相信很多人在涉及到性能相关的领域时,经常会遇到甚至会用『并发用户数』来判断一个系统是否达到性能需求,又比如说『系统支持1000用户』这样的诉求来描述性能要求,根据这些描述,我们看看其中涉及到并发与TPS,在线用户数和并发用户数它们之间又存在怎样关系?本节内容针对这些问题简单谈讨并给出实践结论 !
1 计算公式
目前并发用户数典型的计算公式,甚至多数人会用如下公式进行计算 : 并发用户数= TPS × RT
2 问题说明
上述的计算是否存在问题,现举例说明(为简化问题说明,我们估且不考虑响应时间的变化):

上图 压力线程 为 5个,在 1 s 内有 5个线程可以完成5 次请求,那根据上面的公式可知并发用户数为 : = 25(完成的事务总数)*0.2= 5,显而易见,这个5 是并发线程的个数,从上图可知每一个事务才是一个真实的用户,显然这里的并发用户数为25个。
那么并发真正指什么:『是指在单位时间内完成的事务(T)的个数。如果这个事务(T)是用户的操作,那就是并发的用户』
根据上图的例子,如果TPS为100,则并发用户就是100,而不是 100*0.2=20,因为20 并没有时间上的概念。
3 实际案例
3.1 以购车下单为例:
步骤 操作 开始时间 结束时间
1 打开app,进入首页 2025.08.08 23:59:21
2 选择全系新车,进入购车页面
3 选择车型
4 即刻预定
5 版本选择
6 电池容量选择
7 外饰选择-外观
8 外饰选择-车轮
9 外饰选择-内饰
10 外饰选择-选装
11 外饰选择-软件
12 智驾选择
13 权益选择
14 点击确定,跳转到立即下单页
15 立即下单
16 登录
17 支付定金
18 查看订单详情 2025.08.09 00:02:53
19 退出
上述表格为 1 个用户从app内到购买车完成付款的全业务流程,通过服务端日志抓取共有400个请求,完成支付业务从开始到结束的时间窗口为120s,我们按不同事务及别分别计算在线用户与TPS的之间的关系:
3.2 单个在线用户的 TPS 计算
事务 T 设置为每个请求
则此用户的TPS 计算如下:
1(用户) * 400(请求数) ÷ 120(时间窗口) = 3.33 (请求数/s)
事务 T 定义到每个业务操作的级别
对应上述的 18 个业务操作,这里退出操作不计算在内,这 18 个业务操作完成的窗口为120s
1(用户) * 18(业务级操作事务) ÷ 120(时间窗口) = 0.15 (请求数/s)
事务 T 定义到整个用户级别
通常情况下,业务部门会这样要求,因为只有做完了这些步骤才是一个业务完成了,那显然这 120 秒内只完成了 1 个事务。那对应的 TPS 就是:
1(用户) × 1(完整用户级事务) ÷ 120(时间窗口) = 0.008(TPS)
ps : 这里没有加入业务模型,如果加了业务模型,问题说明反而会更复杂
3.3 多在线用户的 TPS 计算
