文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: F042
✅ 知识图谱构造+导入neo4j
✅ A星算法推荐课程(A*)
✅ 知识图谱推理路径展示
✅ 知识图谱可视化+搜索子图
✅ vue+flask+neo4j前后端分离B/S架构
视频
https://www.bilibili.com/video/BV18o4y1M7pN
1 系统简介
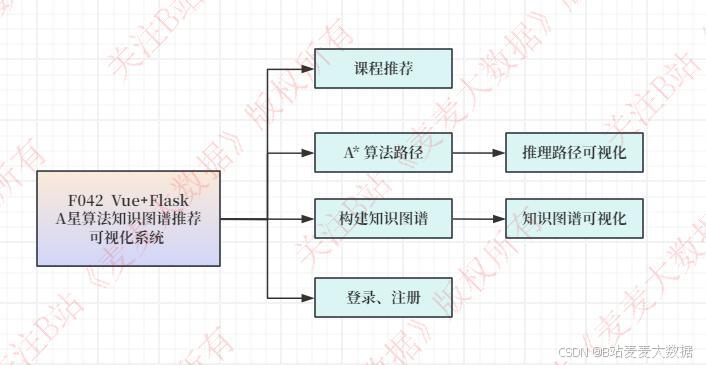
系统简介:本系统是一个基于Vue+Flask+Neo4j构建的课程推荐可视化系统,旨在通过知识图谱技术为用户提供个性化的课程推荐服务。系统的核心功能包括:知识图谱构造与导入Neo4j数据库,为系统提供数据支持;利用A星算法进行课程推荐,为用户推荐最适合的学习路径;知识图谱推理路径展示,让用户了解推荐课程的推理过程;知识图谱可视化模块,通过图表形式展示整体知识图谱结构,并支持搜索子图功能,方便用户查找相关信息;以及采用Vue+Flask+Neo4j构建的B/S架构前后端分离模式,确保系统的高效稳定运行。
2 功能设计
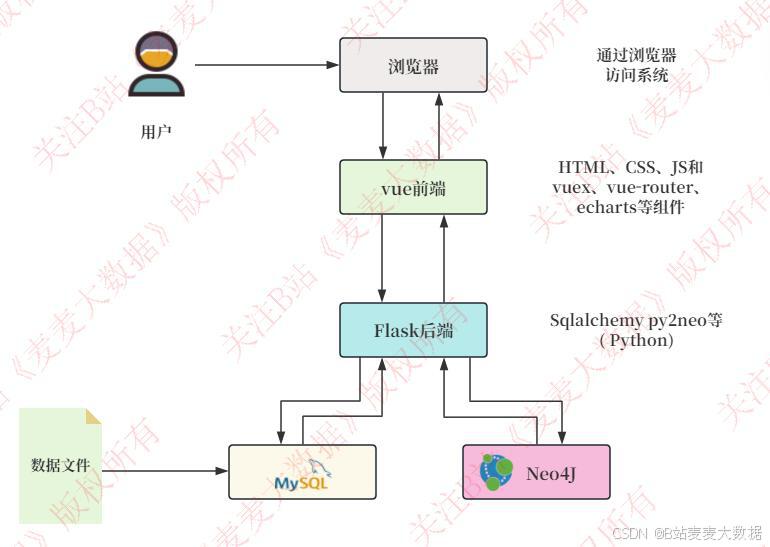
