
👨💻程序员三明治 :个人主页
🔥 个人专栏 : 《设计模式精解》 《重学数据结构》
🤞先做到 再看见!
目录
-
- [Redis List 队列](#Redis List 队列)
- 发布/订阅模型:Pub/Sub
- 趋于成熟的队列:**Stream**
-
- 1) Stream 是否支持「阻塞式」拉取消息? Stream 是否支持「阻塞式」拉取消息?)
- 2) Stream 是否支持发布 / 订阅模式? Stream 是否支持发布 / 订阅模式?)
- 3) 消息处理时异常,Stream 能否保证消息不丢失,重新消费? 消息处理时异常,Stream 能否保证消息不丢失,重新消费?)
- 4) Stream 数据会写入到 RDB 和 AOF 做持久化吗? Stream 数据会写入到 RDB 和 AOF 做持久化吗?)
- 与专业的消息队列对比
-
- 1) 生产者会不会丢消息? 生产者会不会丢消息?)
- 2) 消费者会不会丢消息? 消费者会不会丢消息?)
- 3) 队列中间件会不会丢消息? 队列中间件会不会丢消息?)
- 4) 消息积压怎么办? 消息积压怎么办?)
- 总结
很多人在做技术选型时会遇到一个问题:把 Redis 当作消息队列合适吗?
Redis 轻量、易用,但有人担心会丢数据;而 Kafka、RabbitMQ 这类专业中间件则更稳健但运维复杂。
本文从实际场景和技术细节出发,带你一步步看清 Redis(包括 List、Pub/Sub、Stream)与专业消息队列在队列场景下的差异与适用建议,帮助你做出更合适的选型决策。
Redis List 队列
Redis 的 List 本质上是双端链表,头尾操作复杂度均为 O(1),很适合实现简单的 FIFO 队列。
如果把 List 当作队列,你可以这么来用。
生产者使用 LPUSH 发布消息:
plain
127.0.0.1:6379> LPUSH queue msg1
(integer) 1
127.0.0.1:6379> LPUSH queue msg2
(integer) 2消费者这一侧,使用 RPOP 拉取消息:
plain
127.0.0.1:6379> RPOP queue
"msg1"
127.0.0.1:6379> RPOP queue
"msg2"问题1:轮询会造成 CPU 空转
如果消费者在循环中不断 RPOP,会出现空转,既浪费 CPU,又给 Redis 增加压力。常见的改进是当没有消息时 sleep 一段时间,但这会带来延迟。
问题2:延迟与阻塞读取
Redis 提供 BRPOP / BLPOP 实现阻塞读取,队列为空时消费者会阻塞,直到有新消息到来,从而避免空转并即时处理新消息(延迟最小化):
plain
while true:
msg = redis.rpop("queue")
// 没有消息,继续循环
if msg == null:
continue
// 处理消息
handle(msg)List 的局限
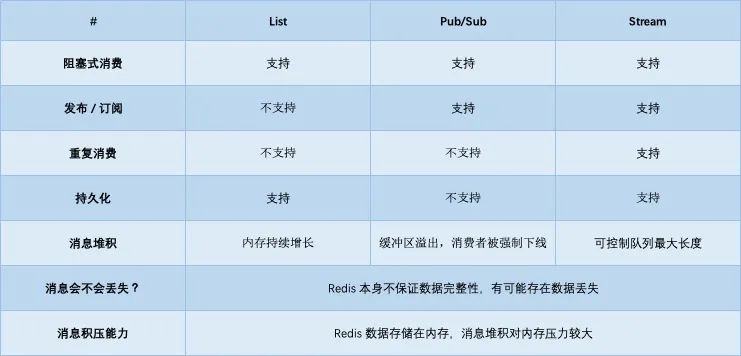
- 不支持多订阅(重复消费):同一条消息无法被多消费者/多业务并行消费。
- 消费失败后消息会丢失:消费者 RPOP 后若处理失败而未备份或重试,消息已从队列中移除。
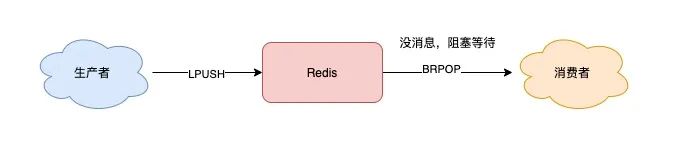
现在,你可以这样来拉取消息了:
plain
while true:
// 没消息阻塞等待,0表示不设置超时时间
msg = redis.brpop("queue", 0)
if msg == null:
continue
// 处理消息
handle(msg)那这种队列模型,还有什么缺点?
