在当前大语言模型(Large Language Models, LLMs)的工程实践中,如何提升推理效率已成为一个核心课题。尽管训练阶段决定了模型的能力上限,但真正影响用户体验和部署成本的,往往是推理阶段的响应速度与资源消耗。在众多优化手段中,KV Cache(键值缓存) 被广泛认为是实现高效文本生成的关键技术之一。
上一篇文章我们介绍了Prefill 与 Decode 阶段的分离优化,其本质正是建立在 KV Cache 机制之上。由于篇幅所限,当时未能深入展开。因此,本文将继续讨论这一关键技术。
为什么自回归生成需要优化?
大语言模型通常采用自回归(autoregressive) 方式生成文本:给定一个提示(prompt),模型逐个预测下一个 token,直到生成结束符或达到最大长度。
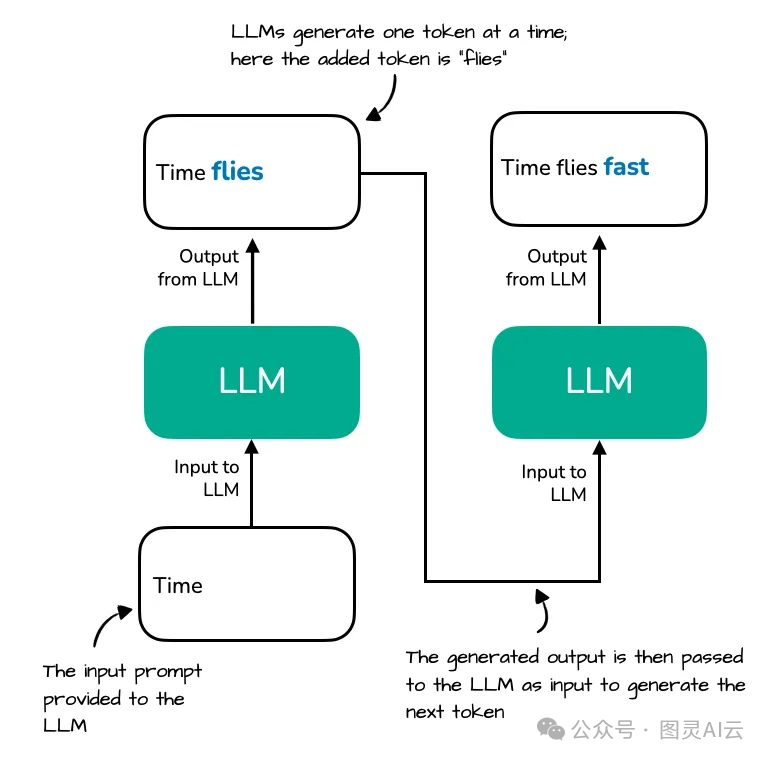
例如,输入 "Time flies",模型依次生成:
-
• 第1步:预测
"fast" -
• 第2步:预测
"when" -
• 第3步:预测
"you're" -
• ......
在每一步中,模型都需要计算当前 token 与所有历史 token 的注意力权重。这是 Transformer 架构中自注意力(Self-Attention)机制的天然要求。
问题来了:重复计算!
