多模态大模型在推理上虽然效果好,但会强制执行 "逐步思考" 流程,导致输出 token 量激增,冗余思考过程不会提升简单任务的准确性,反而可能因 "过度推理" 引入噪声。
现有模型无法根据任务复杂度自主选择 "思考模式"(需推理)或 "非思考模式"(直接回答),需要手动触发是否思考的条件(如qwen3的开关控制)或者如Keye-VL 通过人工标注 "任务复杂度标签" 触发思考模式,但人工标注成本高、覆盖场景有限,且推理时需额外输出 "复杂度分析" token,进一步增加计算开销。
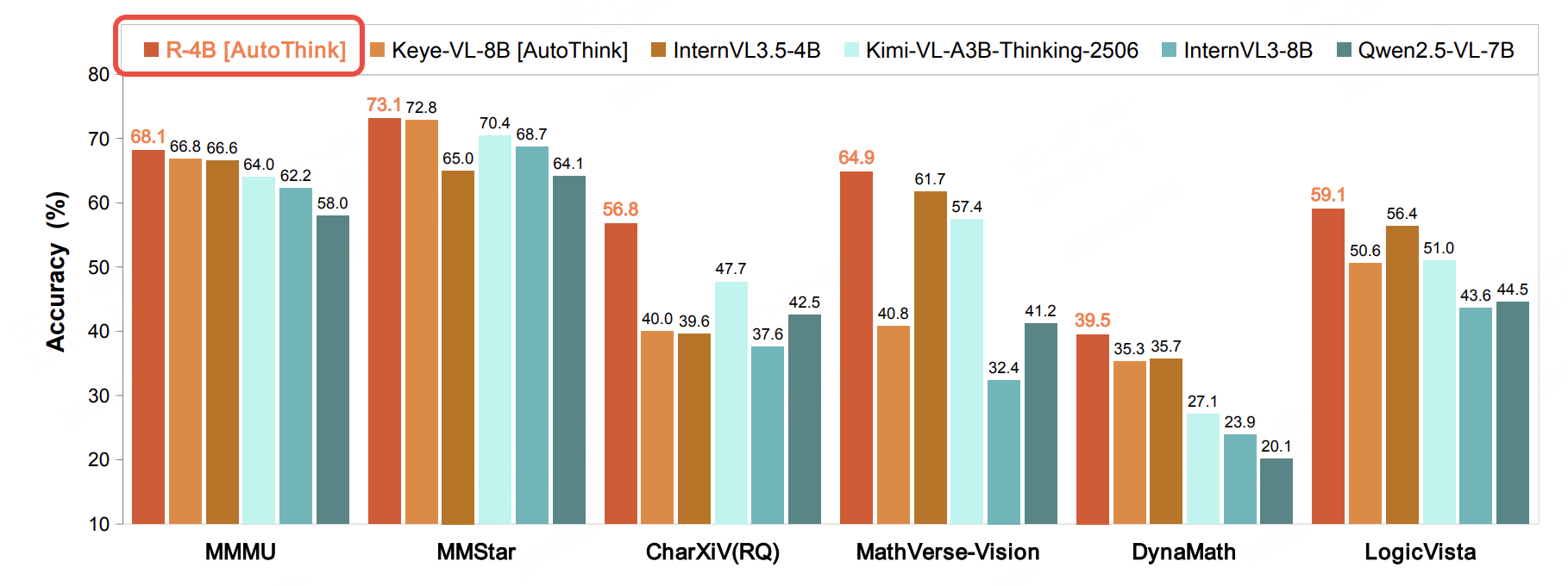
因此,如何为多模态 MLLMs 提供自动思考能力,下面来看看R-4B的思路。
方法-R-4B双阶段训练设计
为自动思考,R-4B的核心是设计了一个两阶段训练方式:双模态退火(Bi-mode Annealing) 和 双模态策略优化(Bi-mode Policy Optimization, BPO)。
阶段1、双模态退火设计
这一阶段的目标是让模型学会自动思考能力("思考"和"不思考")。
提出启发式驱动的自动化数据构建策略,利用现有强性能 MLLM(Qwen2.5-32B-VL)作为 "统一标注器",自动将通用领域数据划分为两类,流程如下图:
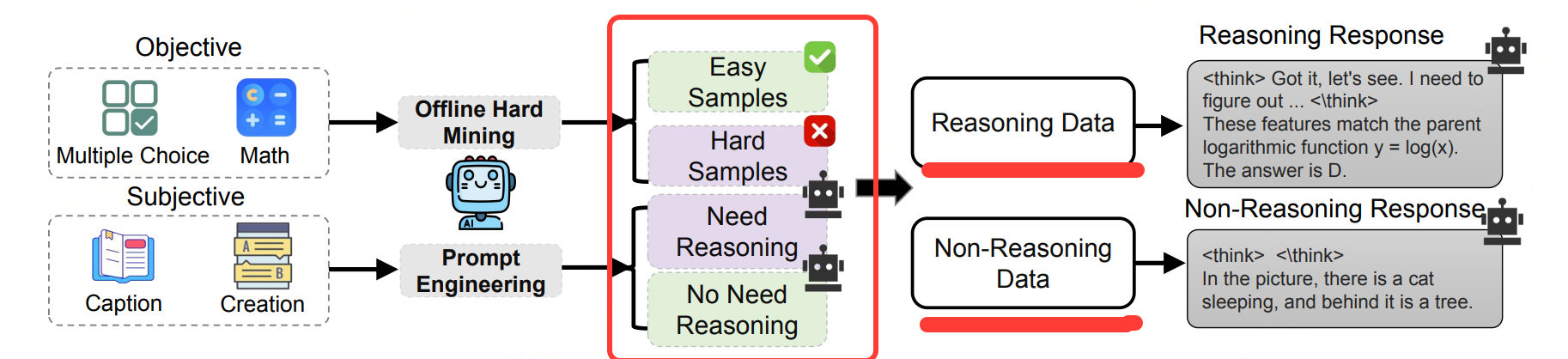
两种启发式标注规则:
-
难度导向启发式:针对主观类查询
利用现有多模态大语言模型进行提示工程,基于其内在难度评估是否需要推理过程。被判定为复杂的查询被标注为需要推理的样本。