上面的计算是根据1个用户进行计算,如果是多个用户,该如何计算:
假设系统中有 100000 用户都是平均 120 秒完成业务,并且是在 1 个小时内完成的则计算过程如下:
请求级的 TPS:
(100000(用户)×400(请求数))÷3600(秒)≈11111(TPS)
单业务操作级 TPS:
(100000(用户)×18(业务操作)))÷3600(秒)≈500(TPS)
用户级 TPS:
(100000(用户)×1(用户级)÷3600(秒)≈27.78(TPS)
ps : 这里做的假设只是为了后续的计算方便,并不是说这个假设条件是成立的『假设系统中有 100000 用户都是平均 120 秒完成业务』
3.4 峰值在线用户的 TPS 计算
上面是按 1 小时内所有的用户都平均分布的方式算的,如果有峰值呢?这个算法就不对了,线上业务峰值的统计时间段越短,显然是越准确的。假如从生产上统计出来 10 万用户是在 1 小时内完成的,且其中 1 万用户在 1 个小时内的某 1 分钟内完成业务,这样的数据其实为大型电商的秒杀级别,那根据上面的计算方式,可以得到:
请求级的 TPS:
(10000(用户)×400(请求数))÷60(秒)≈66666.67(TPS)
单业务操作级 TPS:
(10000(用户)×18(业务操作)))÷60(秒)=3000(TPS)
用户级 TPS:
(10000(用户)×1(用户级)÷60(秒)≈166.67(TPS)
想要得到精确的峰值 TPS,很明显的前提就是统计的时间段够精准,通过以上的计算过程,可以知道在包括静态资源的时候,在线用户数怎么转化到相对应的不同级别的 TPS,对于不包括静态资源的计算过程,其计算逻辑可根与上述一样。
3.5 并发用户和 TPS 之间的关系
从上面的在线用户计算示例中,在日志中两个操作之间的是有时间间隔的,那如果 1 个用户在操作的时候没有间隔,TPS 应该是多少呢?通过 JMeter 录制浏览器的行为,先把同样的操作步骤变成 JMeter 脚本,然后再回放一下,抓一下日志,看看在没有停顿的时候,一个完整的用户流程需要多长时间。日志如下:
{"client_ip":"59.109.155.203","local_time":"08/08/2025:01:08:56 +0800","request":"GET / HTTP/1.1","status":"200","body_bytes_sent":"23293","http_x_forwarded_for":"-","upstream_addr":"127.0.0.1:8180","request_time":"0.109","upstream_response_time":"0.109"}
...中间省略398行
