注意:该项目只展示部分功能,如需了解,文末咨询即可。
本文目录
- [1 开发环境](#1 开发环境)
- [2 系统设计](#2 系统设计)
- [3 系统展示](#3 系统展示)
- [3.1 功能展示视频](#3.1 功能展示视频)
- [3.2 大屏页面](#3.2 大屏页面)
- [3.3 分析页面](#3.3 分析页面)
- [3.4 基础页面](#3.4 基础页面)
- [4 更多推荐](#4 更多推荐)
- [5 部分功能代码](#5 部分功能代码)
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
分布式存储与计算:采用Hadoop作为底层分布式文件系统(HDFS),解决海量图书数据的存储问题。在此基础上,利用Spark作为核心计算引擎,通过其基于内存的计算特性,对数据进行高效的ETL(抽取、转换、加载)操作。具体研究包括使用PySpark对原始CSV文件中格式混乱、包含大量无效值和缺失值的字段(如出版时间、价格、页数)进行标准化清洗、类型转换和特征提取(如从作者字段中提取国籍)。
数据分析与挖掘:基于处理后的规整数据,利用Spark SQL和DataFrame API执行多维度的聚合统计与关联分析。同时,引入机器学习算法,研究使用K-Means聚类对图书进行市场定位分群,将图书划分为"高分热门"、"高分冷门"等类别,实现对图书价值的深度挖掘。
数据持久化与服务:将Spark分析得出的结构化结果数据存储于MySQL关系型数据库中。MySQL作为成熟稳定的数据库,负责为前端提供快速、可靠的数据查询服务,充当后端大数据平台与前端可视化应用的桥梁。
