文章目录
- 一、构建与训练神经网络:TensorFlow实践
-
- [1.1 使用 Keras Sequential API 搭建网络](#1.1 使用 Keras Sequential API 搭建网络)
- [1.2 附录 手动实现前向传播的底层逻辑](#1.2 [附录] 手动实现前向传播的底层逻辑)
- [二、选学 人工智能与大脑的深层联系](#二、[选学] 人工智能与大脑的深层联系)
-
- [2.1 人工智能的分类](#2.1 人工智能的分类)
- [2.2 大脑的"单一学习算法"假说](#2.2 大脑的“单一学习算法”假说)
- 三、性能优化与训练流程再探
-
- [3.1 向量化:从 For 循环到矩阵乘法](#3.1 向量化:从 For 循环到矩阵乘法)
- [3.2 神经网络的训练流程](#3.2 神经网络的训练流程)
视频链接
吴恩达机器学习p47-56
一、构建与训练神经网络:TensorFlow实践
在上一篇文章中,我们从理论上了解了神经网络的结构。现在,我们将进入激动人心的实践环节,学习如何使用目前业界最主流的深度学习框架之一------TensorFlow,来高效地构建、训练并使用一个神经网络。
1.1 使用 Keras Sequential API 搭建网络
想象一下,如果每次搭建神经网络都需要我们手动编写复杂的矩阵运算,那将是一件非常繁琐且容易出错的事情。幸运的是,TensorFlow 的 Keras API 为我们提供了一套非常高级和直观的工具,其中最常用的就是 Sequential 模型。Sequential 意为"序列",它允许我们像搭积木一样,将网络层按我们设计的顺序一层一层地堆叠起来,形成一个完整的模型。

上图为我们展示了一个具体的例子。左侧是我们熟悉的咖啡烘焙预测模型的可视化结构,右侧则是其对应的 TensorFlow 代码实现。
