软件说明:
所有软件包下载地址:https://www.elastic.co/cn/downloads/past-releases
打开页面后选择对应的组件及版本即可!
所有软件包名称如下:

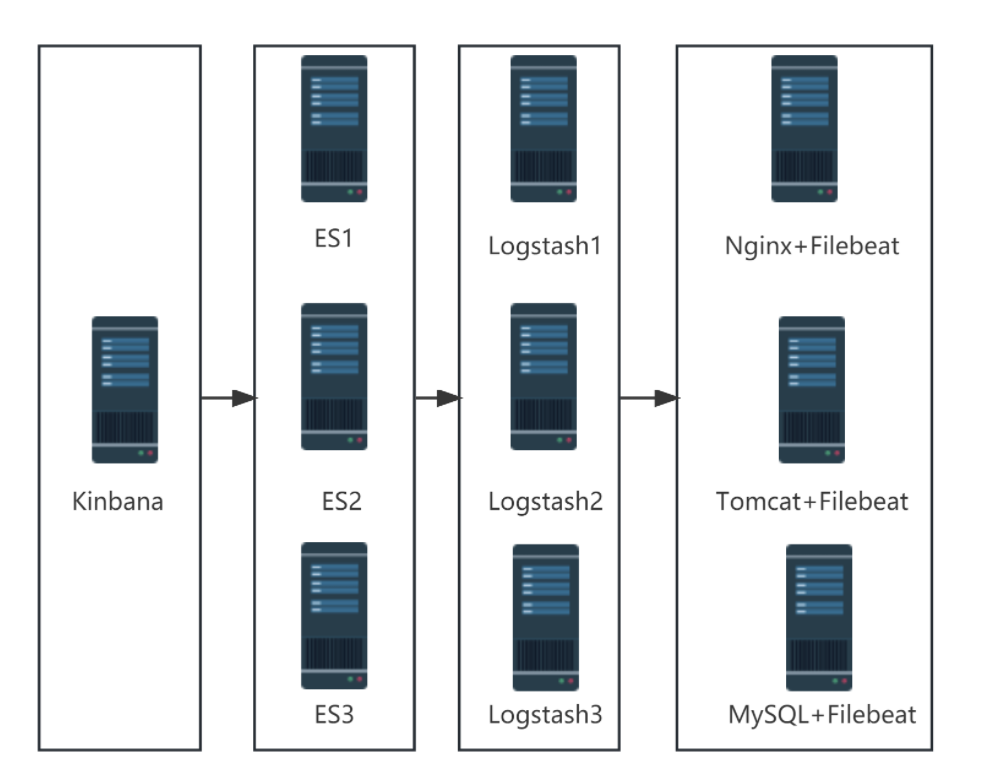
架构拓扑:
1、集群模式:
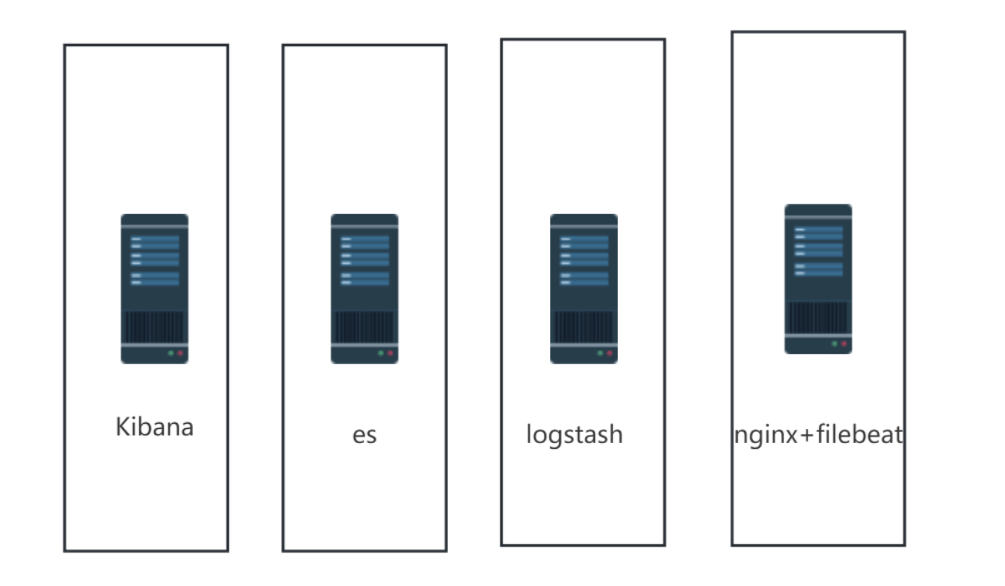
2、单机模式
架构规划:
1、集群模式
| 角色 | 主机名 | IP地址 |
|---|---|---|
| 图形展示 | kibana | 192.168.166.111 |
| 日志存储 | es1 | 192.168.158.6 |
| es2 | 192.168.166.113 | |
| es3 | 192.168.166.114 | |
| 日志收集分析 | lostash1 | 192.168.166.166 |
| lostash2 | 192.168.166.116 | |
| lostash3 | 192.168.166.117 | |