前端可视化与交互:采用Vue.js作为前端开发框架,构建单页面应用(SPA),实现动态、响应式的用户界面。深度集成Echarts图表库,研究如何将MySQL中的分析结果以丰富多样的图表形式(如柱状图、折线图、散点图、词云图等)进行可视化呈现,并提供用户交互功能,使用户能够直观地探索数据。
2 系统设计
随着互联网的快速发展,豆瓣读书等平台积累了海量的用户行为与图书信息数据。然而,这些原始数据往往存在格式不一、信息缺失、噪音干扰等问题,其背后蕴含的商业与文化价值难以被直接发掘。本系统正是在此背景下,旨在利用以Hadoop和Spark为核心的大数据技术栈,对庞杂的豆瓣读书数据进行高效的清洗、处理与深度分析,并通过现代化的Web技术(Vue、Echarts)构建一个直观、交互式的可视化平台。其意义在于,不仅能为广大读者提供多维度的图书发现指南,辅助其进行阅读决策,也能为出版行业从业者、作者及研究人员揭示市场动态、读者偏好和内容趋势,从而实现数据驱动的精准决策,最大化挖掘图书数据的潜在价值。
系统功能模块的设计紧密围绕需求分析展开,旨在从宏观到微观,多角度、全方位地揭示豆瓣读书数据的内在规律。
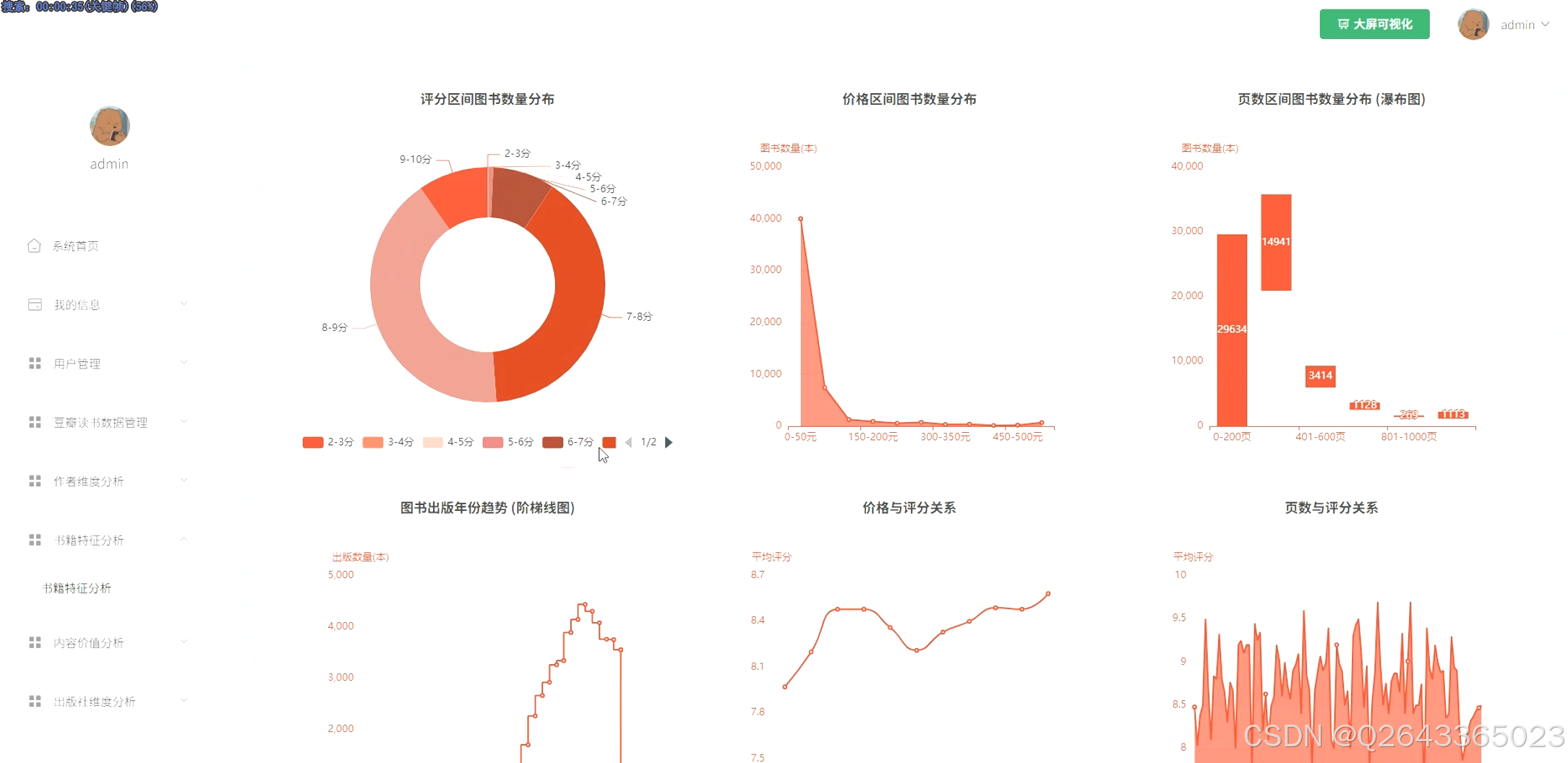
总体图书特征分析模块:此模块从全局视角探索图书市场的整体面貌。功能包括:不同评分、价格、页数区间的图书数量分布统计;图书出版年份的趋势分析;以及价格、页数与评分之间的关联性探究,旨在揭示图书的基本属性分布与潜在联系。
核心实体(作者与出版社)分析模块:此模块聚焦于市场中的关键参与者。功能包括:对作者和出版社进行TOP N排行分析(高产、高评分、最受欢迎);基于作者国籍进行作品数量与质量的跨文化比较;并对核心出版社的出版物书名进行高频词分析,以洞察其市场定位与题材偏好。