model = Sequential([...]): 我们首先实例化一个Sequential容器。Dense(units=3, activation="sigmoid"): 这是我们的第一个隐藏层。Dense表示这是一个全连接层,意味着每个神经元都与前一层的所有输出相连。units=3指定了该层有3个神经元,activation="sigmoid"则指定了这些神经元使用的激活函数。Dense(units=1, activation="sigmoid"): 这是我们的输出层,只有一个神经元,同样使用 Sigmoid 函数,以输出一个0到1之间的概率值。
模型搭建完成后,整个机器学习的流程也变得异常简洁:
model.compile(...): 编译模型,这是训练前的准备步骤,我们将在后面详细讨论。model.fit(x, y): 这是训练模型的关键步骤,只需将我们的特征数据x和目标标签y传入,框架就会自动执行梯度下降等优化过程。model.predict(x_new): 训练完成后,我们可以用predict方法对全新的、未见过的数据进行预测。
对于更深、更复杂的网络,例如我们之前提到的手写数字识别模型,其构建逻辑是完全一样的,我们只需在 Sequential 列表中添加更多的 Dense 层即可。
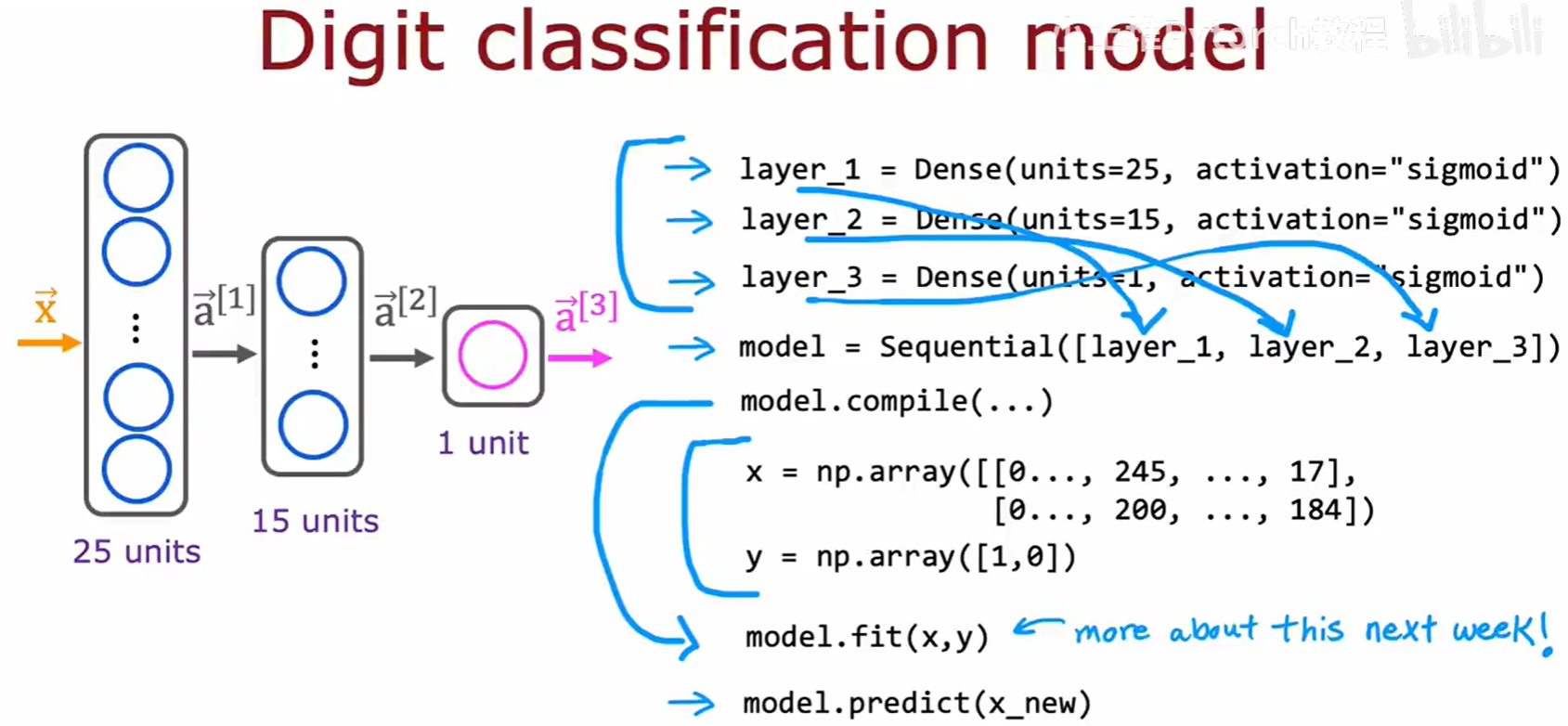
这种高度封装的API,让我们可以将精力更多地集中在模型的设计和实验上,而不是繁琐的底层实现。
1.2 附录 手动实现前向传播的底层逻辑
Sequential 模型非常方便,但作为学习者,理解其背后到底发生了什么是至关重要的。现在,我们就"掀开盖子",尝试用基础的 NumPy 库来手动实现一遍前向传播的过程,看看框架在后台究竟为我们做了什么。

我们再次回到咖啡烘焙模型。输入 x 是一个包含温度和烘焙时长的1D数组。
- 计算第一层(
layer 1) : 这一层有3个神经元,因此有3组独立的权重和偏置参数(w1_1, b1_1到w1_3, b1_3)。每个神经元都会对完整的输入x进行一次逻辑回归式的计算(点积后加偏置,再通过Sigmoid函数),得到各自的激活值a1_1,a1_2,a1_3。最后,我们将这3个激活值组合成一个数组a1,作为第一层的输出。

- 计算第二层(
layer 2) : 第二层(输出层)只有一个神经元,它接收来自第一层的完整输出a1作为自己的输入。然后,它用自己的参数w2_1, b2_1进行计算,得到最终的输出a2。
