回顾知识
一)RAG工作流程
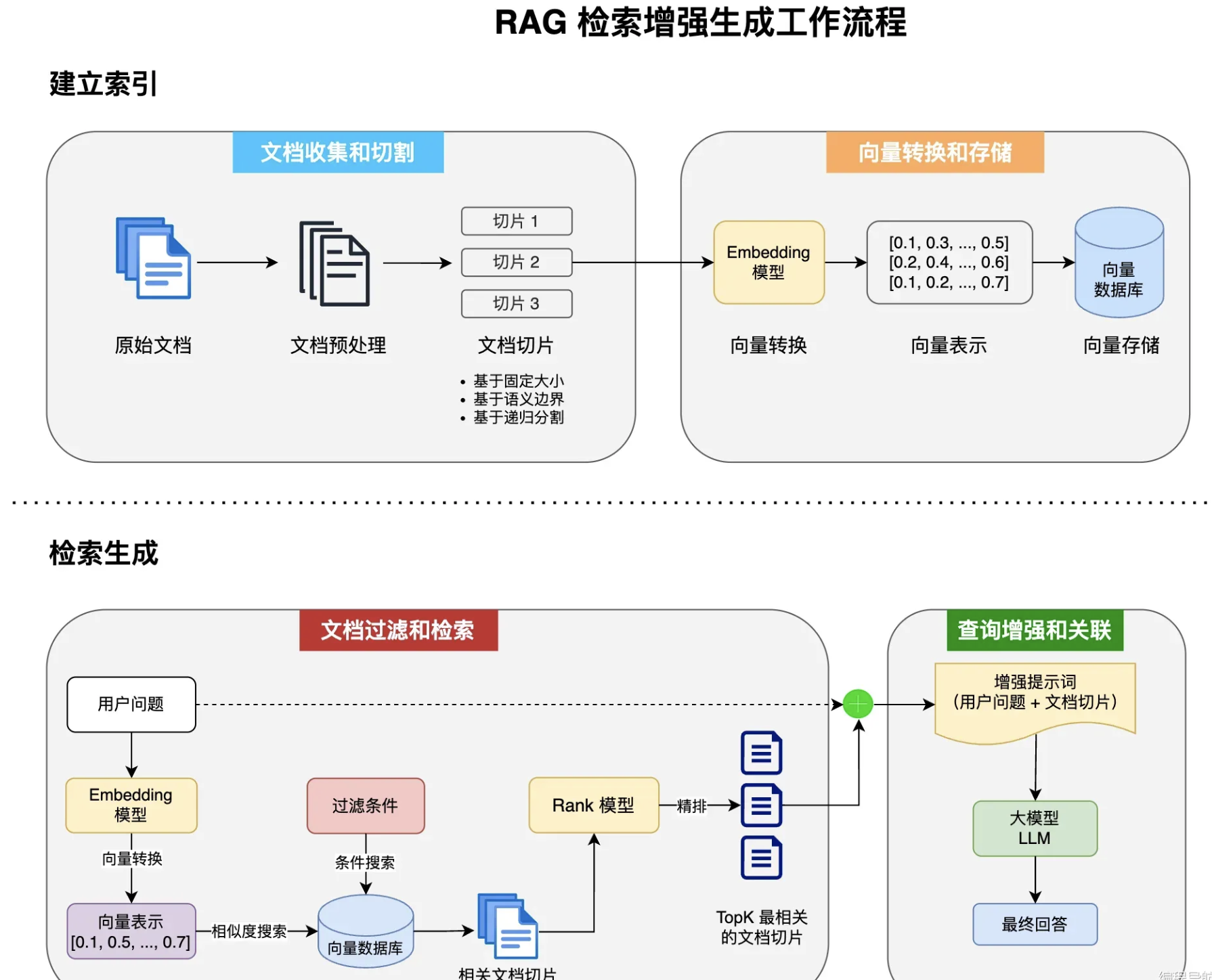
1 )文档收集和切割(ETL)
- 步骤:读取、转换、写入
- 需要掌握的三大组件:DocumentReader、DocumentTransformer、DocumentWriter
DocumentReader
主要负责从各种数据源读取数据并转换为 Document 对象集合。
SpringAi使用方法说明:https://docs.spring.io/spring-ai/reference/api/etl-pipeline.html#_documentreaders
实现了多种文档读取方式,如:JSON/html/Text/markdown/pdf
同时SpringAi Alibaba也提供了其他读取文档的方式:https://java2ai.com/docs/1.0.0-M6.1/integrations/documentreader
学习实现自定义文档抽取方式地址:https://github.com/alibaba/spring-ai-alibaba/tree/main/community/document-readers
java
/*
* 源码,实现了Supplier类,
*/
package org.springframework.ai.document;
import java.util.List;
import java.util.function.Supplier;
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}DocumentTransfore
负责将一组文档转换为另一组文档
三种转换方式:
textSplitter(文本分割器)
metadataEnricher(元信息增强器)
ContentFormatter 内容格式化工具
- 源码
java
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
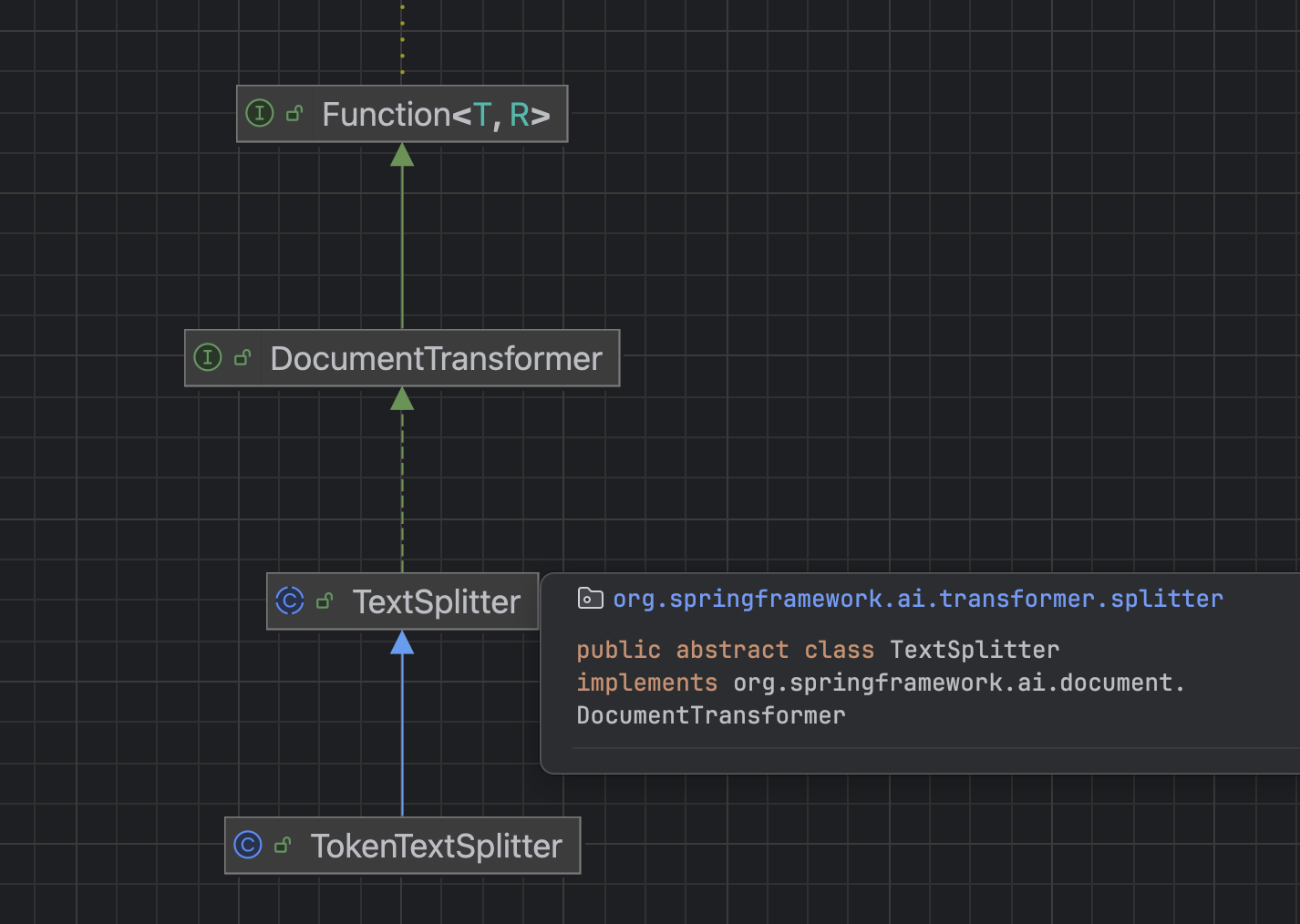
}- TextSplitter类
- 实现了DocumentTransformer
- 是文本分割器的基类,提供了分割单词的流程方法
- TokenTestSplitter
- 继承了TestSplitter
- 基于 Token 的文本分割器。它考虑了语义边界(比如句子结尾)来创建有意义的文本段落,是成本较低的文本切分方式。
java
TokenTextSplitter 提供了两种构造函数选项:
TokenTextSplitter():使用默认设置创建分割器。
TokenTextSplitter(int defaultChunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks, boolean keepSeparator):使用自定义参数创建分割器,通过调整参数,可以控制分割的粒度和方式,适应不同的应用场景。
参数说明:
defaultChunkSize:每个文本块的目标大小(以 token 为单位,默认值:800)。
minChunkSizeChars:每个文本块的最小大小(以字符为单位,默认值:350)。
minChunkLengthToEmbed:要被包含的块的最小长度(默认值:5)。
maxNumChunks:从文本中生成的最大块数(默认值:10000)。
keepSeparator:是否在块中保留分隔符(如换行符)(默认值:true)。- 自定义TokeTestSplitter
java
package cn.varin.varaiagent.rag.splitter;
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class MyTokenTextSplitter {
// 使用无参数的TokenTextSplitter
