通过训练生成对抗网络(GAN),让生成器学会生成逼真的手写数字图像。
目录
[生成对抗网络 GAN](#生成对抗网络 GAN)
[训练 GAN](#训练 GAN)
生成对抗网络 GAN
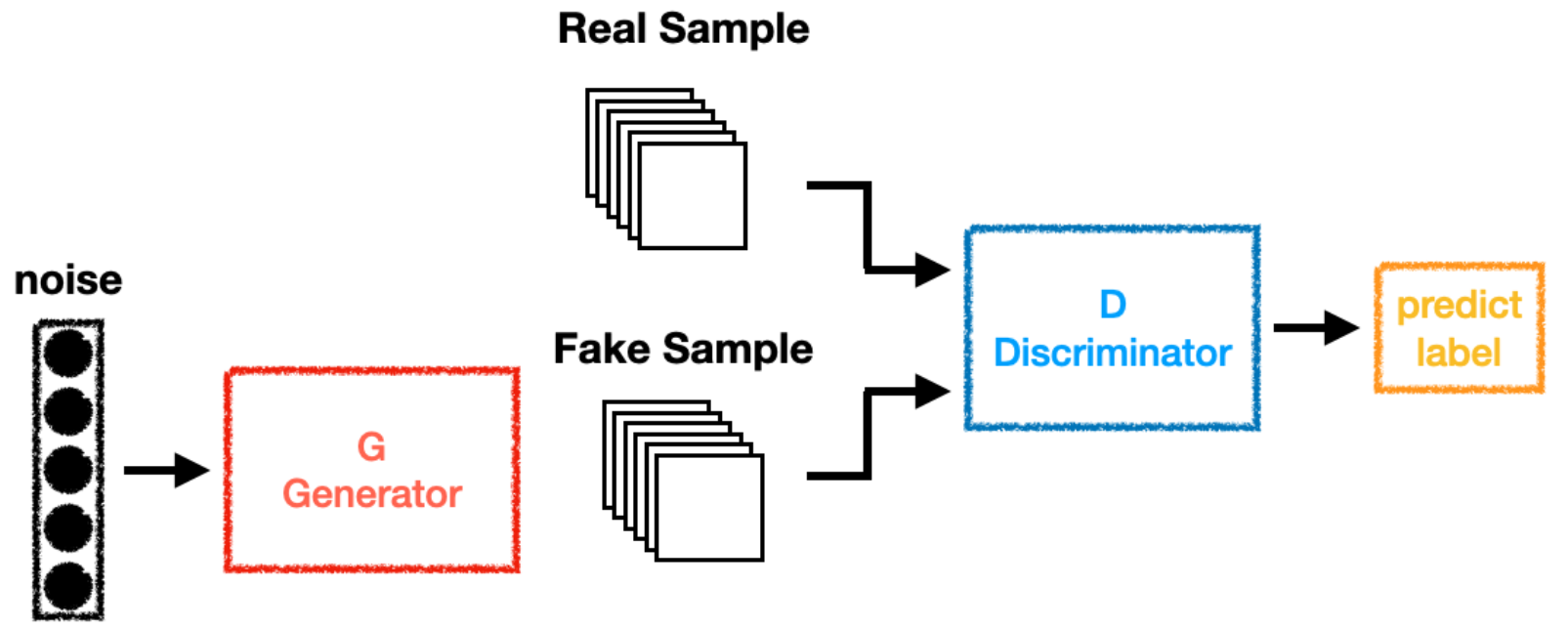
一部分为生成网络(Generative Network),此部分负责生成尽可能地以假乱真的样本,这部分被成为生成器(Generator);
另一部分为判别网络(Discriminative Network), 此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为判别器(Discriminator) 生成器和判别器的互相博弈,就完成了对抗训练。
在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据 (通常是目标域) 当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器 (Feature Extractor)。
本地环境
Windows + Conda + CPU
conda install pytorch torchvision torchaudio cpuonly -c pytorch
代码
生成器(Generator)
输入 100 维随机噪声,通过全连接层逐步映射到 28×28 的图像(MNIST 图像尺寸)。
python
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 全连接层序列:输入噪声→输出图像
self.model = nn.Sequential(
nn.Linear(100, 256), # 100维噪声→256维
nn.LeakyReLU(0.2), # 激活函数(带小斜率的ReLU,防止梯度消失)
nn.Linear(256, 512), # 256→512
nn.LeakyReLU(0.2),
nn.Linear(512, 1024), # 512→1024
nn.LeakyReLU(0.2),
nn.Linear(1024, 28*28),# 1024→784(28×28的图像展平)
nn.Tanh() # 输出值限制在[-1, 1](与预处理后的真实图像一致)
)
def forward(self, x):
# 输入噪声x(形状:[batch_size, 100])
img = self.model(x)
# 重塑为图像格式:[batch_size, 1, 28, 28](1是通道数,MNIST是灰度图)
img = img.view(-1, 1, 28, 28)
return img判别器(Discriminator)
输入 28×28 的图像,输出该图像为 "真实图像" 的概率(0-1)。
python
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# s输入图像,输出频率
self.model = nn.Sequential(
nn.Linear(28*28, 512),
nn.LeakeyReLU(0.2),
nn.Linear(512, 256)
nn.LeakeyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # 输出限制在0-1 表示真实概率
)
def forward(self, x):
# 输入图像
x = x.view(-1, 28*28)
prob = self.model(x)
return prob初始化模型、损失函数和优化器
python
# 初始化模型生成器和判别器
generator = Generator()
discriminator = Discriminator()
# 损失函数:二元交叉熵
criterion = nn.BCELoss()
# 优化器 Adam
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.99))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.99))训练 GAN
交替训练判别器和生成器,通过对抗过程提升性能。
python
