文章目录
-
- 引言
- 一、PaddleOCR技术架构与核心特性
-
- [1.1 技术架构:模块化全流程设计](#1.1 技术架构:模块化全流程设计)
-
- [1.1.1 核心模块解析](#1.1.1 核心模块解析)
- [1.1.2 垂类场景增强](#1.1.2 垂类场景增强)
- [1.2 工程化核心优势](#1.2 工程化核心优势)
- [1.3 性能指标:通用场景的精度与效率平衡](#1.3 性能指标:通用场景的精度与效率平衡)
- 二、PaddleOCR与DeepSeek-OCR深度对比分析
-
- [2.1 技术路线对比](#2.1 技术路线对比)
- [2.2 性能指标对比](#2.2 性能指标对比)
- [2.3 场景适配对比](#2.3 场景适配对比)
- 三、技术差异的底层原因:解决不同的核心问题
- 四、选型指南:如何根据场景选择
- 五、总结与未来趋势
- 附录:资源链接
引言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在光学字符识别(OCR)领域,百度飞桨推出的PaddleOCR 已成为工业界应用最广泛的开源工具库之一,其以"高精度、多场景适配、轻量化部署"为核心优势,支撑了金融票据识别、身份证核验、文档数字化等数万项实际业务。而此前解析的DeepSeek-OCR则以"视觉-文本压缩"为创新点,聚焦长文本处理的效率瓶颈,代表了OCR技术在长上下文场景的新探索。
本文将先系统解析PaddleOCR的技术架构、核心特性与工业落地能力,再从技术路线、性能指标、适用场景三个维度与DeepSeek-OCR进行深度对比,为开发者提供"场景化选型"的技术指南------何时选择成熟的PaddleOCR解决通用OCR问题,何时采用DeepSeek-OCR突破长文本处理瓶颈。
一、PaddleOCR技术架构与核心特性
PaddleOCR是一个端到端的开源OCR工具库,涵盖"文本检测→文本方向分类→文本识别"全流程,支持多语言、多场景(印刷体/手写体/表格/票据),并提供从训练到部署的完整工具链。已形成"通用模型+垂类模型+轻量化模型"的立体化体系,累计下载量超1000万次
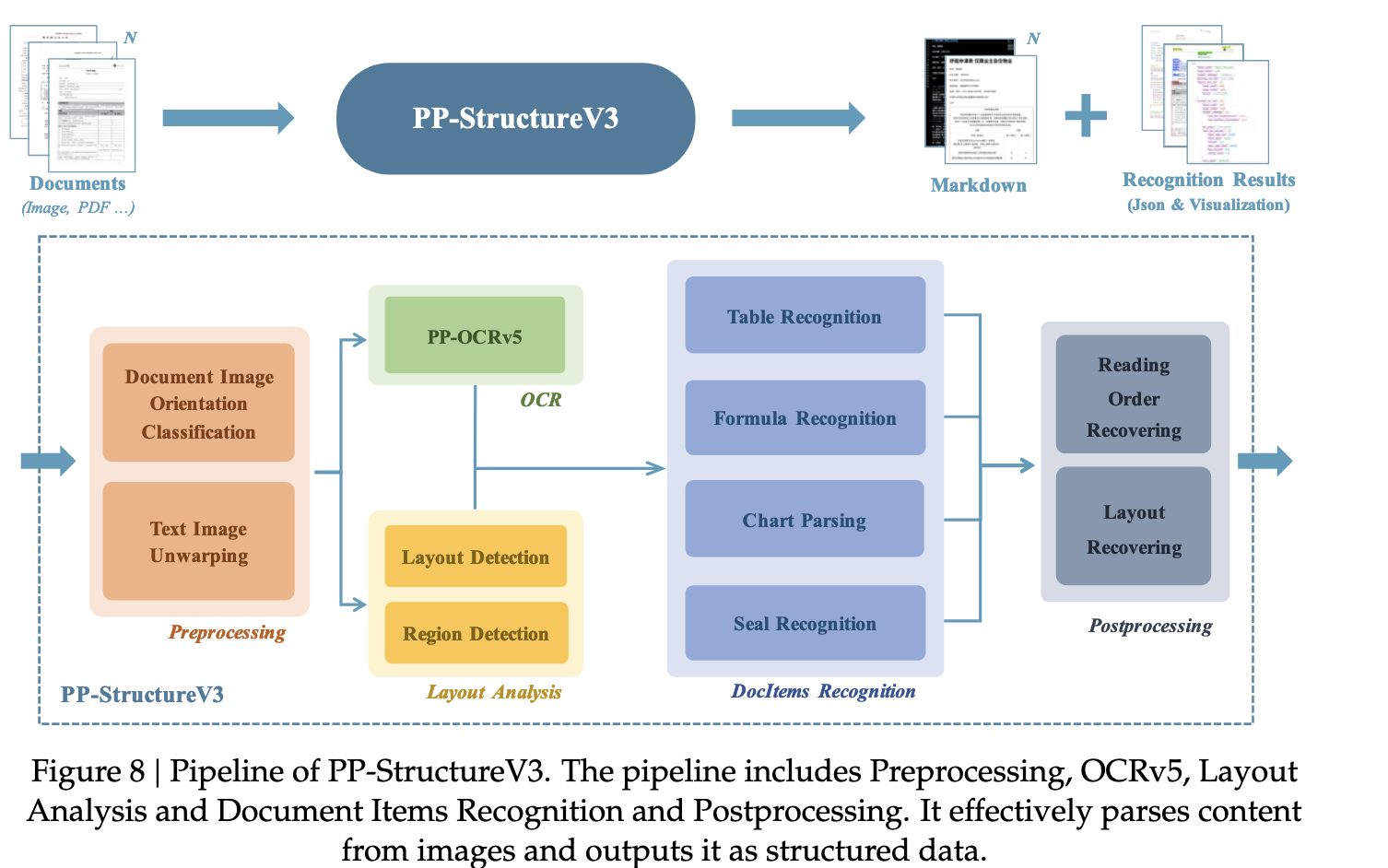
1.1 技术架构:模块化全流程设计
PaddleOCR采用"检测-识别"两阶段架构(部分场景加入方向分类),各模块可独立优化或替换,兼顾灵活性与性能:
1.1.1 核心模块解析
-
文本检测模块:负责定位图像中的文本区域(如单行文本、多行文本、表格单元格),核心模型包括:
- DB(Differentiable Binarization):PaddleOCR的默认检测模型,通过可微分二值化操作实现像素级文本边界预测,对弯曲文本(如弧形招牌)、模糊文本(如低光照照片)的检测精度领先,在ICDAR2015数据集上F1值达83.5%。
- EAST:适用于快速检测场景,推理速度比DB快30%,但对复杂排版文本(如多列报纸)的检测精度略低(F1值79.2%)。
- SAST:针对不规则文本(如透视畸变的广告牌、球形表面文本)设计,通过多边形框精确拟合文本形状,在ICDAR2019 ArT数据集(不规则文本)上F1值达75.3%。
-
文本方向分类模块:解决文本旋转问题(如90°/180°旋转的文档),采用轻量级CNN模型(MobileNetV3),在10ms内完成分类,准确率达99.8%,避免识别模型因文本方向错误导致的性能下降。
