本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
在自然语言处理(NLP)的世界里,有一个词几乎无处不在------Embedding(嵌入表示) 。
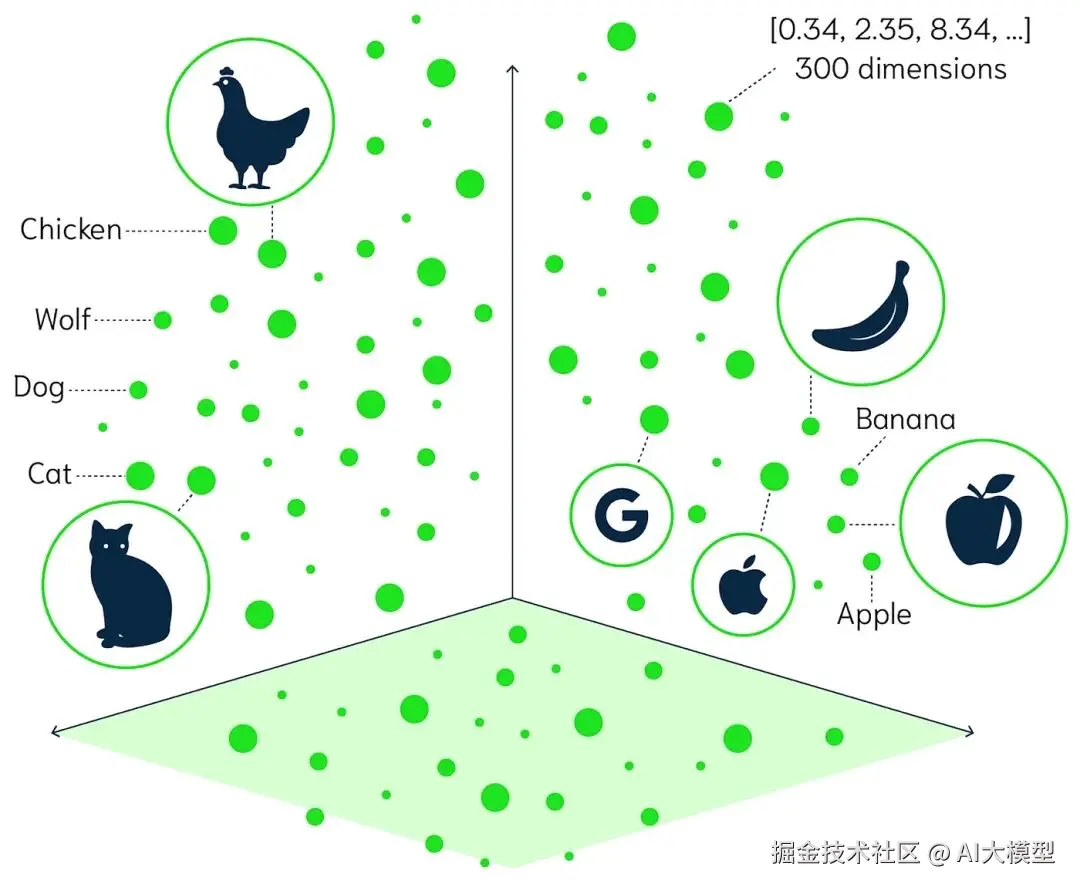
它是语言被机器理解的第一步,是模型通向"语义"的桥梁。
简单来说,Embedding就是把文字转成数字。但这个"转"的过程并不简单,它经历了三次重要的技术演化。
今天我们就来讲讲------Embedding的三大分类:
① 传统基于统计的词向量表示
② 基于浅层神经网络的静态词向量
③ 基于深度学习大模型的上下文动态词向量
传统统计类:从"数词频"开始
时间回到上个年代,机器还"懵懂无知"。
要让它理解文字,人类最先想到的办法是------统计。于是有了我们熟悉的三种方法:
-
One-hot Encoding: 每个词一个独立编号,向量中只有一个位置是1,其余全是0。 简单粗暴,但"我"和"你"之间没有任何语义关系,全靠瞎猜。
-
