本文根据 2025 云栖大会演讲整理而成,演讲信息如下
演讲人: 聂清 零跑汽车大数据高级专家
零跑科技的快速发展与数据挑战
 零跑科技成立于2015年12月,总部位于浙江杭州,是国内造车新势力中唯一具备全域自研自造能力及垂直整合度最高的智能电动车企业。业务涵盖整车设计、研发制造、智能驾驶等领域,始终致力于为用户创造价值。
零跑科技成立于2015年12月,总部位于浙江杭州,是国内造车新势力中唯一具备全域自研自造能力及垂直整合度最高的智能电动车企业。业务涵盖整车设计、研发制造、智能驾驶等领域,始终致力于为用户创造价值。
特别值得一提的是,就在演讲前一天,零跑迎来了第100万台量产车的下线。从50万台到100万台,零跑仅用343天时间,标志着零跑汽车已经迈入规模化发展的新阶段。这种跨越式的增长速度在行业内实属罕见。
随着近几年零跑销量逐年翻倍增长及车型矩阵持续丰富,业务端对数据的需求也发生了本质性变化。过去,企业提供的基本都是T+1的离线数据,这种延迟在当时的业务场景下尚可满足需求。但如今,分钟级甚至秒级的数据已经成为业务刚需。正是业务对数据实效性的强烈需求,推动了零跑科技实时计算的构建与落地。
在智能网联汽车的发展中,实时计算至关重要。随着大数据、物联网和人工智能等技术的飞速发展,实时计算在数据处理领域的重要性日益凸显。它不仅能够提高数据处理效率、支持实时决策,还能优化业务流程、提升客户体验,推动创新应用的持续发展。
为什么选择Flink?
在Flink出现之前,业界已经有两款主流的流处理框架。最早是Storm,由Twitter在2011年开源。Storm的ACK机制很好地解决了"至少一次"语义的问题,确保了数据不丢失。然而,大多数业务场景更需要"精确一次性"语义来保证数据的一致性。
随后出现的Spark Streaming通过微批模式实现了精确一次性语义,但存在天然缺陷:本质上仍是将流数据细分成微批进行计算,导致最低延迟只能达到分钟级别,无法满足更高实时性要求的场景。
直到2014年Flink的出现,才真正解决了在大数据应用场景下强一致性与低延时之间的矛盾。Flink是分布式流处理框架,旨在提供高吞吐、低延迟、高性能的流数据处理能力。它统一了流处理和批处理,设计之初就认为"批是流的特例",整个系统采用Native Streaming设计,每条数据都能够触发计算。  Flink具有四大核心优势:低延迟与高吞吐的完美结合、精确一次性语义的可靠保障、强大的状态管理能力、灵活的时间语义与窗口机制。正是基于这些优秀特性,零跑科技最终选择Flink作为实时计算的核心引擎。