# 训练参数
epochs = 50 # 训练轮次(可根据效果调整,50轮基本能看到明显效果)
fixed_noise = torch.randn(16, 100) # 固定噪声(用于观察生成效果变化)
# 记录损失
G_losses = []
D_losses = []
for epoch in range(epochs):
for i, (real_imgs, _) in enumerate(dataloader): # 每次迭代加载一批真实图像
batch_size = real_imgs.size(0) # 批次大小(64)
# ---------------------
# 训练判别器
# ---------------------
# 真实图像标签:全1(希望判别器认为真实图像是"真")
real_labels = torch.ones(batch_size, 1)
# 伪造图像标签:全0(希望判别器认为伪造图像是"假")
fake_labels = torch.zeros(batch_size, 1)
# 1. 训练真实图像:判别器对真实图像的输出应接近1
real_output = discriminator(real_imgs)
d_loss_real = criterion(real_output, real_labels)
# 2. 训练伪造图像:生成器生成假图像,判别器对假图像的输出应接近0
noise = torch.randn(batch_size, 100) # 随机噪声
fake_imgs = generator(noise) # 生成假图像
fake_output = discriminator(fake_imgs.detach()) # 冻结生成器参数
d_loss_fake = criterion(fake_output, fake_labels)
# 总判别器损失:真实损失+伪造损失
d_loss = d_loss_real + d_loss_fake
# 更新判别器参数
optimizer_D.zero_grad() # 清空梯度
d_loss.backward() # 反向传播
optimizer_D.step() # 更新参数
# ---------------------
# 训练生成器
# ---------------------
# 生成器希望判别器将假图像判断为"真"(标签全1)
fake_output = discriminator(fake_imgs) # 此时不冻结生成器
g_loss = criterion(fake_output, real_labels)
# 更新生成器参数
optimizer_G.zero_grad() # 清空梯度
g_loss.backward() # 反向传播
optimizer_G.step() # 更新参数
# 记录损失
G_losses.append(g_loss.item())
D_losses.append(d_loss.item())
# 打印训练进度(每100批次打印一次)
if (i+1) % 100 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Batch [{i+1}/{len(dataloader)}], "
f"D Loss: {d_loss.item():.4f}, G Loss: {g_loss.item():.4f}")
# 每个epoch结束后,用固定噪声生成图像并显示(观察效果)
with torch.no_grad(): # 不计算梯度,节省资源
fake_imgs = generator(fixed_noise).detach() # 生成图像
# 显示16张生成的图像
plt.figure(figsize=(4,4))
for j in range(16):
plt.subplot(4,4,j+1)
# 反标准化:将[-1,1]转回[0,1]以便显示
img = fake_imgs[j].numpy().squeeze() # 去掉通道维度
img = (img + 1) / 2 # 反标准化
plt.imshow(img, cmap='gray')
plt.axis('off')
plt.suptitle(f"Epoch {epoch+1}")
plt.show()fixed_noise和循环中动态生成的noise作用?
