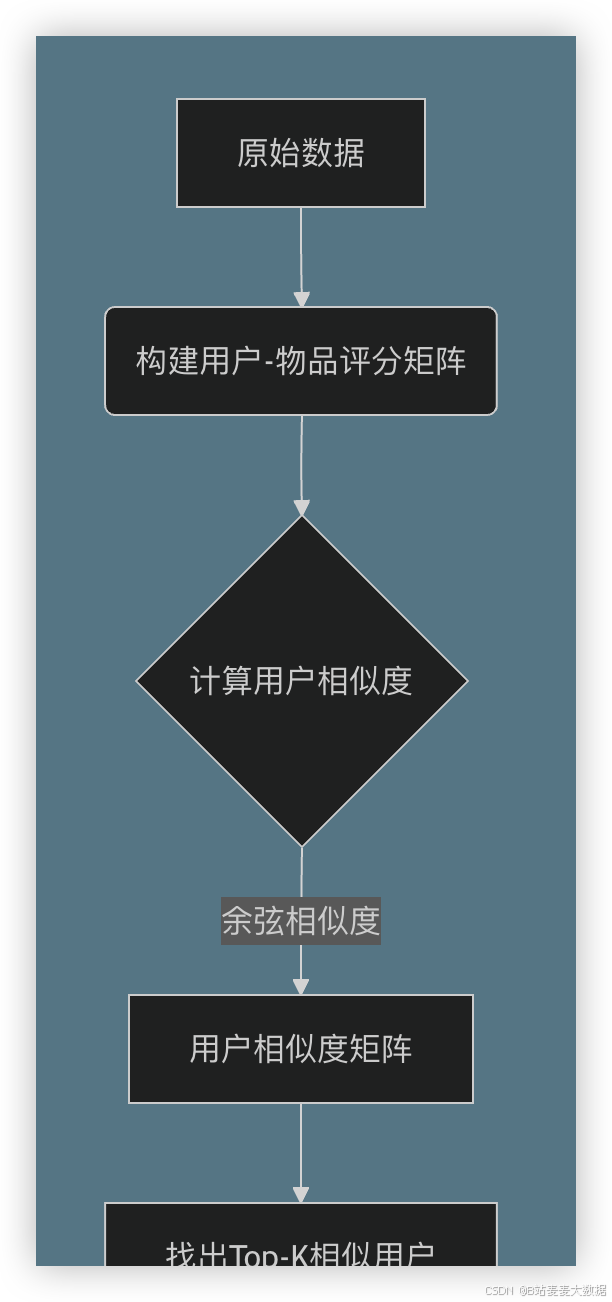
UserCF的两个关键步骤:① 构建用户-物品评分矩阵;② 计算用户相似度,生成推荐。
此推荐系统适用于场景:连续评分数据可用,且需要个性化的推荐结果,却不依赖复杂模型。
4.2 流程图
4.3 代码实例
python
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# --- Step 1: 加载数据 ---
def load_data(file_path):
df = pd.read_csv(file_path)
return df
# --- Step 2: 构建用户-电影评分矩阵 ---
def build_user_item_matrix(df):
user_item_matrix = df.pivot_table(index='user_id', columns='item_id', values='rating')
# 填充空缺评分为空评
user_item_matrix = user_item_matrix.fillna(0)
return user_item_matrix
# --- Step 3: 计算用户相似度(使用余弦相似度)---
def calc_user_similarity(matrix, method='cosine'):
"""
:param method: cosine or pearson
"""
if method == 'cosine':
similarity = cosine_similarity(matrix)
else:
matrix = matrix.values
mean_ratings = np.mean(matrix, axis=1, keepdims=True)
centered = matrix - mean_ratings
similarity = cosine_similarity(centered)
return pd.DataFrame(similarity, index=matrix.index, columns=matrix.index)
# --- Step 4: 预测目标用户对未评分电影的兴趣 ---
def predict_ratings(similarity_df, user_item_matrix, user_id, k=20):
user_ratings = user_item_matrix.loc[user_id]
non_rated_movies = user_ratings[user_ratings == 0].index # 找未评分的电影
similar_users = similarity_df[user_id].sort_values(ascending=False).index[1:k+1] # 排除自己,选Top-k用户
scores = {}
for movie in non_rated_movies:
weighted_sum = 0
similarity_sum = 0
for other_user in similar_users:
rating = user_item_matrix.loc[other_user, movie]
sim = similarity_df.loc[user_id, other_user]
if rating > 0:
weighted_sum += rating * sim
similarity_sum += abs(sim)
if similarity_sum > 0:
scores[movie] = weighted_sum / similarity_sum
else:
scores[movie] = 0
return scores
# --- Step 5: 推荐电影 ---
def recommend_movies(predicted_scores, top_n=5):
return sorted(predicted_scores.items(), key=lambda x: x[1], reverse=True)[:top_n]
# --- Main函数 ---
def user_cf_recommendation(csv_path, target_user, k=20, top_n=5):
# Step 1: 加载数据
df = load_data(csv_path)
# Step 2: 构建评分矩阵
user_item_matrix = build_user_item_matrix(df)
# Step 3: 计算用户相似度
user_similarity = calc_user_similarity(user_item_matrix)
# Step 4: 推荐电影
predicted_scores = predict_ratings(user_similarity, user_item_matrix, target_user, k)
# Step 5: 排名并返回推荐
recommendations = recommend_movies(predicted_scores, top_n=top_n)
return recommendations
# --- 示例调用 ---
if __name__ == "__main__":
# 示例数据文件路径需要改为实际文件路径
movie_ratings_path = "movieratings.csv"
target_user = "A1" # 替换为目标用户ID
k = 5 # 相似用户数量
top_n = 3 # 预测中推荐前N个未评分的电影
recommendations = user_cf_recommendation(movie_ratings_path, target_user, k, top_n)
print("为用户 {} 推荐如下电影:{}".format(target_user, recommendations))