Flink具有四大核心优势:低延迟与高吞吐的完美结合、精确一次性语义的可靠保障、强大的状态管理能力、灵活的时间语义与窗口机制。正是基于这些优秀特性,零跑科技最终选择Flink作为实时计算的核心引擎。
零跑科技大数据平台架构
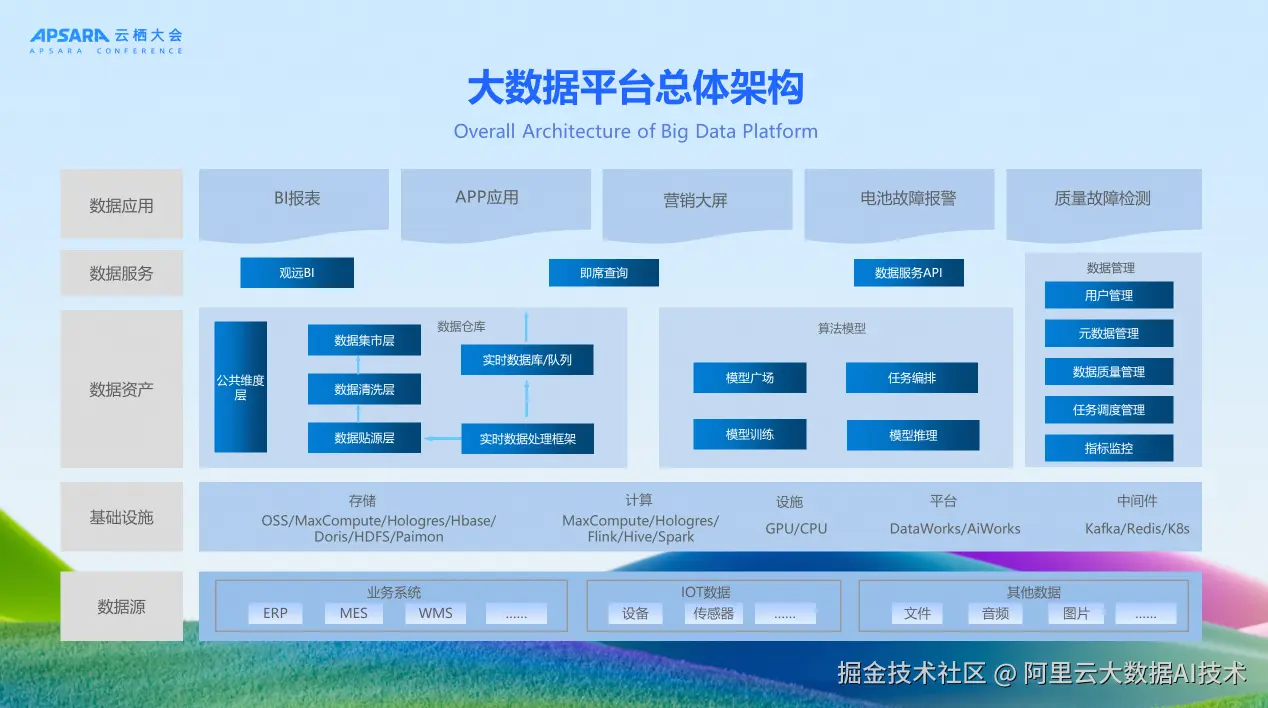 零跑汽车的大数据平台总体架构自下而上分为五层。最底层是数据源层,主要覆盖三类核心数据:业务系统类的关系型数据,如ERP、MES等多达几十种业务系统;IoT设备上的数据,以车机信号类传感器数据为主,这类数据多呈现为半结构化形式;文件、视频、图片等非结构化数据。
零跑汽车的大数据平台总体架构自下而上分为五层。最底层是数据源层,主要覆盖三类核心数据:业务系统类的关系型数据,如ERP、MES等多达几十种业务系统;IoT设备上的数据,以车机信号类传感器数据为主,这类数据多呈现为半结构化形式;文件、视频、图片等非结构化数据。
第二层是基础设施层,包括计算、存储及开发算法平台,为上层提供强大的资源支撑。平台采用OSS、MaxCompute、Hologres、Hbase、Doris、HDFS、Paimon等多种存储方案,计算层包括MaxCompute、Hologres、Flink、Hive、Spark等组件,还配备GPU/CPU算力资源,以及DataWorks和AiWorks等开发平台。
第三层是数据资产层,由数据仓库分层建模及算法训练模型和推理组成,为上层的数据服务及数据应用提供数据支撑。数据仓库采用标准的分层架构,包括数据贴源层、数据清洗层、公共维度层和数据集市层,同时建设了模型广场、模型训练和模型推理能力。
第四层是数据服务层,提供BI报表、即席查询、数据服务API等能力,同时具备完善的数据管理体系,包括用户管理、元数据管理、数据质量管理、任务调度管理和指标监控等功能。
最上层是数据应用层,包括观远BI、APP应用、营销大屏、电池故障报警、质量故障检测等多种应用场景,真正实现了数据价值的释放。
车机信号实时分析的挑战与实践
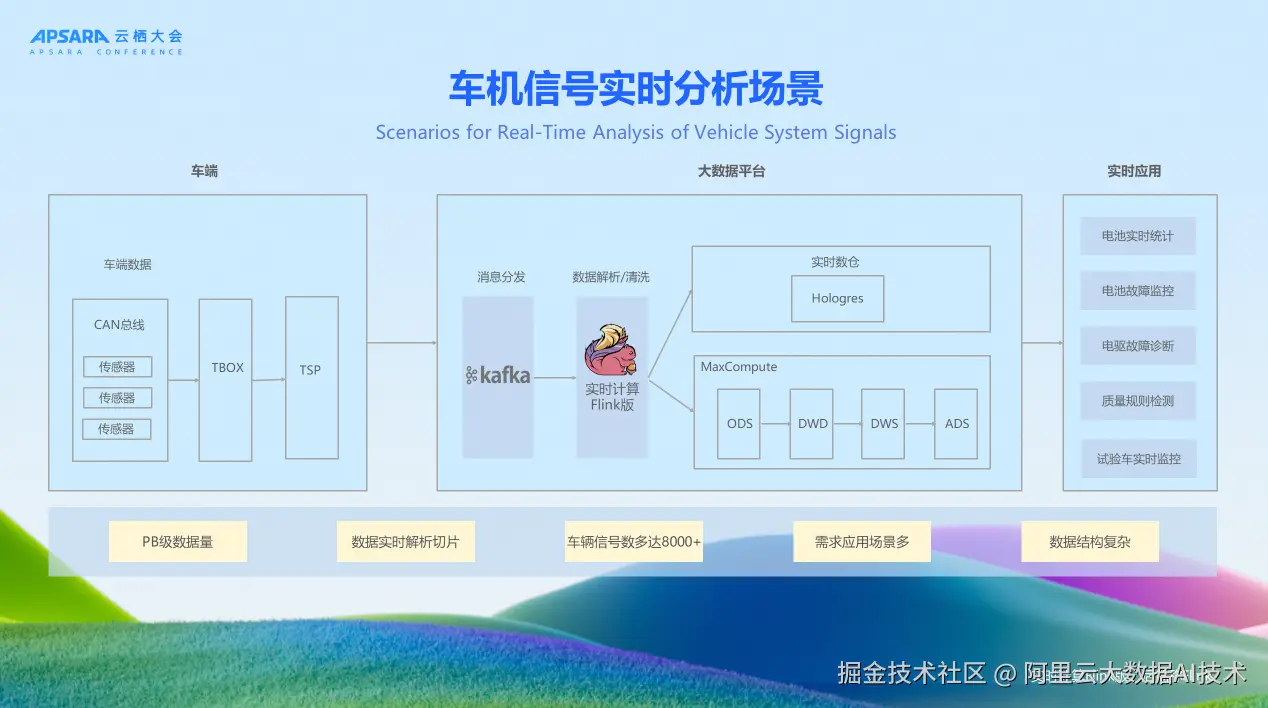
车机信号实时分析是零跑科技实时计算应用的核心场景之一。车辆启动后,CAN总线会产生大量传感器数据。这些数据通过T-Box传输到云端Kafka,经过Flink进行解析清洗,实时场景数据写入实时数仓Hologres,离线场景数据写入MaxCompute进行分层加工,最终供各类实时应用使用。
