好久没更了,打了俩比赛收益很低,收收心回来继续做论文
这期随笔记录qwen3 embedding模型中的核心内容
这里训练qwen3 embedding模型主要用到一些预训练数据和利用qwen3合成的高质量训练数据
一、简介
采用Qwen3 instruct来合成了一些数据,用于第一训练阶段并且取出一部分高质量的数据用于第二阶段训练
二、模型架构
从Qwen3 dense结构出发
三、embedding和判别式排序
embedding
输入格式:{Instruction} {Query}
用instruct带入语境信息
判别式:

对于判别式的得分,是用两个对数概率求加权占比,这一点和不加权直接拿yes的概率有什么区别
四、训练过程
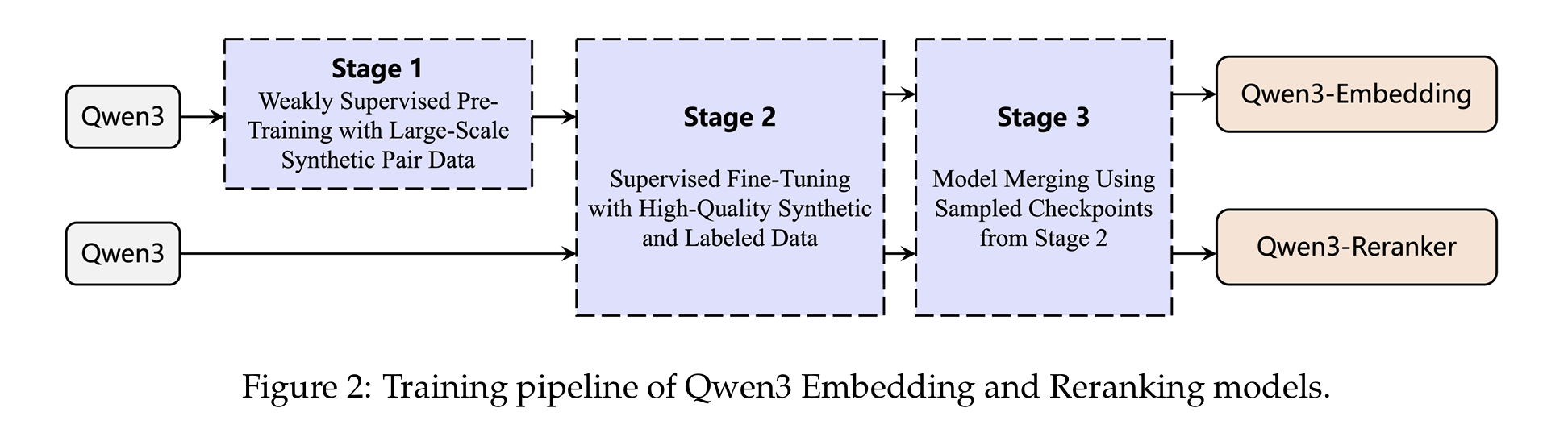
reranker模型不经过第一阶段的预训练
具体损失
embedding模型的训练损失就是对比损失,对于对比损失的分母,设计比较复杂,融合了多种负样本,并且利用了对query和doc之间的表征的相似度 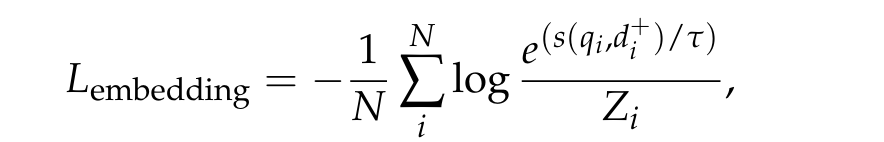
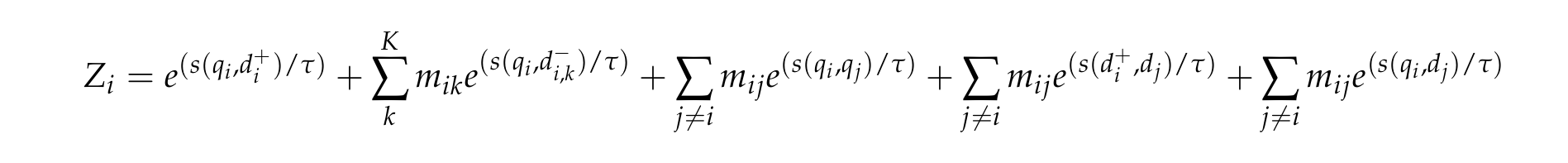
包括inbatch内的query和正样本doc、query和k难负样本、batch内非自身doc、query之间、doc之间
根据doc候选和正样本的相似度来分配权重,即通过相似度排除一些高可能性是假的负样本带来的噪声: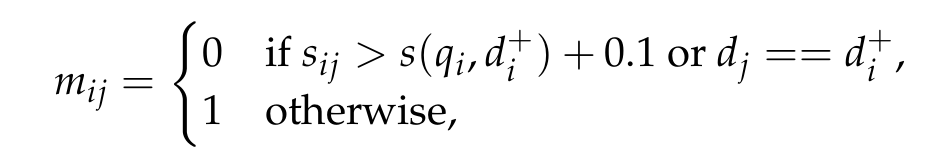