为了让代码更简洁、通用,避免为每个神经元单独编写代码,我们可以将同一层的所有权重向量 w⃗ 堆叠成一个权重矩阵 W,并将所有偏置 b 组合成一个偏置向量。

基于此,我们可以编写一个 dense 函数来模拟一整个网络层的计算。这个函数内部使用 for 循环,遍历该层的所有神经元(units),为每个神经元执行一次点积运算。然后,再编写一个 sequential 函数,按顺序调用 dense 函数,从而模拟整个网络的前向传播。这正是 Sequential 模型的底层逻辑的简化版。
二、选学 人工智能与大脑的深层联系
在我们深入探讨性能优化之前,让我们暂停一下,回顾神经网络的灵感来源------生物大脑。这背后有一些有趣的哲学和科学假说,也深刻地启发了人工智能的发展方向。
2.1 人工智能的分类
首先,我们需要明确我们正在讨论的AI处于什么范畴。目前,公众媒体和科幻作品中常常混淆两种截然不同的人工智能。
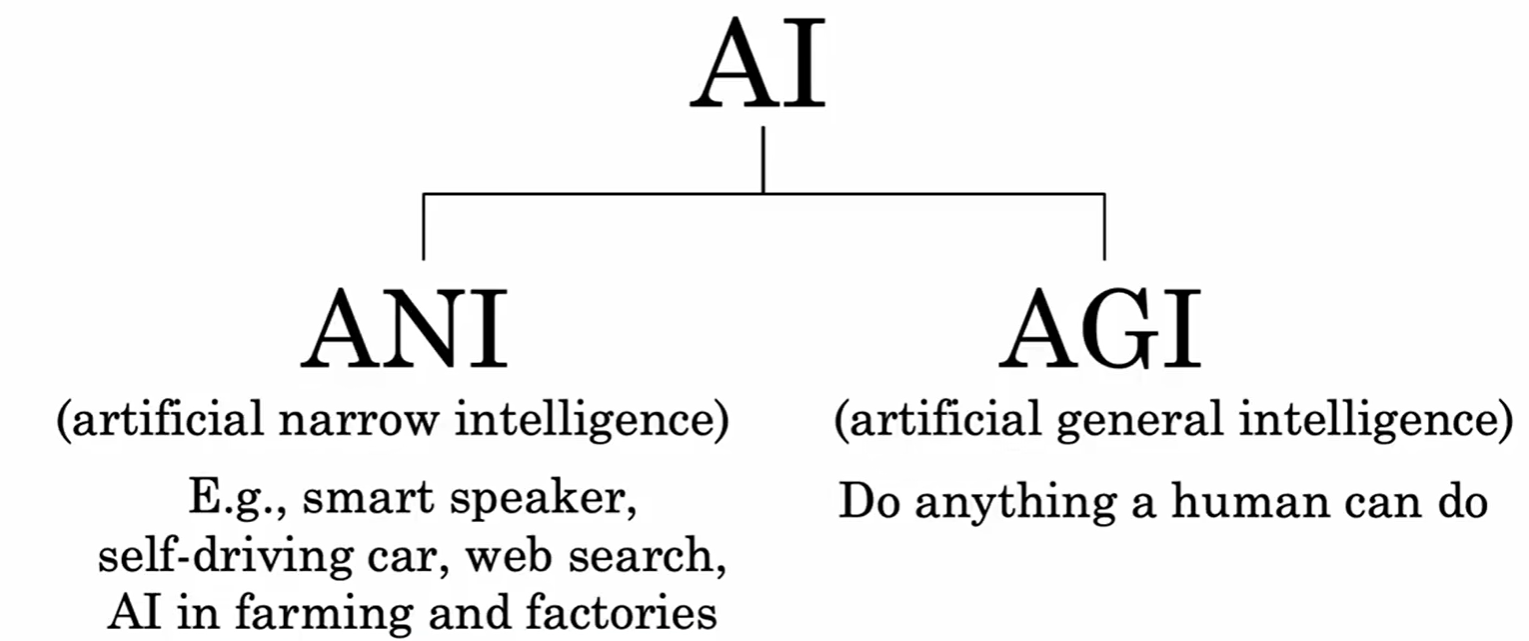
- 弱人工智能(Artificial Narrow Intelligence, ANI) : 这是我们目前已经实现并广泛应用的AI。它们被设计用来执行一个特定的、狭窄的任务,例如智能音箱的语音识别、自动驾驶的路线规划、网页搜索的排序等。它们在自己的领域可能远超人类,但无法跨领域工作。
- 通用人工智能(Artificial General Intelligence, AGI) : 这是科幻作品中常见的那种,拥有与人类相当、甚至超越人类的、能够执行任何智力任务的能力的AI。目前,AGI仍是一个非常遥远且充满挑战的理论目标。
2.2 大脑的"单一学习算法"假说
我们知道,生物神经元是构成大脑的基本计算单元,而人工神经元是其高度简化的数学模型。
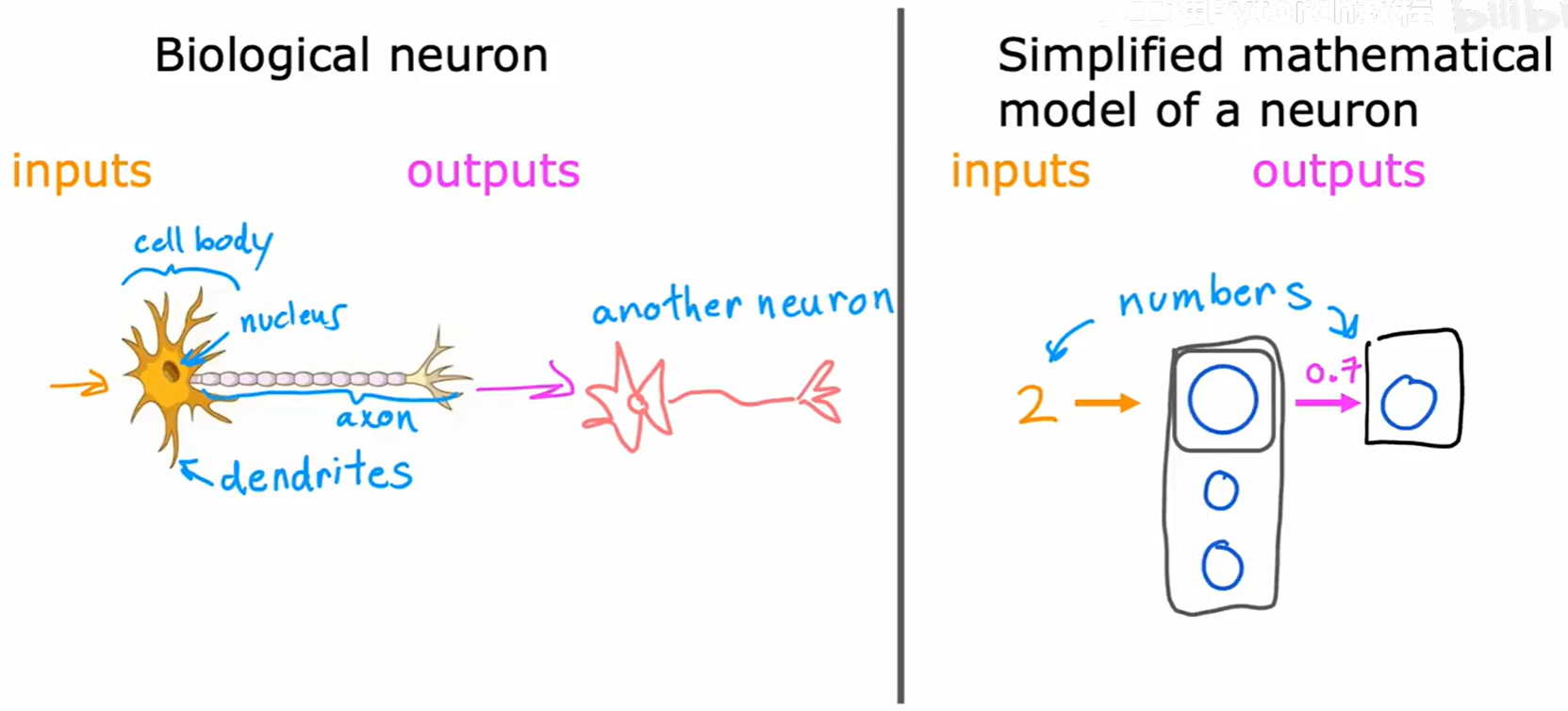
一个深刻的、驱动了早期AI研究的问题是:大脑的不同区域(视觉皮层、听觉皮层、触觉皮层等)虽然功能各异,但它们是用完全不同的底层算法,还是用同一种通用的学习算法来处理不同类型的信息的呢?