逻辑如下:
- 对每个主观查询,构造提示词,让 Qwen2.5-32B-VL 评估其 "是否需要复杂推理过程";
- 提示词核心逻辑:"判断以下问题是否需要分步骤分析、逻辑推导或多视角权衡才能回答,若需要则标记为'推理密集型',否则标记为'非推理型'";
- 例如,"描述猫的外形" 被标记为非推理型(直接调用常识),"分析猫的外形如何适应夜间捕猎" 被标记为推理型(需结合生物学知识分步骤推导)。
-
性能导向启发式:用于客观查询
对于答案可验证的查询(例如数学题或选择题),引入一种基于模型的离线困难样本挖掘策略,系统地识别出难样本。
逻辑如下:
- 对每个客观查询,让 Qwen2.5-32B-VL 生成 8 次独立回答(N=8);
- 若 8 次回答全部错误(即模型在该问题上表现极差,属于 "硬样本"),标记为 "推理密集型"(需复杂推理才能正确回答,如 "基于图表数据计算近 5 年增长率");
- 若 8 次回答至少 1 次正确(即模型可直接给出答案,属于 "易样本"),标记为 "非推理型"(如 "识别图中的数字""回答'地球自转周期是多少'")。
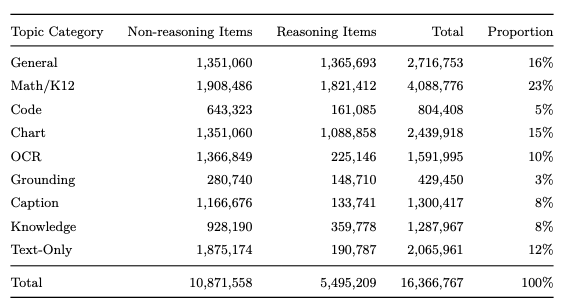
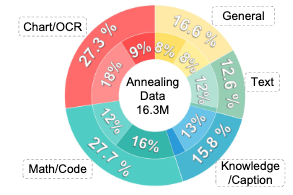
数据分布情况:
阶段2、双模态策略优化
经过"双模态退火阶段",这时候有了 R-4B-Base 模型,然而存在的 "思考萎缩" 问题(模型虽同时具备思考 / 非思考能力,但倾向于优先选择非思考模式。
