总览
Magnus ,一个专为解决大规模机器学习(ML)工作负载中数据管理挑战而设计的综合性系统。针对传统数据湖表格式(如Iceberg)在处理海量数据、多模态数据、频繁更新和大模型训练时面临的存储效率低、元数据开销大、读写性能差等问题,Magnus提出了多项创新。其核心包括:为宽表和多模态数据设计的高效Krypton和Blob存储格式 ;通过消除冗余和索引优化来提升元数据管理效率 ;支持列级更新和主键Upsert 的轻量级MOR机制;以及为大型语言模型(LLM)和长序列推荐模型(LRM) 训练优化的双表设计和分片机制。实验证明,Magnus在存储、读写性能和训练效率上均显著优于现有方案。
1. 背景与挑战
随着机器学习模型规模和数据量的激增,传统的数据湖表格式(如Apache Iceberg, Hudi, Delta Lake)在以下方面表现出局限性:
- 存储效率低:Parquet等格式在处理宽表或多模态数据时效率不高。
- 元数据开销大:海量文件导致元数据(特别是Iceberg中冗余的min-max统计信息)管理成本高昂,规划延迟严重。
- 更新效率差:缺乏高效的列级更新和Upsert能力,难以满足特征工程等需要频繁修改数据的场景。
- 训练支持不足:现有系统未针对LLM和LRM等特定大模型训练的数据访问模式进行优化。
2. Magnus的主要贡献与设计
-
高效的数据布局与存储格式:
- Krypton格式 :一种自主设计的列式存储格式,通过减少冗余元数据和优化内存使用,相比Parquet节省超30%的存储空间,并提升读写吞吐量。
- Blob格式 :针对多模态二进制数据(如视频帧)。采用"行列混合"存储:将大二进制对象(Blob)以行式存入独立文件,仅在列式文件中存储其大小和偏移量的元数据。这极大地减轻了读取部分元素时的"读放大"问题。
-
高效的元数据管理:
- 消除冗余:识别并移除Iceberg清单文件中占70%-80%开销的冗余统计信息。