- 不支持重复消费:使用 List 做消息队列,它仅仅支持最简单的,一组生产者对应一组消费者;即不支持多个消费者消费同一条消息
为什么需要重复消费?
因为同一批消息可能需要触发多种业务动作(如支付成功后,需同步库存、发送短信通知、生成物流单),让不同消费者分别处理一种逻辑,解耦的操作。
- 消息丢失:消费者拉取到消息后,如果没消费成功,那这条消息就丢失了
发布/订阅模型:Pub/Sub
Redis 的 PUBLISH/SUBSCRIBE 适合广播场景,可以让多消费者同时收到同一条消息,满足多个业务并行处理的需求。
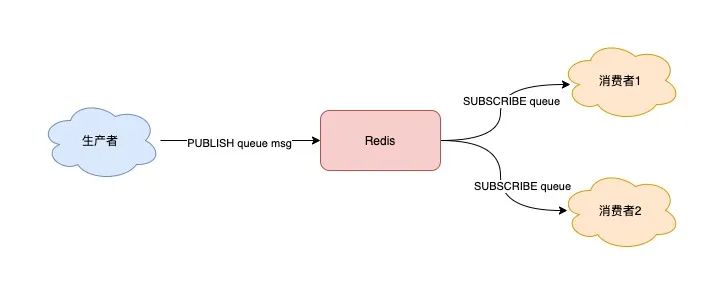
假设你想开启 2 个消费者,同时消费同一批数据,就可以按照以下方式来实现。
首先,使用 SUBSCRIBE 命令,启动 2 个消费者,并「订阅」同一个队列。
plain
// 2个消费者 都订阅一个队列
127.0.0.1:6379> SUBSCRIBE queue
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "queue"
3) (integer) 1此时,2 个消费者都会被阻塞住,等待新消息的到来。
之后,再启动一个生产者,发布一条消息。
plain
127.0.0.1:6379> PUBLISH queue msg1
(integer) 1这时,2 个消费者就会解除阻塞,收到生产者发来的新消息。
plain
127.0.0.1:6379> SUBSCRIBE queue
// 收到新消息
1) "message"
2) "queue"
3) "msg1"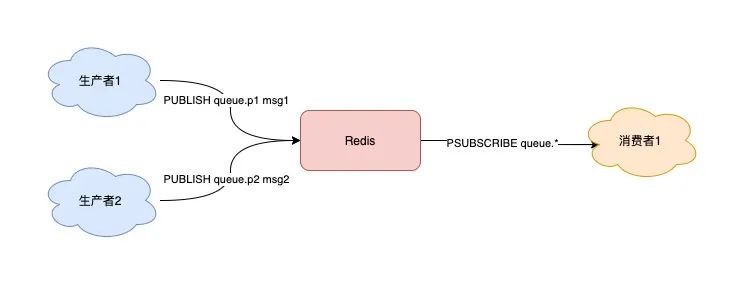
但 Pub/Sub 的主要问题是"丢数据"风险极高:
- 如果消费者掉线,消息就丢失;
- Redis 不保证持久化(除非额外持久化逻辑),Redis 宕机会丢失正在传输的消息;
- 消息堆积导致缓冲区溢出时,消费者会被踢下线,从而丢失消息。
因此,Pub/Sub 更适合对可靠性要求不高的实时广播(如在线聊天、实时通知)而非关键业务流水。
趋于成熟的队列:Stream
我们来看 Stream 是如何解决上面这些问题的。
首先,Stream 通过 XADD 和 XREAD 完成最简单的生产、消费模型:
- XADD:发布消息
- XREAD:读取消息
生产者发布 2 条消息:
powershell
// *表示让Redis自动生成消息ID
127.0.0.1:6379> XADD queue * name zhangsan
"1618469123380-0"
127.0.0.1:6379> XADD queue * name lisi
"1618469127777-0"使用 XADD 命令发布消息,其中的「*」表示让 Redis 自动生成唯一的消息 ID。
这个消息 ID 的格式是「时间戳-自增序号」。
消费者拉取消息:
powershell
// 从开头读取5条消息,0-0表示从开头读取
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 0-0
1) 1) "queue"
2) 1) 1) "1618469123380-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618469127777-0"
2) 1) "name"
2) "lisi"如果想继续拉取消息,需要传入上一条消息的 ID:
powershell
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 1618469127777-0
(nil)没有消息,Redis 会返回 NULL。
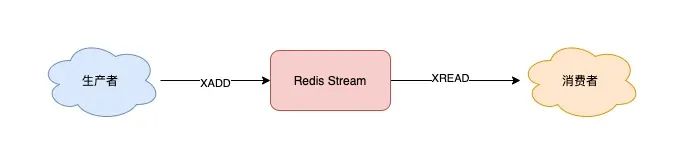
以上就是 Stream 最简单的生产、消费。
1) Stream 是否支持「阻塞式」拉取消息?