引入双模态策略优化(Bi-mode Policy Optimization, BPO),这是一种为自动思考量身定制的强化学习算法。
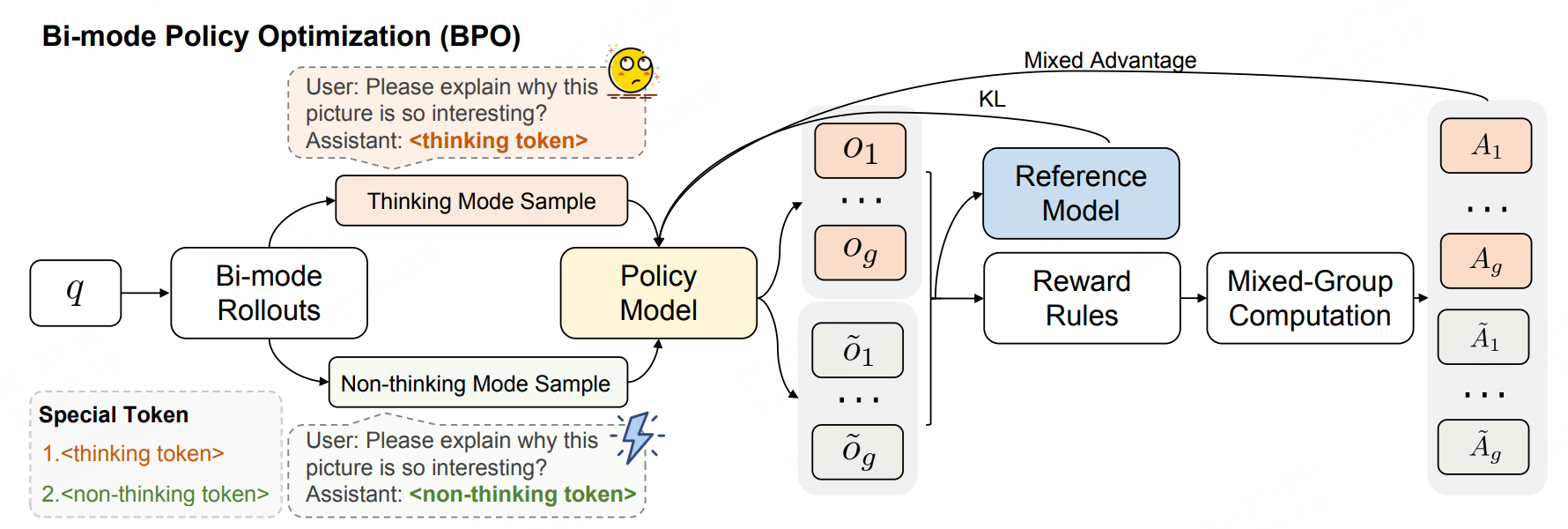
BPO的核心目标是通过 RL 优化模型的 "模式选择策略",让模型在面对不同复杂度的任务时,能自主选择 "性价比最高" 的响应模式。
核心设计思想:"强制双模态Rollouts"
传统RL方法在训练自动思考模型时,常因"单模态采样"导致模型偏向某一种模式(如始终选择非思考模式以降低损失),最终引发"思考萎缩"。BPO通过Bi-mode Rollouts强制打破这种偏好,逻辑如下:
- 对每个输入查询(如"求解数学方程""识别图片文字"),模型需同时生成两组响应 :
- 思考模式组:通过特殊token
<thinking token>触发,输出包含逐步推理过程的响应; - 非思考模式组:通过特殊token
<non-thinking token>触发,输出仅含答案的响应。
- 思考模式组:通过特殊token
两组响应的数量严格相等(如每组各生成g个样本,|Group_thinking|=|Group_non-thinking|=g),确保模型在训练中必须"公平探索"两种模式,无法因数据分布或损失函数偏向而忽略某一模式。
方法架构、训练方法
模型架构:VIT+MLP+LLM
训练方法:
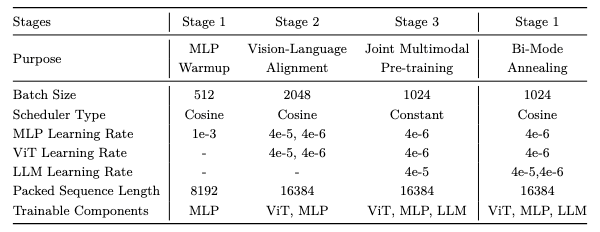