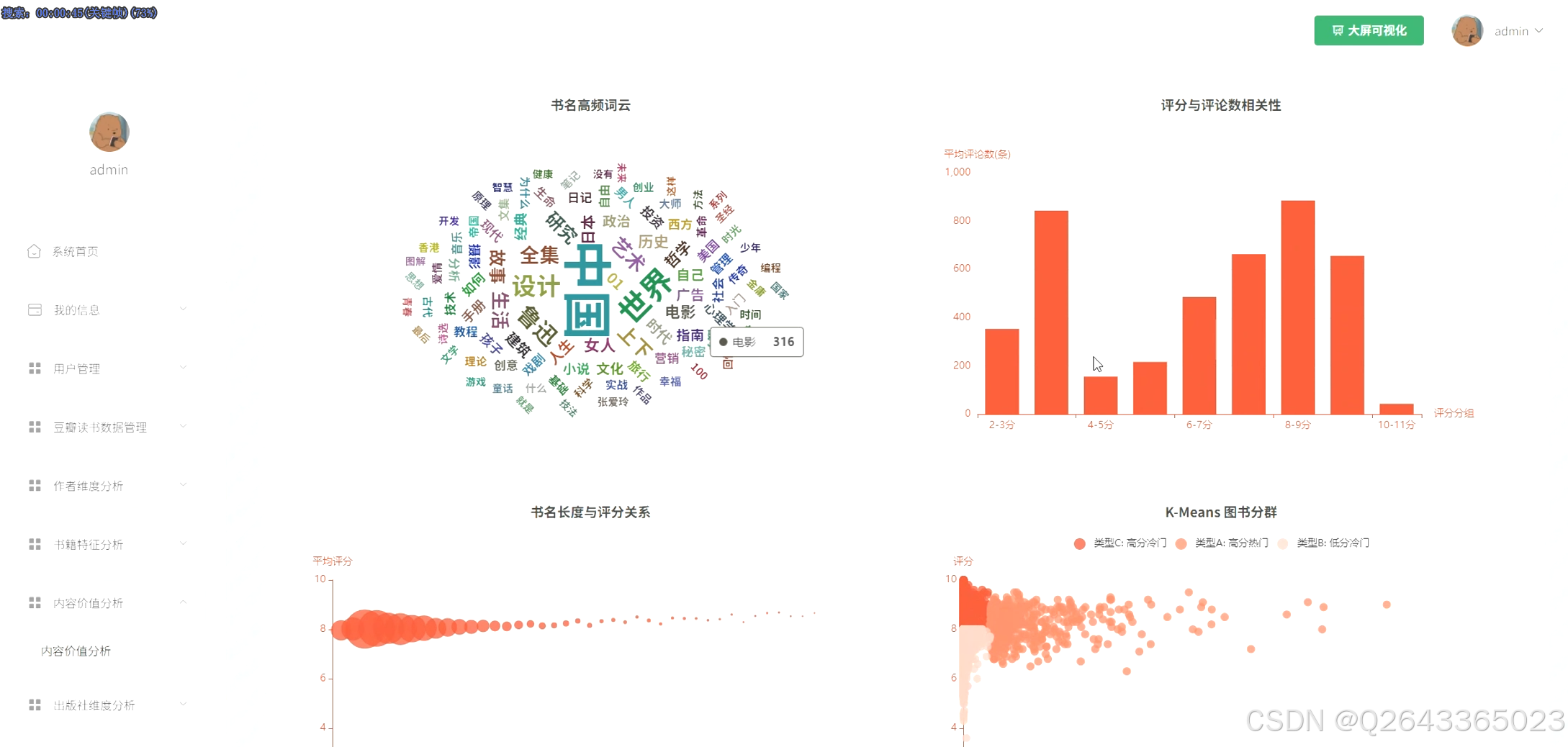
图书内容与价值探索模块:此模块深入挖掘图书本身的特性及其市场反响。功能包括:通过书名生成词云图,直观展示热门主题;分析评分与评论数的相关性,验证"好评"与"热度"的关系;并利用K-Means聚类算法对图书进行用户分群,为读者和出版社提供更精细化的数据洞察。
3 系统展示
3.1 功能展示视频
基于spark大数据的豆瓣读书数据分析与可视化系统毕设源码
3.2 大屏页面
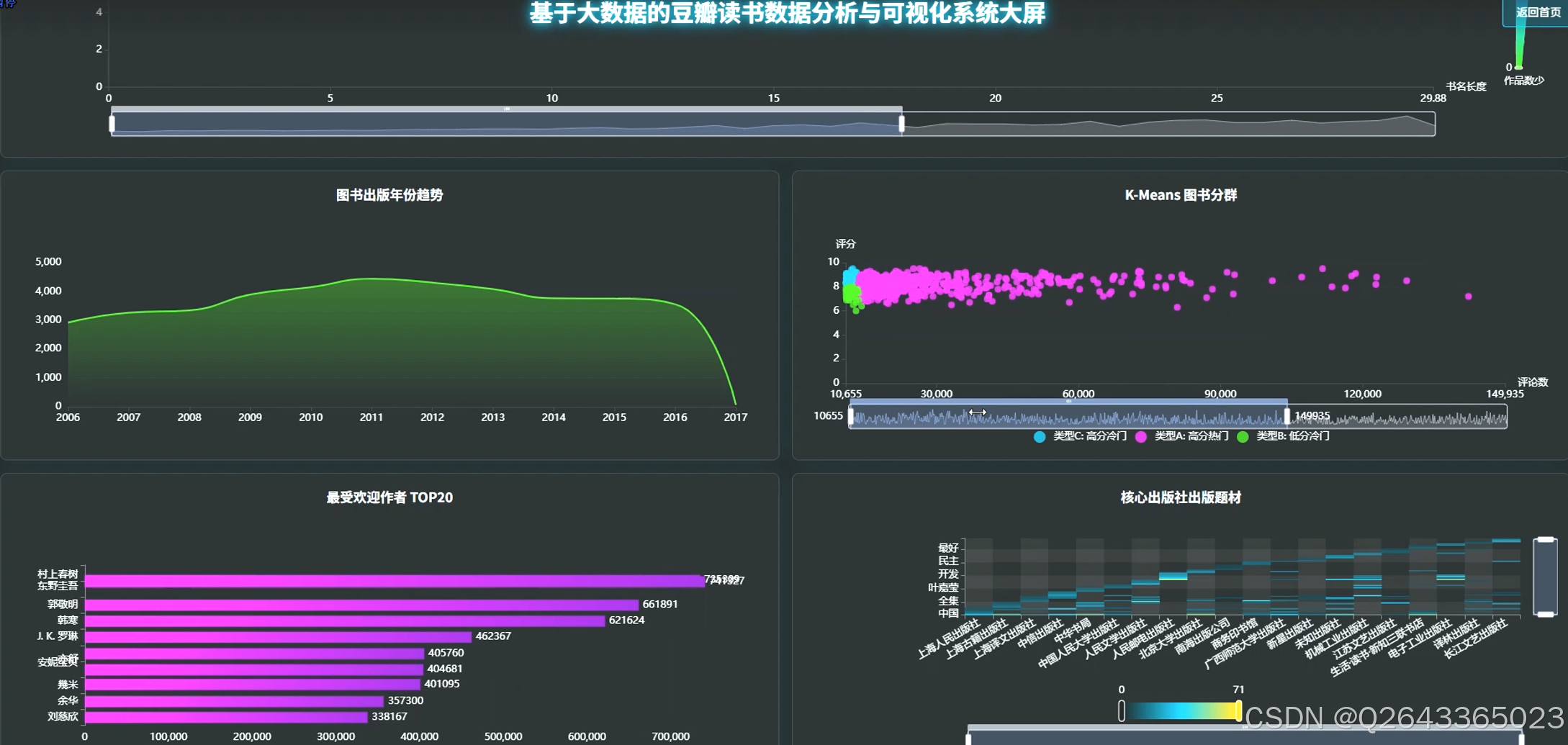
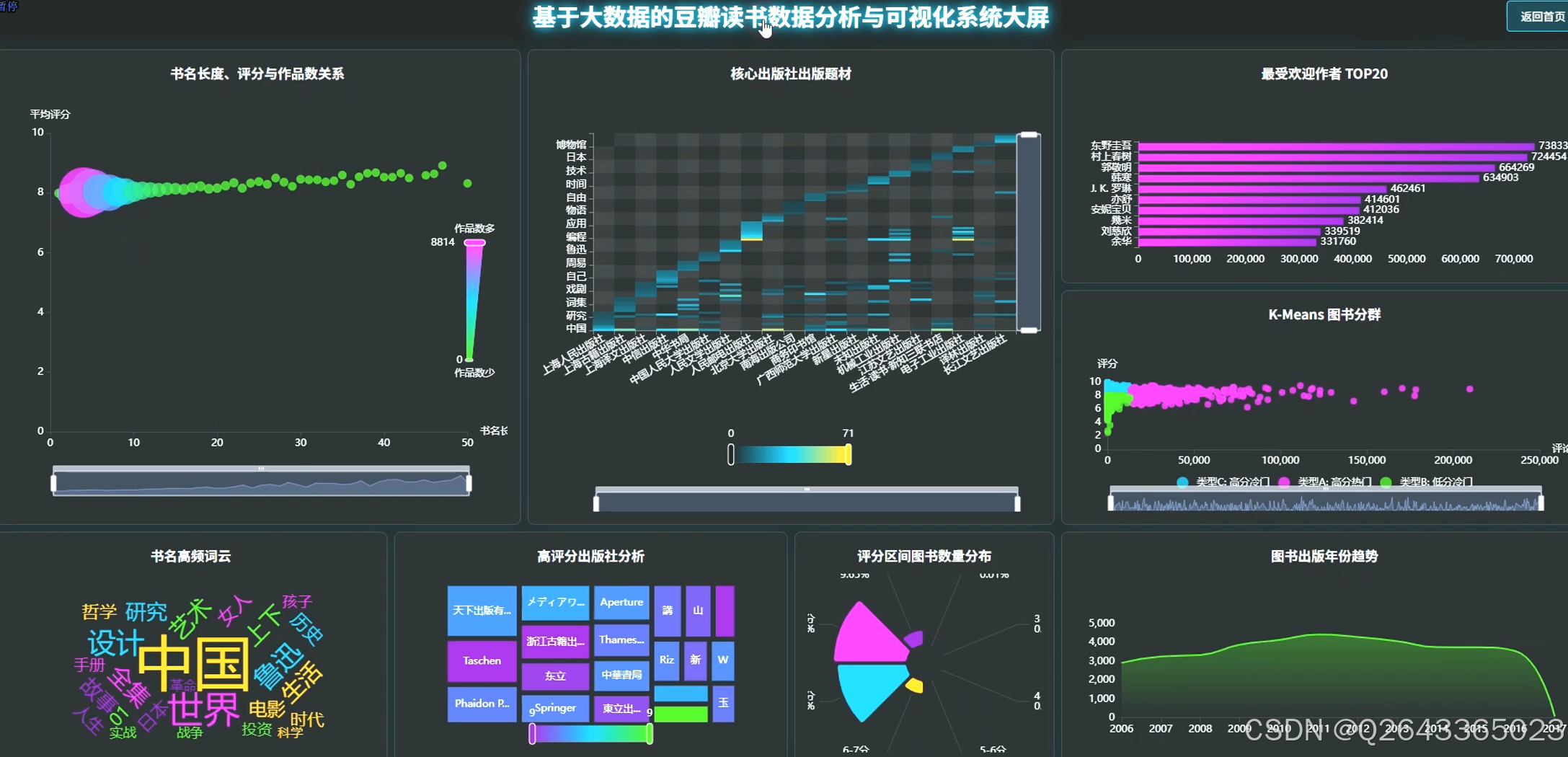
3.3 分析页面
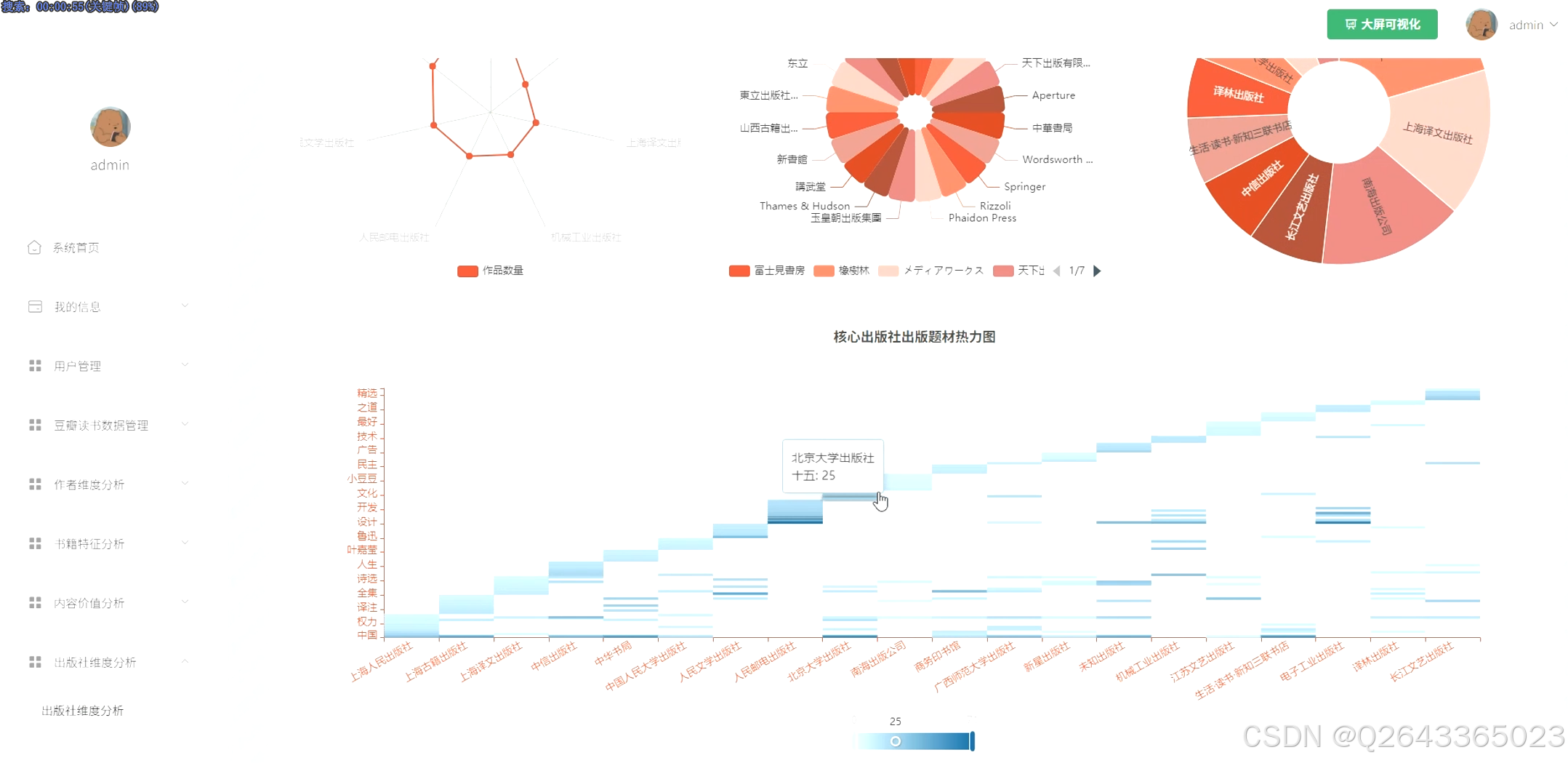
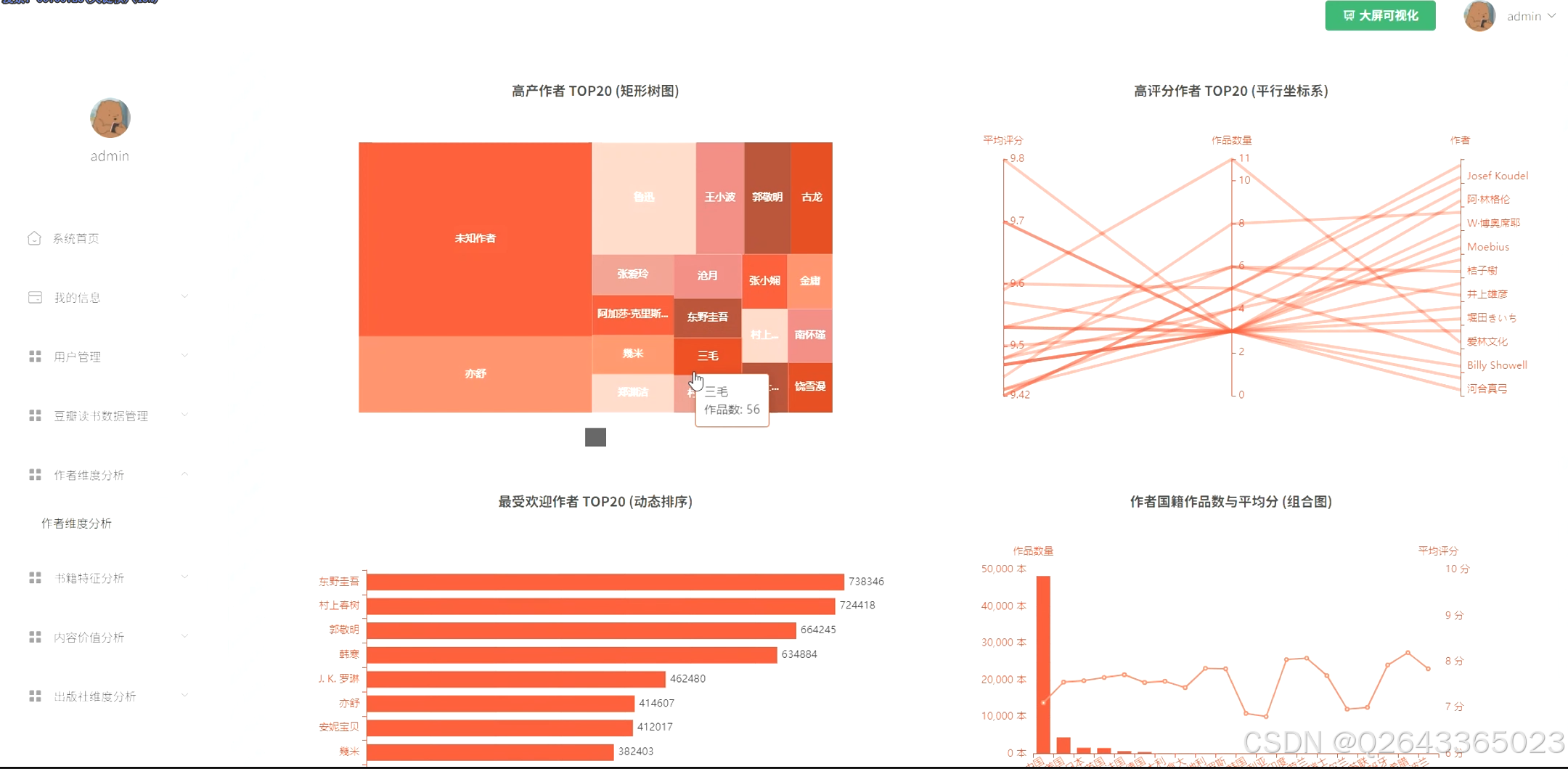
3.4 基础页面

4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
纯分享!2026届计算机毕业设计选题全攻略(选题+技术栈+创新点+避坑),这80个题目覆盖所有方向,计算机毕设选题大全收藏
【有源码】基于Hadoop生态的大数据共享单车数据分析与可视化平台-基于Python与大数据的共享单车多维度数据分析可视化系统
5 部分功能代码
python
"""
数据预处理核心函数:对原始DataFrame进行清洗、转换和特征工程。
:param raw_df: 原始的、未处理的Spark DataFrame。