可以的,在读取消息时,只需要增加 BLOCK 参数即可。
powershell
// BLOCK 0 表示阻塞等待,不设置超时时间
127.0.0.1:6379> XREAD COUNT 5 BLOCK 0 STREAMS queue 1618469127777-0这时,消费者就会阻塞等待,直到生产者发布新的消息才会返回。
2) Stream 是否支持发布 / 订阅模式?
也没问题,Stream 通过以下命令完成发布订阅:
- XGROUP:创建消费者组
- XREADGROUP:在指定消费组下,开启消费者拉取消息
下面我们来看具体如何做?
首先,生产者依旧发布 2 条消息:
powershell
127.0.0.1:6379> XADD queue * name zhangsan
"1618470740565-0"
127.0.0.1:6379> XADD queue * name lisi
"1618470743793-0"之后,我们想要开启 2 组消费者处理同一批数据,就需要创建 2 个消费者组:
powershell
// 创建消费者组1,0-0表示从头拉取消息
127.0.0.1:6379> XGROUP CREATE queue group1 0-0
OK
// 创建消费者组2,0-0表示从头拉取消息
127.0.0.1:6379> XGROUP CREATE queue group2 0-0
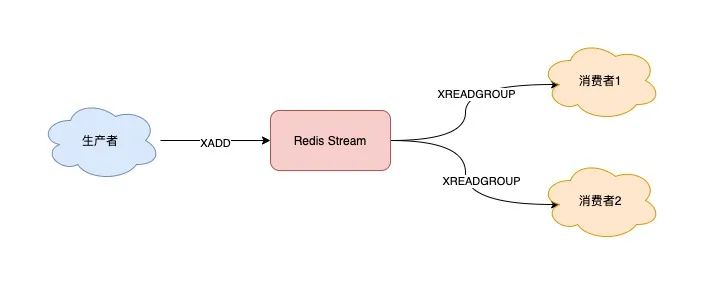
OK消费者组创建好之后,我们可以给每个「消费者组」下面挂一个「消费者」,让它们分别处理同一批数据。
第一个消费组开始消费:
powershell
// group1的consumer开始消费,>表示拉取最新数据
127.0.0.1:6379> XREADGROUP GROUP group1 consumer COUNT 5 STREAMS queue >
1) 1) "queue"
2) 1) 1) "1618470740565-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618470743793-0"
2) 1) "name"
2) "lisi"同样地,第二个消费组开始消费:
powershell
// group2的consumer开始消费,>表示拉取最新数据
127.0.0.1:6379> XREADGROUP GROUP group2 consumer COUNT 5 STREAMS queue >
1) 1) "queue"
2) 1) 1) "1618470740565-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618470743793-0"
2) 1) "name"
2) "lisi"我们可以看到,这 2 组消费者,都可以获取同一批数据进行处理了。
这样一来,就达到了多组消费者「订阅」消费的目的。
3) 消息处理时异常,Stream 能否保证消息不丢失,重新消费?
除了上面拉取消息时用到了消息 ID,这里为了保证重新消费,也要用到这个消息 ID。
当一组消费者处理完消息后,需要执行 XACK 命令告知 Redis,这时 Redis 就会把这条消息标记为「处理完成」。
powershell
// group1下的 1618472043089-0 消息已处理完成
127.0.0.1:6379> XACK queue group1 1618472043089-0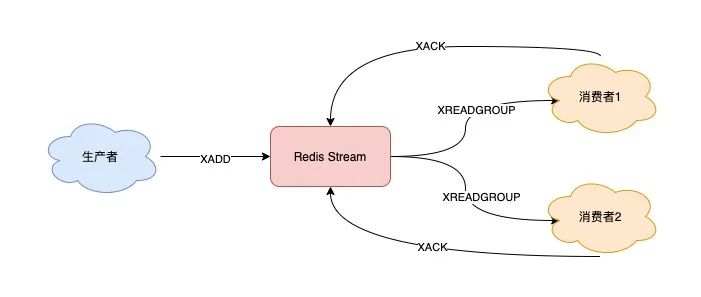
如果消费者异常宕机,肯定不会发送 XACK,那么 Redis 就会依旧保留这条消息。
待这组消费者重新上线后,Redis 就会把之前没有处理成功的数据,重新发给这个消费者。这样一来,即使消费者异常,也不会丢失数据了
powershell
// 消费者重新上线,0-0表示重新拉取未ACK的消息
127.0.0.1:6379> XREADGROUP GROUP group1 consumer1 COUNT 5 STREAMS queue 0-0
// 之前没消费成功的数据,依旧可以重新消费
1) 1) "queue"
2) 1) 1) "1618472043089-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618472045158-0"
2) 1) "name"
2) "lisi"4) Stream 数据会写入到 RDB 和 AOF 做持久化吗?
