【实战:倒计时 + 进度条】目录
- 前言:
- ---------------倒计时---------------
-
- [1. 回车和换行有什么区别?](#1. 回车和换行有什么区别?)
- [2. 什么是行缓冲区?](#2. 什么是行缓冲区?)
- [3. 行缓冲的实际案例你见过吗?](#3. 行缓冲的实际案例你见过吗?)
- [4. 如何编写一个倒计时的程序?](#4. 如何编写一个倒计时的程序?)
- ---------------进度条---------------
-
- 头文件:process.h
- 源文件:process.c
- [主文件: main.c](#主文件: main.c)
- Makefile文件:
- 运行结果:
往期《Linux系统编程》回顾:/------------ 入门基础 ------------/
【Linux的前世今生】
【Linux的环境搭建】
【Linux基础 理论+命令】(上)
【Linux基础 理论+命令】(下)
【权限管理】/------------ 开发工具 ------------/
【软件包管理器 + 代码编辑器】
【编译器 + 自动化构建器】
【版本控制器 + 调试器】
前言:
hi~ ,小伙伴们大家好啊!(*๓´╰╯`๓)♡
今天是阳历 11 月 7 日🍂、阴历九月十八,同时也是二十四节气中的立冬~❄️
立冬是二十四节气的第 19 个节气,更是冬季的第一个节气,标志着冬天正式拉开序幕。
"立" 是开始的意思,"冬" 代表终了,意味着万物开始收藏蛰伏,躲避寒冷啦~🐿️🐾
经过之前的系统学习,咱们已经掌握了 Linux 里关键的开发工具,现在都能在 Linux 系统中进行简单编程了吧!🖥️鼠鼠猜大家肯定迫不及待想写点有趣又实用的小项目,所以今天就带来两个超接地气的实战案例 ------【实战:倒计时 + 进度条】 ٩(ˊᗜˋ)و✧*。
---------------倒计时---------------
1. 回车和换行有什么区别?

回车与换行的基础概念:
- 回车(\r) :作用是让
"打字位置"回到==当前行的开头==(类似老式打字机上,把打字的 "小车" 拉回行首的动作)- 换行(\n) :作用是让
"纸张"向下移动一行(类似老式打字机上,把纸张向上滚动一格,使后续文字能在下一行显示的动作)
对于老式打字机,当打完一行文字后,要开始新的一行,需要两个动作:
- 先回车:把打字的 "字车"(承载打字键的部件)拉回行首,这样下一个字符会从行的最开头开始打
- 再换行:把纸张向上滚动一格,让字车能在 "新的一行" 打字
如果只回车不换行:后续打字会覆盖当前行已有的内容
如果只换行不回车:后续打字会从当前字符的右侧继续(跑到下一行的中间位置)
只有两者结合,才能精准开始 "新的一行、行首" 的打字操作。
不同操作系统对 "换行" 的表示有差异,但核心是 "回车 + 换行" 的逻辑演变:
- Windows 系统 :
用 \r\n(回车 + 换行)表示 "换行",严格还原了老式打字机 "回车→换行" 的两步操作- Linux/Unix、macOS(现代)系统 :
用 \n(仅换行)表示 "换行",因为系统内部会自动处理 "回到行首" 的逻辑,无需显式用\r我们日常使用的键盘上的 Enter 键,功能是 "回车 + 换行" 的组合操作 ------ 按下 Enter 后,既会让光标回到行首,又会让内容跳到下一行,相当于同时触发了
\r和\n
2. 什么是行缓冲区?