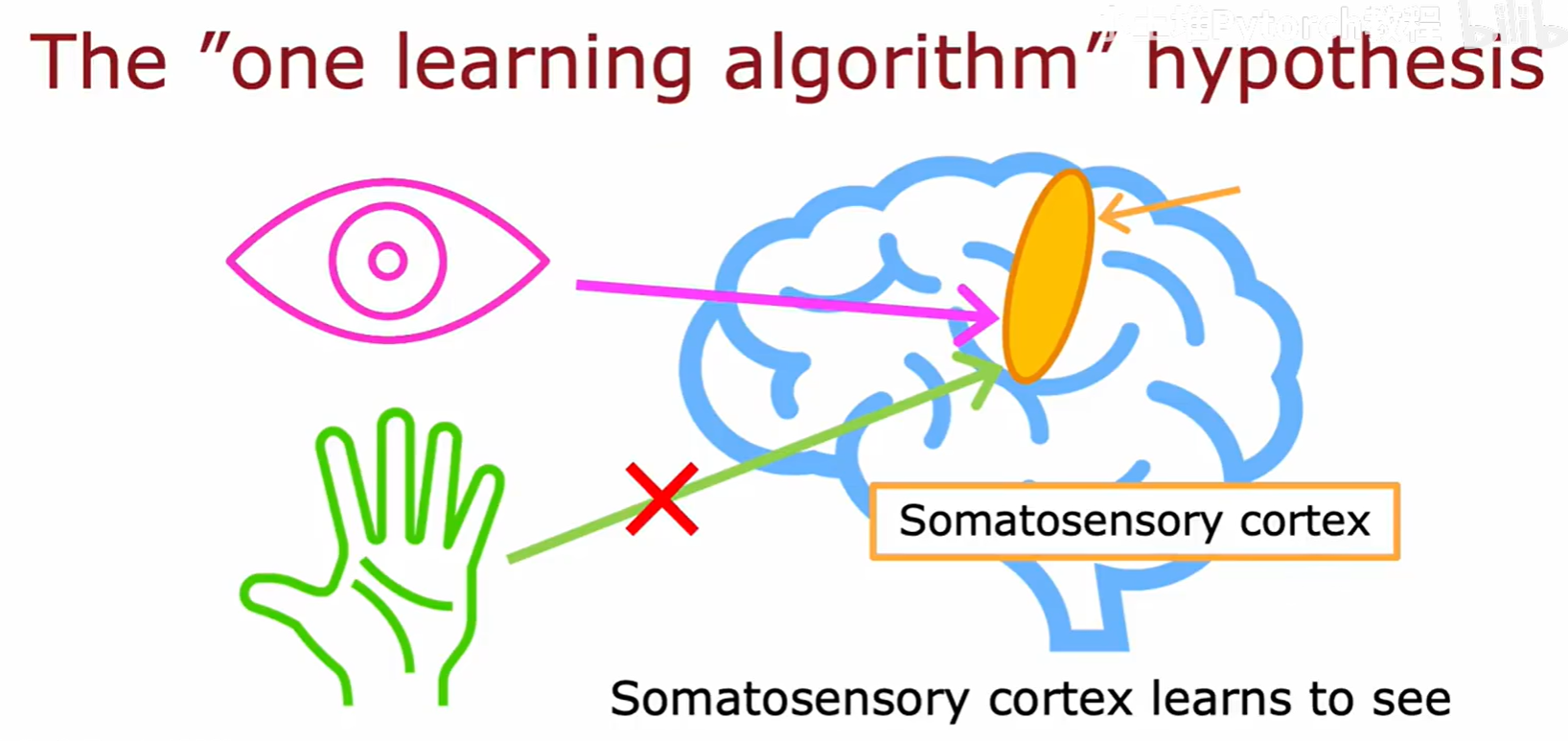
一个被称为"单一学习算法"假说 (The "one learning algorithm" hypothesis 的理论认为,大脑新皮层可能使用的就是一种通用的学习算法。神经科学的一些惊人实验为此提供了证据,比如神经重接实验,它表明如果将视觉信号强行输入到本应处理听觉信号的皮层区域,该区域最终也能学会"看"。
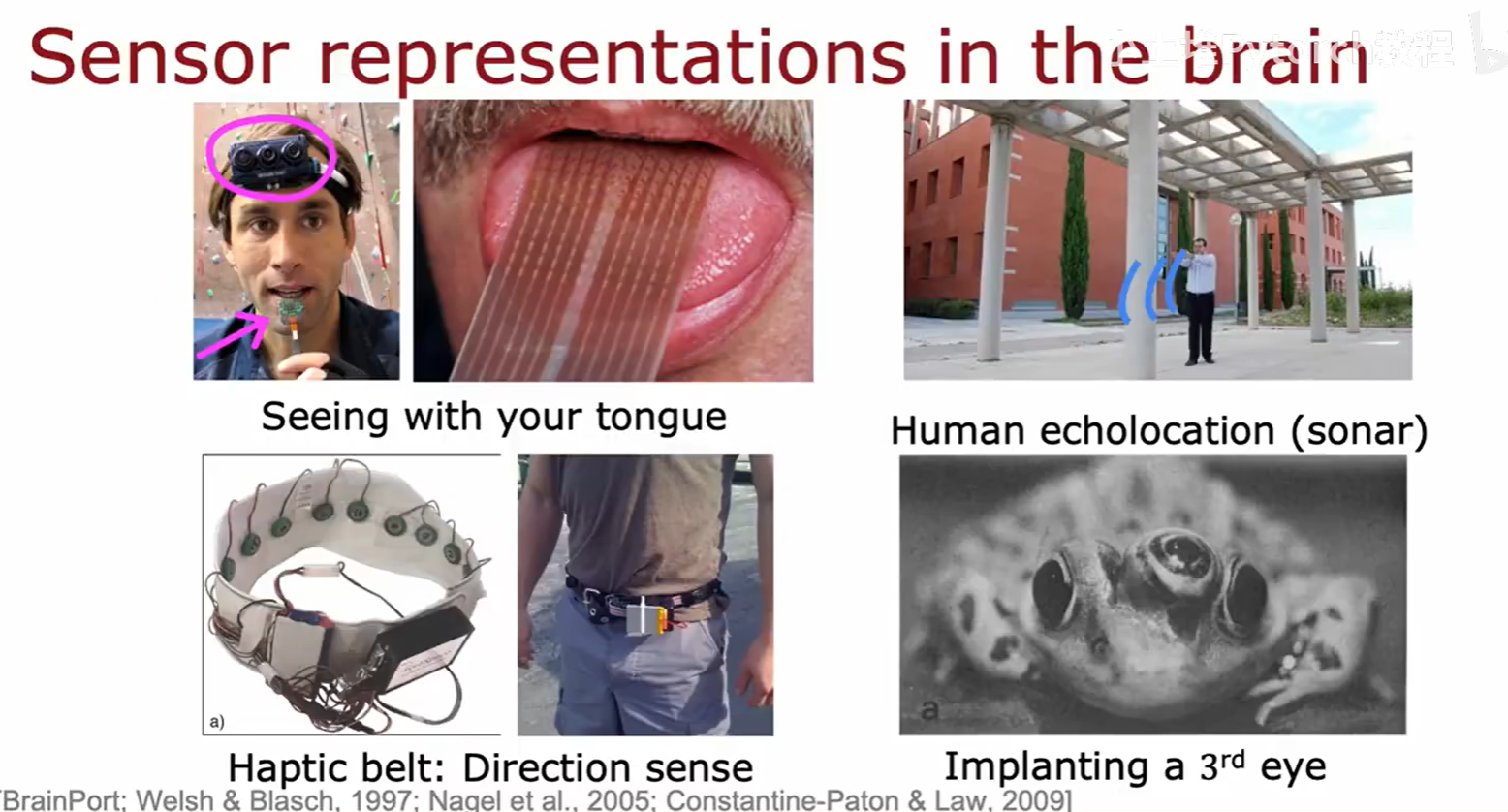
这些发现极大地鼓舞了AI研究者:我们或许也能找到一种或少数几种强大的、通用的学习算法(比如神经网络的反向传播算法),让计算机也能像大脑一样,用同一种底层逻辑来学习解决视觉、听觉、语言等各种看似不同的问题。这正是我们今天看到深度学习能够"一招鲜,吃遍天",在众多领域取得成功的原因之一。