Stream 是新增加的数据类型,它与其它数据类型一样,每个写操作,也都会写入到 RDB 和 AOF 中。
我们只需要配置好持久化策略,这样的话,就算 Redis 宕机重启,Stream 中的数据也可以从 RDB 或 AOF 中恢复回来。
下面我们就来看一下,Redis 在作队列时,到底还有哪些欠缺?
与专业的消息队列对比
其实,一个专业的消息队列,必须要做到两大块:
- 消息不丢
- 消息可堆积
1) 生产者会不会丢消息?
当生产者在发布消息时,可能发生以下异常情况:
- 消息没发出去:网络故障或其它问题导致发布失败,中间件直接返回失败
- 不确定是否发布成功:网络问题导致发布超时,可能数据已发送成功,但读取响应结果超时了
如果是情况 1,消息根本没发出去,那么重新发一次就好了。
如果是情况 2,生产者没办法知道消息到底有没有发成功?所以,为了避免消息丢失,它也只能继续重试,直到发布成功为止。
生产者一般会设定一个最大重试次数,超过上限依旧失败,需要记录日志报警处理。
所以无论是 Redis 还是专业的队列中间件,生产者在这一点上都是可以保证消息不丢的。
2) 消费者会不会丢消息?
消费者在处理完消息后,必须「告知」队列中间件,队列中间件才会把标记已处理,否则仍旧把这些数据发给消费者。
这种方案需要消费者和中间件互相配合,才能保证消费者这一侧的消息不丢。
无论是 Redis 的 Stream,还是专业的队列中间件,例如 RabbitMQ、Kafka,其实都是这么做的。
所以,从这个角度来看,Redis 也是合格的。
3) 队列中间件会不会丢消息?
Redis 在以下 2 个场景下,都会导致数据丢失。
- AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
- 主从复制也是异步的,主从切换时,也存在丢失数据的可能(从库还未同步完成主库发来的数据,就被提成主库)
像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时,一般是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,以此保证消息的完整性。这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
也正因为如此,RabbitMQ、Kafka在设计时也更复杂。毕竟,它们是专门针对队列场景设计的。
但 Redis 的定位则不同,它的定位更多是当作缓存来用,它们两者在这个方面肯定是存在差异的。
4) 消息积压怎么办?
因为 Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。
所以,Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。
但 Kafka、RabbitMQ 这类消息队列就不一样了,它们的数据都会存储在磁盘上,磁盘的成本要比内存小得多,当消息积压时,无非就是多占用一些磁盘空间,相比于内存,在面对积压时也会更加「坦然」。
综上,我们可以看到,把 Redis 当作队列来使用时,始终面临的 2 个问题:
- Redis 本身可能会丢数据
- 面对消息积压,Redis 内存资源紧张
总结
「技术方案选型」
这篇文章所讲到的内容,都是以业务功能角度出发做决策的。
但这里的第二点,从技术资源角度出发,技术资源的角度是说,你所处的公司环境、技术资源能否匹配这些技术方案。
简单来讲,就是你所在的公司、团队,是否有匹配的资源能 hold 住这些技术方案。
我们都知道 Kafka、RabbitMQ 是非常专业的消息中间件,但它们的部署和运维,相比于 Redis 来说,也会更复杂一些。
如果你在一个大公司,公司本身就有优秀的运维团队,那么使用这些中间件肯定没问题,因为有足够优秀的人能 hold 住这些中间件,公司也会投入人力和时间在这个方向上。
所以,做技术选型不只是技术问题,还与人、团队、管理、组织结构有关。
本文参考多篇资料,详情可看下面的链接:
- https://redis.io/docs/latest/commands/
- https://blog.csdn.net/zhangchb/article/details/120507983
- https://redis.com/blog/redis-streams-a-practical-introduction/
- https://kafka.apache.org/documentation/
如果我的内容对你有帮助,请辛苦动动您的手指为我点赞,评论,收藏。感谢大家!!