- 阶段 1:MLP 预热首先冻结 ViT 和 LLM 的参数,同时初始化一个随机初始化的两层MLP 投影模块。该投影模块使用图像-标题对进行训练,以建立初始的跨模态对齐。此阶段能够确保后续阶段中梯度传播的稳定性,并缓解由表示对齐不佳引起的不稳定性。
- 阶段 2:视觉-语言对齐在此阶段,ViT 主干网络被解冻,而 LLM 保持冻结状态,使用交错的多模态数据进行训练。这些批量中包含的多样化视觉内容系统性地提升了视觉编码器处理不同视觉领域的能力。
- 阶段 3:联合多模态预训练此阶段实现了对整个架构的全参数最优化。将训练方案扩展至包含 1450 亿个跨越多种模态和任务的 token,涵盖 OCR 解析、视觉定位、数学推理以及结构化数据(表格/图表)。
此外,实施了一种非思考损失掩码策略。在此策略中,在生成响应前添加 < think>
< /think> 标签,并对其对应的损失贡献进行掩码处理。该策略在联合多模态预训练过程中
有效保留了 Qwen3的专用推理能力。
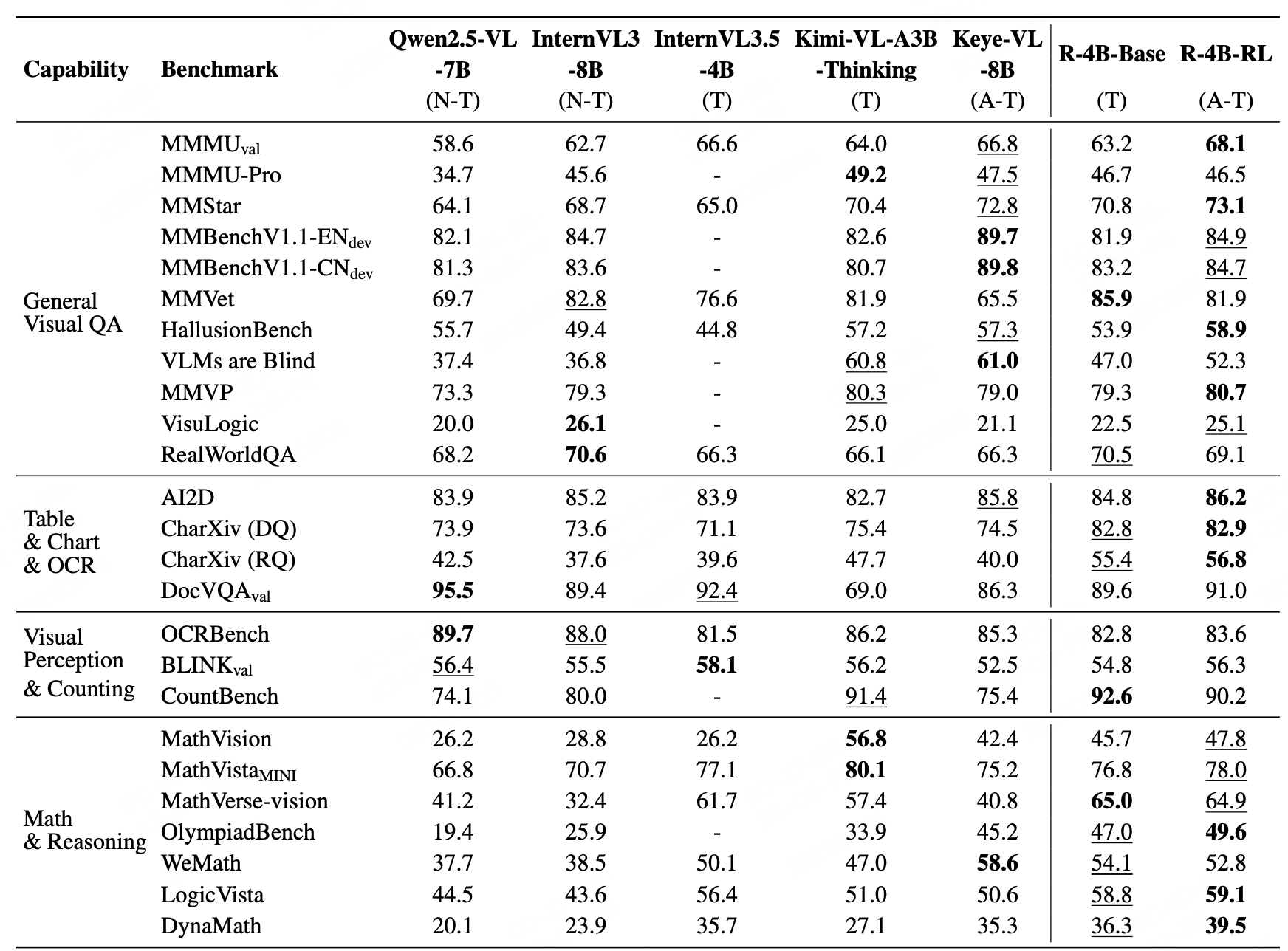
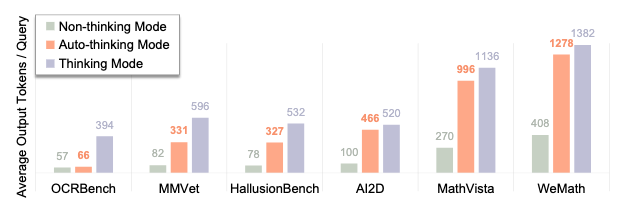
实验
参考文献:R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning,https://arxiv.org/pdf/2508.21113
Repo:https://link.zhihu.com/?target=https%3A//github.com/yannqi/R-4B