fixed_noise 用于监控训练效果
- 作用:作为一个 "固定不变的基准输入",在每个 epoch 结束后生成图像,直观对比不同训练阶段生成器的效果(比如是否从模糊到清晰、从无意义到接近 MNIST 真实图像)。
- 为什么固定:只有输入噪声固定,才能排除 "噪声变化" 对生成结果的干扰,准确反映生成器自身能力的提升(而非噪声随机性导致的效果波动)。
循环中 noise:用于训练模型
- 作用:作为训练过程中动态生成的随机噪声,用于让生成器学习 "从任意随机噪声映射到真实图像分布" 的能力。
分析结果
python
plt.figure(figsize=(10, 5))
plt.plot(G_losses, label='Generator Loss')
plt.plot(D_losses, label='Discriminator Loss')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.legend()
plt.show()如何执行
建议使用虚拟环境
保存文件为 gan.py
运行:
python gan.py
遇到的问题
判别器损失函数很快收敛甚至为0,生成器越来越发散
为什么判别器容易收敛
判别器的任务相对简单,它只需要判断输入的数据是真实的还是假的。在训练初期,生成器生成的假数据质量很差,判别器很容易就能识别出来,比如生成器生成的图片可能只是一堆乱码,判别器很容易判断这是假的。
随着训练的进行,判别器不断学习,它的能力会越来越强,很快就能够很准确地判断出哪些是真实的,哪些是假的。这就像是一个警察,只要看到身份证上的照片和本人明显不符,就能轻易判断是假的。因此,判别器很容易就"收敛"了,也就是它的性能稳定下来,能够很好地完成任务。
为什么生成器容易发散
生成器的任务要难得多,它需要从随机噪声中生成逼真的数据。在训练初期,生成器生成的假数据质量很差,判别器很容易就能识别出来。生成器会根据判别器的反馈进行调整,但它很难一下子找到生成逼真数据的方法。
随着训练的进行,如果判别器变得太强,生成器可能就会"绝望"了。比如,判别器已经能轻易判断出生成器生成的所有数据都是假的,生成器就会收到很强的负面反馈,它可能会朝着错误的方向调整,导致生成的数据越来越差,甚至完全失去方向。这就像是一个造假者,无论怎么努力,都造不出像样的假货,最后可能越造越离谱。
尝试解决
- 更换损失函数
- 增加正则化
- 降低学习率
完整代码
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 数据预处理,转换为张量并标准化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载 MNIST 训练集
mnist_dataset = datasets.MNIST(
root = './data', # 数据集存放路径
train = True, # 自动下载数据集
transform = transform,
download = True
)
# 数据加载器
dataloader = DataLoader(
dataset = mnist_dataset,
batch_size = 64,
shuffle = True
)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 输入噪声,输出图像
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.BatchNorm1d(256), # 批量归一化
nn.LeakyReLU(0.2),
nn.Linear(256, 512),
nn.BatchNorm1d(512), # 批量归一化
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024), # 批量归一化
nn.LeakyReLU(0.2),
nn.Linear(1024, 28*28),
nn.Tanh() # 输出值限制在[-1, 1](与预处理后的真实图像一致)
)
def forward(self, x):
img = self.model(x)
img = img.view(-1, 1, 28, 28)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# s输入图像,输出频率
self.model = nn.Sequential(
nn.Linear(28*28, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
)
def forward(self, x):
# 输入图像
x = x.view(-1, 28*28)
prob = self.model(x)
return prob
# 初始化模型生成器和判别器
generator = Generator()
discriminator = Discriminator()
# 优化器 Adam
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.99))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0001, betas=(0.5, 0.99))
# WGAN损失函数
def wgan_loss(real_out, fake_out):