行缓冲区是计算机文件输入输出(I/O)操作中,缓冲机制的一种类型,它与数据的读写方式以及何时真正写入存储设备或从存储设备读取数据密切相关。
行缓冲区:是在程序执行 I/O 操作时,在内存中开辟的一块区域,用于临时存储数据。
- 当向输出设备(如:显示器、文件等)写入数据时,数据会先被放入行缓冲区,而不是立即写入目标设备
- 当从输入设备读取数据时,数据会一次性从设备读取到缓冲区,然后程序再从缓冲区获取数据
输出场景:
- 以向控制台打印文本为例,当程序执行
printf这样的输出函数时,数据会先写入行缓冲区- 当遇到以下几种情况时,行缓冲区中的数据才会被真正输出到目标设备(比如显示器):
- 遇到换行符(\n),比如执行
printf("Hello\nWorld");,当输出到\n时,会将 "Hello" 连同换行符一起从行缓冲区刷新到显示器上显示出来。- 行缓冲区已满,达到了其预先设定的容量上限,此时缓冲区中的数据会被刷新输出。
- 程序正常结束,在程序终止前,系统会自动刷新所有缓冲区,确保数据都能输出到相应设备。
- 调用了 fflush 函数,主动刷新缓冲区,例如:
fflush(stdout);可以强制将标准输出流(通常对应控制台输出)的行缓冲区中的数据立即输出。
输入场景:
- 从键盘读取数据时,当用户按下回车键,输入的数据会被放入行缓冲区,程序中的输入函数(如:
scanf、fgets等)会从行缓冲区读取数据
与其他缓冲区类型对比:
- 全缓冲区 :通常用于文件 I/O,它会在缓冲区满或者程序显式调用
fflush函数、程序结束时,才将缓冲区中的数据写入文件。
- 比如:在写入一个大文件时,数据会不断填充全缓冲区,直到缓冲区被填满或者手动刷新,才真正将数据写入磁盘上的文件
- 无缓冲区 :数据不经过缓冲区,直接写入目标设备或从设备读取。
- 例如:在使用
stderr(标准错误输出流)时,它通常是无缓冲的,这样错误信息能立即显示给用户,而不会因为缓冲区的存在导致延迟显示,影响问题排查
3. 行缓冲的实际案例你见过吗?
c
/*--------------------------- 第一种情况 ---------------------------*/