- 优化结构 :按分区值对数据进行排序,并构建索引文件,使元数据规划(解析)效率比Iceberg快5到26倍。
-
灵活的更新与插入机制:
- 实现了基于MOR(Merge-on-Read)策略的列级更新 和主键驱动的Upsert,满足了机器学习场景下频繁数据变更的需求。
-
大规模模型训练支持:
- 针对LRM(长序列推荐模型) :采用双表设计 。
- 主表:存储变化频繁的实时行为特征(如点击、转化)。
- 附加表:存储稳定、冗长的用户行为序列,每个用户仅保留最新一份完整序列。
- 针对LMM(大型语言模型) :应用分片机制来优化数据管理和训练效率。
- 针对LRM(长序列推荐模型) :采用双表设计 。
3. 实验效果
- 存储:Krypton格式比Parquet节省30%以上存储。
- 元数据:元数据解析效率比Iceberg快5-26倍。
- 更新:写入性能显著优于Iceberg。
- 训练 :在LRM/LMM场景下,优化后的Magnus减少40%内存消耗 ,启动时间从30分钟缩短至15分钟 ,并缩短了20分钟的训练时长。
结论:Magnus通过一系列针对大规模ML工作负载的系统性优化,在存储、元数据管理、数据更新和模型训练支持方面均取得了显著进步,为下一代机器学习数据平台提供了重要的实践参考。
详细介绍:

00 简介
本篇文章旨在解决大规模机器学习(ML)工作负载中的数据管理挑战,特别是随着模型复杂性和数据量的增加,传统数据管理方法在存储效率、元数据可扩展性、更新机制和与ML框架的集成方面存在局限性。
01 背景和问题
该问题的研究难点在于如何有效地管理海量训练数据,特别是在处理大规模数据和复杂模型时,传统的数据湖表格式(如Apache Hudi、Apache Iceberg和Delta Lake)在资源利用、元数据管理、读写性能和与训练框架的集成方面仍存在不足。