| 日志采集 | access、error | 192.168.166.118 |
2、单机模式
| 角色 | 主机名 | IP地址 |
|---|---|---|
| 图形展示 | kibana | 192.168.52. |
| 日志存储 | es | 192.168.52. |
| 日志收集分析 | lostash | 192.168.52. |
| 日志采集 | access、error | 192.168.52. |
一、配置准备
主机IP:192.168.52.202
1、关闭防火墙与安全上下文
cpp
systemctl disable --now firewalld
cpp
setenforce 0
cpp
yum install -y lrzsz2、安装elasticsearch、Kibana、logstash、filebeat
cpp
rpm -ivh kibana-7.1.1-x86_64.rpm
rpm -ivh elasticsearch-7.1.1-x86_64.rpm
rpm -ivh logstash-7.1.1.rpm
rpm -ivh filebeat-7.1.1-x86_64.rpm3、下载java,需要Java环境
cpp
yum -y install java-1.8.0-openjdk-devel.x86_64二、单机模式 ELK部署
1、elasticsearch配置
进入配置文件
cpp
vim /etc/elasticsearch/elasticsearch.yml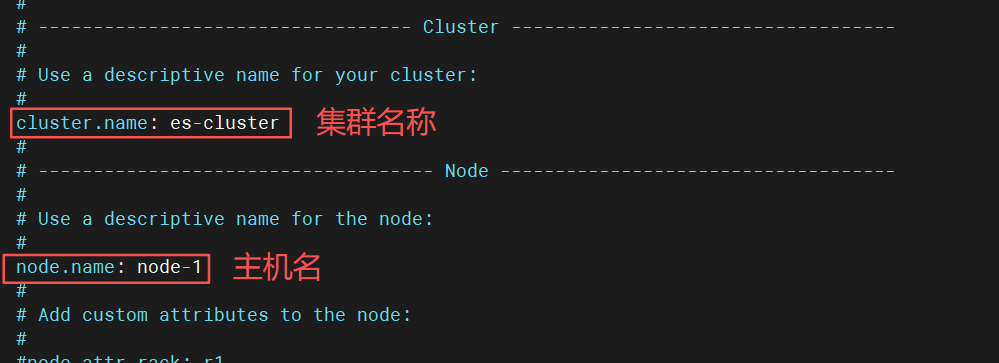
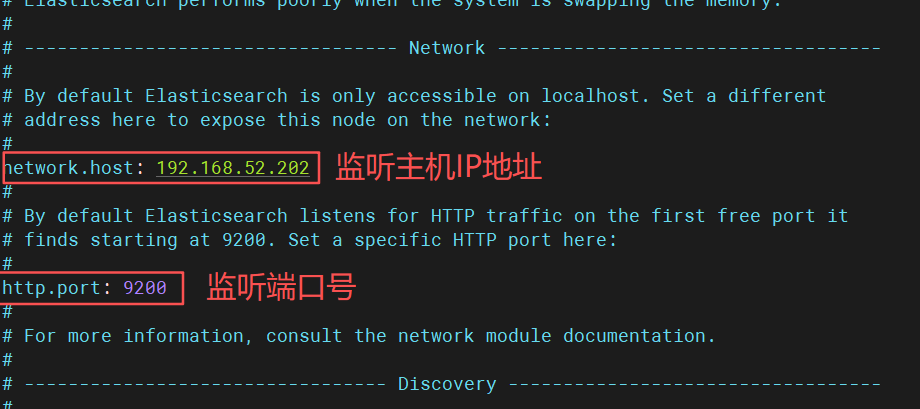
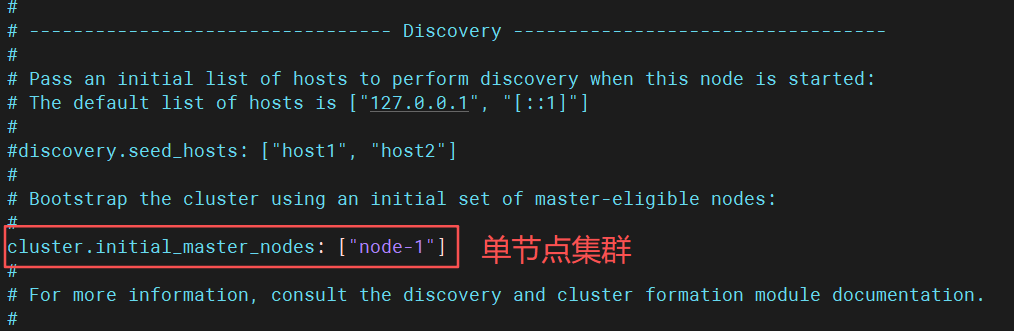
cpp
http.cors.enabled: true
http.cors.allow-origin: "*"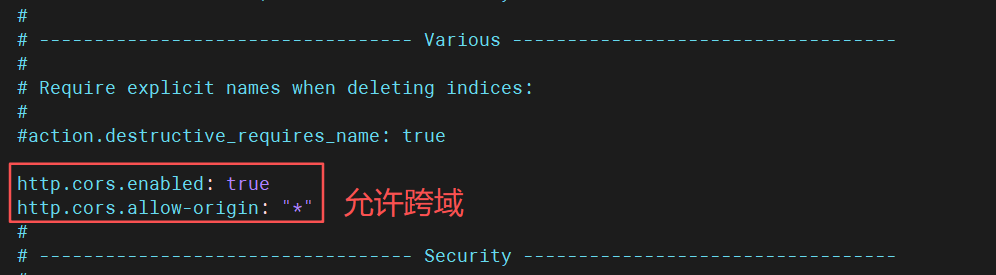
1.1、启动elasticsearch服务
cpp
systemctl start elasticsearch.service 查看启用状态
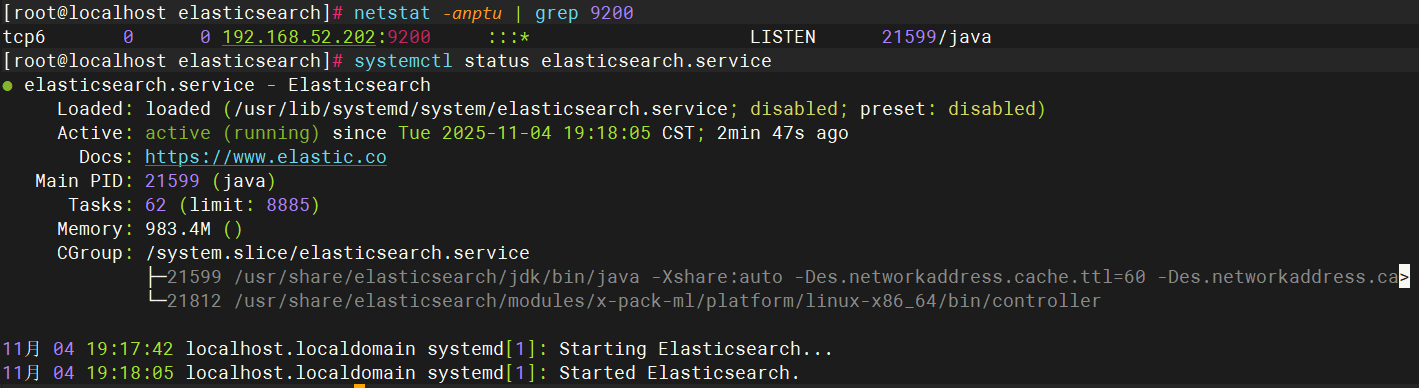
查看监听端口