#include <stdio.h>
int main()
{
printf("hello world!\n");
sleep(3);
return 0;
}
/*--------------------------- 第二种情况 ---------------------------*/
#include <stdio.h>
int main()
{
printf("hello world!");
sleep(3);
return 0;
}
/*--------------------------- 第三种情况 ---------------------------*/
#include <stdio.h>
int main()
{
printf("hello world!");
fflush(stdout);
sleep(3);
return 0;
}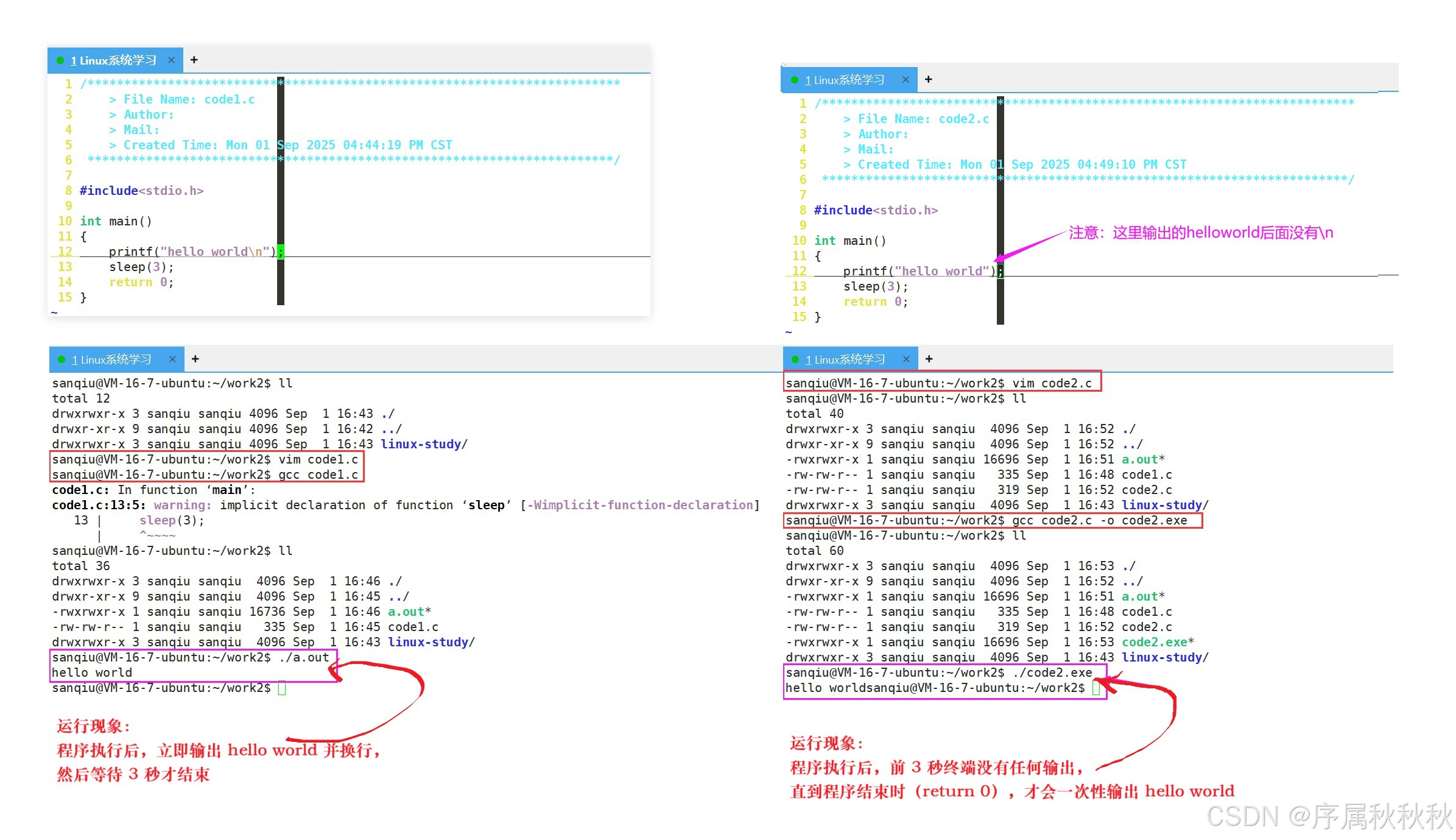
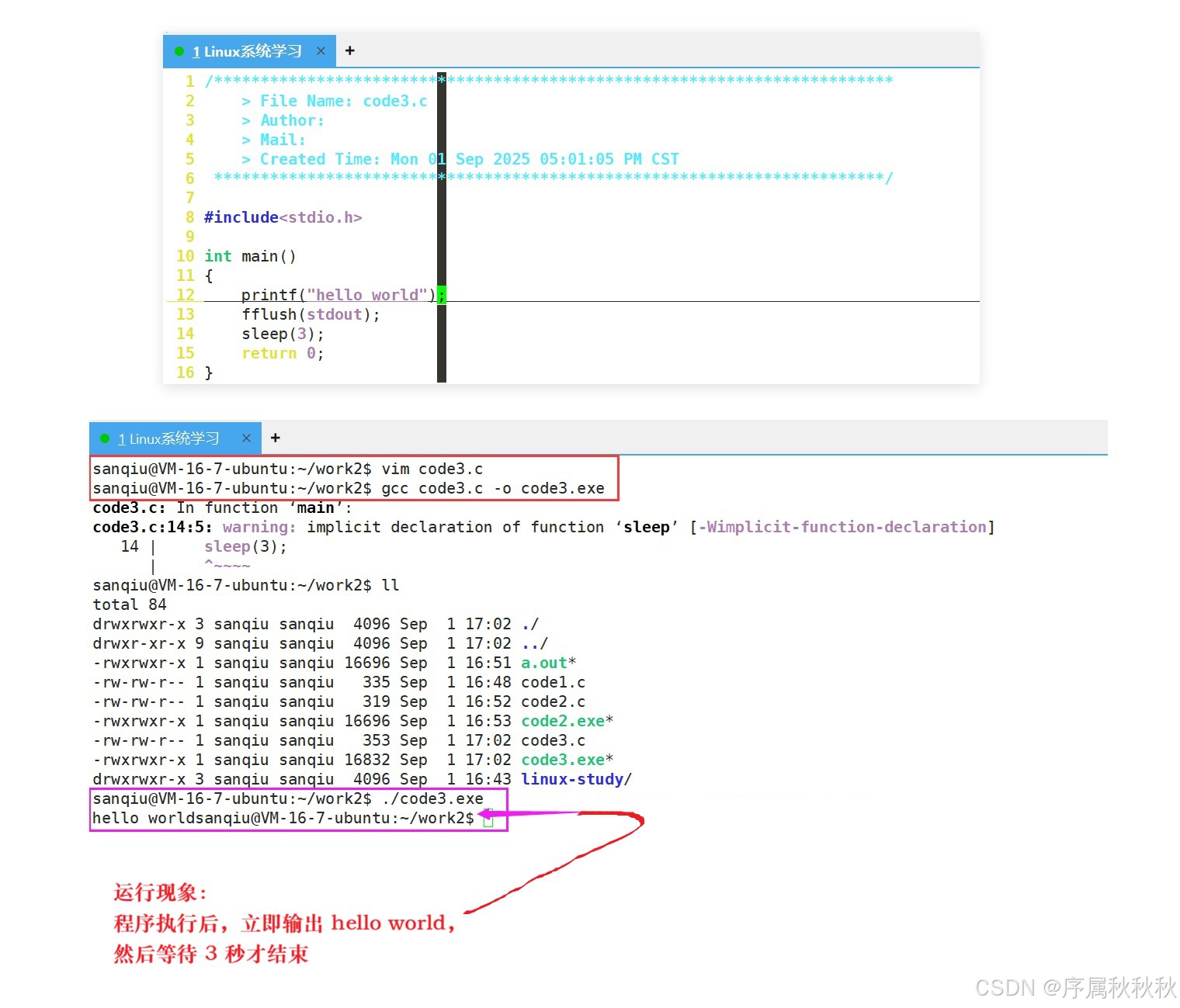
我们可以结合 行缓冲区(
stdout的缓冲机制) 和代码运行现象,把内容梳理得更通顺、易理解:一、代码与行缓冲区的关联
printf 输出的内容会先进入标准输出(stdout)的行缓冲区,只有满足 "触发条件" 时,缓冲区里的内容才会真正显示到终端上。
二、分场景解释代码现象
场景 1:
printf("hello world\n"); sleep(3);(对应code1.c)
运行现象 :程序执行后,立即输出
hello world并换行,然后等待 3 秒才结束原因解释:
printf输出的字符串包含\n,触发了行缓冲区的 "换行刷新" 机制,所以内容会立即显示- 之后的
sleep(3)只是让程序暂停,不影响已经输出的内容
场景 2:
printf("hello world"); sleep(3);(对应code2.c)
运行现象 :程序执行后,前 3 秒终端没有任何输出 ,直到程序结束时(
return 0),才会一次性输出hello world原因解释:
printf输出的字符串没有\n,行缓冲区不会立即刷新- 而
