Transformer 的注意力机制经历了从 MHA(多头注意力) 到 MQA(多查询注意力) 、GQA(分组查询注意力) ,再到 MLA(多头潜变量注意力) 的逐步演进。这一过程的核心目标是:减少计算和显存开销,同时保持模型性能。
MHA(Multi-Head Attention,多头注意力)
MHA 是最早出现在 Transformer(Vaswani et al., 2017) 中的注意力形式。它通过 多组独立的注意力头(heads) 来并行捕捉不同子空间的关系。
数学形式:
-
输入向量
,经过线性变换得到:
-
对每个 head:
-
最后拼接:
特点:
- 每个注意力头都有自己独立的
- 模型表达力强,能够捕获复杂的上下文关系,但参数多,计算开销大
- 随着模型规模扩大,MHA 的参数和显存开销呈线性增长,尤其是Key 和 Value 的存储成为瓶颈
python
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.qkv = nn.Linear(embed_dim, 3 * embed_dim)
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, T, C = x.shape
qkv = self.qkv(x).reshape(B, T, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # [B, num_heads, T, head_dim]
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = torch.softmax(attn, dim=-1)
out = (attn @ v).transpose(1, 2).reshape(B, T, C)
return self.proj(out)
# 使用示例
mha = MultiHeadAttention(embed_dim=512, num_heads=8)
x = torch.randn(1, 10, 512) # [batch, seq_len, dim]
print(mha(x).shape) # [1, 10, 512]MQA(Multi-Query Attention,多查询注意力)
在传统的多头注意力机制中,每个注意力头都使用自己的一组查询、键和值,这可能需要大量计算,尤其是在注意力头数量增加的情况下。
多查询注意力机制 (MQA) 是 Transformer 中使用的传统多头自注意力机制(MHA)的一种变体。MQA 通过在多个注意力头之间共享同一组键和值,同时为每个注意力头维护不同的查询。
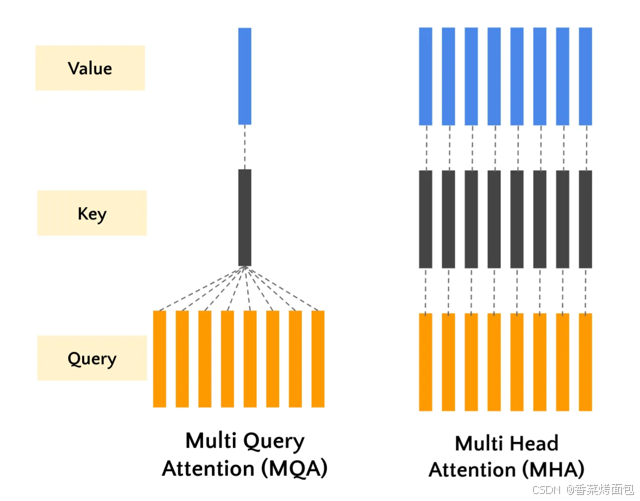
即:在 解码(inference) 阶段,MHA 的计算瓶颈主要在于存储每个 head 的 Key/Value 缓存 。MQA 的改进是:多个 Query heads 共享同一个 Key 和 Value
核心思想: 为了解决推理时 Key/Value 缓存过大的问题,所有头共享同一组 Key 和 Value
- Query:每个头独立
- Key / Value:所有头共享一组
特点:
- Q 独立,K,V 全部共享
- 大幅减少 KV 缓存,推理速度更快,显存占用更低,KV 缓存减少约 h 倍 (h是头数)