主要包括以下几个方面的挑战:
-
资源友好的存储格式。在字节跳动中,其管理的巨大的数据量,每天有大量的计算资源投入到数据的读取和写入中,用于数据处理和训练。然而,Parquet在处理具有大量列或多模态数据时,面临存储和计算效率问题。
-
**高效的元数据管理。**随着数据量的增长,元数据自然也变成了海量元数据,现有的元数据规划方法如Iceberg在处理如此大量的元数据时就会遇到困难,特别是当元数据包含冗余信息时。
-
**轻量级的MOR更新和插入。**许多机器学习场景涉及频繁的数据修改,例如在特征工程中添加新列、从回传中更新广告转化数据或刷新多模态注释数据。然而,像Iceberg这样的开源数据湖的MOR策略通常难以满足这些机器学习用例下的读写效率要求。
-
**大型模型训练支持。**日益多样化的大规模机器学习场景对数据管理和模型训练提出了独特的要求。例如,在LRM训练中,训练样本从按时间顺序排列转变为按用户行为分组。同样,大型语言模型(LMM)训练由于其依赖众多多模态数据源而涉及额外的复杂性。针对大型模型训练的数据管理优化对于降低资源消耗和最大化训练吞吐量至关重要。
02 主要贡献
-
引入了列式Krypton格式和Blob格式,以增强存储效率,特别是在处理宽表和多模态数据时。Krypton格式通过减少冗余元数据结构和优化内存使用,显著提高了存储和读取效率。Blob格式则通过行式存储多模态二进制数据,并使用列式存储格式仅存储引用元数据,从而提高了存储效率。
-
通过消除冗余字段、按分区排序和构建清单文件索引,显著提高了大数据规划效率。此外,Magnus增强了Iceberg的分支和标记功能,支持合并和变基操作,提供了灵活的版本控制,便于特征分析。
-
实现了基于MOR策略的列级更新和主键驱动的Upsert,同时通过原生引擎增强和数据重组技术优化了读取性能。
-
针对LRM和LMM训练场景,分别应用了双表设计和分片机制,优化了数据管理和模型训练效率。