:return: 清洗和转换后的Spark DataFrame。
"""
# 1. 字段重命名:将中文列名映射为英文,便于后续处理
preprocessed_df = raw_df.withColumnRenamed("书名", "title") \
.withColumnRenamed("作者", "author") \
.withColumnRenamed("出版社", "publisher") \
.withColumnRenamed("出版时间", "publish_date") \
.withColumnRenamed("数", "pages") \
.withColumnRenamed("价格", "price") \
.withColumnRenamed("ISBM", "isbn") \
.withColumnRenamed("评分", "rating") \
.withColumnRenamed("评论数量", "review_count")
# 2. 过滤无效数据:移除书名为"点击上传封面图片"的无效行
preprocessed_df = preprocessed_df.filter(col("title") != "点击上传封面图片")
# 3. 清洗与转换核心字段
preprocessed_df = preprocessed_df.withColumn(
# 提取出版年份:使用正则表达式优先匹配四位数字年份
"publish_year", regexp_extract(col("publish_date"), "(\d{4})", 1)
).withColumn(
# 清洗价格:移除除数字和小数点外的所有字符
"price", regexp_replace(col("price"), "[^0-9.]", "")
).withColumn(
# 清洗页数:移除所有非数字字符
"pages", regexp_replace(col("pages"), "[^0-9]", "")
)
# 4. 特征提取:从作者字段中提取国籍,并清洗原作者字段
preprocessed_df = preprocessed_df.withColumn(
# 提取中括号内的国籍信息作为新列
"author_country", regexp_extract(col("author"), "\[(.*?)\]", 1)
).withColumn(
# 从原作者字段中移除国籍信息
"author", regexp_replace(col("author"), "\[(.*?)\]", "")
)
# 5. 统一填充缺失值 (None/Null)
# 对字符型字段填充为'未知'
preprocessed_df = preprocessed_df.na.fill("未知", ["author", "publisher"])
preprocessed_df = preprocessed_df.withColumn("author_country", when(col("author_country") == "", "未知").otherwise(col("author_country")))
# 对数值型字段填充为0
preprocessed_df = preprocessed_df.na.fill(0, ["pages", "price", "rating", "review_count"])