public List<Document> splitDocument(List<Document> documents) {
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
return tokenTextSplitter.apply(documents);
}
// 使用参数的TokenTextSplitter
public List<Document> splitStructure(List<Document> documents) {
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(1000, 400, 10, 5000, true);
return tokenTextSplitter.apply(documents);
}
}- metadataEnricher
- 作用:为文档补充更多的原信息
keywordMetadataEnricher:使用AI提取**关键词**并添加到元信息中
SurmmaryMetadataEnricher:使用Ai关联上下文提取**摘要**
java
package cn.varin.varaiagent.rag.enricher;
import cn.varin.varaiagent.config.AliyunConfig;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.KeywordMetadataEnricher;
import org.springframework.ai.transformer.SummaryMetadataEnricher;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 自定义文档元信息增强器
*/
@Component
public class MyDocumentEnricher {
private final ChatModel chatModel;
private MyDocumentEnricher(ChatModel chatModel) {
this.chatModel = chatModel;
}
/**
* 关键词
* @param documents
* @return
*/
List<Document> documentEnricherByKeyWord(List<Document> documents) {
KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(chatModel, 5);
List<Document> documentList = keywordMetadataEnricher.apply(documents);
return documentList;
}
/**
* 摘要
* @param documents
* @return
*/
List<Document> documentEnricherBySummary(List<Document> documents) {
SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryMetadataEnricher.SummaryType.PREVIOUS, // 关联上文
SummaryMetadataEnricher.SummaryType.CURRENT,// 关联当前文章
SummaryMetadataEnricher.SummaryType.NEXT));// 关联下文
List<Document> documentList = summaryMetadataEnricher.apply(documents);
return documentList;
}
}- ContentFormatter
- 用于统一文档内容格式
- 实现类:defaultContentFormatter
功能:
文档格式化:
将文档内容与元数据合并成特定格式的字符串,以便于后续处理。