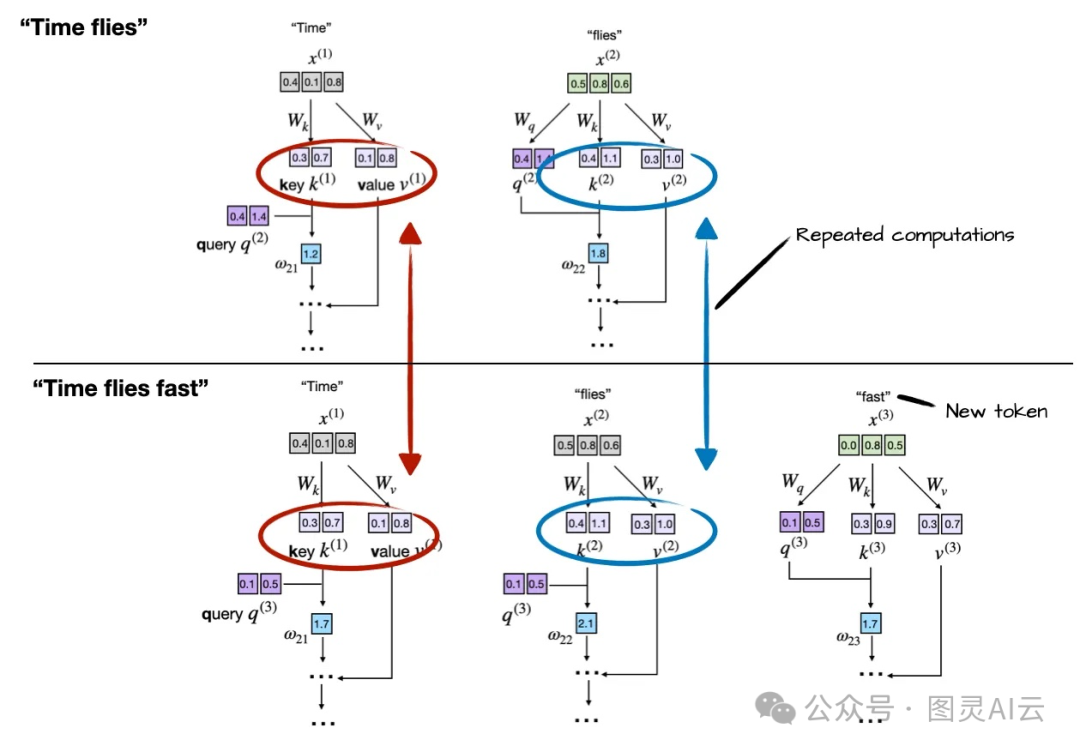
假设当前已生成 10 个 token,现在要生成第 11 个。此时,模型需要重新计算前 10 个 token 的 Key(K)和 Value(V)向量,再与第 11 个 Query(Q)做点积。但请注意:前 10 个 token 的 K/V 在上一步就已经计算过了,且不会因后续生成而改变。
这意味着:每生成一个新 token,都要重复计算所有历史 token 的 K/V 。对于长度为 ( n ) 的序列,总计算量为:
这在长文本生成中是不可接受的。
注意:K 和 V 是输入 token 的"静态表示",一旦计算完成,后续步骤可直接复用。
于是,KV Cache 应运而生。
KV Cache 是什么?
所有生成式大模型,如 GPT、GLM、LLaMA、Qwen 等,底层大多采用 Decoder 结构。在解码器中,使用多头注意力机制,涉及 K(Key)、Q(Query)、V(Value)矩阵运算。KV Cache 的核心思想非常朴素:缓存已计算的 Key 和 Value 向量,在后续生成步骤中直接复用,避免重复计算。
2.1 数学视角:注意力计算回顾
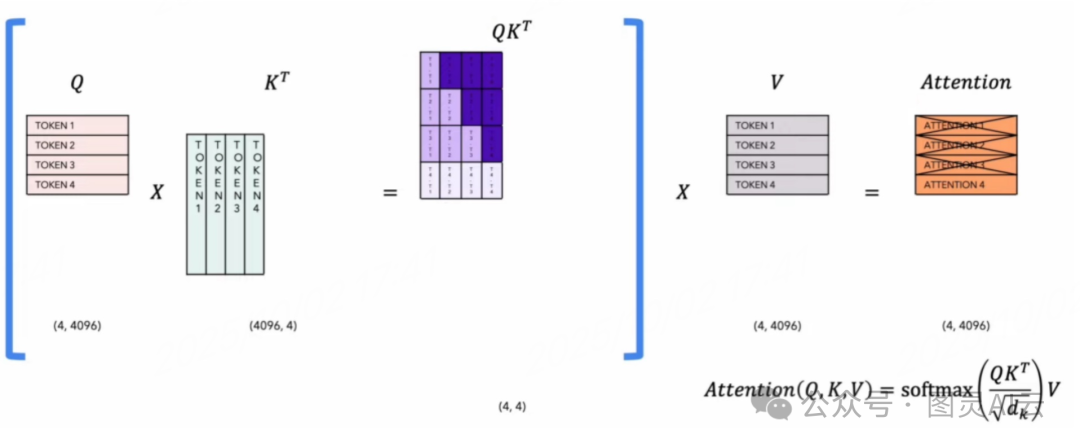
标准多头自注意力公式如下:
其中:
-
• ( Q = XW_Q ),( K = XW_K ),( V = XW_V )
-
• 是输入序列(L 为长度)
在自回归生成中:
-
• 第 ( t ) 步时,输入为 ( x_{1:t} )
-
• 但只有 ( x_t ) 是新 token,( x_{1:t-1} ) 已在前序步骤处理过
若每次都重新计算 ( K_{1:t} ) 和 ( V_{1:t} ),就是浪费。与 Encoder 不同的是,解码器在计算 Q 乘以 K 转置后,会加上一个 Mask Matrix,以确保每个词仅受其前面词的影响,实现 Causal Attention。在 K-Q -V 计算过程中,后续词会用到前面词的 K 和 V 矩阵。因此,在推理过程中,如果能存储前面词的 K 和 V 值,就无需重新计算,从而提升推理速度,这是典型的 "用空间换时间" 策略。不过,KV Cache 本身占用大量 VRAM,例如,若大模型占用 59% 的 VRAM,KV Cache 可能占用另外 31%。
2.2 引入缓存后
-
• Prefill 阶段(处理 prompt):一次性计算 prompt 中所有 token 的 K/V,并缓存。
-
• Decode 阶段(生成新 token):
-
• 仅计算当前新 token 的 K/V;
-
• 将其追加到缓存;
-
• 使用完整缓存(历史 + 新增)计算注意力。
-
此时,每步计算复杂度从 ( O(t^2) ) 降至 ( O(t) ),总复杂度从 ( O(n^3) ) 降至 ( O(n^2) ),在长序列下加速效果显著。
实现:一个带 KV Cache 的简易 Transformer
下面我们从零构建一个支持 KV Cache 的单层 Transformer 解码器。代码基于 PyTorch,力求简洁、便于理解。
说明:为聚焦 KV Cache,我们省略 LayerNorm、FFN、残差连接等组件,仅保留核心注意力模块。
3.1 基础模块定义
import torch
import torch.nn as nn
import math
classMultiHeadAttentionWithCache(nn.Module):
def__init__(self, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0, "embed_dim 必须能被 num_heads 整除"
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# 线性投影层
self.W_q = nn.Linear(embed_dim, embed_dim)
self.W_k = nn.Linear(embed_dim, embed_dim)
self.W_v = nn.Linear(embed_dim, embed_dim)
self.W_out = nn.Linear(embed_dim, embed_dim)