Bag of Words(词袋模型) : 不再关心词序,只统计一个句子里词出现的次数。 缺点是"我爱你"和"你爱我"在它眼里没区别。

-
TF-IDF(词频-逆文档频率) : 稍微聪明点,会考虑"常见词"没什么信息量。 但依旧停留在"统计层面",完全不懂语义。
某个词在该样本中出现的次数总的样本数包含有该词的样本数
这一阶段的 Embedding,就像机器在背生词表。 它能数清词出现几次,却听不懂词的意思。
静态词向量:让词"有了灵魂"
2013年,Word2Vec 横空出世。这标志着Embedding正式进入神经网络时代。
Word2Vec的思想非常巧妙:"你是什么样的词,取决于你周围出现的词。"这就是著名的分布式假设(Distributional Hypothesis)。
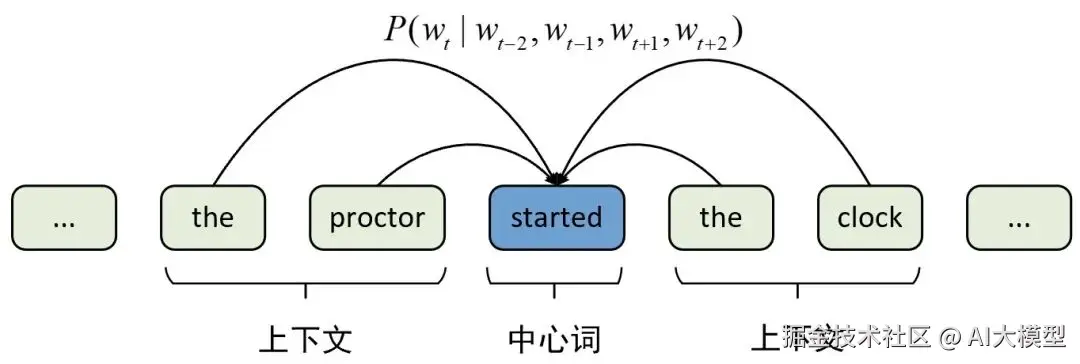
通过一个浅层神经网络(两层而已), 模型学会把语义相近的词映射到相近的向量空间中。
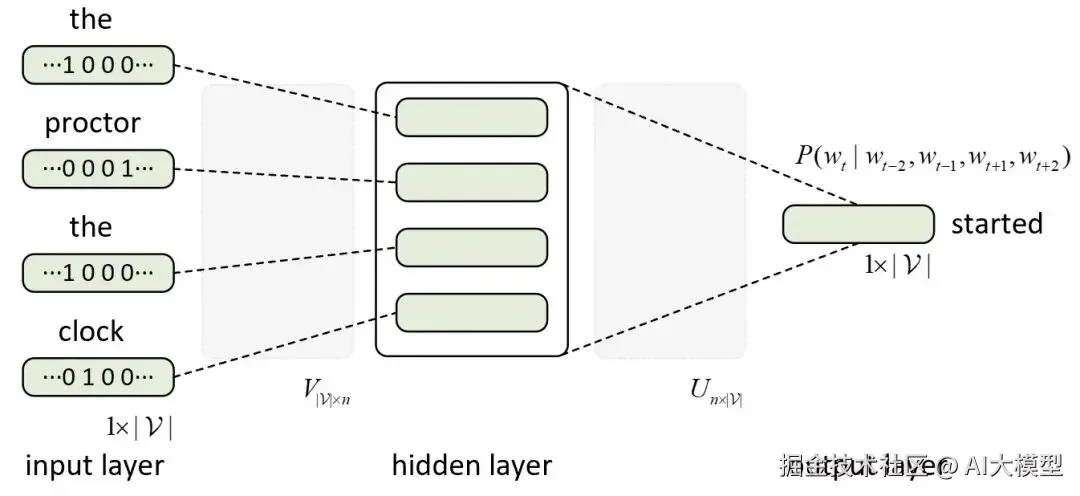
比如:
- "国王"和"王后"的向量差 ≈ "男人"和"女人"
- "巴黎" - "法国" + "日本" ≈ "东京"