sleep(3)期间程序处于休眠,也没有触发刷新- 直到程序正常退出时,系统自动刷新行缓冲区,内容才会显示
场景 3 :
printf("hello world"); fflush(stdout); sleep(3);(对应code3.c)
运行现象:程序执行后,立即输出
hello world,然后等待 3 秒才结束原因解释:
printf输出后,手动调用fflush(stdout)强制刷新了行缓冲区,所以内容会立即显示- 之后的
sleep(3)只是程序暂停,不影响已经输出的内容
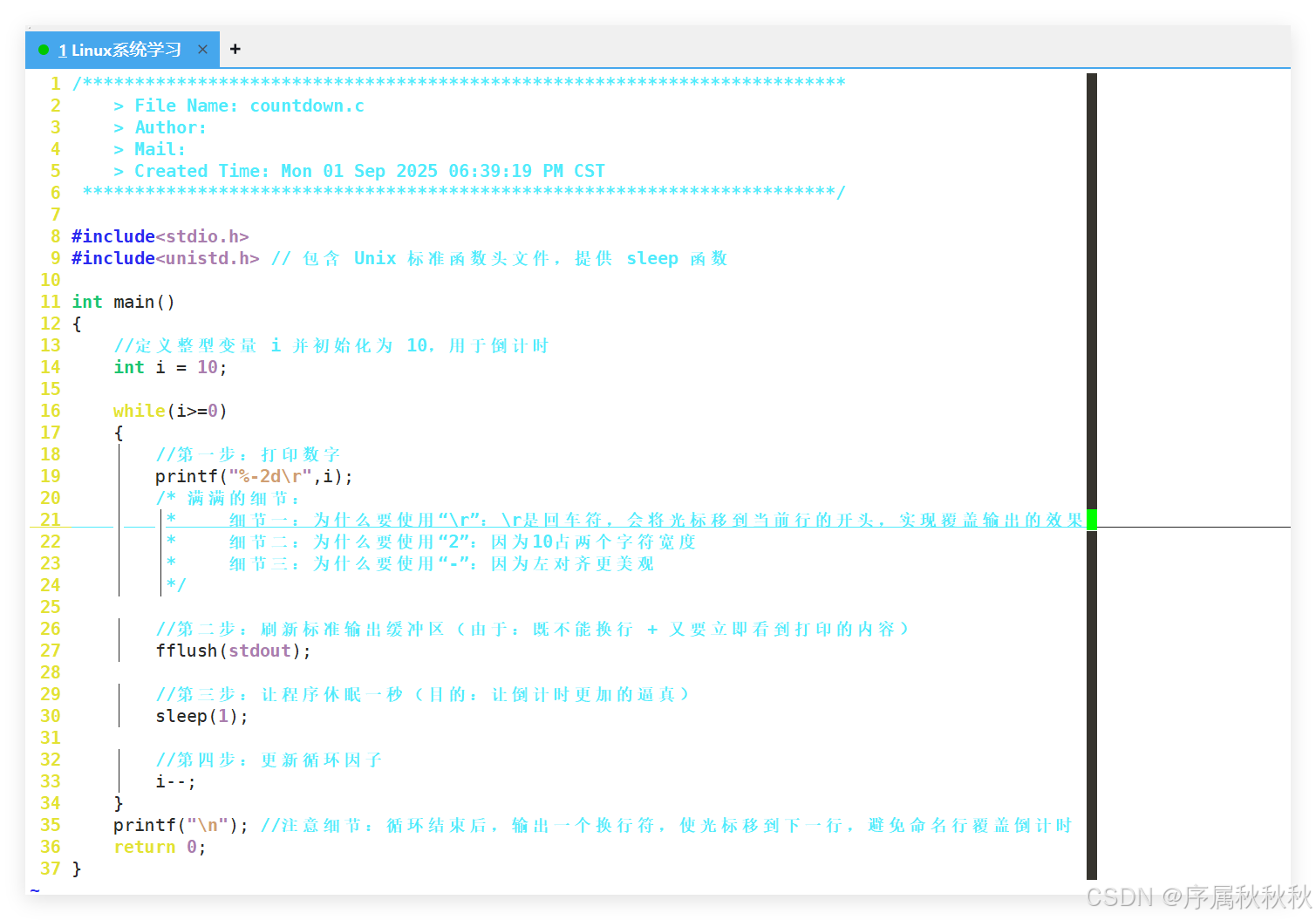
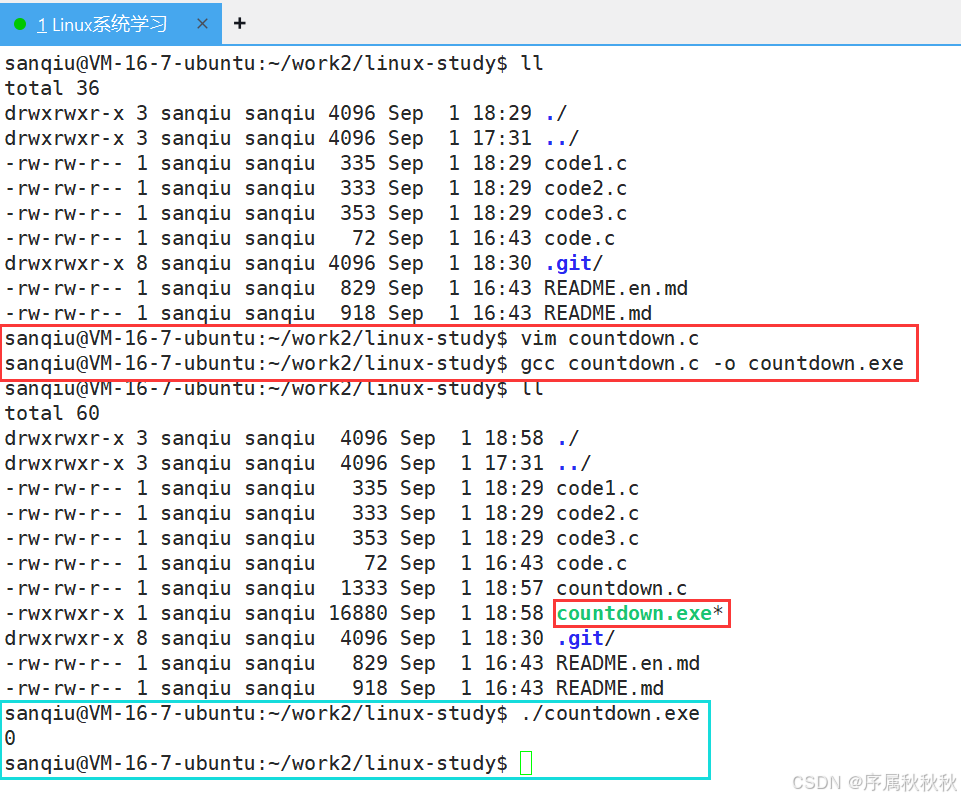
4. 如何编写一个倒计时的程序?
c
#include<stdio.h>
#include<unistd.h> // 包含 Unix 标准函数头文件,提供 sleep 函数
int main()
{
// 定义整型变量 i 并初始化为 10,用于倒计时
int i = 10;
while(i>=0)
{
// 第一步:打印数字
printf("%-2d\r",i);
/* 满满的细节:
* 细节一:为什么要使用 "\r":\r是回车符,会将光标移到当前行的开头,实现覆盖输出的效果
* 细节二:为什么要使用 "2":因为10占两个字符宽度
* 细节三:为什么要使用 "-":因为左对齐更美观
*/
// 第二步:刷新标准输出缓冲区(由于:既不能换行 + 又要立即看到打印的内容)
fflush(stdout);
// 第三步:让程序休眠一秒(目的:让倒计时更加的逼真)
sleep(1);
// 第四步:更新循环因子
i--;
}
printf("\n"); // 注意细节:循环结束后,输出一个换行符,使光标移到下一行,避免命名行覆盖倒计时
return 0;
}
---------------进度条---------------
头文件:process.h
c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
//1.声明 version1 版本的进度条函数
//2.声明 version2 版本的进度条函数 ---> 区别之处:接收"总数据量"和"当前已处理数据量参数"