{"client_ip":"59.109.155.203","local_time":"08/08/2025:01:09:08 +0800","request":"GET /resources/common/fonts/iconfont.ttf?t=1499667026218 HTTP/1.1","status":"200","body_bytes_sent":"159540","http_x_forwarded_for":"-","upstream_addr":"127.0.0.1:8180","request_time":"0.005","upstream_response_time":"0.005"
从时间戳上来看,从第一个请求到最后一个请求,共有 400 个请求,总共用了 8 秒(ps :这个响应时间,只截了一个用户的完整请求,实际上这里应该是用压力场景中的包括这些请求的平均响应时间),同样计算一下对应的 TPS:
请求级的 TPS:
1(用户)×400(请求数)÷8(秒)=50(TPS)
单业务操作级 TPS:
1(用户)×18(业务操作)÷8(秒)=2.25(TPS)
用户级 TPS:
1(用户)×1(用户级)÷8(秒)≈0.125(TPS)
并发度计算
可以对应算一下,1 个没有停顿的用户(并发用户)相当于多少个有停顿的用户(在线用户)
在这个转换的过程中,暂时不考虑请求的区别。那么显然是:
50÷3.33=2.25÷0.15=0.125÷0.008≈15(倍)
用哪个级别的 TPS 来算,其结果都是一样的,那么并发度就是:
1(并发用户)÷15(在线用户)≈0.7%(也即是8/120),那么如果录制了脚本并且没有设置停顿时间( 也可以叫 Think Time 或等待时间),如果想支持的是 10 万在线用户在 1 小时内完成所有业务,那么支持的对应并发用户数就是:
100000(在线用户)×0.7%=1428.58 (个并发用户)
而我们一个线程跑出来的请求级的 TPS 是 3.33,要想模拟出 10 万用户的在线,需要的压力线程数就是:
11111(10万在线用户时的请求级TPS)÷3.33(一个用户的请求级TPS)≈3336(压力线程)
4 在线用户数和压力线程之间的关系
4.1 用请求级 TPS 计算:
压力线程=(在线用户数×单用户请求数)/峰值采样时间段÷一个压力线程的请求级TPS
4.2 用单业务操作级 TPS 计算
压力线程=(在线用户数×单用户业务操作数)/峰值采样时间段÷一个压力线程业务操作级TPS
4.3 用户级TPS计算
压力线程=(在线用户数×单用户完整业务数(也就是1)/峰值采样时间÷一个压力线程的用户级TPS
4.4 并发用户数的计算
并发用户数=在线用户数×(有停顿时间的单线程TPS/无停顿时间的单线程TPS)
4.5 并发度
并发度=(并发用户/在线用户)×100%(取值要在同一时间段)
从以上的计算逻辑中,可以看到,这其中有几个关键数据:在线用户数,这个值可以从日志中取到;在线用户数统计的时间段,这个值也可以从日志中取到;用户级操作的完整业务流时间(记得多采样一些数据,计算平均时间),这个值也是从日志中取到;无停顿时间的完整业务流时间,这个值从压力工具中可以取到;单用户完整业务流的请求数,这个值可以从日志中获取。