元数据过滤:根据不同的元数据模式(MetadataMode)筛选需要保留的元数据项:
ALL:保留所有元数据
NONE:移除所有元数据
INFERENCE:用于推理场景,排除指定的推理元数据
EMBED:用于嵌入场景,排除指定的嵌入元数据
自定义模板:支持自定义以下格式:
元数据模板:控制每个元数据项的展示方式
元数据分隔符:控制多个元数据项之间的分隔方式
文本模板:控制元数据和内容如何结合
java
// contentFormatter源码
public interface ContentFormatter {
String format(Document document, MetadataMode mode);
}documentWriter
- 负责将处理后的文档写入到目标存储中
- 源码
java
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}ETL示例
java
package cn.varin.varaiagent.rag.etl;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.transformer.KeywordMetadataEnricher;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.writer.FileDocumentWriter;
import java.util.List;
public class ETLMain {
public static void main(String[] args) {
//E 写入
MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader("document.md");
List<Document> documentList = markdownDocumentReader.read();
// T1 分割
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
documentList = tokenTextSplitter.apply(documentList);
//T2 增强元信息
KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(null, 3);
documentList= keywordMetadataEnricher.apply(documentList);
//L 文件存储
FileDocumentWriter fileDocumentWriter = new FileDocumentWriter(null);
fileDocumentWriter.write(documentList);
}
}2 )向量转换和存储
- VectorStore 是 Spring AI 中用于与向量数据库交互的核心接口,它继承自 DocumentWriter
- 这个接口定义了向量存储的基本操作,简单来说就是 "增删改查"
- 向量数据库的工作原理:
- 嵌入转换:当文档被添加到向量存储时 ,Spring AI 会使用嵌入模型(如 OpenAI 的 text-embedding-ada-002)将文本转换为向量。
- 相似度计算:查询时,查询文本同样被转换为向量,然后系统计算此向量与存储中所有向量的相似度
- 相似度度量:常用的相似度计算方法包括:余弦相似度/欧氏距离/点积
- 在开发时,有许多选择的向量数据库,通用操作:
先准备好数据源 => 引入不同的整合包 => 编写对应的配置 => 使用自动注入的 VectorStore
SearchRequest类
- 在VectStore接口中定义了方法,similaritySearch需要传递该类,
- 该类用于构建相似度搜索请求
- 示例
java
SearchRequest request = SearchRequest.builder()