三、性能优化与训练流程再探
现在,让我们回到工程实践,探讨如何让我们的神经网络计算得更快,以及如何用 TensorFlow 将训练流程的各个部分整合起来。
3.1 向量化:从 For 循环到矩阵乘法
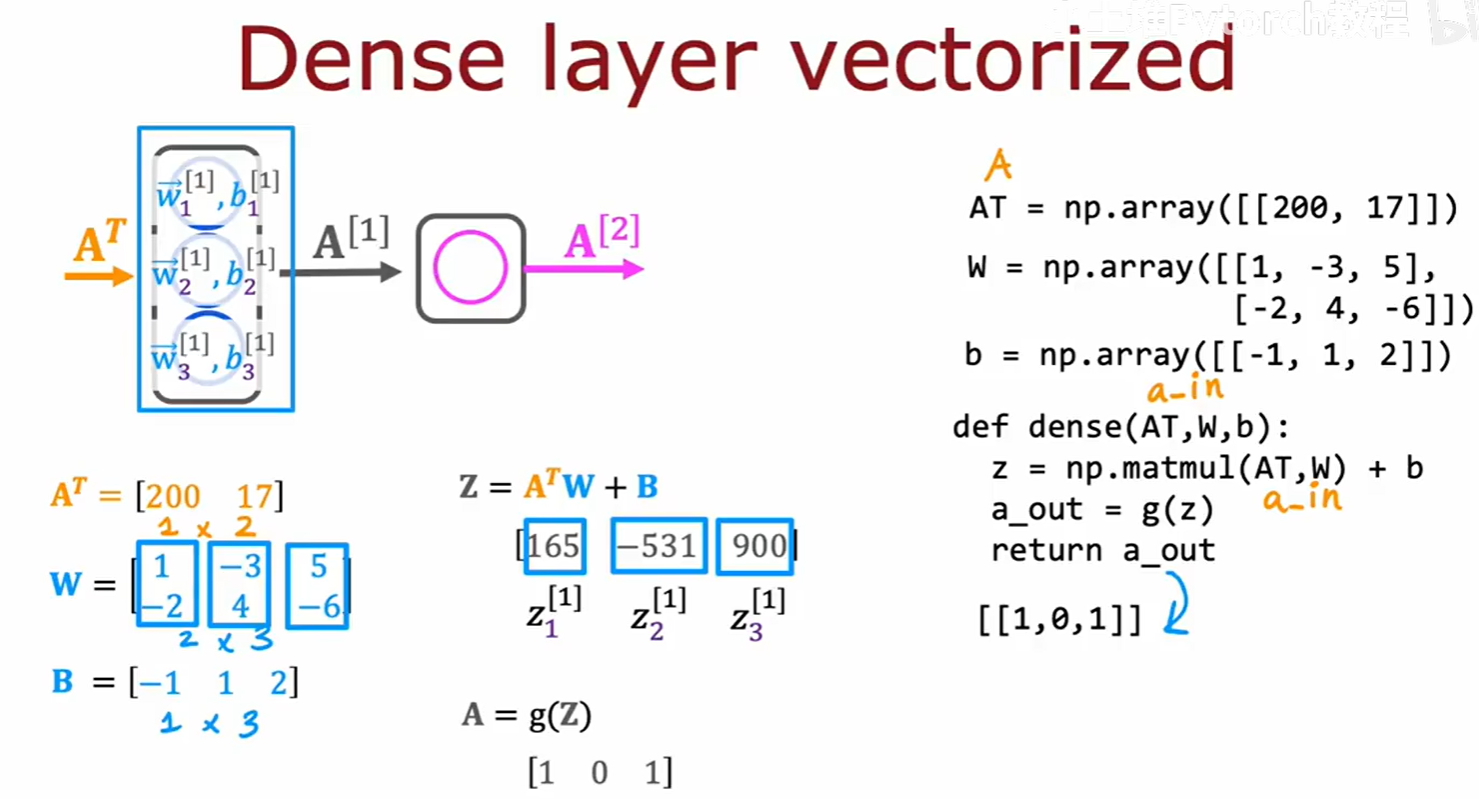
我们之前用 for 循环实现的 dense 函数虽然能工作,但在处理现代深度学习中的海量参数和数据时,其效率是完全无法接受的。专业库都使用向量化(Vectorization来获得数个数量级的性能提升。

向量化的核心思想,是用高度优化的矩阵运算 来替代 Python 层面上的显式 for 循环。如上图右侧所示,原本需要对每个神经元循环执行的点积操作,现在可以通过一次矩阵乘法(Matrix Multiplication和一次向量加法来完成。这种方式能够充分利用现代硬件(CPU/GPU)的并行计算能力,速度会快得多。