5 RPS 和 TPS
相信有部分同行都知道不建议用 TPS(每秒事务数)来衡量系统的性能,而是建议用 RPS(每秒请求数)衡量,对于 RPS 和 TPS,异议点:
● TPS 是从压力工具的角度来说的,但是因为 TPS 会受到响应时间的影响,所以不建议采用 TPS 模式;
● 在接口串行请求时,由于各种异常问题的出现,TPS 不能反映出后端服务的每秒请求数;
● TPS 反映的是业务视角,RPS 反映的是服务端视角。
这些描述或认同看似是成立的,但是会存在误差:
● 在请求 - 响应的同步逻辑中,TPS 必然是和响应时间成反比关系,那么受响应时间影响,TPS 也受影响是合情合理的,而在做性能工程时我们要分析的就是,这种响应时间会变长的性能问题,同理采用了 RPS 模式,我们也需要关注响应时间,它也会受到响应时间的影响;
● 在异步逻辑中,只关注发送出去多少请求,显然无法反映出系统的完整的处理能力,所以,第 1点异议其实是不存在的,即便接口是串行的,并且后端流程长,会在各个节点产生多个请求,那后端请求也肯定是大于压力工具中的 TPS ;在一个固定的场景中,压力工具中的 TPS 和后端的请求数,必然是成线性关系,如果有异常出现,有报错,导致了后端某些服务的请求变少了,这种情况也正是我们要分析的性能问题;
● 综上所述第3点也异议不存在,没有人把压力工具中的 TPS 和服务端的 RPS 混为一谈,这两者是不同的统计手法,它们本来就在不同的角度,以示意图来说明一下请求和 TPS 之间的关系:
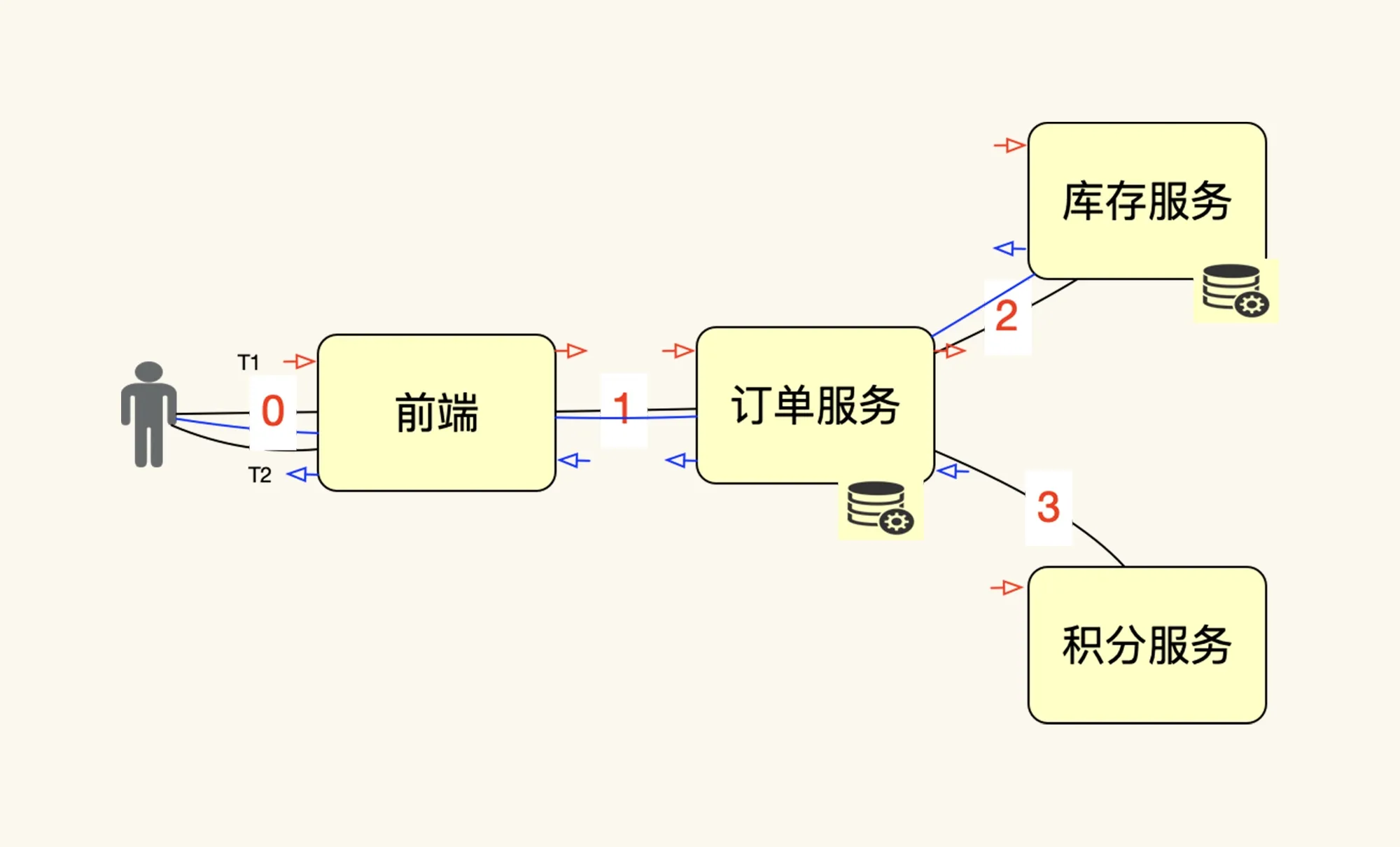
如上图所示(此图为网上摘自),如果压力工具中的一个线程(图中人的位置)发出一个请求(也就是在图中 0 的位置),系统中共产生了 4 个请求(图中的 0、1、2、3 位置),不管这些请求是同步还是异步,这些请求都是真实存在的。如果再来一个线程,也发同样的一个请求,那系统中必然总共产生 8 个请求,这个逻辑很清楚。如果我们把压力工具中线程的请求做为一个 T(压力工具中的事务数),那它对应的后端就应该是 4 个 R(后端请求总数);
PS:在压力工具中是无法统计出后端的 4 个请求的,且这也必要统计的,这个统计工作,应该留给业务监控、日志监控的系统去做,不用再去增加压力工具的负担。
显然请求和 TPS 是线性关系,除非发的不是这个请求,而是其他的请求,或者是改变了参数。如果愿意关注后端 RPS,就去关注;如果愿意关注压力工具的 TPS,也无所谓;
但是,在一个项目的具体实践中,不管是 RPS 还是 TPS,一定要达成共识,统一概念,并且都能有同样的理解形成共识(方便后续工作开展),既然 TPS、RPS 是线性的,那么也不存这两种度量当成是对立面来看待,因为这不仅会增加性能理解的复杂度,也没有实际的价值。