return -torch.mean(real_out) + torch.mean(fake_out)
# 梯度惩罚(WGAN-GP)
def gradient_penalty(discriminator, real_imgs, fake_imgs):
batch_size = real_imgs.size(0)
alpha = torch.rand(batch_size, 1, 1, 1).to(real_imgs.device)
interpolated = alpha * real_imgs + (1 - alpha) * fake_imgs
interpolated.requires_grad_(True)
d_interpolated = discriminator(interpolated)
gradients = torch.autograd.grad(
outputs=d_interpolated,
inputs=interpolated,
grad_outputs=torch.ones_like(d_interpolated),
create_graph=True,
retain_graph=True,
only_inputs=True
)[0]
gradients = gradients.view(batch_size, -1)
gp = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gp
# 训练 GAN
epochs = 100 # 训练轮次
fixed_noise = torch.randn(16, 100) # 固定噪声,用于观察生成效果变化
G_losses = []
D_losses = []
for epoch in range(epochs):
for i, (real_images, _) in enumerate(dataloader):# 每次迭代加载一批真实图像
batch_size = real_images.size(0)
# 训练判别器
# 1.训练真是图像(训练判别器)
real_output = discriminator(real_images)
# 2. 训练伪造图像:生成器生成假图像,判别器对假图像的输出应接近0
noise = torch.randn(batch_size, 100)
fake_imgs = generator(noise)
fake_output = discriminator(fake_imgs.detach()) # 冻结生成器参数
lambda_gp = 10 # 梯度惩罚系数
d_loss = wgan_loss(real_output, fake_output) + lambda_gp * gradient_penalty(discriminator, real_images, fake_imgs)
# 4. 反向传播,更新判别器参数
optimizer_D.zero_grad() # 清空梯度
d_loss.backward(retain_graph=True) # 反向传播
optimizer_D.step() # 更新参数
D_losses.append(d_loss.item())
# 训练生成器
# 生成器希望判别器将假图像判断为"真"(标签全1)
# 1. 训练伪造图像:生成器生成假图像,判别器对假图像的输出应接近1
fake_output = discriminator(fake_imgs)
g_loss = -torch.mean(fake_output)
# 2. 反向传播,更新生成器参数
optimizer_G.zero_grad() # 清空梯度
g_loss.backward() # 反向传播
optimizer_G.step() # 新增这行:更新生成器参数
# 记录损失
G_losses.append(g_loss.item())
D_losses.append(d_loss.item())
# 打印训练梯度
if(i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Step [{i+1}/{len(dataloader)}], D_loss: {d_loss.item():.4f}, G_loss: {g_loss.item():.4f}')
# 每个epoch结束后,用固定噪声生成图像并显示(观察效果)
with torch.no_grad():# 不计算梯度,节省资源
fake_imgs = generator(fixed_noise) # 生成图像
# 显示16张图像
plt.figure(figsize=(4, 4))
for j in range(16):
plt.subplot(4, 4, j+1)
# 反标准化
img = fake_imgs[j].numpy().squeeze()
img = (img + 1) / 2
plt.imshow(img, cmap='gray')
plt.axis('off')
plt.suptitle(f'Epoch {epoch+1}')
plt.show()
# 结果分析
plt.figure(figsize=(10, 5))
plt.plot(G_losses, label='Generator Loss')
plt.plot(D_losses, label='Discriminator Loss')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.legend()
plt.show()