- 每个头看到的 Key/Value 相同 → 表达能力略有下降,即共享 K 和 V 可能导致模型捕捉上下文的能力下降
python
class MultiQueryAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.q = nn.Linear(embed_dim, embed_dim) # 独立 Q
self.k = nn.Linear(embed_dim, self.head_dim) # 共享 K
self.v = nn.Linear(embed_dim, self.head_dim) # 共享 V
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, T, C = x.shape
q = self.q(x).reshape(B, T, self.num_heads, self.head_dim).transpose(1, 2) # [B, H, T, D]
k = self.k(x).unsqueeze(1) # [B, 1, T, D] -> 广播到所有头
v = self.v(x).unsqueeze(1)
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = torch.softmax(attn, dim=-1)
out = (attn @ v).transpose(1, 2).reshape(B, T, C)
return self.proj(out)
# 使用示例
mqa = MultiQueryAttention(embed_dim=512, num_heads=8)
print(mqa(x).shape) # [1, 10, 512]GQA(Grouped Query Attention,分组查询注意力)
组查询注意力 (GQA) 是对 Transformer 中使用的传统多头自注意力机制和多查询注意力机制的折中。在标准多头自注意力中,每个注意力头独立处理整个序列。这种方法虽然功能强大,但计算成本高昂,尤其是对于长序列。而MQA虽然通过在多个注意力头之间共享同一组键和值简化了这一过程,但其简化也不可避免的带来了一些精度的损失。GQA 通过将查询分组在一起来解决此问题,从而降低了计算复杂性,而不会显著影响性能。
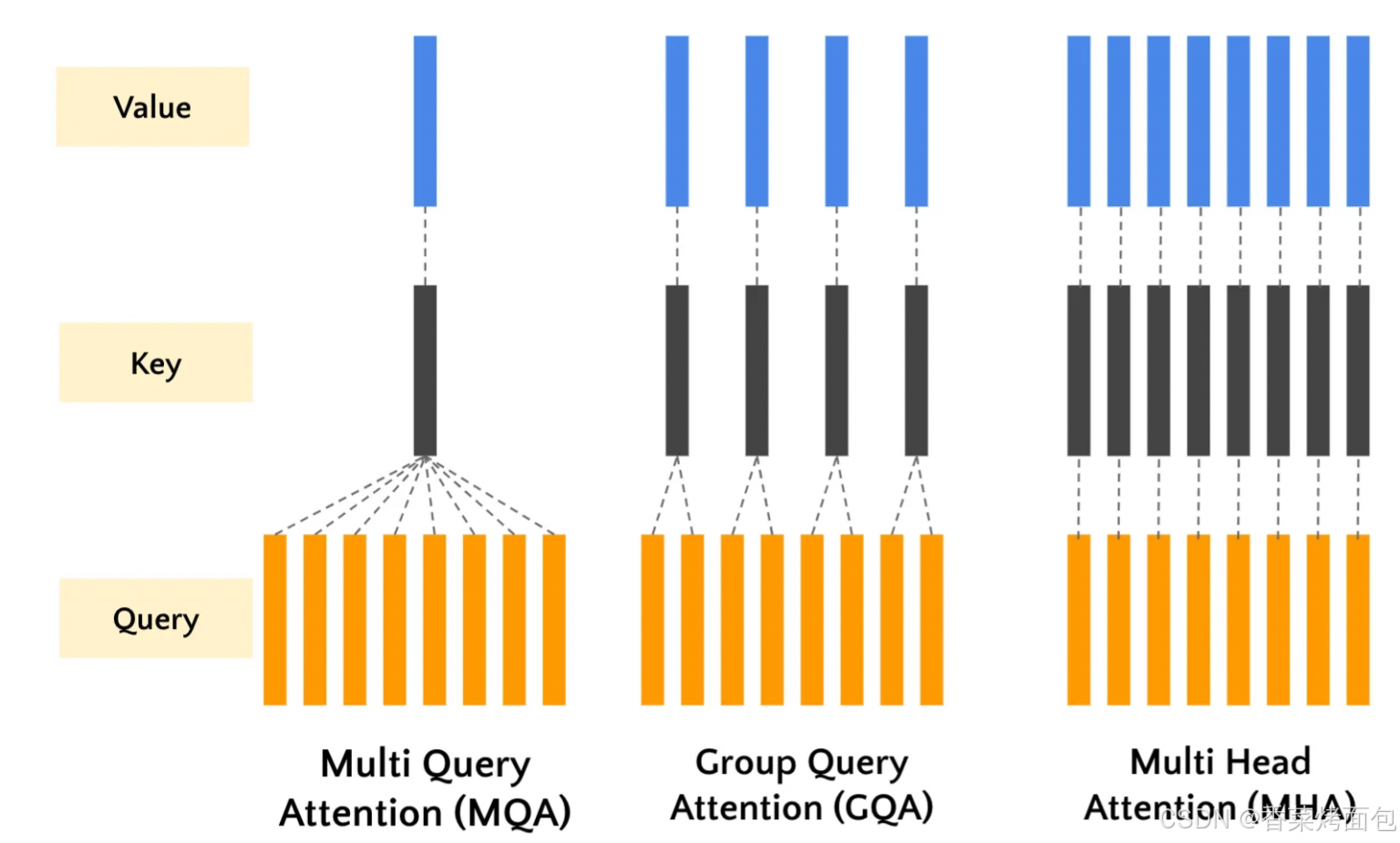
核心思想: GQA 是 MHA 和 MQA 的折中方案:****将多个 Query 头划分为若干组,每组共享一组 Key/Value,****Q 独立
- 每组包含多个 Query heads
- 每组有独立的 Key 和 Value
- 介于"每头独立"和"全部共享"之间
特点:
- 减少显存, KV Cache 减少到 g /h , 同时保留了部分多样性,性能接近 MHA
- 需要合理设置组数 g,组数过少可能接近 MQA,过多则接近 MHA
- 被广泛采用(PaLM 2、Gemini、LLaMA 2、Mixtral 等)
python
class GroupedQueryAttention(nn.Module):
def __init__(self, embed_dim, num_heads, num_groups):
super().__init__()
self.num_heads = num_heads
self.num_groups = num_groups