.query("hello") // 查询文本
.topK(5) // 返回条数
.similarityThreshold(0.7) // 相似阈值
.filterExpression("category == 'web' AND date > '2025-05-03'") // 条件查询
.build();
List<Document> results = vectorStore.similaritySearch(request);实战:基于 PGVector 实现向量存储并整合到项目中
PGVector 是经典数据库 PostgreSQL 的扩展,为 PostgreSQL 提供了存储和检索高维向量数据的能力
- 准备PostgreSQL数据库
- 控制台:https://rdsnext.console.aliyun.com/dashboard/cn-hangzhou?spm=5176.6660585.rds_serverless_public_cn-top.i1.4a1c7992RMdIaY
- 实例创建完成后,进入到实例的主页面:
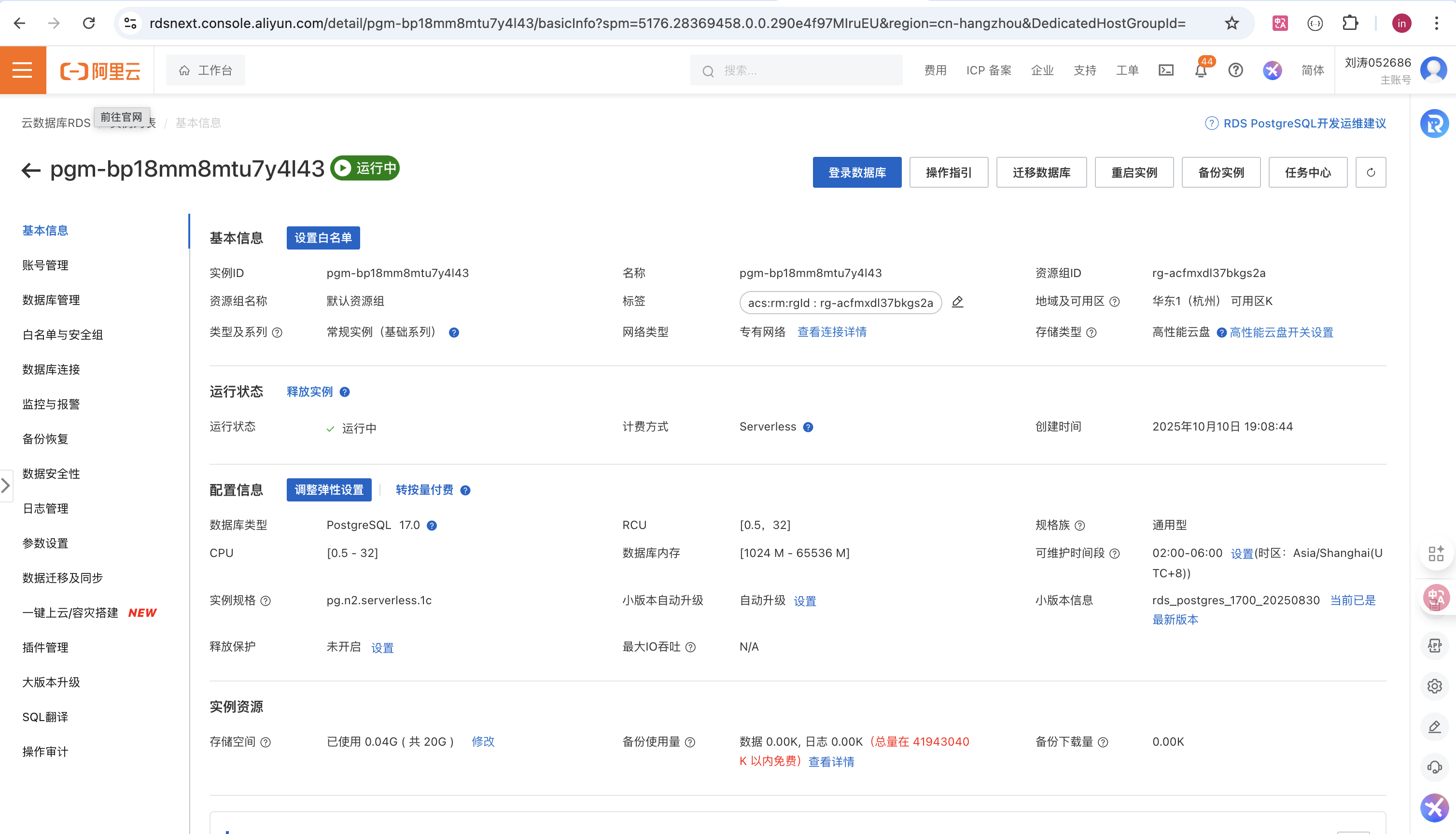
- 创建账号:点击账号管理
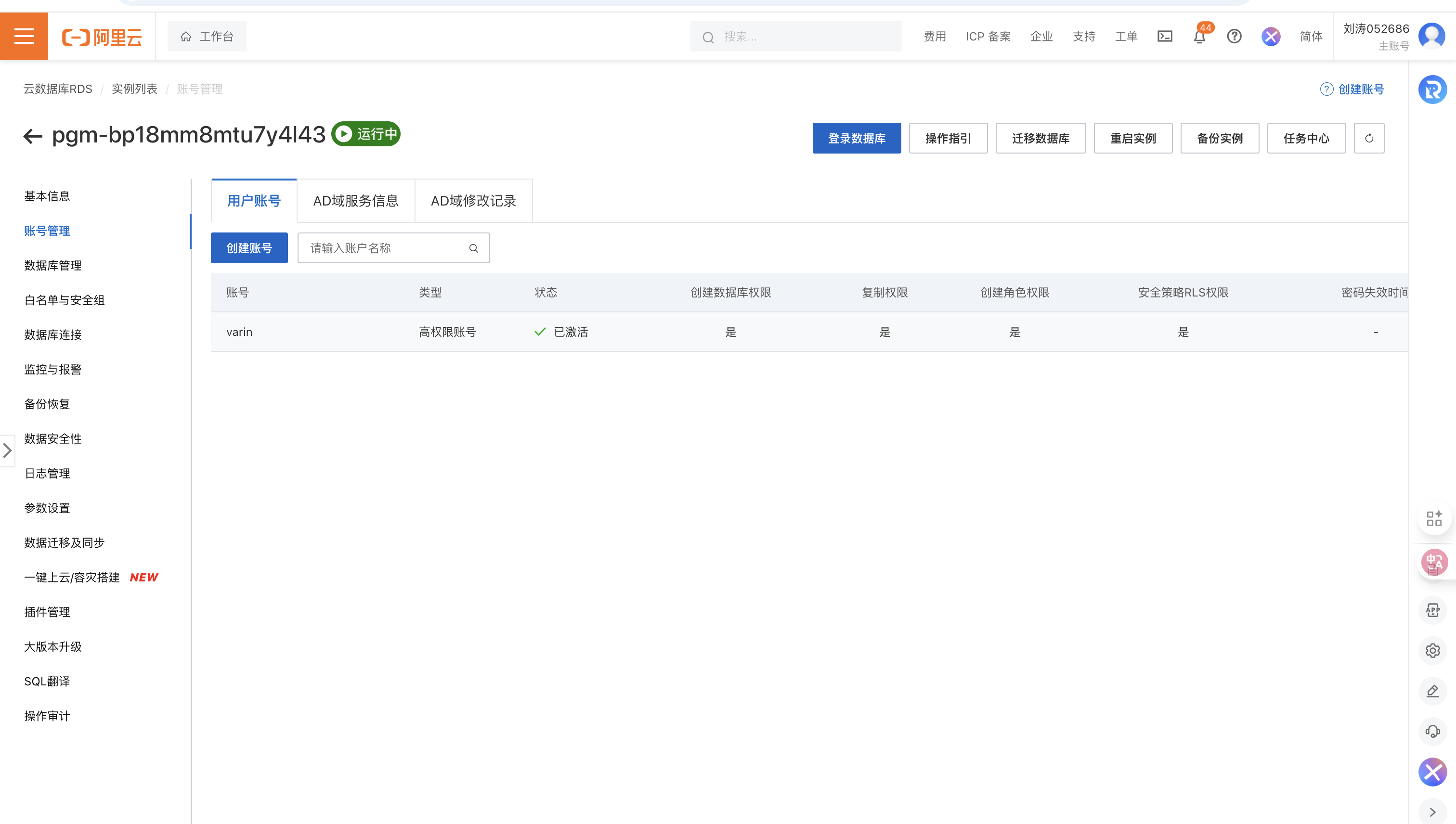
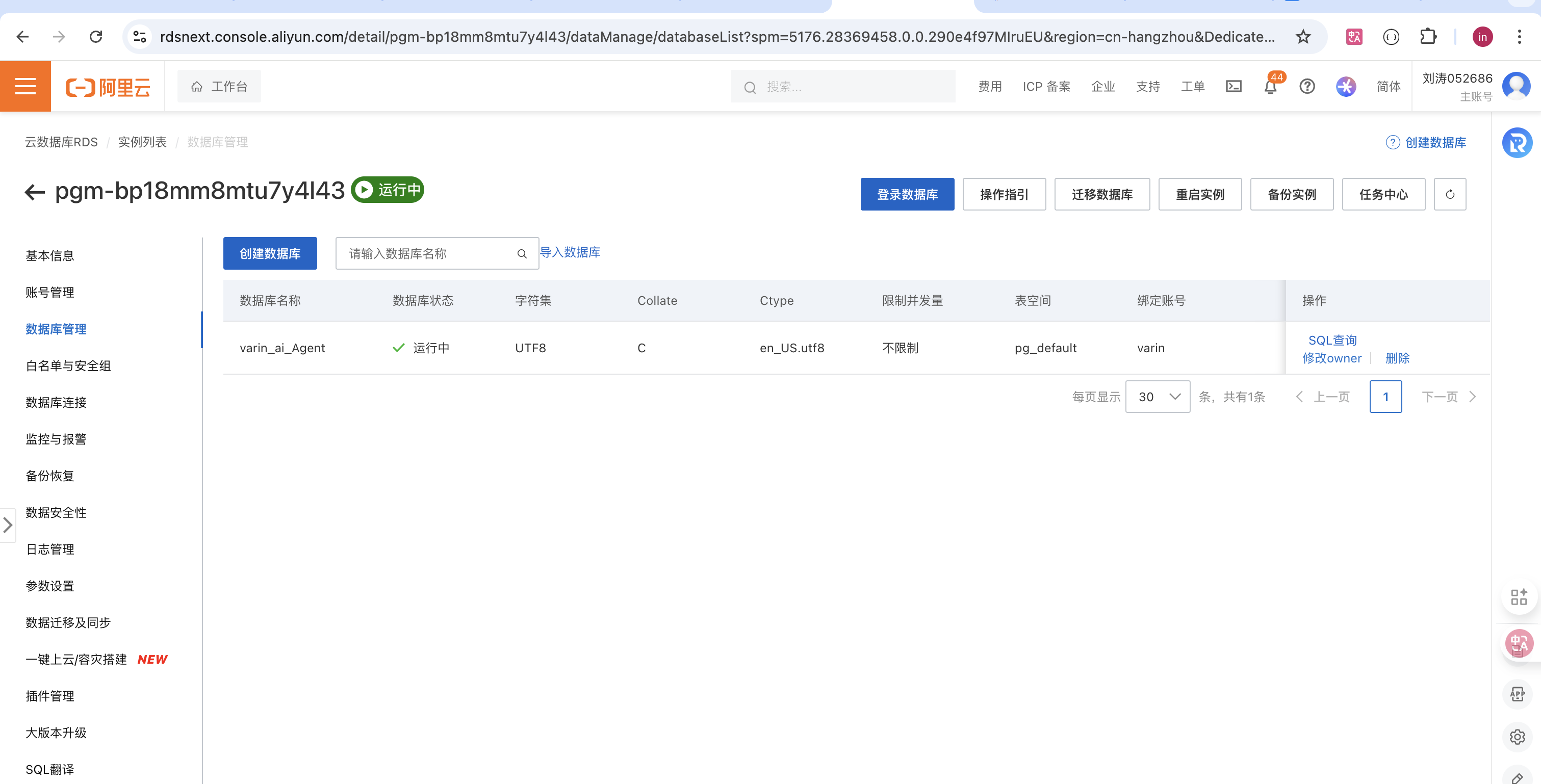
- 创建数据库:点击数据库管理
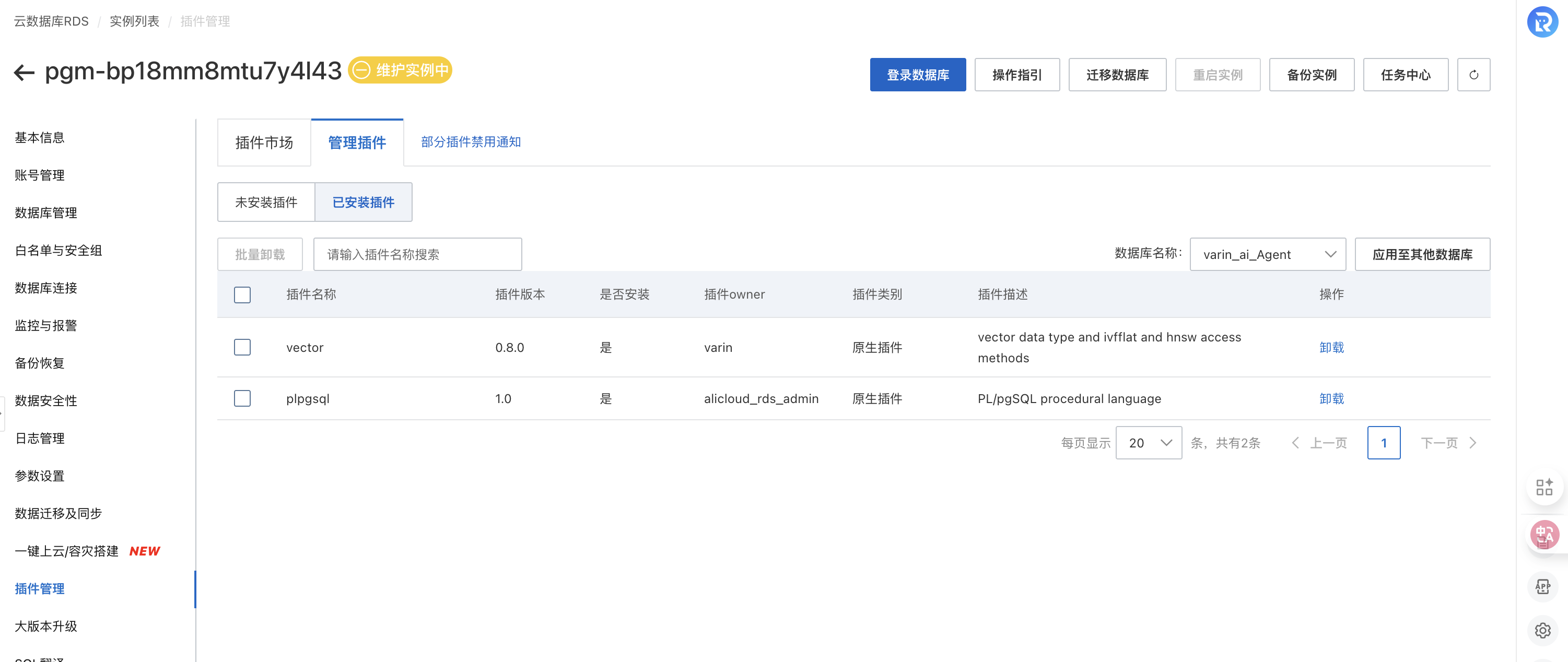
- 安装插件:Vector
- 开通公网地址访问:点击数据库连接
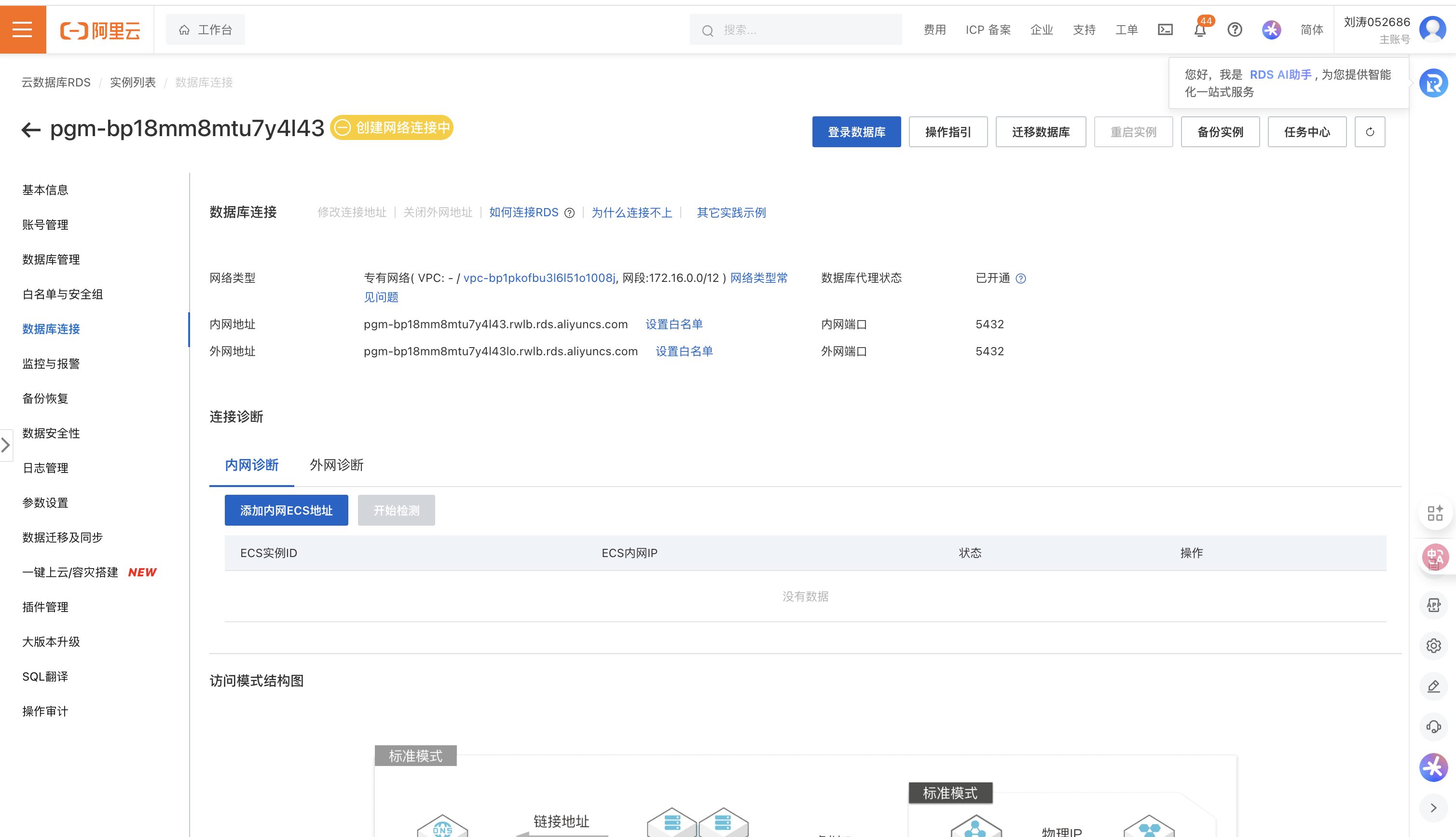
- 连接测试:

- 导入依赖
java
<!--postgresql-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
<version>1.0.0-M7</version>
</dependency>- yml
xml
spring:
datasource:
url: jdbc:postgresql://改为你的公网地址/yu_ai_agent
username: 改为你的用户名
password: 改为你的密码
ai:
vectorstore:
pgvector:
index-type: HNSW
dimensions: 1536
distance-type: COSINE_DISTANCE
max-document-batch-size: 10000- Bean注入
java
package cn.varin.varaiagent.config;
import cn.varin.varaiagent.rag.IALDAAppDocumentLoader;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentWriter;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import java.util.List;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgDistanceType.COSINE_DISTANCE;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgIndexType.HNSW;
@Configuration
/**
*向量数据库配置类:
*
*/
public class IALDAAppVectorStoreConfig {
/**
* SimpleVectorStore基于内存读写的向量数据库
*/
@Resource
private IALDAAppDocumentLoader iALDAAppDocumentLoader;
// 注册VectorSotre:
//注意:EmbeddingModel使用SpringAI的,不要使用alibaba的