void process_v1();
void process_v2(double total, double current);源文件:process.c
c
#include "process.h"
/*------------------------宏定义------------------------*/
//1.定义进度条填充的字符样式
#define STYLE '=' //注意:STYLE是字符,所以=需要加上单引号
//2.定义缓冲区大小
#define NUM 101 ///注意:+1 是为了容纳字符串结束符 '\0'
/*------------------------version1版本的进度条------------------------*/
//功能:简单的固定次数进度条实现函数
void process_v1()
{
/*----------------准备阶段----------------*/
//1.用于存储进度条字符的数组
char buffer[NUM];
//2.将数组中的所有字节初始化为 0
memset(buffer, 0, sizeof(buffer));
//3.定义进度条旋转的指示字符数组,模拟进度条的动态效果
const char* lable = "|/-\\"; //细节:由于单独一个'\'是转移字符,所以想要'反斜杠\'需要加两个\
//4.获取指示字符数组的长度
int len = strlen(lable);
/*----------------打印阶段----------------*/
int cnt = 0;
while (cnt <= 100)
{
//第一步:打印进度条
printf("[%-100s][%d%%][%c]\r", buffer, cnt, lable[cnt % len]);
/* 细节分析:
* %-100s:表示左对齐,占 100 个字符宽度的字符串(进度条主体)---> 值得细细品味
* [%d%%]:表示当前进度的百分比数值
* [%c]: 表示当前旋转的指示字符
* \r: 是回车符,将光标移到当前行开头,实现覆盖输出,让进度条在同一行更新