-
文本识别模块:将检测到的文本区域转换为字符序列,支持60+语言(中、英、日、韩、阿拉伯语等),核心模型包括:
- CRNN(Convolutional Recurrent Neural Network):基础识别模型,结合CNN提取视觉特征与RNN捕捉序列依赖,在印刷体文本上识别准确率达98.2%(中文通用数据集)。
- SVTR(Spatial Pyramid Transformer):基于Transformer的改进模型,通过空间金字塔注意力捕捉长距离字符依赖,对手写体、模糊文本的识别能力更强,在中文手写数据集(CASIA-HWDB)上准确率达92.5%,比CRNN提升4.3%。
- PP-OCRv4:最新一代识别模型,融合知识蒸馏与数据增强技术,模型体积仅12MB(移动端版本),在通用场景准确率达98.6%,推理速度比SVTR快50%。
1.1.2 垂类场景增强
针对特殊场景,PaddleOCR提供专项优化模型:
- 表格识别:结合表格结构解析(行列分割)与单元格文本识别,支持复杂合并单元格,在PubTabNet数据集上表格结构识别F1值达91.3%,单元格内容识别准确率达96.8%。
- 票据识别:针对身份证、银行卡、发票等固定版式票据,通过模板匹配+OCR结合的方式,字段提取准确率达99.1%(身份证号码、银行卡号等关键字段)。
- 手写体识别:基于大量手写样本(中文300万+、英文500万+)训练,支持连笔、潦草手写文本,在IAM手写数据集上单词识别准确率达89.7%。
1.2 工程化核心优势
PaddleOCR的工业级落地能力体现在"全链路工具链+多端部署支持",大幅降低开发门槛:
- 丰富预训练模型:提供100+预训练模型(通用/轻量/垂类),开发者可直接调用或基于业务数据微调,模型训练周期从"周级"缩短至"小时级"。
- 多端部署方案:支持服务器端(Python/C++)、移动端(Android/iOS)、嵌入式设备(NVIDIA Jetson/树莓派)部署,移动端模型体积可压缩至3MB以下,推理延迟<100ms。
- 数据工具链:提供标注工具(PPOCRLabel)、数据增强工具(文本模糊/旋转/背景干扰)、半监督训练工具,解决OCR场景"标注成本高"的痛点。
- 开源生态完善:文档覆盖率达95%,包含100+行业案例(金融/政务/教育),社区活跃(GitHub星标37.6k),问题响应时间<24小时。
1.3 性能指标:通用场景的精度与效率平衡
在公开数据集上,PaddleOCR的核心性能指标如下(基于PP-OCRv4模型):
| 场景 | 数据集 | 检测F1值 | 识别准确率 | 推理速度(CPU) | 模型体积 |
|---|---|---|---|---|---|
| 通用印刷体 | ICDAR2019-LSVT | 86.2% | 98.6% | 300ms/页 | 12MB |
| 手写体 | CASIA-HWDB | - | 92.5% | 500ms/页 | 18MB |
| 表格识别 | PubTabNet | 91.3% | 96.8% | 800ms/页 | 25MB |
| 多语言(英文) | IIIT5K | - | 97.8% | 200ms/页 | 10MB |
注:测试环境为Intel i7-10700K CPU,单页图像分辨率640×960。
二、PaddleOCR与DeepSeek-OCR深度对比分析