self.head_dim = embed_dim // num_heads
assert num_heads % num_groups == 0, "头数必须能被组数整除"
self.q = nn.Linear(embed_dim, embed_dim)
self.k = nn.Linear(embed_dim, self.head_dim * num_groups) # 每组一个 K
self.v = nn.Linear(embed_dim, self.head_dim * num_groups) # 每组一个 V
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, T, C = x.shape
q = self.q(x).reshape(B, T, self.num_heads, self.head_dim).transpose(1, 2) # [B, H, T, D]
k = self.k(x).reshape(B, T, self.num_groups, self.head_dim).transpose(1, 2) # [B, G, T, D]
v = self.v(x).reshape(B, T, self.num_groups, self.head_dim).transpose(1, 2)
# 将 K/V 广播到每个组内的头
k = k.repeat_interleave(self.num_heads // self.num_groups, dim=1)
v = v.repeat_interleave(self.num_heads // self.num_groups, dim=1)
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = torch.softmax(attn, dim=-1)
out = (attn @ v).transpose(1, 2).reshape(B, T, C)
return self.proj(out)
# 使用示例(4 组,8 头)
gqa = GroupedQueryAttention(embed_dim=512, num_heads=8, num_groups=4)
print(gqa(x).shape) # [1, 10, 512]MLA(Multi-Head Latent Attention,多头潜变量注意力)
多头潜在注意力 (MLA) 将潜在特征表示纳入注意力机制,以降低计算复杂度并改善上下文表示。MLA的核心是对KV进行压缩后,再送入标准的MHA算法中,用一个更短的k,v向量来进行计算,进而减少KV Cache的大小。
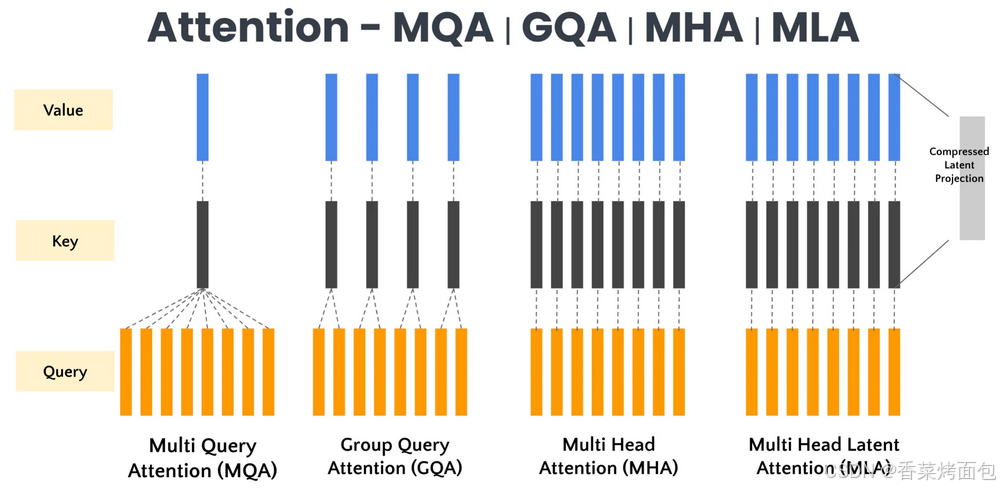
核心思想: 在 GQA 的基础上进一步优化:****不再直接存储 KV,而是引入一个低维"潜空间"(latent space)生成 KV,****从而减少 KV Cache 的大小
工作机制:
- 将输入 token 投影到一个潜向量空间(通常维度更低)
- Key/Value 通过该潜向量生成
- 每个注意力头在潜空间中计算
- 减少 KV 缓存存储,同时保持多头的表达多样性
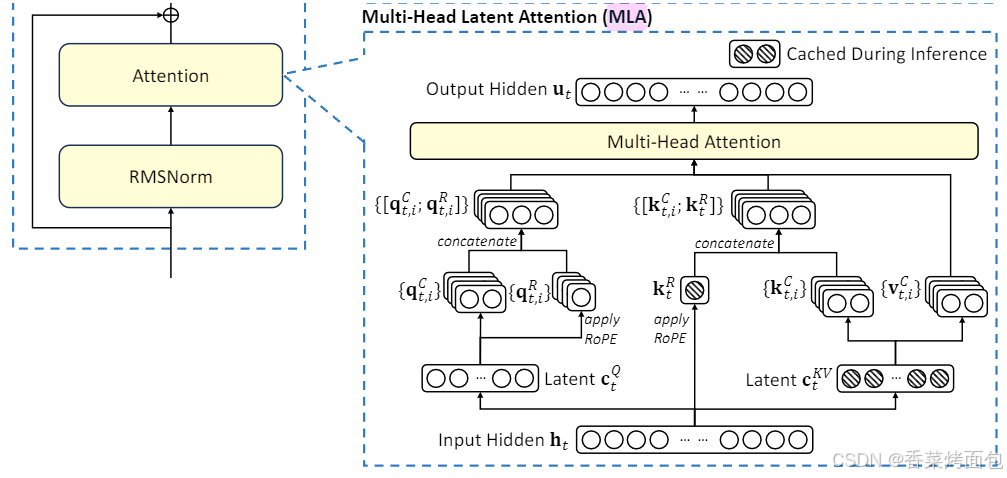
特点:
- 显著减少 KV 缓存,减少 93.3%,适合超长序列推理
- 推理更快,尤其在长上下文时
- 性能与 GQA 相当甚至更优