*/
//第二步:刷新标准输出缓冲区
fflush(stdout);
//多加一步:向缓冲区中添加一个进度条样式字符
buffer[cnt] = STYLE;
//第三步:让程序休眠:50000 微秒(0.05 秒)
usleep(50000);
//第四步:更新循环因子
cnt++;
}
printf("\n"); //小细节:进度条完成后,输出一个换行符,使光标移到下一行
}
/*------------------------version2版本的进度条------------------------*/
void process_v2(double total, double current)
{
/*----------------准备阶段----------------*/
//1.用于存储进度条字符的数组
char buffer[NUM];
//2.将数组中的所有字节初始化为 0
memset(buffer, 0, sizeof(buffer));
//3.定义进度条旋转的指示字符数组,模拟进度条的动态效果
const char* lable = "|/-\\"; //细节:由于单独一个'\'是转移字符,所以想要'反斜杠\'需要加两个\
//4.获取指示字符数组的长度
int len = strlen(lable);
/*----------------准备阶段----------------*/
//1.定义静态变量 ---> 用于记录旋转指示字符的位置,程序运行过程中保持值不变(跨函数调用)
static int cnt = 0;
//2.旋转指示字符的位置取模,实现循环旋转效果
cnt = cnt % len;
//3.计算当前进度的百分比 ---> 乘以 100 后取整
int num = (int)(current * 100 / total);
//4.根据进度百分比向缓冲区填充进度条样式字符
for (int i = 0; i < num; i++)
{
buffer[i] = STYLE;
}
//5.计算进度的比例(0 到 1 之间的小数)
double rate = current / total;