在数据流转过程中,面临着多重挑战。数据量巨大,目前已达PB级规模;大多数应用场景下,需要对信号数据进行实时切片处理;信号数量众多,高端车型的信号数远超8000个;需求应用场景繁多;数据结构极为复杂。
这些挑战对实时计算平台提出了极高要求,必须在保证数据准确性的前提下,实现高吞吐、低延迟的数据处理能力。
车辆故障诊断的实时应用
 车辆故障诊断是典型的实时计算应用场景。Flink与Hologres高吞吐低延迟的性能特性,完美支撑了该场景下的三大核心任务。
车辆故障诊断是典型的实时计算应用场景。Flink与Hologres高吞吐低延迟的性能特性,完美支撑了该场景下的三大核心任务。
实时故障解析是第一项任务。Flink将计算后的数据写入Hologres,并对故障进行状态更新。这里充分利用了Hologres主键模型的UPSERT能力,能够高效进行数据更新操作。
质量规则监控是第二项任务。业务层将质量标准配置成规则,Flink通过Flink CDC读取这些规则,关联车辆信号数据,最终写入Hologres,支撑质量问题的追溯分析。
AI智能预测预警是第三项任务。Flink实时解析信号并及时计算特征,输入AI模型预测故障发生概率。针对高风险车辆的异常数据,系统主动触发服务维护,形成从监测到预测再到用户服务的完整业务循环。
在该场景中,Hologres的重要特性凸显出来------实时写入即可见。相比之下,ClickHouse、Doris等OLAP型数据库,数据可见性更多依赖于Flink的checkpoint时长。在生产环境中,checkpoint一般设置为几十秒甚至一两分钟级别,因为过短的checkpoint时长会影响计算性能。而Hologres完全不受此限制,数据写入后立即可见,这对于实时性要求极高的故障诊断场景至关重要。
基于Flink的一体化实时计算平台
 在构建一体化实时计算平台之前,零跑科技的常规开发运维情况是:Flink作业部署在Kubernetes及Yarn上,由开发人员或运维人员通过命令行创建Flink Session,或直接通过命令行提交JAR作业进行部署。
在构建一体化实时计算平台之前,零跑科技的常规开发运维情况是:Flink作业部署在Kubernetes及Yarn上,由开发人员或运维人员通过命令行创建Flink Session,或直接通过命令行提交JAR作业进行部署。