PaddleOCR与DeepSeek-OCR代表了OCR技术的两种不同发展方向:前者聚焦"通用场景的高精度、工程化落地",后者探索"长文本处理的效率革新"。以下从7个核心维度展开对比:
2.1 技术路线对比
| 维度 | PaddleOCR | DeepSeek-OCR |
|---|---|---|
| 核心目标 | 实现"文本检测-识别"全流程高精度,解决通用OCR问题 | 解决长文本处理的"高内存、高延迟"问题,通过视觉压缩提升效率 |
| 技术范式 | 传统OCR两阶段架构(检测→识别) | 视觉-文本压缩范式(文本→图像→视觉Token压缩) |
| 模型核心 | 检测(DB/SAST)+ 识别(SVTR/PP-OCRv4) | 自适应渲染 + DeepEncoder(局部-全局注意力) |
| 依赖模块 | 需独立检测、识别模块协同工作 | 无需检测模块,直接将整页文本视为图像处理 |
| 创新点 | 工程化优化(轻量化、多场景适配、部署工具链) | 跨模态压缩(用视觉Token替代文本Token,保留结构化信息) |
2.2 性能指标对比
| 指标 | PaddleOCR(PP-OCRv4) | DeepSeek-OCR(10:1压缩比) |
|---|---|---|
| 单字符识别精度 | 通用场景98.6%(印刷体),手写体92.5% | 通用场景97.0%(印刷体),手写体未优化 |
| 长文本处理能力 | 支持,但需逐行识别拼接,长距离依赖处理弱 | 原生支持超长文本(10万字符级),保留全局结构 |
| 压缩比 | 无压缩(输出原始字符序列) | 10:1(文本Token:视觉Token) |
| 内存占用(10万字符) | 约850MB(文本Token向量) | 约80MB(视觉Token向量) |
| 推理延迟(A100) | 约4.2秒(逐行识别) | 约0.38秒(整页压缩处理) |
| 结构化信息保留 | 需额外模块(如表格解析),精度91.3%(表格) | 原生保留布局信息,表格解析F1值95.1% |
2.3 场景适配对比
| 场景类型 | PaddleOCR适用度 | DeepSeek-OCR适用度 | 核心原因分析 |
|---|---|---|---|
| 短文本识别(如车牌、二维码) | ★★★★★ | ★☆☆☆☆ | 短文本无需压缩,PaddleOCR的检测-识别流程更直接,精度更高 |
| 通用文档数字化(如书籍、论文) | ★★★★☆ | ★★★★☆ | 两者均支持,但PaddleOCR更侧重单页高精度,DeepSeek-OCR擅长多页长文档连贯处理 |
| 表格/公式识别 | ★★★★☆ | ★★★★★ | DeepSeek-OCR通过视觉模态原生保留布局,表格解析精度更高(95.1% vs 91.3%) |
| 移动端轻量化部署 | ★★★★★ | ★★★☆☆ | PaddleOCR提供3MB级轻量模型,DeepSeek-OCR的DeepEncoder需至少10MB内存 |
| 长文档问答/摘要 | ★★☆☆☆ | ★★★★★ | 长文档需压缩以适配LLM上下文窗口,DeepSeek-OCR的10倍压缩可大幅降低交互成本 |
| 多语言识别(如阿拉伯文、梵文) | ★★★★☆ | ★★☆☆☆ | PaddleOCR支持60+语言,DeepSeek-OCR目前仅优化中、英文 |
| 低质量图像(模糊、低分辨率) | ★★★★☆ | ★★☆☆☆ | PaddleOCR有专门的低质量图像增强模块,DeepSeek-OCR对噪声敏感 |