@Bean
VectorStore iALDAAppVectorStore(EmbeddingModel environment) {
VectorStore vectorStore = SimpleVectorStore.builder(environment).build();
System.out.println("vectorStore = " + vectorStore.getClass().getName());
List<Document> documents = iALDAAppDocumentLoader.loadDocuments();
vectorStore.add(documents);
return vectorStore;
}
/**
* 阿里云PGVectorStore
* @param jdbcTemplate
* @param dashscopeEmbeddingModel
* @return
*/
@Bean
public VectorStore pgVectorVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {
VectorStore vectorStore = PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel)
.dimensions(1536)
.distanceType(COSINE_DISTANCE)
.indexType(HNSW)
.initializeSchema(true)
.schemaName("public")
.vectorTableName("vector_store")
.maxDocumentBatchSize(10000)
.build();
List<Document> documents =iALDAAppDocumentLoader.loadDocuments();
vectorStore.add(documents);
return vectorStore;
}
}- 测试
java
package cn.varin.varaiagent.VectorStore;
import jakarta.annotation.Resource;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import java.util.Map;
@SpringBootTest
public class PgVectorVectorStoreConfigTest {
@Resource
VectorStore pgVectorVectorStore;
@Test
void test() {
System.out.println(pgVectorVectorStore.getClass());
List<Document> documents = List.of(
new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),
new Document("The World is Big and Salvation Lurks Around the Corner"),
new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));
pgVectorVectorStore.add(documents);
List<Document> results = this.pgVectorVectorStore.similaritySearch(SearchRequest.builder().query("Spring").topK(5).build());
}
}- 效果
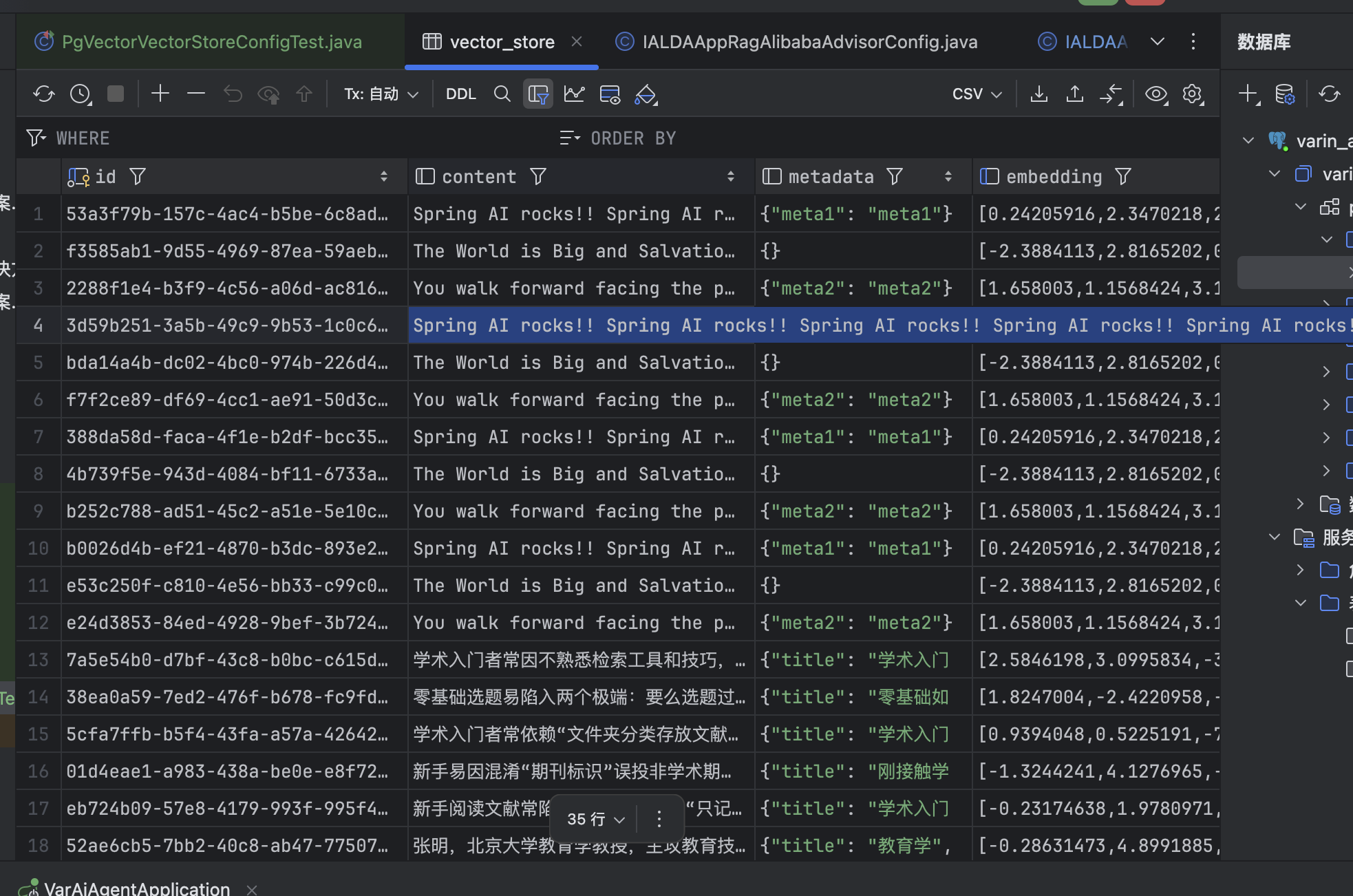
3 )文档过滤与检索
- 文档过滤分为了:
- 检索前
- 检索时
- 检索后
- 可以分别对不同的阶段定义不同的组件