要进行矩阵乘法,我们需要熟悉一些基本操作,例如矩阵的转置(Transpose) ,以及在 NumPy 中执行矩阵乘法的函数 np.matmul() 或更简洁的操作符 @。

现在,我们可以用矩阵乘法来重写 dense 层的计算。通过将输入 A、权重 W 和偏置 B 都处理成矩阵(二维数组)的形式,整个前向传播的核心计算就可以简化为一行高效的代码:Z = A @ W + B(或根据具体的线性代数约定进行调整)。
3.2 神经网络的训练流程
现在,我们已经理解了模型搭建、前向传播和性能优化,是时候将所有部分整合起来,正式审视一下在 TensorFlow 中训练一个神经网络的完整流程了。
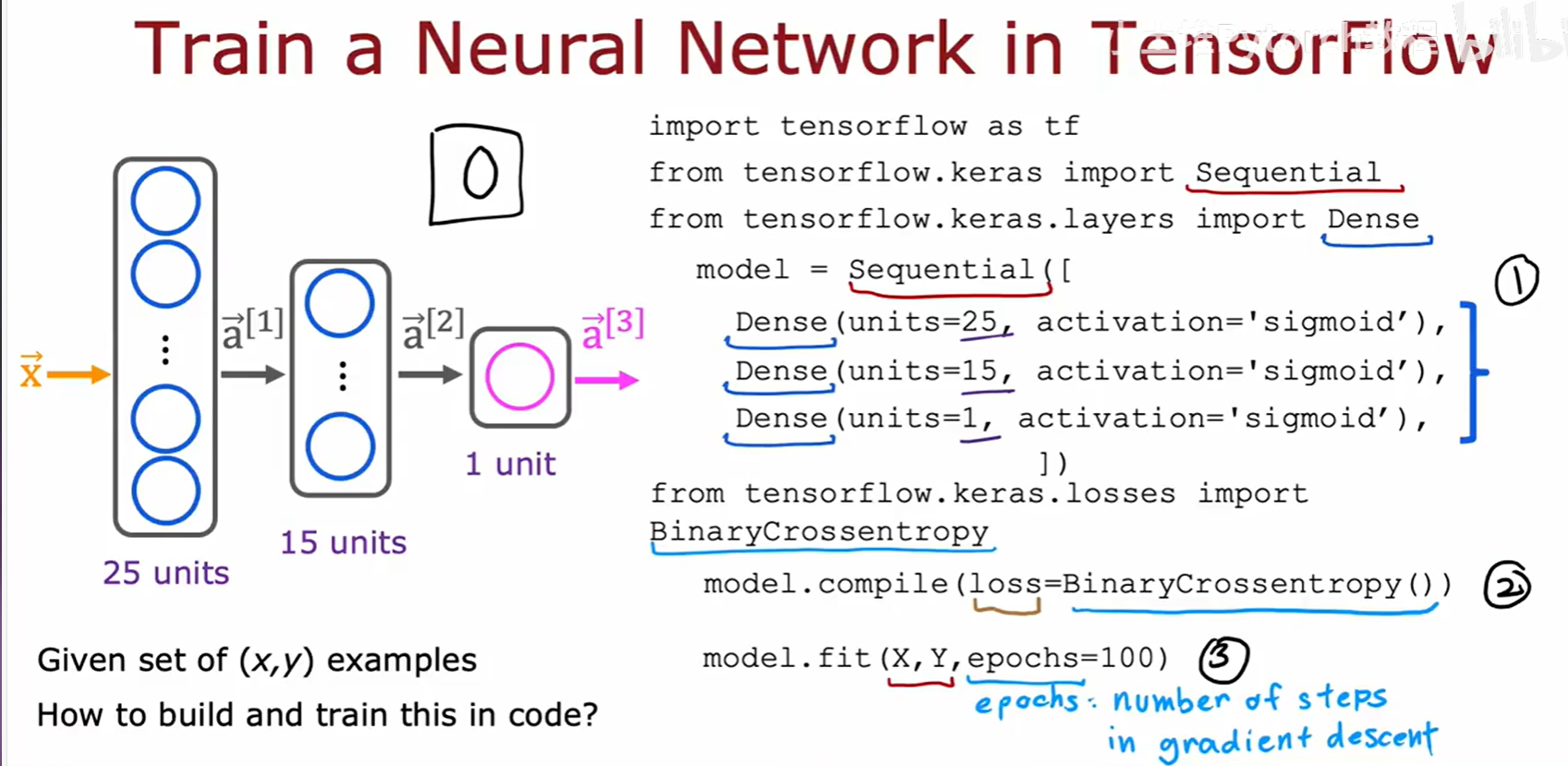
在 TensorFlow 中,训练一个模型主要有三个逻辑上清晰的步骤,这与我们之前学习线性/逻辑回归的思路完全一致:
- 创建模型 (
Sequential):定义模型的结构,即前向传播的计算方式。 - 编译模型 (
model.compile):为模型配置训练所需的"零件",即损失函数和优化器。 - 拟合数据 (
model.fit):将数据喂给模型,让模型执行梯度下降,学习数据中的规律。

-
第一步:创建/定义模型
f(X)。在 TensorFlow 中,这一步就是我们已经熟悉的,使用
Sequential和Dense层来搭建网络。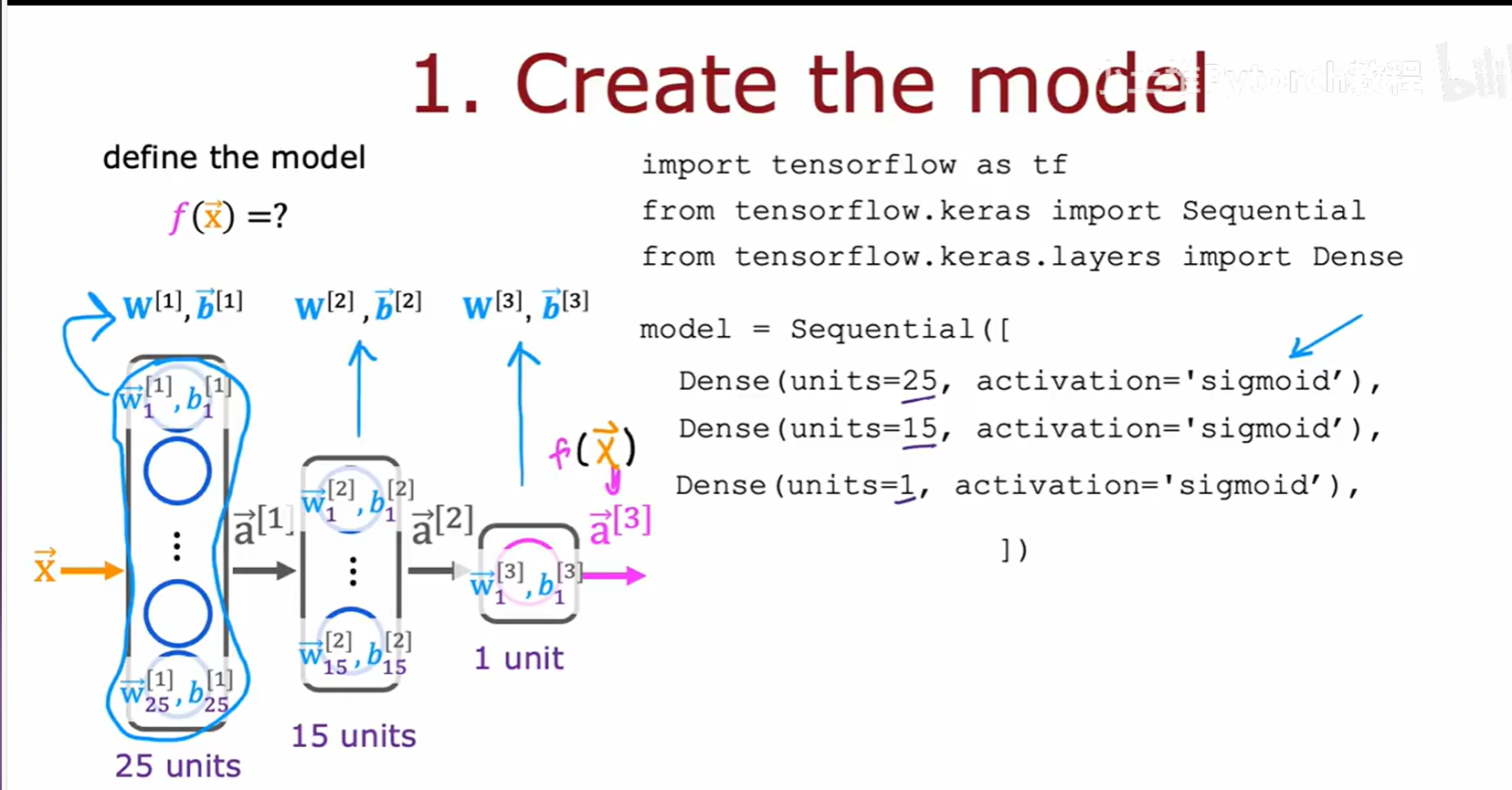
-
第二步:指定损失函数和代价函数 。