 2、logstash部署
2、logstash部署
cpp
cd /etc/logstash/conf.d/
ls
vim pipline.conf
cpp
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["http://192.168.52.202:9200"]
index => "system-log-%{+YYYY.MM.dd}"
}
###日志进行标准输出,观察日志获取的过程###
stdout {
codec => rubydebug
}
}优化logstash命令
cpp
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/3、kibana部署
进入配置文件
cpp
vim /etc/kibana/kibana.yml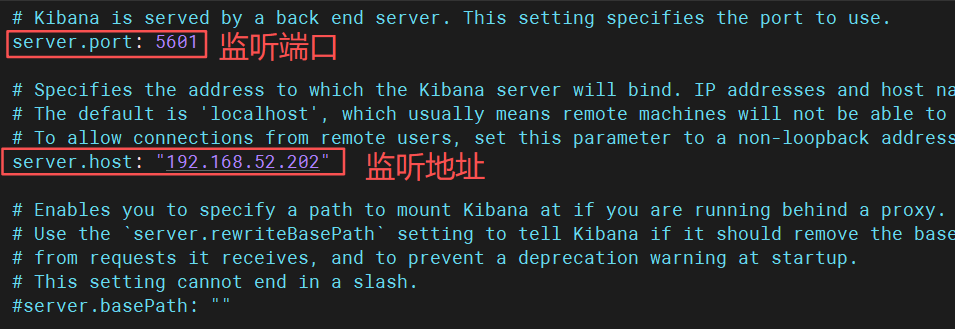
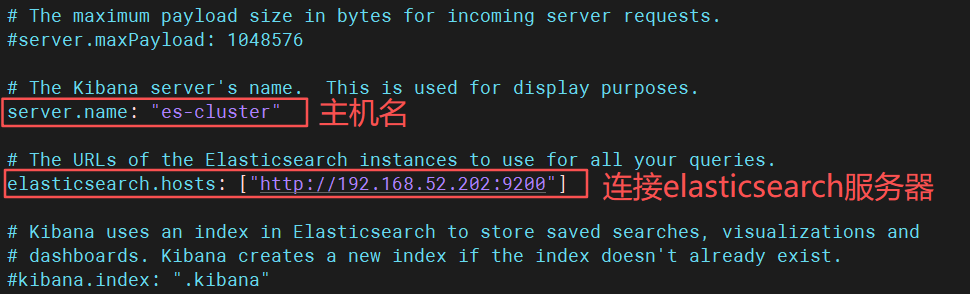


3.1、启动服务kebana服务
cpp