这种方式产生了一系列问题。部署在Yarn上的部分作业中,离线任务与实时任务混部,导致在高峰期离线任务会挤占实时任务资源,造成状态丢失,最终导致数据不一致。此外还存在作业种类繁多、研发人员众多导致管控困难、监控分散等问题。
基于阿里云的Flink一体化实时计算平台后,这些问题得到了明显改善。平台提供统一界面,支撑Flink SQL及JAR作业的提交,具备可视化的资源配置及弹性扩缩容能力。一致性的状态管理保证了数据的一致性。特别值得一提的是,Flink全链路的监控指标非常完善,能够进行实时告警,同时简化了开发人员的操作流程。
总结来看,有了这个平台后,零跑科技实现了从分散管控到集中管控的转变,显著提升了研发效率及系统稳定性。
信号业务实时离线一体化实践
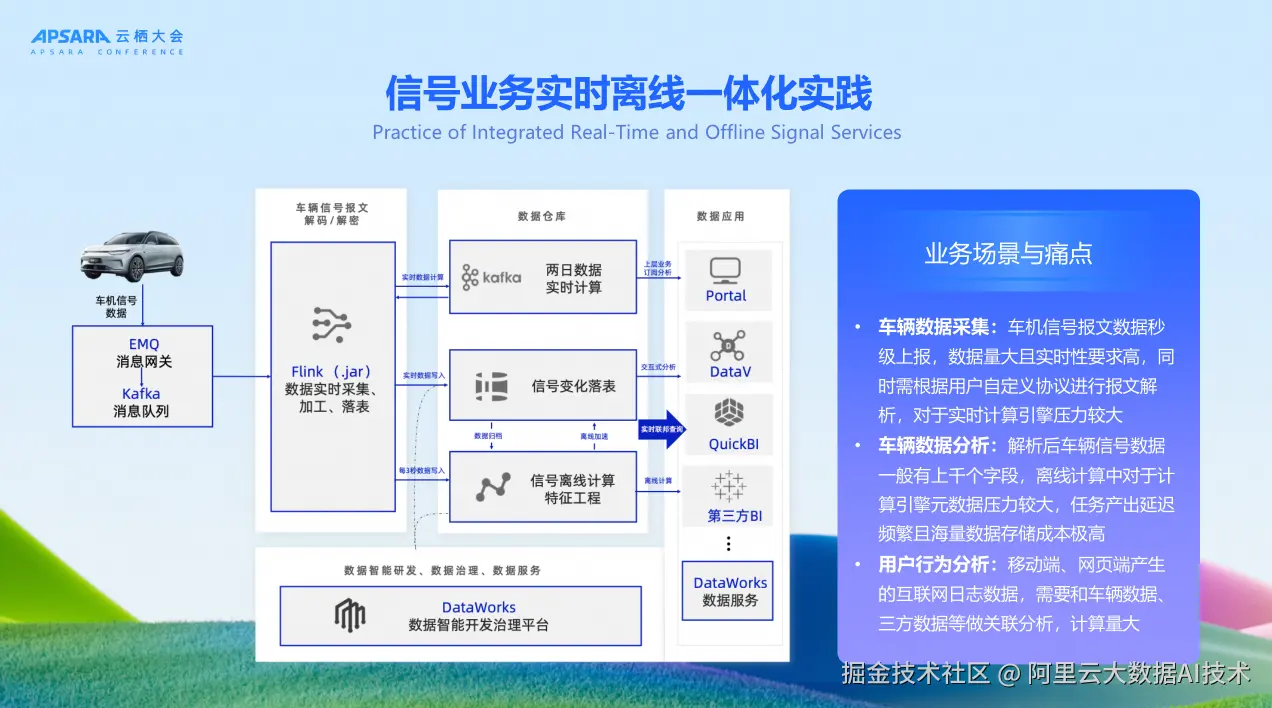 在正式落地该场景之前,零跑科技在去年的POC阶段进行了大量性能测试,主要涵盖三大类任务。Flink的JAR作业将信号解析后写入Kafka,供后续分层应用计算使用;Flink将信号变宽表写入Hologres;对信号进行切片处理后写入MaxCompute的大宽表。此外还包括复杂场景的测试,如MaxCompute里的复杂计算、多表join,以及Hologres的并发性能测试等。
在正式落地该场景之前,零跑科技在去年的POC阶段进行了大量性能测试,主要涵盖三大类任务。Flink的JAR作业将信号解析后写入Kafka,供后续分层应用计算使用;Flink将信号变宽表写入Hologres;对信号进行切片处理后写入MaxCompute的大宽表。此外还包括复杂场景的测试,如MaxCompute里的复杂计算、多表join,以及Hologres的并发性能测试等。  经过POC验证,性能提升效果非常显著。Flink作业解析信号写入Kafka,相比开源产品性能提升约60%。该环节主要为CPU解析过程,所以在三种作业中提升相对最小。Flink作业写入MaxCompute的大宽表,对比Hive性能提升200%。Flink JAR作业写入Hologres,对比ClickHouse性能提升高达400%。
经过POC验证,性能提升效果非常显著。Flink作业解析信号写入Kafka,相比开源产品性能提升约60%。该环节主要为CPU解析过程,所以在三种作业中提升相对最小。Flink作业写入MaxCompute的大宽表,对比Hive性能提升200%。Flink JAR作业写入Hologres,对比ClickHouse性能提升高达400%。  经过这一系列试验,总结出三大优势。首先是降本增效,通过提升作业性能、提高存储压缩比(压缩率提升五倍)及合理的定价策略,整体作业平均提升3倍以上,部分任务提升5倍以上,有效降低了存储成本。