# 6. 数据类型转换:将清洗后的字段转换为正确的数值类型
final_df = preprocessed_df.withColumn("pages", col("pages").cast(IntegerType())) \
.withColumn("price", col("price").cast(DoubleType())) \
.withColumn("rating", col("rating").cast(DoubleType())) \
.withColumn("review_count", col("review_count").cast(IntegerType())) \
.withColumn("publish_year", col("publish_year").cast(IntegerType()))
return final_df
def kmeans_cluster_analysis(preprocessed_df):
"""
K-Means聚类分析核心函数:基于评分和评论数对图书进行分群。
:param preprocessed_df: 经过预处理的Spark DataFrame。
:return: 包含聚类结果和簇含义的Spark DataFrame。
"""
# 1. 核心过滤:进行聚类分析前,必须过滤掉评分为0或评论数为0的无效数据
# 这是保证聚类结果有意义的关键步骤
df_filtered = preprocessed_df.filter((col("rating") > 0) & (col("review_count") > 0))
# 2. 特征工程:将'rating'和'review_count'合并为特征向量
# K-Means算法要求输入为向量格式
assembler = VectorAssembler(inputCols=["rating", "review_count"], outputCol="features_raw")
df_vector = assembler.transform(df_filtered)
# 3. 特征缩放:由于'rating'和'review_count'量纲差异巨大,必须进行标准化
# 否则评论数大的样本会主导聚类结果,评分基本不起作用
scaler = StandardScaler(inputCol="features_raw", outputCol="features", withStd=True, withMean=False)
scaler_model = scaler.fit(df_vector)
df_scaled = scaler_model.transform(df_vector)
# 4. 模型训练:创建K-Means模型实例并进行训练
# 设置k=4,期望将图书分为四类;设置seed保证每次运行结果一致
kmeans = KMeans(featuresCol="features", k=4, seed=1)
model = kmeans.fit(df_scaled)
# 5. 执行预测:将聚类标签(簇ID)添加到DataFrame中
predictions = model.transform(df_scaled)
# 6. 簇心解读与映射:计算每个簇的评分和评论数均值,以解释其业务含义
centroids_df = predictions.groupBy("prediction").agg(
avg("rating").alias("avg_rating"),
avg("review_count").alias("avg_review_count")
).orderBy("prediction")
# 根据每个簇的均值,手动为其打上业务标签
# 例如,找到评分和评论数均值都高的簇,标记为'高分热门'
# (此处的映射逻辑是示例,实际应根据centroids_df的输出结果动态确定)
# 假设通过观察centroids_df得到以下映射关系:
# 簇0: 高分高评论 -> 高分热门
# 簇 1: 高分低评论 -> 高分冷门
# 簇 2: 低分低评论 -> 低分冷门
# 簇 3: 低分高评论 -> 低分热门
predictions = predictions.withColumn("cluster_meaning",
when(col("prediction") == 0, "高分热门")
.when(col("prediction") == 1, "高分冷门")
.when(col("prediction") == 2, "低分冷门")
.when(col("prediction") == 3, "低分热门")
.otherwise("未知分类")
)
# 7. 整理并返回最终结果
result_df = predictions.select("title", "author", "publisher", "rating", "review_count", "prediction", "cluster_meaning")源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