systemctl start kibana.service查看状态
cpp
netstat -anput | grep node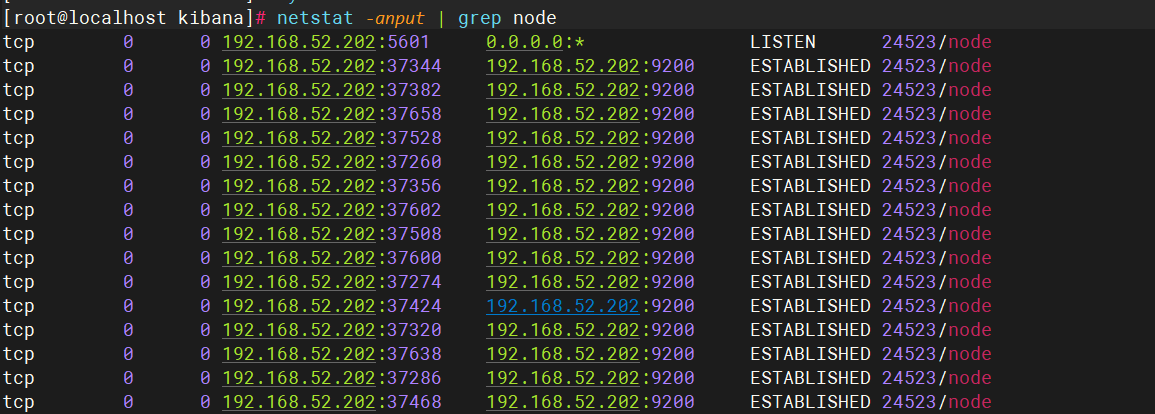
4、验证
cpp
[root@localhost elasticsearch]# logstash -e 'input{ stdin{} }output { stdout{} }'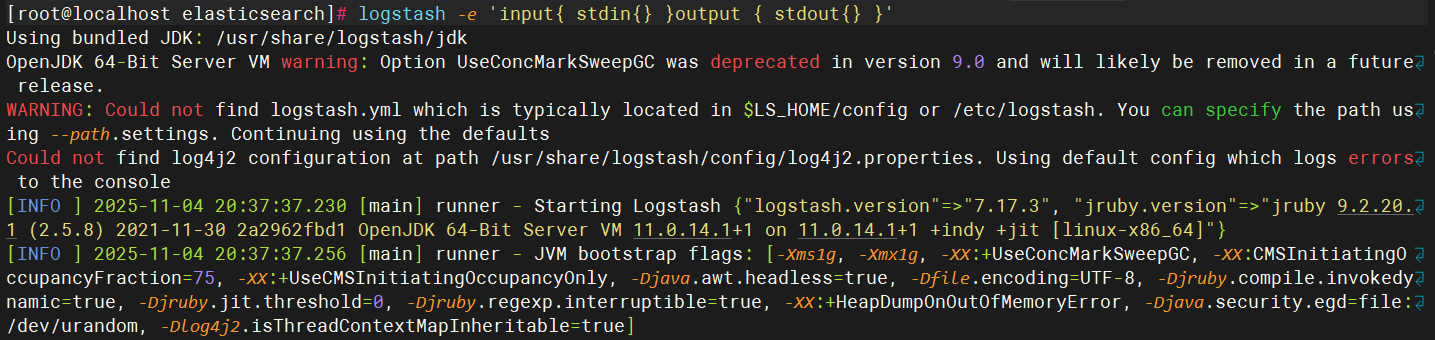
cpp
[root@localhost elasticsearch]# logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'5、网页验证
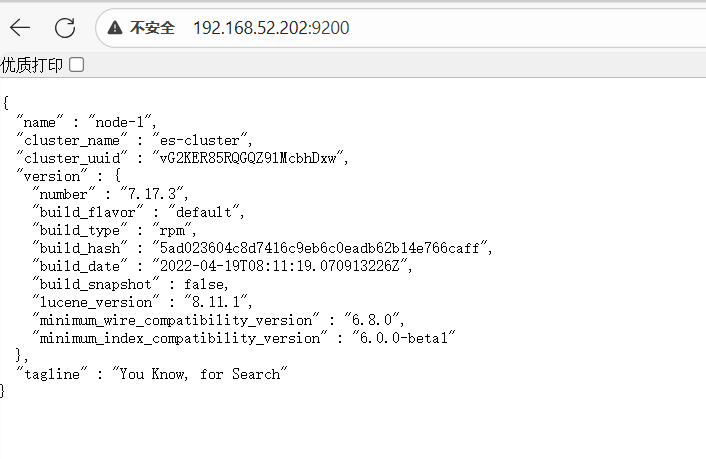
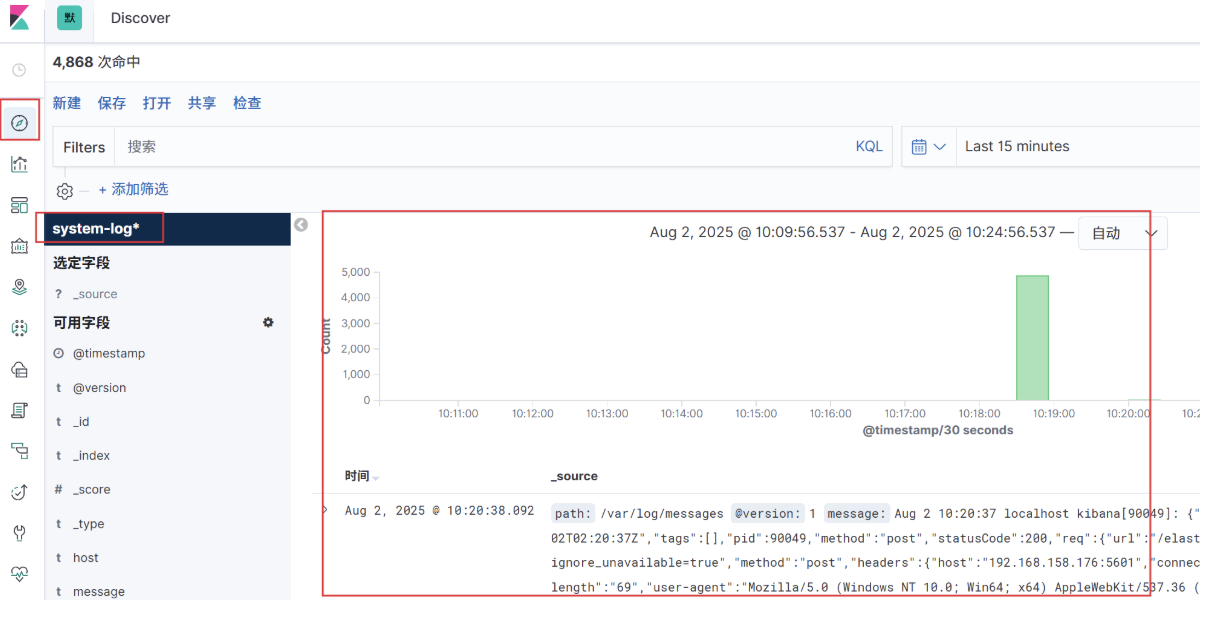
6、生成表格
cpp
[root@elk elasticsearch]# logstash -f /etc/logstash/conf.d/pipline.conf