03 设计
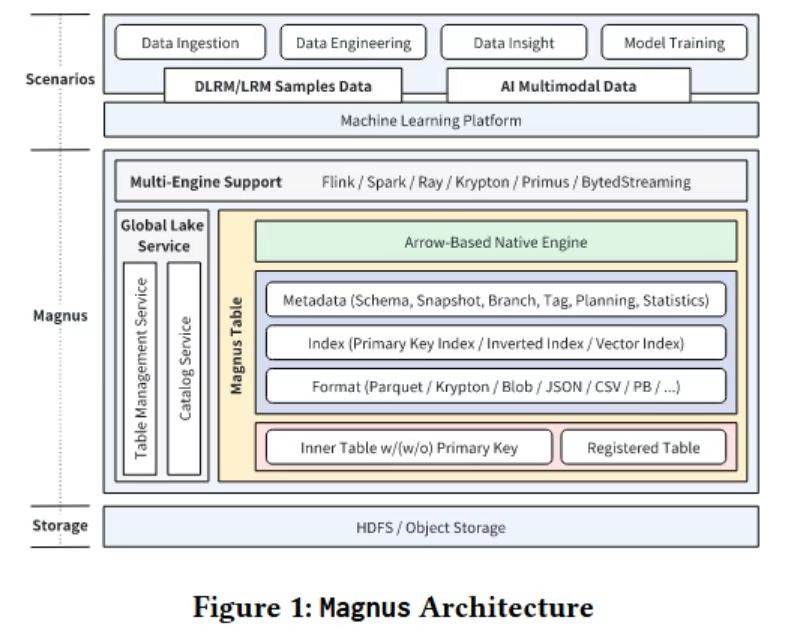
3.1 数据布局
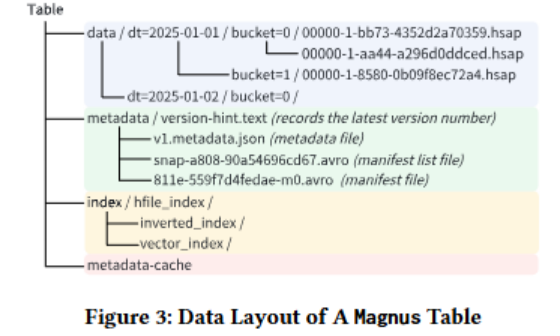
数据布局也就是Magnus的表格式,集成了了自主设计的Krypton列式格式,包含4个组成部分,数据目录、元数据目录、索引目录、元数据缓存。
3.2 多模态数据的Bolb格式
为了应对多模态数据中的大型二进制对象存储,导致的单个列庞大,以及在读取视频帧(常常是List<Binary>格式存储)时导致的严重读放大问题。
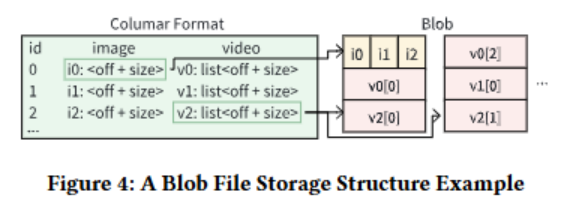
如图所示,将多模态二进制数据使用基于行的存储格式分别存储在blob文件中,然后将数据大小和偏移量使用列式存储存储在列式文件中,取数据时,只需要从列式文件中获取数据的精确位置信息,对于List<Binary>数据,还可以快速过滤,精确定位子项,减轻读放大。实际上,这是一种行列混合的存储方式。
3.3 索引机制
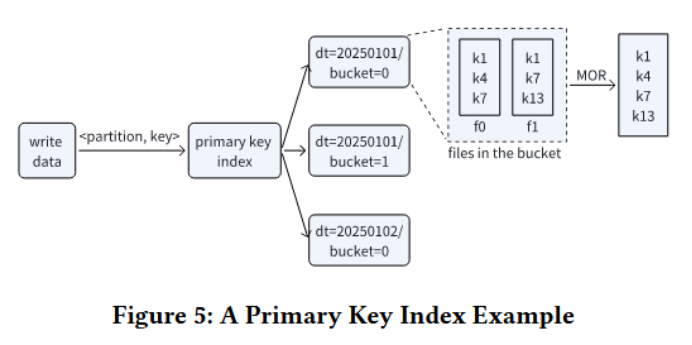
设计了主键索引和搜索索引(包括倒排索引和向量索引),以实现高效的数据扫描和检索。主键索引通过哈希索引和HFile索引确保数据的唯一性和高效更新。
3.4 元数据管理
通过消除冗余字段、按分区排序和构建索引文件,显著提高了大数据规划的效率。此外,增强了Iceberg的分支和标签功能,支持灵活的版本控制和特征分析。
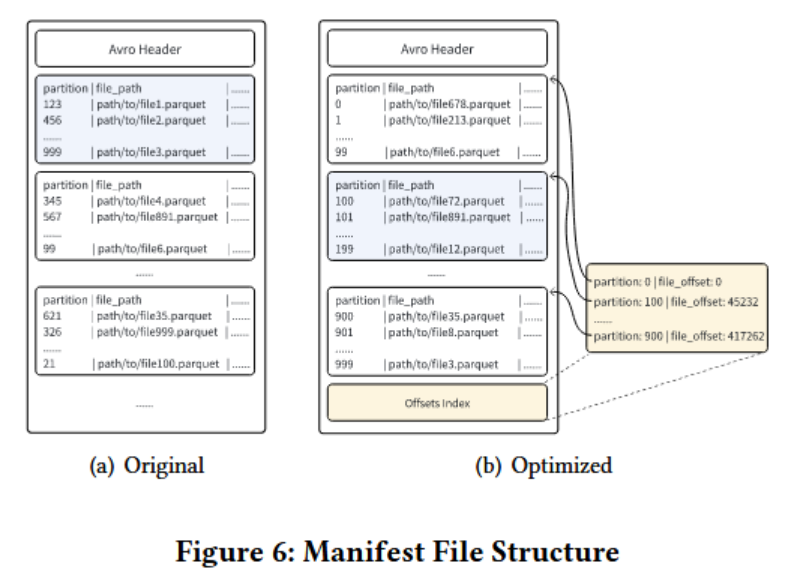
Iceberg 默认在每个数据文件的每个列的清单文件中保留最小-最大统计信息。这种冗余的统计数据占清单文件存储空间和解析开销的70%-80%,导致元数据规划延迟过高。Magnus优化了清单文件结构,在写入清单文件前,按分区值进行排序,这大大降低了元数据规划开销。