/*----------------打印阶段----------------*/
//第一步:打印进度条
printf("[%-100s][%.1f%%][%c]\r", buffer, rate * 100, lable[cnt]);
/* 细节分析:
* %-100s:进度条主体
* [%.1f%%]:进度百分比,保留 1 位小数
* [%c]:旋转的指示字符
* \r:回车符,实现覆盖输出
*/
//第二步:刷新标准输出缓冲区
fflush(stdout);
//第三步:更新循环因子 ---> 旋转指示字符的位置加 1,为下次旋转做准备
cnt++;
}主文件: main.c
c
#include "process.h"
/*--------------------------设置初始状态的信息--------------------------*/
//1.定义总数据量(注:单位可自行假设,这里为 5.0M)
double total = 5.0;
//2.定义每次下载的数据量(注:单位可自行假设,这里为 1.0M)
double speed = 1.0;
/*--------------------------模拟下载过程的函数--------------------------*/
void Download()
{
//1.记录当前已下载的数据量
double current = 0;
//2.当已下载数据量小于总数据量时继续循环
while (current < total)
{
//2.1:调用进度条函数
process_v1(); //调用 version1 版本的函数
//process_v2(total, current); //调用 version2 版本的函数
//2.2:模拟下载数据的耗时休眠 3000 微秒
usleep(3000);
//2.3:已下载数据量增加 speed
current += speed;
}
//针对于 version2 版本:循环结束后,current 已经等于 total,额外调用一次进度条函数,确保 100% 的进度被显示出来
process_v2(total, current); //注意:这是个细节注意一下