我们需要一个标准来衡量模型预测的好坏。对于二元分类问题,我们使用二元交叉熵(Binary Crossentropy) ,它在数学上等同于我们之前为逻辑回归推导的对数损失。对于回归问题,则使用均方误差(Mean Squared Error) 。在
model.compile()中,我们通过loss参数来指定它。
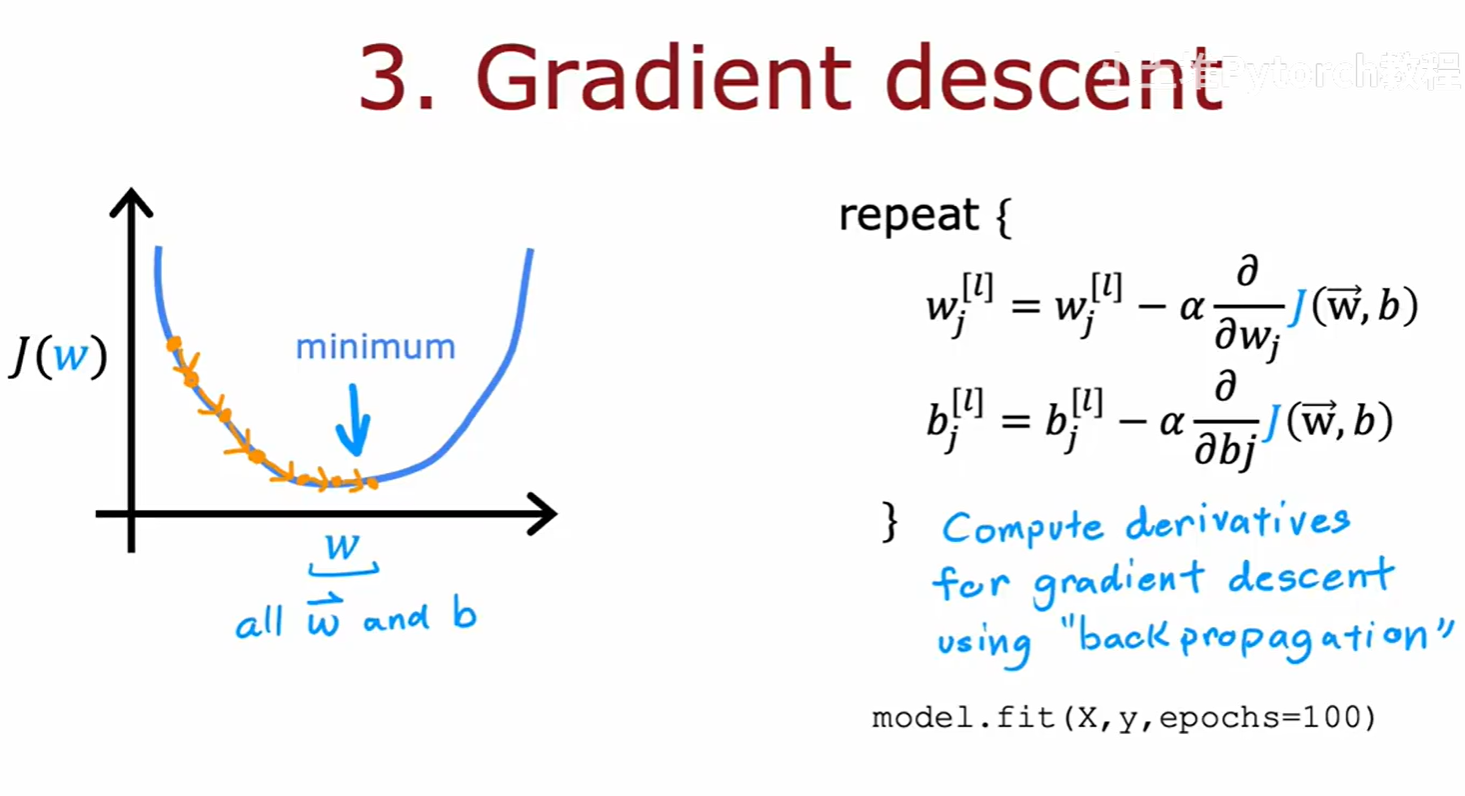
-
第三步:执行梯度下降以最小化代价 。
model.fit()函数封装了整个优化循环。它会根据我们指定的损失函数,通过一个名为反向传播(Backpropagation 的高效算法来计算代价函数对所有参数W和b的偏导数(梯度)。然后,它会使用我们指定的优化器(例如梯度下降)来更新这些参数。这个过程会重复进行,直到我们指定的训练轮数epochs完成。