3.5 更新和插入操作
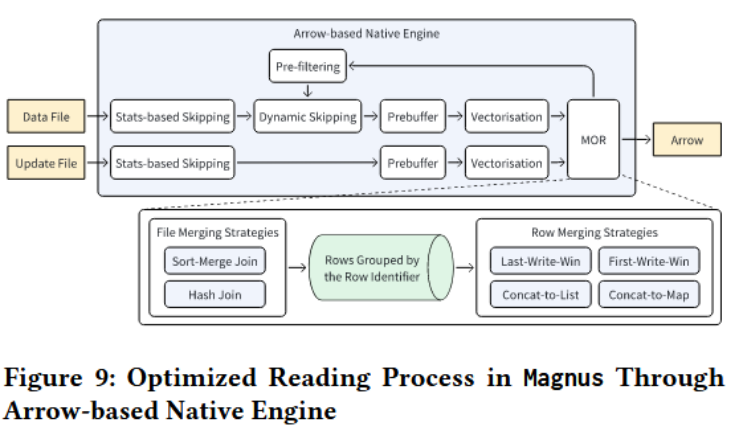
实现了基于MOR策略的列级更新和主键驱动的插入操作,同时通过原生引擎增强和数据重组优化了读取性能。
3.6 大规模模型训练支持
针对LRM和LMM训练场景进行了有针对性的适配,分别采用了双表设计和分片机制。
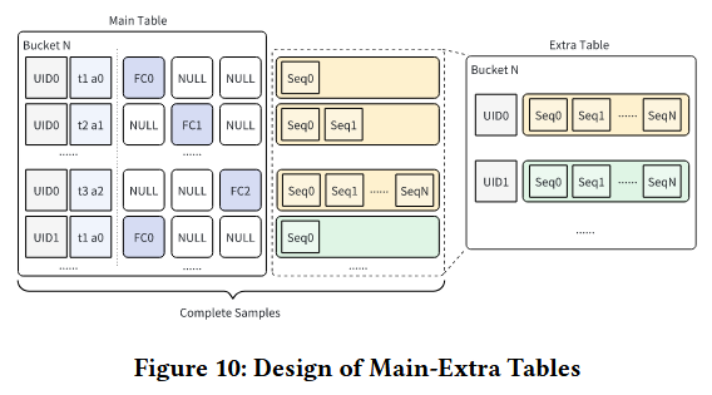
主表:存储数值型行为特征,如点击、点赞、转化等实时性较强的信号。这些特征变化频繁。
附加表:存储相对稳定且冗长的用户行为序列特征。每个用户在此表中仅保留最新的一份完整序列数据。
04 实验
(1)存储格式性能:
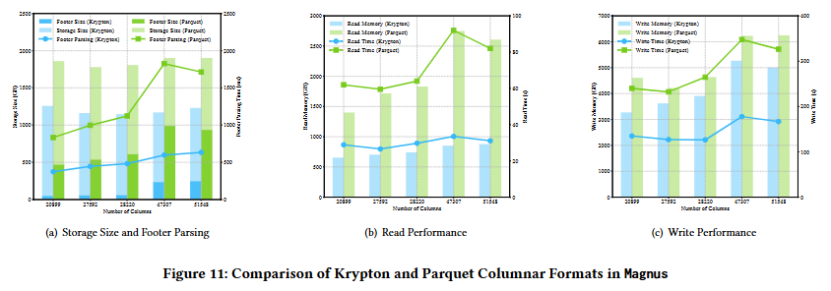
Krypton格式在存储大小上比Parquet格式节省了超过30%,并且在内存使用和读写吞吐量上表现更优。
(2)Bolb格式性能
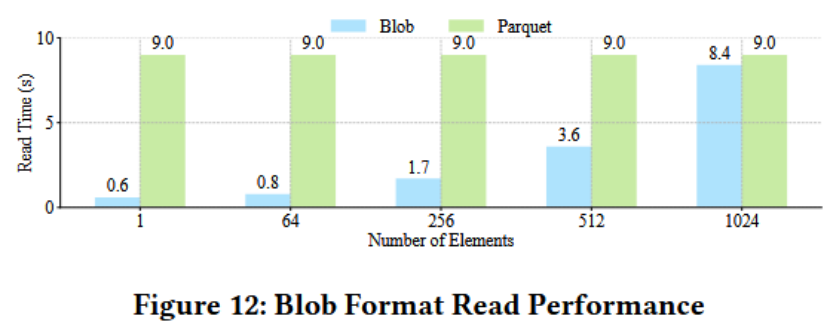
Blob格式在读取部分元素时显著优于Parquet格式,特别是在处理视频帧提取等任务时。
(3)元数据规划性能
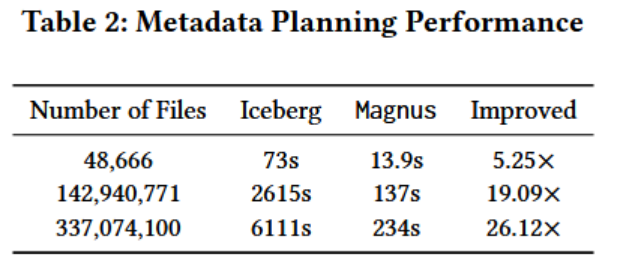
优化后的Magnus在解析效率上比Iceberg快5倍到26倍,特别是在处理大量文件时。
(4)更新和Upset性能
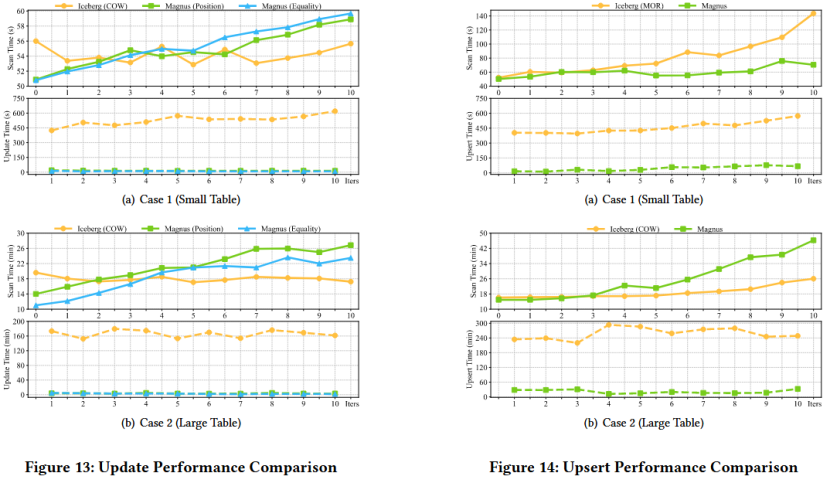
Magnus在写入性能上显著优于Iceberg,同时在读取性能上也保持了竞争力,特别是在处理频繁更新的工作负载时。
(5)LRM和LMM训练性能
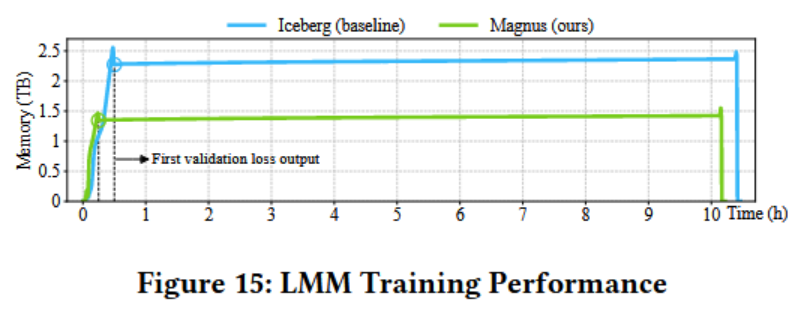
优化后的Magnus减少了40%的内存消耗,将启动时间从30分钟缩短至15分钟,并略微缩短了20分钟的训练时长。