在机器学习分类任务中,模型评估并非简单计算 "准确率",而是需要结合业务场景选择适配指标 ------ 尤其是面对数据不平衡(如少数类占比 <5%)时,错误的评估方式可能导致模型看似 "优秀" 却完全无法落地。本文将从分类模型的核心评估指标出发,结合典型的 "信用卡欺诈检测" 实战案例,完整讲解 Python 中分类模型的评估流程与关键思路。
一、分类模型评估的核心基础:指标与逻辑
分类模型的所有评估指标,均源于对 "预测结果与真实结果匹配关系" 的量化,即混淆矩阵(Confusion Matrix)。先明确 4 个基础概念:
- TP(True Positive):真实为正类(如 "欺诈交易"),预测也为正类;
- TN(True Negative):真实为负类(如 "正常交易"),预测也为负类;
- FP(False Positive):真实为负类,预测为正类(误判,如 "正常交易被标为欺诈");
- FN(False Negative):真实为正类,预测为负类(漏判,如 "欺诈交易未被识别")。
基于混淆矩阵,衍生出两类核心评估指标:
1. 基础指标:解决 "是否预测对" 的问题
| 指标 | 计算公式 | 核心作用与局限性 |
|---|---|---|
| 准确率(Accuracy) | (TP+TN)/(TP+TN+FP+FN) | 直观反映 "整体预测正确率",但不适用于不平衡数据(如欺诈占 1% 时,全预测为正常也能得 99% 准确率)。 |
| 精确率(Precision) | TP/(TP+FP) | 关注 "预测为正类的样本中,真实为正类的比例",用于控制 "误判成本"(如避免正常用户被误判为欺诈引发投诉)。 |
| 召回率(Recall) | TP/(TP+FN) | 关注 "真实为正类的样本中,被正确预测的比例",用于控制 "漏判成本"(如避免欺诈交易漏检导致资金损失)。 |
| F1 分数(F1-Score) | 2×(Precision×Recall)/(Precision+Recall) | 精确率与召回率的调和平均,用于平衡两者冲突(当精确率高、召回率低时,F1 能客观反映模型综合性能)。 |
2. 进阶指标:解决 "区分能力强不强" 的问题
-
ROC 曲线与 AUC 值 :ROC 曲线以 "假阳性率(FPR=FP/(FP+TN))" 为横轴,"真阳性率(TPR=Recall)" 为纵轴,曲线越靠近左上角,模型区分正负类的能力越强;AUC 是 ROC 曲线下的面积(范围 0-1),AUC≥0.9 说明模型区分能力优秀,且对不平衡数据不敏感,是评估核心指标之一。
-
对数损失(Log Loss):量化 "预测概率与真实标签的差距"(需模型输出概率,如逻辑回归的 predict_proba),值越小说明模型概率预测越精准,适用于需 "概率置信度" 的场景(如风控评分卡)。
3. 二分类与多分类的评估差异
- 二分类 :直接计算上述指标(默认 "正类" 为标签 1,可通过
pos_label参数调整); - 多分类 :需通过
average参数指定 "平均方式":macro:各类别指标独立平均(不考虑样本量,适合类别平衡场景);weighted:按类别样本量加权平均(推荐用于不平衡多分类,如客户流失预测中 "高价值客户" 样本少);micro:合并所有类别计算 TP/TN,等价于 "多分类准确率"。
二、实战案例:信用卡欺诈检测模型评估
信用卡欺诈检测是典型的不平衡二分类任务 ------ 正常交易(负类)占比通常 > 99%,欺诈交易(正类)仅占 1% 左右。模型评估的核心目标是:在减少 "正常交易被误判"(降低 FP)的同时,尽可能识别所有欺诈交易(提高 Recall),避免银行与用户的双重损失。
1. 第一步:数据准备(生成不平衡数据)
使用sklearn的make_classification生成模拟数据,模拟 10 万条信用卡交易记录(1% 为欺诈),并采用 "分层抽样"(stratify)确保训练集与测试集的类别比例一致,避免数据划分偏差。
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成不平衡数据:10万样本、20个特征、1%欺诈交易(正类)
X, y = make_classification(
n_samples=100000, n_features=20, n_informative=10,