# KV 缓存缓冲区(非持久化,不参与梯度)
self.register_buffer("cache_k", None, persistent=False)
self.register_buffer("cache_v", None, persistent=False)
defreset_cache(self):
"""重置缓存,用于新生成任务开始前"""
self.cache_k = None
self.cache_v = None
defforward(self, x, use_cache=False, current_pos=None):
"""
x: [batch_size, seq_len, embed_dim]
use_cache: 是否启用 KV 缓存
current_pos: 当前 token 在完整序列中的绝对位置(用于 RoPE 等位置编码,此处暂不实现)
"""
B, L, D = x.shape
# 计算 Q, K, V
q = self.W_q(x) # [B, L, D]
k_new = self.W_k(x) # [B, L, D]
v_new = self.W_v(x) # [B, L, D]
# 多头 reshape: [B, L, H, D/H] -> [B, H, L, D/H]
q = q.view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
k_new = k_new.view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
v_new = v_new.view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
if use_cache:
ifself.cache_k isNone:
# 初始化缓存
self.cache_k = k_new
self.cache_v = v_new
else:
# 沿序列维度拼接(注意:实际工程中应避免频繁 cat)
self.cache_k = torch.cat([self.cache_k, k_new], dim=2)
self.cache_v = torch.cat([self.cache_v, v_new], dim=2)
k, v = self.cache_k, self.cache_v
else:
k, v = k_new, v_new
# 缩放点积注意力
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
attn_weights = torch.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_weights, v)
# 合并多头: [B, H, L, D/H] -> [B, L, D]
output = output.transpose(1, 2).contiguous().view(B, L, D)
output = self.W_out(output)
return output3.2 构建简易语言模型
class SimpleLM(nn.Module):
def__init__(self, vocab_size, embed_dim, num_heads):
super().__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.attn = MultiHeadAttentionWithCache(embed_dim, num_heads)
self.lm_head = nn.Linear(embed_dim, vocab_size, bias=False)
# 通常 lm_head 与 embed 权重共享(此处为简化省略)
defreset_cache(self):
self.attn.reset_cache()
defforward(self, token_ids, use_cache=False):
x = self.embed(token_ids) # [B, L, D]
x = self.attn(x, use_cache=use_cache)