经过这一系列试验,总结出三大优势。首先是降本增效,通过提升作业性能、提高存储压缩比(压缩率提升五倍)及合理的定价策略,整体作业平均提升3倍以上,部分任务提升5倍以上,有效降低了存储成本。
其次是架构升级。将开源Flink替换为云上全托管Flink,底层采用Flash向量化引擎进一步提升性能。ClickHouse替换为Hologres后,在分布式计算、多表join及高QPS场景下优势明显,能够支撑更多应用场景。Hive与Spark替换为MaxCompute后,6000字段以上的大宽表查询及写入性能实现翻倍提升。
第三是运维简化。云托管产品无需专门的运维人员,且具备自动调优能力,非常适合车机信号波峰波谷场景,能够明显节约资源。DataWorks提供开发、运维、治理全生命周期管理能力,极大提高了运维管控效率,同时实现了租户隔离、精细化访问控制等安全能力。
未来规划与展望
目前,基于Flink的实时计算体系已基本覆盖零跑科技的核心业务场景。但面向未来,零跑科技还将在两个方向继续发力。 
Flink与数据湖的深度融合是第一个方向。该方面已开始预研,部分小场景已基于Flink加数据湖实现了流批一体。未来希望扩大应用范围,通过Flink与Paimon的深度集成,实现统一元数据管理、统一存储及统一查询引擎,真正做到实时写入也能全量读取的流批一体数仓架构,最终实现降本增效的目标。
Flink与AI的深度融合是第二个方向,主要包括三个方面。提升决策时效性,通过Flink实时处理流数据,为AI模型提供最新特征,将决策时效性从小时级提升至秒级。探索Flink Agents场景,尝试Flink与多模态数据管理、Agent、模型预训练场景的落地,同时提供多种研发范式,降低研发门槛。构建实时特征计算平台,结合数据流优化、计算优化、状态管理、资源调度等多方面技术,针对长窗口特征计算进行进一步优化,提升实时特征计算的效率。
总结
零跑科技的实时计算实践始终遵循原则------从业务刚需出发,以技术为支撑,最终回归业务价值。这也是零跑科技能够在短短几年内实现从0到100万台量产车跨越的重要原因之一。
通过Flink与Hologres的深度应用,零跑科技不仅解决了智能网联汽车场景下海量数据的实时处理难题,更为整个行业提供了宝贵的实践经验。在数据洪流中驰骋,零跑科技正在用技术创新驱动智能汽车产业的数字化转型。