该系统采用经典的B/S(浏览器/服务器)架构模式。用户通过浏览器访问Vue前端界面,该前端由HTML、CSS、JavaScript以及Vue.js生态系统中的Vuex(用于状态管理)、Vue Router(用于路由导航)和Echarts(用于数据可视化)等组件构建。前端通过API请求与Flask后端进行数据交互,Flask后端则负责业务逻辑处理,并利用SQLAlchemy(或类似ORM工具)与MySQL数据库进行持久化数据存储,同时与Neo4j数据库进行知识图谱数据的读写操作。此外,系统还包含一个独立的数据抓取和导入模块,负责从外部来源抓取课程相关信息并将其导入Neo4j数据库,为知识图谱的构建和推荐算法提供数据支撑。
2.1系统架构图
2.2 功能模块图
3 功能展示
3.1 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击去登录后者去注册可以切换,背景是一个视频,循环播放。
登录需要验证用户名和密码是否正确,如果不正确会有错误提示 。
注册需要验证用户名是否存在 ,如果错误会有提示。
3.2 课程推荐,利用A*算法
主页的布局采用了左侧是菜单,右侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。

3.3 推理路径可视化
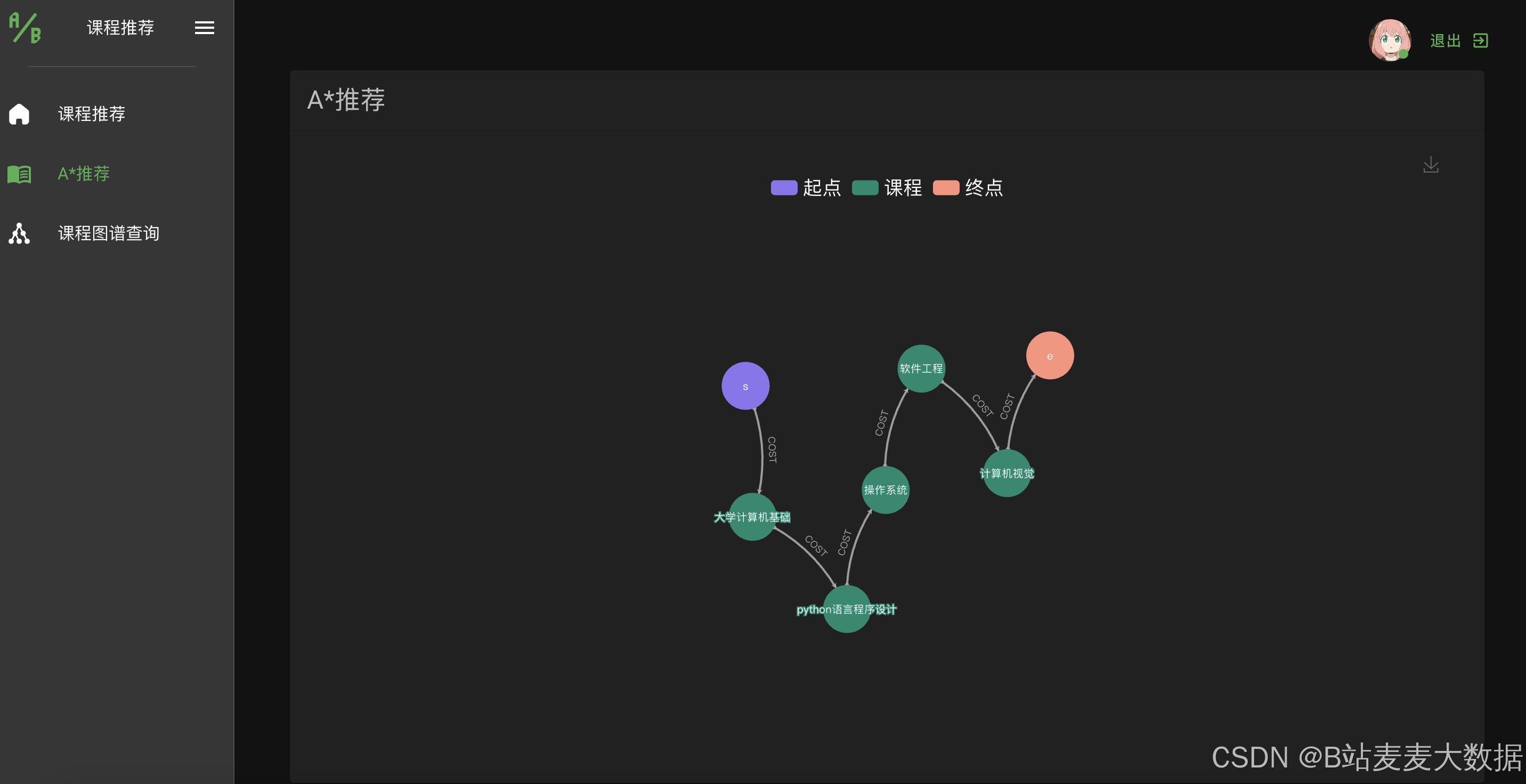
3.4 知识图谱可视化
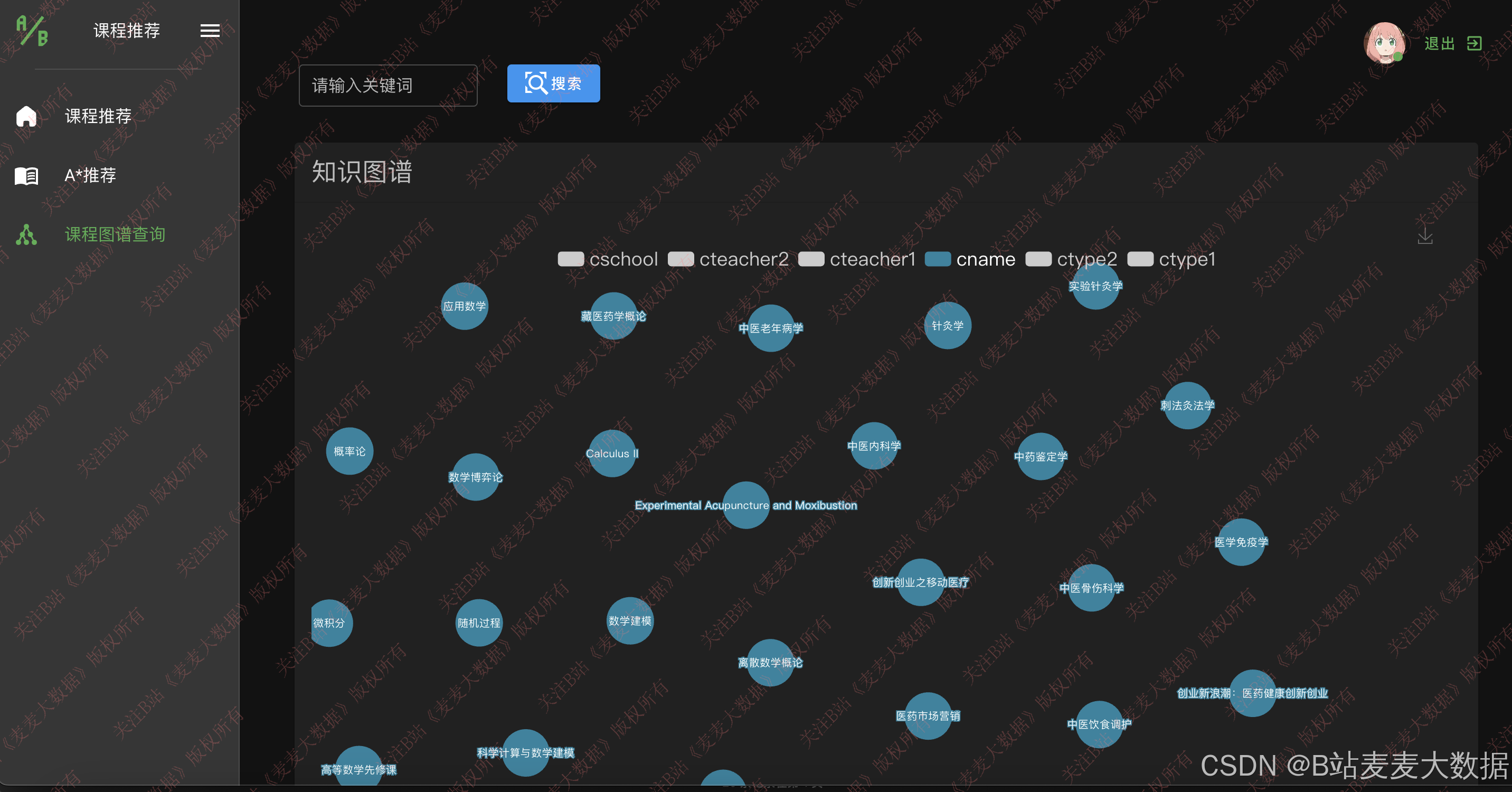
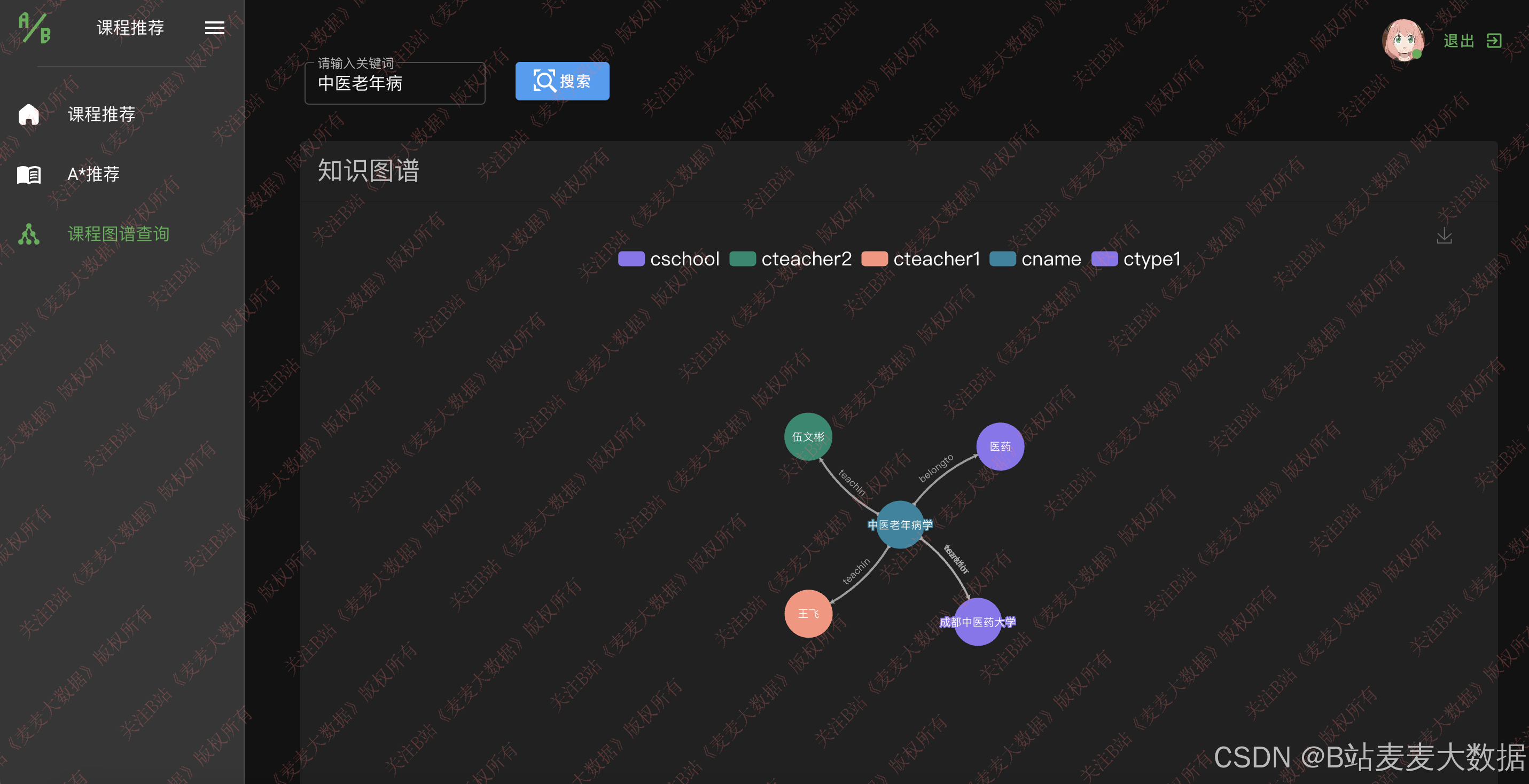
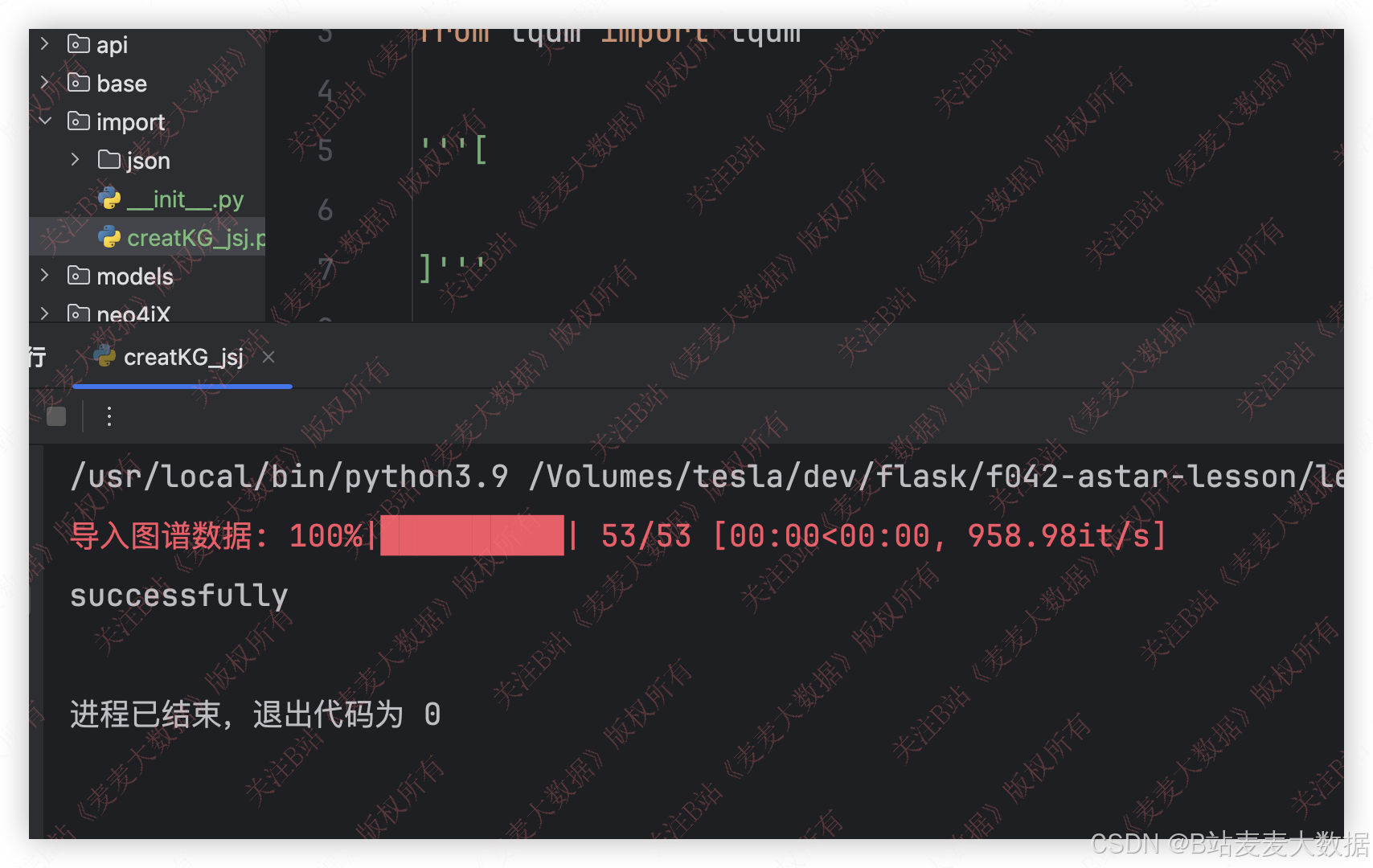
3.5 图谱构造过程
4程序代码
4.1 代码说明
代码介绍:一个基于Python和Neo4j的A*算法实现的课程推荐系统代码片段。该系统以用户兴趣为初始节点,通过计算路径代价和启发式代价,找到最优推荐路径。代码首先连接Neo4j数据库,查询出所有可能的课程节点和关系,然后根据用户兴趣进行课程推荐。
4.2 流程图
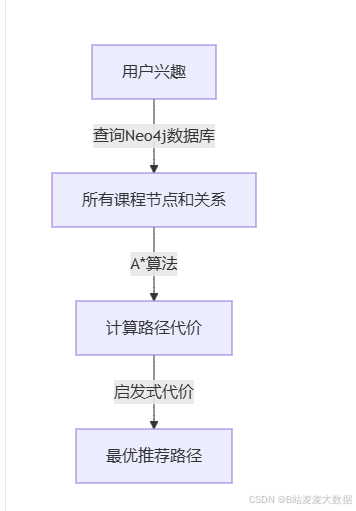
4.3 代码实例
python
from py2neo import Graph, Node, Relationship
import heapq