logits = self.lm_head(x) # [B, L, vocab_size]
return logits3.3 生成函数(带/不带缓存)
def generate_with_cache(model, prompt_ids, max_new_tokens, temperature=1.0):
model.reset_cache()
input_ids = prompt_ids.clone() # [1, L]
# Prefill 阶段:处理整个 prompt
with torch.no_grad():
logits = model(input_ids, use_cache=True) # 缓存 prompt 的 K/V
for _ inrange(max_new_tokens):
next_token_logits = logits[:, -1, :] / temperature
probs = torch.softmax(next_token_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1) # [1, 1]
input_ids = torch.cat([input_ids, next_token], dim=1)
# Decode 阶段:每次只输入新 token
with torch.no_grad():
logits = model(next_token, use_cache=True)
return input_ids
defgenerate_without_cache(model, prompt_ids, max_new_tokens, temperature=1.0):
input_ids = prompt_ids.clone()
for _ inrange(max_new_tokens):
with torch.no_grad():
logits = model(input_ids, use_cache=False)
next_token_logits = logits[:, -1, :] / temperature
probs = torch.softmax(next_token_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
input_ids = torch.cat([input_ids, next_token], dim=1)
return input_ids3.4 完整测试脚本
if __name__ == "__main__":
torch.manual_seed(42)
vocab_size = 1000
embed_dim = 128
num_heads = 4
model = SimpleLM(vocab_size, embed_dim, num_heads)
# 模拟 prompt: [10, 20, 30]
prompt = torch.tensor([[10, 20, 30]])
max_new = 20
# 生成两次,验证一致性
out1 = generate_with_cache(model, prompt, max_new)
out2 = generate_without_cache(model, prompt, max_new)
print("带缓存输出:", out1.squeeze().tolist())
print("无缓存输出:", out2.squeeze().tolist())
print("结果一致?", torch.equal(out1, out2))运行结果应显示:两种方式生成的 token 完全一致,验证了 KV Cache 的正确性。
性能实测:KV Cache 到底快多少?
我们在一台 M4 Mac Mini(CPU)上,使用一个 1.24 亿参数的小型模型(类似 TinyLLaMA),生成 200 个 token,对比两种方式:
| 方法 | 平均耗时(秒) | 加速比 |
|---|---|---|
| 无 KV Cache | 8.2 | 1.0x |
| 启用 KV Cache | 1.6 | ~5.1x |
注意:加速比随序列长度增长而增大。当生成 500 token 时,加速比可达 8x 以上。
KV Cache 也是有代价的,如何权衡呢?