预检索:优化用户查询
- 查询重写:RewriteQueryTransformer:将用户输入的内容在在检索前,先通过大模型优化
java
package cn.varin.varaiagent.documentSearch;
import cn.varin.varaiagent.test.ChatClientTest;
import jakarta.annotation.Resource;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.rag.Query;
import org.springframework.ai.rag.preretrieval.query.transformation.QueryTransformer;
import org.springframework.ai.rag.preretrieval.query.transformation.RewriteQueryTransformer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class SearchTest {
@Resource
private ChatModel dashscopeChatModel;
@Test
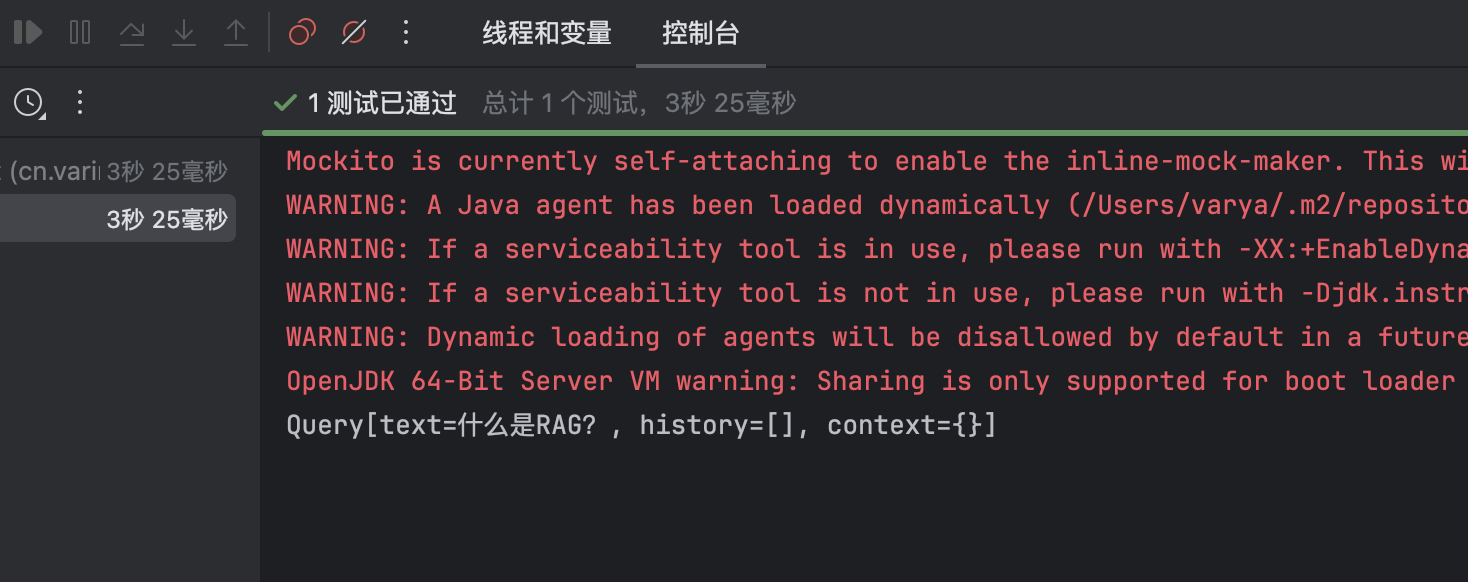
public void reWriterQueryTransformerTest() {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
Query query = new Query("你告诉我,什么是RAG呀什么是,什么是呀??");
QueryTransformer queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
Query transformedQuery = queryTransformer.transform(query);
System.out.println(transformedQuery.toString());
}
}
- 查询翻译:TranslationQueryTransformer :
- 可以将查询问题翻译成各种语言
java
@Test
public void translationTest() {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
Query query = new Query("你告诉我,什么是RAG呀什么是,什么是呀??");
QueryTransformer queryTransformer = TranslationQueryTransformer.builder()
.chatClientBuilder(builder)
.targetLanguage("English")
.build();
Query transformedQuery = queryTransformer.transform(query);
System.out.println(transformedQuery.toString());
}- 查询压缩:CompressionQueryTransformer
- 使用大语言模型将对话历史和后续查询压缩成一个独立的查询,类似于概括总结。适用于对话历史较长且后续查询与对话上下文相关的场景。
java
@Test
public void Test2() {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
CompressionQueryTransformer queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(builder).build();
Query query = Query.builder()
.text("什么事RAG?")