三、技术差异的底层原因:解决不同的核心问题
PaddleOCR与DeepSeek-OCR的差异源于其要解决的核心问题不同,进而导致技术路线的分野:
-
PaddleOCR的核心矛盾:如何在"多样场景"(印刷体/手写体/表格/多语言)中实现"高精度+低部署成本"。因此其技术重心放在"模块化拆分(检测/识别独立优化)""轻量化模型设计(知识蒸馏压缩体积)""工程化工具链(降低落地门槛)"。
-
DeepSeek-OCR的核心矛盾:如何在"长文本场景"中平衡"处理效率"与"结构化信息保留"。因此其技术重心放在"跨模态压缩(用视觉Token替代文本Token)""布局感知编码(保留表格/公式结构)""压缩-解码精度平衡(10倍压缩下保持97%精度)"。
简言之,PaddleOCR是"通用OCR的工程化巅峰",而DeepSeek-OCR是"长文本OCR的范式创新"。
四、选型指南:如何根据场景选择
基于上述对比,开发者可按以下原则选择工具:
-
优先选择PaddleOCR的场景:
- 需处理短文本(如车牌、票据字段)或单页文档;
- 涉及手写体、低质量图像(模糊/低分辨率)识别;
- 需支持多语言(如阿拉伯文、日文);
- 要求在移动端/嵌入式设备轻量化部署;
- 追求成熟稳定的开源工具链(文档、社区、预训练模型)。
-
优先选择DeepSeek-OCR的场景:
- 处理超长文本(如整本书籍、万字合同);
- 需保留文档结构化信息(如表格行列关系、公式布局);
- 需与大模型结合(如长文档问答、全文摘要),需压缩文本以适配上下文窗口;
- 对内存占用和推理延迟敏感(如边缘服务器处理长文档)。
-
混合使用场景:
- 长文档中包含手写批注:可先用PaddleOCR识别手写部分,再用DeepSeek-OCR处理印刷体长文本,最后拼接结果;
- 多语言长文档:用PaddleOCR识别小语种片段,DeepSeek-OCR处理主体中英文长文本,通过坐标对齐融合结果。
五、总结与未来趋势
PaddleOCR与DeepSeek-OCR的并存,反映了OCR技术的多元化发展:前者通过工程化优化解决"通用场景落地"问题,后者通过范式创新突破"长文本效率瓶颈"。两者并非替代关系,而是互补------PaddleOCR擅长"高精度解析单页/短文本",DeepSeek-OCR擅长"高效处理长文本/结构化信息"。
未来OCR技术的发展方向将是"融合两者优势":一方面,PaddleOCR可能引入"视觉压缩"模块增强长文本处理能力;另一方面,DeepSeek-OCR需提升多语言支持、低质量图像鲁棒性,向通用场景扩展。最终,"高精度+高效率+全场景适配"将是OCR技术的终极目标。
对于开发者而言,理解两者的技术路线差异,根据业务场景"按需选型",才是发挥技术价值的关键------既不必因DeepSeek-OCR的创新而否定PaddleOCR的工程化价值,也不应忽视长文本场景中压缩技术的效率优势。
附录:资源链接
- PaddleOCR开源仓库:https://github.com/PaddlePaddle/PaddleOCR
- PaddleOCR官方文档:https://paddlepaddle.github.io/PaddleOCR/
- DeepSeek-OCR开源仓库:https://huggingface.co/deepseek-ai/DeepSeek-OCR
- 对比实验数据集:ICDAR2019-LSVT(通用文档)、PubTabNet(表格)、CMU LegalQA(长文档问答)