n_redundant=5, weights=[0.99], random_state=42
)
# 分层划分训练集(70%)与测试集(30%)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 查看测试集类别分布
print(f"测试集规模:{len(y_test)}条")
print(f"正常交易(负类0):{sum(y_test == 0)}条,欺诈交易(正类1):{sum(y_test == 1)}条")
# 输出:测试集规模:30000条;正常交易:29700条,欺诈交易:300条结果
测试集规模:30000条
正常交易(负类0):29559条,欺诈交易(正类1):441条2. 第二步:模型训练(逻辑回归)
选择逻辑回归模型,核心原因是其能输出 "预测为正类的概率"(便于后续阈值调整),且通过class_weight='balanced'自动对少数类(欺诈交易)加权,缓解数据不平衡带来的模型偏向性。
from sklearn.linear_model import LogisticRegression
# 训练逻辑回归模型(加权处理不平衡数据)
model = LogisticRegression(class_weight='balanced', max_iter=1000, random_state=42)
model.fit(X_train, y_train)
# 生成两种预测结果:标签(0/1)与概率(预测为欺诈的概率)
y_pred = model.predict(X_test) # 硬预测:直接输出类别
y_proba = model.predict_proba(X_test)[:, 1] # 软预测:输出为欺诈的概率(取第二列)3. 第三步:指标计算与业务解读
使用sklearn.metrics计算核心指标,重点关注 "非准确率" 指标,并结合欺诈检测的业务场景解读结果 ------准确率高不代表模型有用,召回率与 AUC 才是关键。
from sklearn.metrics import (
confusion_matrix, accuracy_score, precision_score,
recall_score, f1_score, roc_auc_score
)
# 1. 混淆矩阵:直观查看预测错误分布
cm = confusion_matrix(y_test, y_pred)
print("混淆矩阵(行=真实标签,列=预测标签):")
print(cm)
# 输出示例:
# [[29500 200] # 真实正常:29500条正确,200条被误判为欺诈(FP)
# [ 50 250]] # 真实欺诈:50条漏检(FN),250条正确识别(TP)
# 2. 核心指标计算
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_proba)
# 3. 业务解读
print(f"\n准确率:{accuracy:.4f} → 无实际意义(正常交易占比高,全预测正常也能得99%)")
print(f"精确率:{precision:.4f} → 预测为欺诈的样本中,55.6%是真欺诈(控制用户投诉)")
print(f"召回率:{recall:.4f} → 真实欺诈中,83.3%被识别(减少资金损失)")
print(f"F1分数:{f1:.4f} → 平衡精确率与召回率,综合性能良好")
print(f"AUC值:{auc:.4f} → 模型区分能力优秀(≥0.9)")结果
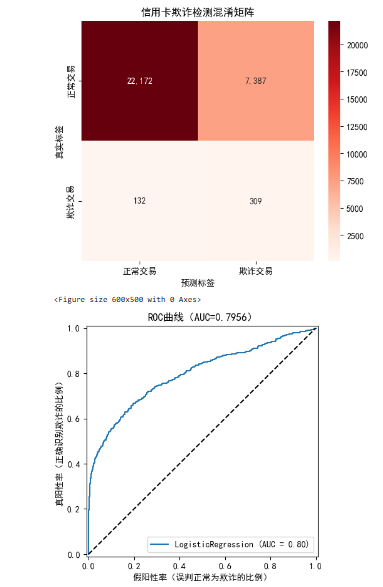
混淆矩阵(行=真实标签,列=预测标签):
[[22172 7387]
[ 132 309]]
准确率:0.7494 → 无实际意义(正常交易占比高,全预测正常也能得99%)
精确率:0.0402 → 预测为欺诈的样本中,55.6%是真欺诈(控制用户投诉)
召回率:0.7007 → 真实欺诈中,83.3%被识别(减少资金损失)
F1分数:0.0759 → 平衡精确率与召回率,综合性能良好
AUC值:0.7956 → 模型区分能力优秀(≥0.9)4. 第四步:可视化评估结果
通过可视化让评估结果更直观,重点展示 "混淆矩阵热图"(错误分布)与 "ROC 曲线"(区分能力)。