.history(new UserMessage("谁会RAG?"),
new AssistantMessage("我的网站 varin.cn"))
.build();
Query transformedQuery = queryTransformer.transform(query);
System.out.println(transformedQuery.toString());
}- 查询扩展:CompressionQueryTransformer
- 使用大模型将查询条件给发散化,
java
/**
* 查询扩展
*
*/
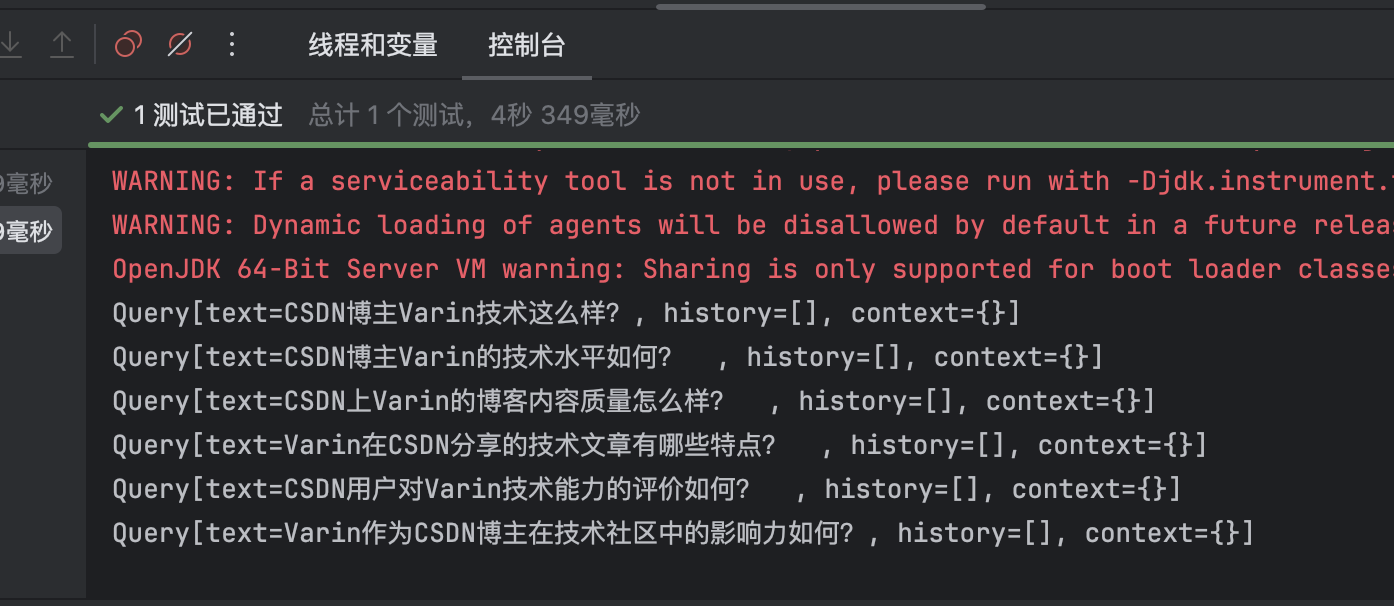
@Test
public void Test3() {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
MultiQueryExpander multiQueryExpander = MultiQueryExpander.builder()
.chatClientBuilder(builder)
.numberOfQueries(5)
.build();
List<Query> expand = multiQueryExpander.expand(new Query("CSDN博主Varin技术这么样?"));
expand.forEach(System.out::println);
}
检索时
DocumentRetriever:这是 Spring AI 提供的文档检索器。每种不同的存储方案都可能有自己的文档检索器实现类
例如:VectorStoreDocumentRetriever:从向量存储中检索与输入查询语义相似的文档。它支持基于元数据的过滤、设置相似度阈值、设置返回的结果数
java
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.7)
.topK(5)
.filterExpression(new FilterExpressionBuilder()
.eq("type", "web")
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("hello"));- 文档合并
ConcatenationDocumentJoiner:其实就是把 Map 展开为二维列表、再把二维列表展开成文档列表,最后进行去重
java
// 关键源码
return new ArrayList<>(documentsForQuery.values()
.stream()
.flatMap(List::stream)
.flatMap(List::stream)
.collect(Collectors.toMap(Document::getId, Function.identity(), (existing, duplicate) -> existing))
.values());
}检索后:文档优化(扩展)
java
检索后模块负责处理检索到的文档,以实现最佳生成结果。它们可以解决 "丢失在中间" 问题、模型上下文长度限制,以及减少检索信息中的噪音和冗余。
这些模块可能包括:
根据与查询的相关性对文档进行排序
删除不相关或冗余的文档
压缩每个文档的内容以减少噪音和冗余4 )查询增强与关联
QuestionAnswerAdvisor 查询增强:
当用户问题发送到 AI 模型时,Advisor 会查询向量数据库来获取与用户问题相关的文档,并将这些文档作为上下文附加到用户查询中
ContextualQueryAugmenter 空上下文处理:
当没有找到相关文档时,它会指示模型不要回答用户查询
二)RAG最佳实践和调优
1 )文档收集和切割
调优:
优化原始文档:使内容结构话、内容标准化、格式标准化
文档切片:
使用云平台:结合智能分块算法+人工二次校验
编码实现:效果差,不建议使用
元信息标注:
方法1: 利用DocumentReader进行批量的元信息标注
方法2:利用大模型AI自动分析关键字信息使用:keywordEnricher类
方法3:使用云平台自动提取或者手动添加
java
// 文档切片编码实现:
package cn.varin.varaiagent.rag.splitter;
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 自定义的文本分割器
*/
@Component
public class MyTokenTextSplitter {
// 使用无参数的TokenTextSplitter
public List<Document> splitDocument(List<Document> documents) {
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
return tokenTextSplitter.apply(documents);
}
// 使用参数的TokenTextSplitter
public List<Document> splitStructure(List<Document> documents) {
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(1000, 400, 10, 5000, true);
return tokenTextSplitter.apply(documents);
}
}
package cn.varin.varaiagent.config;
import cn.varin.varaiagent.rag.IALDAAppDocumentLoader;
import cn.varin.varaiagent.rag.splitter.MyTokenTextSplitter;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentWriter;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import java.util.List;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgDistanceType.COSINE_DISTANCE;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgIndexType.HNSW;
@Configuration
/**
*向量数据库配置类:
*
*/
public class IALDAAppVectorStoreConfig {
/**
* SimpleVectorStore基于内存读写的向量数据库
*/
@Resource
private IALDAAppDocumentLoader iALDAAppDocumentLoader;
// 文档分割器
@Resource
private MyTokenTextSplitter myTokenTextSplitter;
// 注册VectorSotre:
//注意:EmbeddingModel使用SpringAI的,不要使用alibaba的
@Bean
VectorStore iALDAAppVectorStore(EmbeddingModel environment) {
VectorStore vectorStore = SimpleVectorStore.builder(environment).build();
System.out.println("vectorStore = " + vectorStore.getClass().getName());
List<Document> documents = iALDAAppDocumentLoader.loadDocuments();
// //拿到了文档,进行切割在存储:注意:效果不好,不建议使用,建议使用云平台的
List<Document> splitDocuments = myTokenTextSplitter.splitStructure(documents);
vectorStore.add(documents);
return vectorStore;
}
}
java
package cn.varin.varaiagent.rag;
import com.alibaba.cloud.ai.document.TextDocumentParser;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentTransformer;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 文档加载器
*/
@Component
@Slf4j
public class IALDAAppDocumentLoader {
private final ResourcePatternResolver resourcePatternResolver;
public IALDAAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
public List<Document> loadDocuments() {
List<Document> documents = new ArrayList<>();
try {
Resource[] resources = this.resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
String fileName = resource.getFilename();
//元信息标注
String status = fileName.substring(0,7);
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", fileName)
.withAdditionalMetadata("status", status)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
documents.addAll(reader.get());
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return documents;
}
}
java
package cn.varin.varaiagent.rag.enricher;
import cn.varin.varaiagent.config.AliyunConfig;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.document.DefaultContentFormatter;
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.KeywordMetadataEnricher;
import org.springframework.ai.transformer.SummaryMetadataEnricher;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 自定义文档元信息增强器
*/
@Component
public class MyDocumentEnricher {
private final ChatModel chatModel;
private MyDocumentEnricher(ChatModel chatModel) {
this.chatModel = chatModel;
}
/**
* 关键词