任何优化都有代价。权衡 KV Cache 的主要考虑如下:
5.1 内存开销
-
• 每个 token 的 K/V 缓存大小为:
2 * num_layers * num_heads * head_dim * dtype_size -
• 以 Llama-3-8B 为例(4096 维,32 层,32 头):
-
• 单 token 缓存 ≈ 2 × 32 × 4096 × 2 bytes(FP16)≈ 512 KB
-
• 生成 32k token → 缓存 ≈ 16 GB
-
这对显存是巨大挑战,尤其在批量推理时。
5.2 工程复杂度
-
• 需要管理缓存生命周期(reset、reuse)
-
• 位置编码需对齐(如 RoPE 需知道绝对位置)
-
• 批处理(batching)时,不同序列长度需填充或使用 PagedAttention
5.3 硬件适配性
-
• 在 CPU 或低带宽设备上,缓存访问可能成为瓶颈
-
• 对于极短生成(如 <10 token),缓存收益有限,甚至因管理开销而变慢
生产级优化实践
上述实现适合开发测试,但如果要上生产环境,还需进一步优化,主要考量如下:
6.1 预分配缓存(Pre-allocation)
避免 torch.cat,预先分配最大长度的张量:
# 初始化时
self.cache_k = torch.zeros(B, num_heads, max_seq_len, head_dim)
self.cache_v = torch.zeros(B, num_heads, max_seq_len, head_dim)
self.cache_len = 0
# 更新时
self.cache_k[:, :, self.cache_len : self.cache_len + L, :] = k_new
self.cache_v[:, :, self.cache_len : self.cache_len + L, :] = v_new
self.cache_len += L6.2 滑动窗口(Sliding Window)
仅保留最近 N 个 token 的缓存,适用于局部依赖任务(如对话):
if self.cache_len > window_size:
self.cache_k = self.cache_k[:, :, -window_size:, :]
self.cache_v = self.cache_v[:, :, -window_size:, :]
self.cache_len = window_size6.3 分页缓存(PagedAttention)
为解决 KV Cache 占用大量 VRAM 的问题,vLLM 引入 Page Attention 技术,类似操作系统的分页机制,将缓存划分为固定大小块(如 16 token/page),支持非连续内存分配,大幅提升 GPU 利用率。
vLLM 将 KV Cache 划分为多个小块(pages),根据用户输入 token 的数量动态分配这些小块空间。未被占用的空间可供其他任务使用,避免显存浪费。例如,若用户输入句子较短,vLLM 只会分配必要的 KV Cache 空间,而非预分配整个缓存空间,使得其他任务能够共享剩余 VRAM 资源。