- GQA 是"多个头共享同一组 KV",MLA 则是"多个头共享一个低维潜空间,从该空间动态生成 KV"
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadLocalAttention(nn.Module):
def __init__(self, embed_dim, num_heads, window_size=4):
super().__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.window_size = window_size
self.qkv = nn.Linear(embed_dim, 3 * embed_dim)
self.proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, T, C = x.shape
qkv = self.qkv(x).reshape(B, T, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # [B, H, T, D]
# 划分局部窗口
x = x.view(B, T, C)
x = x.unfold(1, self.window_size, self.window_size) # [B, num_windows, window_size, C]
# 每个窗口内计算注意力
local_attn_outputs = []
for i in range(x.size(1)):
window = x[:, i, :, :] # [B, window_size, C]
q_window = q[:, :, i*self.window_size:(i+1)*self.window_size, :]
k_window = k[:, :, i*self.window_size:(i+1)*self.window_size, :]
v_window = v[:, :, i*self.window_size:(i+1)*self.window_size, :]
attn = (q_window @ k_window.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = torch.softmax(attn, dim=-1)
out_window = (attn @ v_window).transpose(1, 2).reshape(B, self.window_size, C)
local_attn_outputs.append(out_window)
# 合并窗口结果
out = torch.cat(local_attn_outputs, dim=1)
return self.proj(out)
# 使用示例
mla = MultiHeadLocalAttention(embed_dim=512, num_heads=8, window_size=4)
x = torch.randn(1, 20, 512) # [batch, seq_len, dim]
print(mla(x).shape) # [1, 20, 512]这篇文章也写的挺好的,可以参考看看:https://lengm.cn/post/20250226_attention/
style="display: none !important;">