* @param documents
* @return
*/
List<Document> documentEnricherByKeyWord(List<Document> documents) {
KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(chatModel, 5);
List<Document> documentList = keywordMetadataEnricher.apply(documents);
return documentList;
}
/**
* 摘要
* @param documents
* @return
*/
List<Document> documentEnricherBySummary(List<Document> documents) {
SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryMetadataEnricher.SummaryType.PREVIOUS, // 关联上文
SummaryMetadataEnricher.SummaryType.CURRENT,// 关联当前文章
SummaryMetadataEnricher.SummaryType.NEXT));// 关联下文
List<Document> documentList = summaryMetadataEnricher.apply(documents);
return documentList;
}
}
2 )向量转换和存储
- 配置向量存储
- 使用本地或云平台,根据需求自行选择
java
package cn.varin.varaiagent.config;
import cn.varin.varaiagent.rag.IALDAAppDocumentLoader;
import cn.varin.varaiagent.rag.splitter.MyTokenTextSplitter;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentWriter;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import java.util.List;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgDistanceType.COSINE_DISTANCE;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgIndexType.HNSW;
@Configuration
/**
*向量数据库配置类:
*
*/
public class IALDAAppVectorStoreConfig {
/**
* SimpleVectorStore基于内存读写的向量数据库
*/
@Resource
private IALDAAppDocumentLoader iALDAAppDocumentLoader;
// 文档分割器
@Resource
private MyTokenTextSplitter myTokenTextSplitter;
// 注册VectorSotre:
//注意:EmbeddingModel使用SpringAI的,不要使用alibaba的
@Bean
VectorStore iALDAAppVectorStore(EmbeddingModel environment) {
VectorStore vectorStore = SimpleVectorStore.builder(environment).build();
System.out.println("vectorStore = " + vectorStore.getClass().getName());
List<Document> documents = iALDAAppDocumentLoader.loadDocuments();
// //拿到了文档,进行切割在存储:注意:效果不好,不建议使用,建议使用云平台的
// List<Document> splitDocuments = myTokenTextSplitter.splitStructure(documents);
vectorStore.add(documents);
return vectorStore;
}
/**
* 阿里云PGVectorStore
* @param jdbcTemplate
* @param dashscopeEmbeddingModel
* @return
*/
// @Bean
public VectorStore pgVectorVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {
VectorStore vectorStore = PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel)
.dimensions(1536)
.distanceType(COSINE_DISTANCE)
.indexType(HNSW)
.initializeSchema(true)
.schemaName("public")
.vectorTableName("vector_store")
.maxDocumentBatchSize(10000)
.build();
List<Document> documents =iALDAAppDocumentLoader.loadDocuments();
vectorStore.add(documents);
return vectorStore;
}
}3 )文档过滤与检索
- 使用扩展查询提高广度:MultiQueryExpander
- 使用查询重写,提高准确度:RewriteQueryTransformer
- 使用查询翻译,使用多种语言:TranslationQueryTransformer
- 配置过滤规则
- 本地知识库配置规则测试:通过状态判断
java
package cn.varin.varaiagent.rag.factory;
/**
*
*/
import org.springframework.ai.chat.client.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;
import org.springframework.stereotype.Component;
/**
* 顾问 配置过滤规则。
*/
@Component
public class AppRagAdvisorFactory {
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression)
.similarityThreshold(0.2)
.topK(3)
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.build();
}
}主体方法:
java
/**
* 读取本地知识库+状态过滤
*/
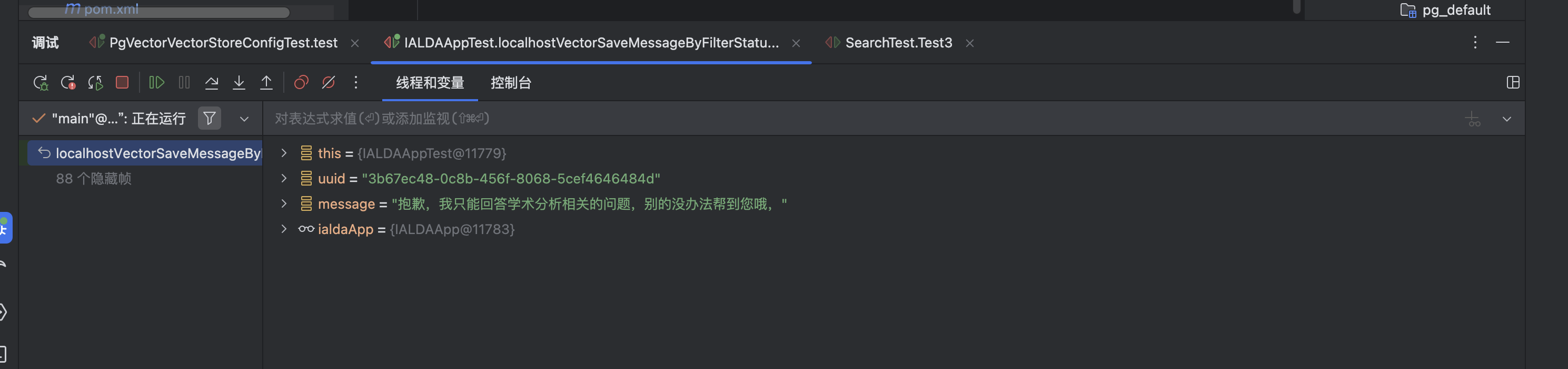
public String localhostVectorSaveMessageByFilterStatus(String content,String chatId) {
ChatResponse chatResponse = this.chatClient.prompt()
.user(content)
.advisors(advisor -> advisor.param("chat_memory_conversation_id", chatId)
// 自定义日志
.param("chat_memory_response_size", 10))
.advisors(
AppRagAdvisorFactory.createLoveAppRagCustomAdvisor(iALDAAppVectorStore,"学术终极阶段")
)
// 本地知识库
.advisors(new QuestionAnswerAdvisor(iALDAAppVectorStore)).call().chatResponse();
String text = chatResponse.getResult().getOutput().getText();
log.info("text:{}", text);
return text;
}测试方法:
java
* 本地过滤测试
*/
@Test
void localhostVectorSaveMessageByFilterStatusTest() {
String uuid= UUID.randomUUID().toString();
String message = ialdaApp.localhostVectorSaveMessageByFilterStatus( "我是软件工程专业,怎么开始写论文",uuid );
System.out.println("cloudAlibabaDoChatWithRag:=================== " );
System.out.println(message);
System.out.println("cloudAlibabaDoChatWithRag:=================== " );
}效果一:
没有找到
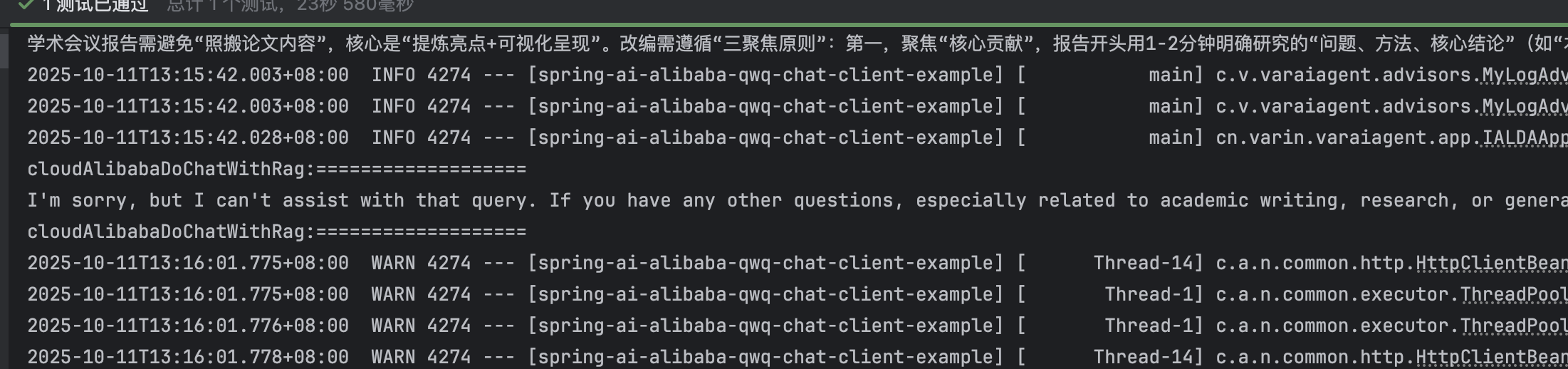
效果二:找到数据:

3 )查询关联与增强
- 添加类似异常处理信息:没有查询到数据时,返回自己定义的信息
java
package cn.varin.varaiagent.rag.factory;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.rag.generation.augmentation.ContextualQueryAugmenter;
public class AppContextualQueryAugmenterFactory {
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你应该输出下面的内容:
抱歉,我只能回答学术分析相关的问题,别的没办法帮到您哦,
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}
}
java
package cn.varin.varaiagent.rag.factory;
/**
*
*/
import org.springframework.ai.chat.client.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;
import org.springframework.stereotype.Component;
/**
* 顾问 配置过滤规则。
*/
@Component
public class AppRagAdvisorFactory {
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression)
.similarityThreshold(0.2)
.topK(3)
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
// 查询增强,没有找到数据时,返回提示信息
.queryAugmenter(AppContextualQueryAugmenterFactory.createInstance())
.build();
}
}