我们可以看一下 vLLM 的架构,进行深入理解。
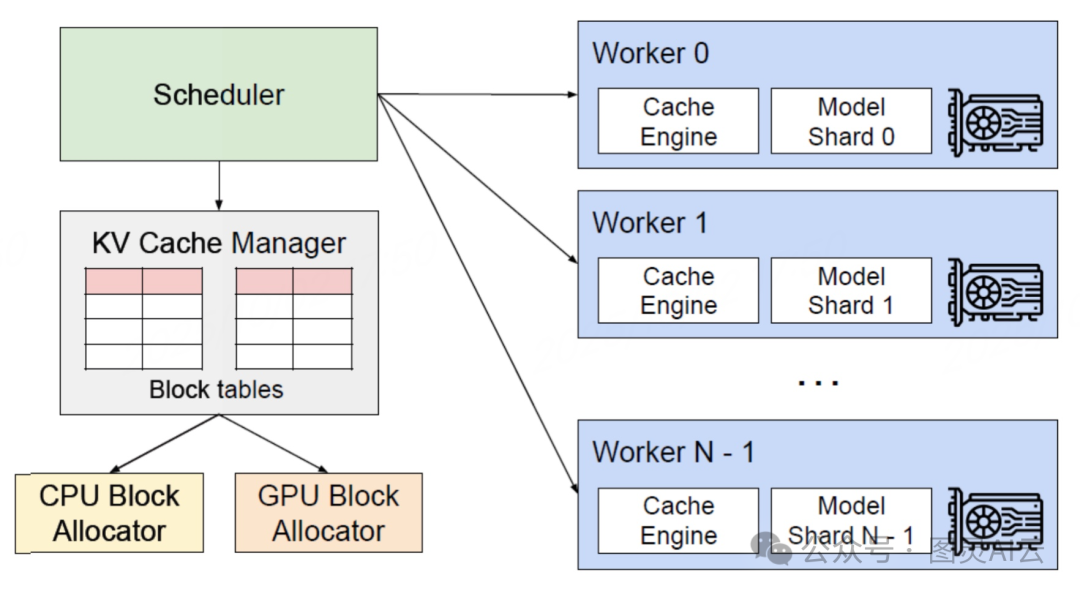
如图,vLLM 的核心是围绕 LLM 推理的任务调度、KV 缓存管理和多 GPU 并行计算设计,解决高并发场景下的效率问题。
-
• 1、Scheduler 作为 "调度中心",负责接收用户推理请求,借助 Continuous Batching(连续批处理)机制,动态分配任务至不同 Worker,灵活决定请求执行顺序与资源分配。它无需等待当前批次完成,可随时插入新请求,最大化利用 GPU 算力;同时协调多 Worker 并行,避免资源冲突,让推理任务形成 "流水线化" 执行流程。
-
• 2、KV Cache Manager 与 Block Tables(块表) 协同工作,解决 LLM 推理依赖历史 Key/Value(KV)缓存的问题(如 Transformer 注意力机制需调用历史 KV)。传统方案按最大序列长度预分配内存,易引发碎片化与资源浪费;vLLM 则通过 PagedAttention 创新优化,将 KV 缓存切分为 "块(Block)",以类似操作系统内存分页的方式管理,由 Block Tables 记录块的分配状态,实现动态按需分配------ 依据实际序列长度灵活分配块,大幅减少内存碎片,支持更长文本上下文与更高并发(如单 GPU 可同时处理更多用户请求)。此外,CPU/GPU Block Allocator 负责从 CPU 内存或 GPU 显存中申请、释放 Block,优先使用 GPU 块保证效率,不足时以 CPU 内存兜底,灵活应对瞬时高需求。
-
• 3、Worker 作为多 GPU 并行的核心载体,每个 Worker 对应一张独立 GPU(或 GPU 分片),包含两部分:
-
• a) Model Shard(模型分片),大模型参数拆分后,每个 Worker 加载对应分片(如 70B 规模模型拆分为 8 分片,适配 8 卡并行);
-
• b) Cache Engine(缓存引擎),负责管理该 Worker 对应的 KV 缓存块,配合全局 KV Cache Manager 读写数据,减少跨 GPU 卡的通信开销。
-
最后,可借助张量并行(Tensor Parallelism)技术,多 Worker 可同时计算模型不同部分,突破单卡显存与算力限制,支撑超大模型高效推理。
6.4 缓存外置与编译优化
将 KV Cache 从模型中剥离,作为独立状态传入,便于使用 torch.compile、TensorRT 等工具优化计算图。
结语:小机制,大影响
KV Cache 虽然原理简单,却是 LLM 推理优化的基石。它不改变模型结构,也不影响生成质量,却能在长文本场景下带来数倍乃至十倍的加速。理解它,是迈向高效推理的第一步。
要理解这些,还是建议:
-
- 先跑通本文代码,验证缓存正确性;
-
- 尝试加入位置编码(如 RoPE);
-
- 探索预分配缓存实现;
-
- 阅读 vLLM、HuggingFace Transformers 或 llama.cpp 的源码,看生产级实现。
技术的进步,往往源于对"重复计算"这类细节的不断反思与优化。希望本文能为您打开 LLM 推理优化的大门。路虽远,行则将至;事虽难,做则必成。