对于ranker的训练,则是接了一个分类头,用sft的损失
模型融合
对训练过程中的多个模型检查点不是简单的线性加权,而是采用球面线性插值来保留多个检查点的优势
以下是这个技术的做法和gemini的解释:
球面线性插值(Spherical Linear Interpolation, slerp)是实现模型融合的一种高级算法。在深度学习中,一个模型的全部参数(权重)可以被看作是一个高维空间中的向量。传统的模型平均方法(即线性插值)是直接将这些向量进行加权平均。然而,这种简单的线性路径可能会导致合并后的向量长度缩短,从而损失模型的性能和特性。
Slerp 则不同,它在两个模型参数向量之间沿着一个球面上的最短弧线(测地线)进行插值。这种方式能够更好地保留每个原始模型的"几何特性",在平滑过渡的同时,确保融合后的模型能更完整地继承各个检查点的优势,避免性能的直接折损。
这个做法有利于提升模型泛化能力
五、训练数据
用Qwen 32B合成数据,增加数据类少的场景的训练数据,用多种prompt
同时在合成数据时用检索模型把一些很可能相关的候选也加入到prompt中,给模型更多参考
融合了多种语言、长度、格式的query
最终大概有150M合成数据,然后用余弦相似度大于0.7的这个方法来过滤高质量的数据12M对用于二阶段的训练
六、效果
在一些benchmark上超过一些embedding的开源和商业模型"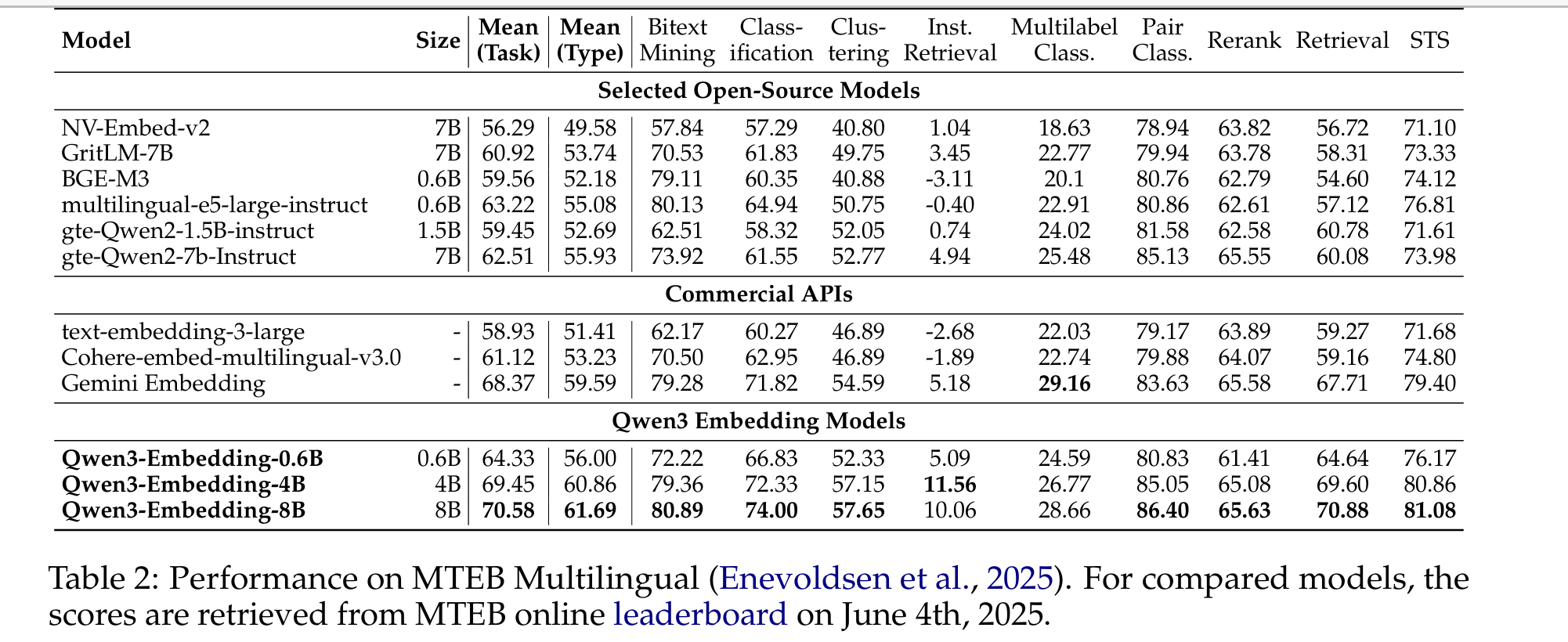
附上链接:Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models