# 连接Neo4j数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 定义A*算法
def a_star_search(start_node, goal_node):
open_set = []
heapq.heappush(open_set, (0, start_node))
came_from = {}
g_score = {start_node: 0}
f_score = {start_node: heuristic_cost_estimate(start_node, goal_node)}
while open_set:
current = heapq.heappop(open_set)[1]
if current == goal_node:
return reconstruct_path(came_from, current)
for neighbor in graph.run(f"MATCH (current)-[r]->(neighbor) WHERE id(current) = {current.identity} RETURN neighbor, r.weight AS weight"):
tentative_g_score = g_score[current] + neighbor['weight']
if neighbor['neighbor'] not in g_score or tentative_g_score < g_score[neighbor['neighbor']]:
came_from[neighbor['neighbor']] = current
g_score[neighbor['neighbor']] = tentative_g_score
f_score[neighbor['neighbor']] = tentative_g_score + heuristic_cost_estimate(neighbor['neighbor'], goal_node)
heapq.heappush(open_set, (f_score[neighbor['neighbor']], neighbor['neighbor']))
return None
def heuristic_cost_estimate(node, goal_node):
# 简单启发式函数示例,这里假设所有节点之间的距离为1
return 1
def reconstruct_path(came_from, current):
total_path = [current]
while current in came_from:
current = came_from[current]
total_path.append(current)
return total_path[::-1]
# 获取用户感兴趣的起始节点ID
start_node_id = 1 # 假设用户感兴趣的课程ID为1
start_node = Node.identity(graph.run(f"MATCH (n) WHERE id(n) = {start_node_id} RETURN n").evaluate())
# 定义目标节点ID
goal_node_id = 5 # 假设目标课程ID为5
goal_node = Node.identity(graph.run(f"MATCH (n) WHERE id(n) = {goal_node_id} RETURN n").evaluate())
# 获取推荐路径
recommended_path = a_star_search(start_node, goal_node)
print(recommended_path)