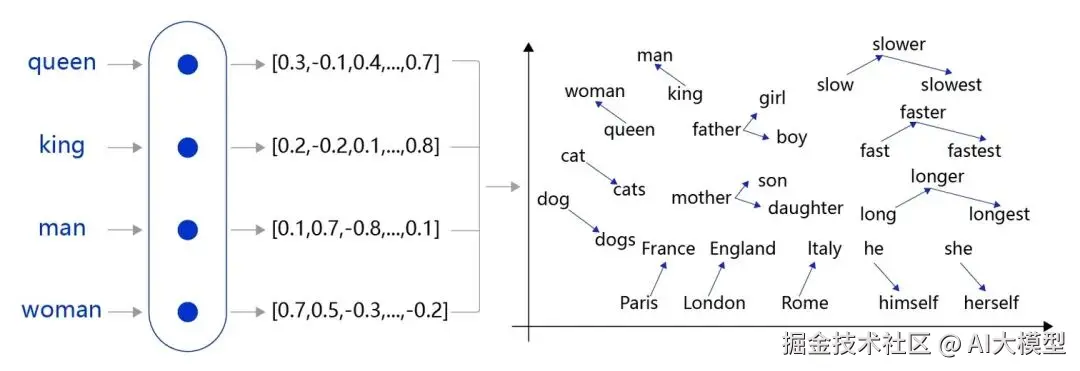
后来的 GloVe 、FastText 也属于这类"静态词向量"。
它们的特点是:
- 语义更丰富,能捕捉词间关系
- 但每个词只有一个固定向量,无论上下文是什么
所以在它眼里,"苹果"在"吃苹果"和"苹果电脑"中,是同一个向量。
动态词向量:让词"看懂上下文"
到了ELMo、BERT、GPT等大模型时代,Embedding再一次质变。
这次的关键词是------ "上下文(Contextualized)" 。
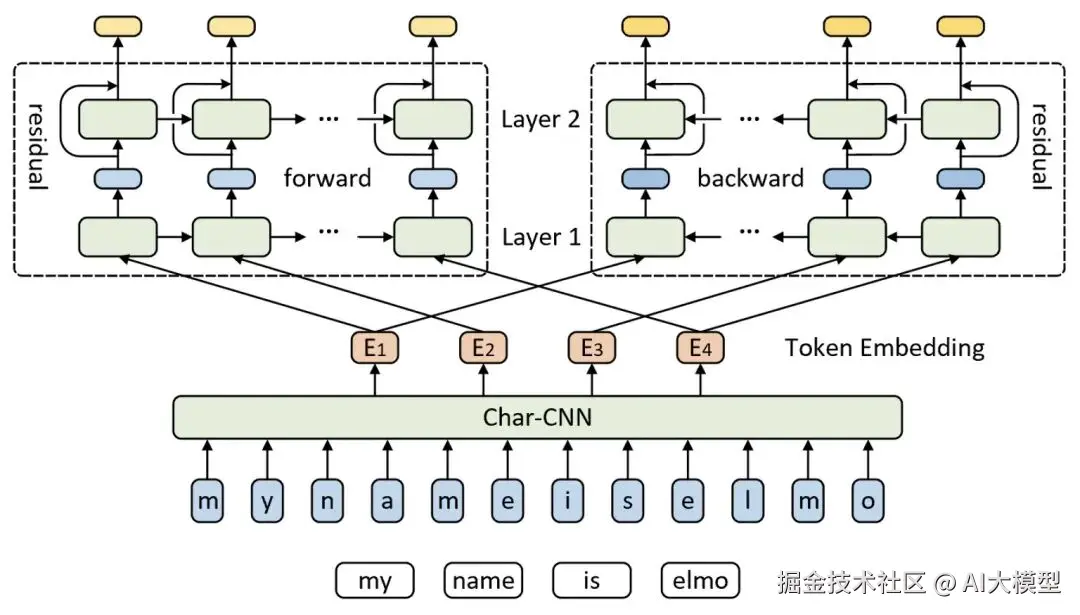
模型不再给每个词固定一个向量,而是根据整个句子的语境,动态生成词的表示。
举个例子:"我买了一个苹果 🍎" 和 "我在调试苹果电脑 💻"
在BERT中,"苹果"会有两种完全不同的Embedding。因为模型能"理解"上下文,知道你说的是水果还是品牌。
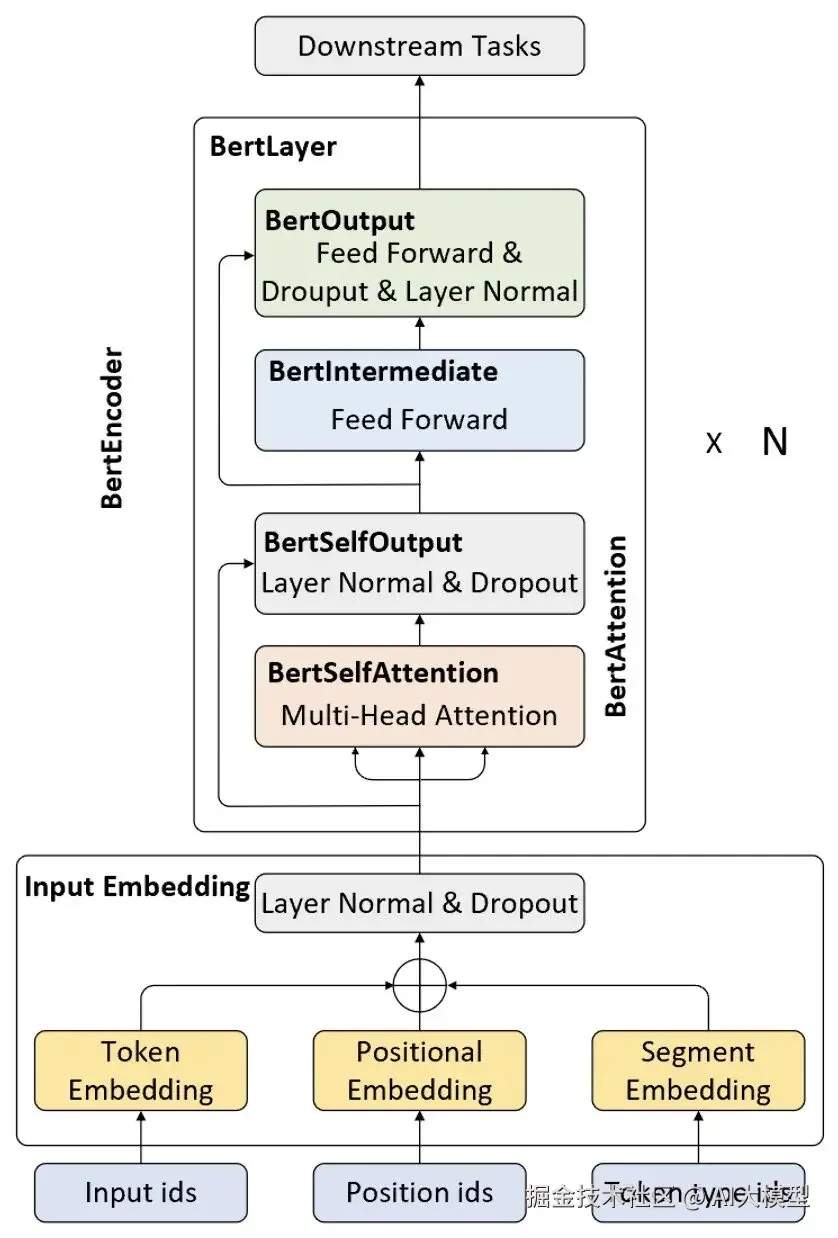
这背后的原理是多层Transformer,每一层都会更新词的表示,让Embedding越来越贴近语义。
最终,这类动态词向量成了大模型的"语言底座",支撑起ChatGPT、Claude、Gemini等的强大语义理解能力。
4 总结
| 类型 | 核心代表 | 是否理解语义 | 是否依赖上下文 | 特点 |
|---|---|---|---|---|
| 统计型 | TF-IDF, BoW | ❌ | ❌ | 简单但无语义 |
| 静态词向量 | Word2Vec, GloVe | ✅ | ❌ | 语义固定不变 |
| 动态词向量 | BERT, GPT | ✅ | ✅ | 语境敏感,理解力最强 |
可以把这三类Embedding想象成语言理解的三次进化:
- 第一代:机器会数数
- 第二代:机器能联想
- 第三代:机器能理解
Embedding虽然只是"语言输入层",但它决定了机器能否"听懂人话"。从词频统计到语义建模,再到上下文理解,这条演化之路,正是NLP智能化的缩影。当机器能真正理解"词在语境中的含义",它就离"懂人"更近了一步。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。