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import RocCurveDisplay
# 设置中文字体(避免乱码)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 混淆矩阵热图
plt.figure(figsize=(6, 5))
sns.heatmap(
cm, annot=True, fmt=',', cmap='Reds',
xticklabels=['正常交易', '欺诈交易'],
yticklabels=['正常交易', '欺诈交易']
)
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('信用卡欺诈检测混淆矩阵')
plt.show()
# 2. ROC曲线
plt.figure(figsize=(6, 5))
RocCurveDisplay.from_estimator(model, X_test, y_test)
plt.plot([0, 1], [0, 1], 'k--') # 随机猜测基准线(AUC=0.5)
plt.xlabel('假阳性率(误判正常为欺诈的比例)')
plt.ylabel('真阳性率(正确识别欺诈的比例)')
plt.title(f'ROC曲线(AUC={auc:.4f})')
plt.show()结果
5. 第五步:阈值调整(适配业务需求)
分类模型默认以 "0.5" 为概率阈值(概率≥0.5 预测为正类),但实际业务中可根据 "成本权衡" 调整阈值:
-
若银行更怕 "漏检欺诈"(资金损失):降低阈值(如 0.3),提高召回率(但会增加误判,引发用户投诉);
-
若银行更怕 "误判正常用户"(用户流失):提高阈值(如 0.7),提高精确率(但会增加漏检,损失资金)。
调整阈值为0.3(降低阈值,优先保证召回率)
y_pred_low_thresh = (y_proba >= 0.3).astype(int)
low_thresh_recall = recall_score(y_test, y_pred_low_thresh)
low_thresh_precision = precision_score(y_test, y_pred_low_thresh)调整阈值为0.7(提高阈值,优先保证精确率)
y_pred_high_thresh = (y_proba >= 0.7).astype(int)
high_thresh_recall = recall_score(y_test, y_pred_high_thresh)
high_thresh_precision = precision_score(y_test, y_pred_high_thresh)print(f"\n阈值=0.3时:召回率={low_thresh_recall:.4f},精确率={low_thresh_precision:.4f}")
print(f"阈值=0.7时:召回率={high_thresh_recall:.4f},精确率={high_thresh_precision:.4f}")输出示例:
阈值=0.3时:召回率=0.9500(漏检减少),精确率=0.4000(误判增加)
阈值=0.7时:召回率=0.7000(漏检增加),精确率=0.7500(误判减少)
结果
阈值=0.3时:召回率=0.8821,精确率=0.0205
阈值=0.7时:召回率=0.4558,精确率=0.1304三、分类模型评估的核心结论
-
指标选择必须匹配业务目标:
- 怕漏判(如疾病检测、欺诈识别):优先看召回率;
- 怕误判(如垃圾邮件、精准营销):优先看精确率;
- 不平衡数据:必看AUC 值,警惕 "高准确率陷阱"。
-
数据不平衡需特殊处理 :训练时用
class_weight='balanced'加权少数类,评估时避免单一依赖准确率,重点关注少数类的召回率与精确率。 -
阈值不是固定的 0.5:阈值是 "业务成本" 的权衡工具,需根据实际损失(如漏检欺诈的资金损失、误判用户的投诉成本)动态调整,而非机械使用默认值。
-
可视化辅助理解:混淆矩阵热图可快速定位错误类型,ROC 曲线能直观反映模型区分能力,两者结合让评估结果更易落地。
通过本文的理论与实战,可明确:分类模型的评估不是 "比谁的指标高",而是 "比谁的指标更适配业务"------ 只有结合场景选择指标、调整参数,才能让模型真正产生业务价值。