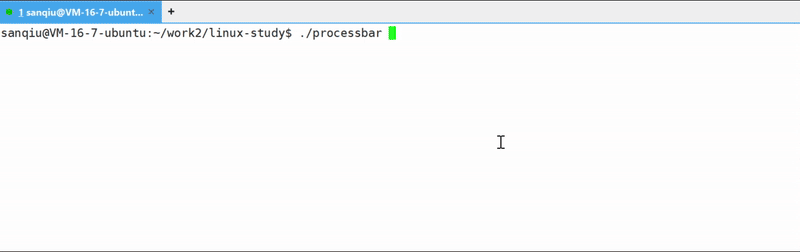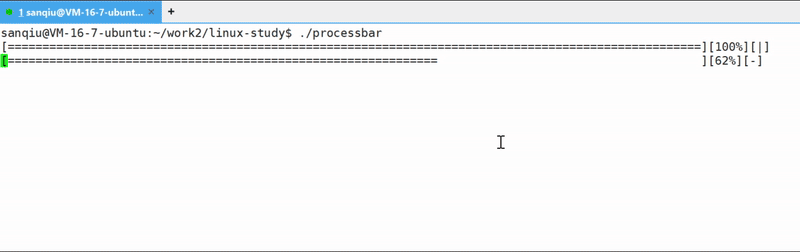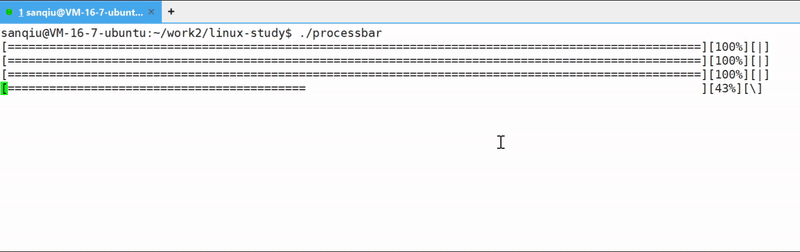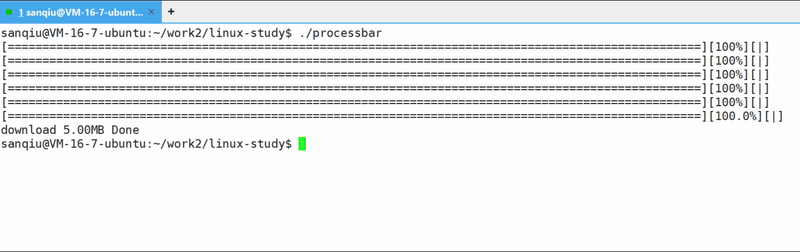
//3.下载完成后,输出提示信息,显示最终的已下载数据量
printf("\ndownload %.2lfMB Done\n", current);
}
/*--------------------------程序入口的主函数--------------------------*/
int main()
{
Download();
return 0;
}Makefile文件:
makefile
#---------------------------定义变量---------------------------#
#1.定义"源文件"变量
SRC = $(wildcard *.c) #将当前目录下的所有的以.c为结尾的文件都作为源文件
#2.定义"目标文件"变量
OBJ = $(SRC:.c=.o) #将源文件的后缀 .c 替换为 .o,得到目标文件列表
#3.定义"可执行文件"变量
BIN = processbar
#---------------------------生成可执行文件---------------------------#
$(BIN):$(OBJ)
gcc -o $@ $^ # 编译生成可执行文件,$@ 表示目标文件(processbar),$^ 表示所有依赖文件(所有 .o 文件)
#---------------------------模式规则---------------------------#
%.o:%.c
gcc -c $< # 编译源文件生成目标文件,$< 表示第一个依赖文件(当前的 .c 文件)
#---------------------------清理中间文件和目标文件---------------------------#
.PHONY:clean
clean: #注意这个clean:是不用Tab键来缩进的
rm -f $(OBJ) $(BIN)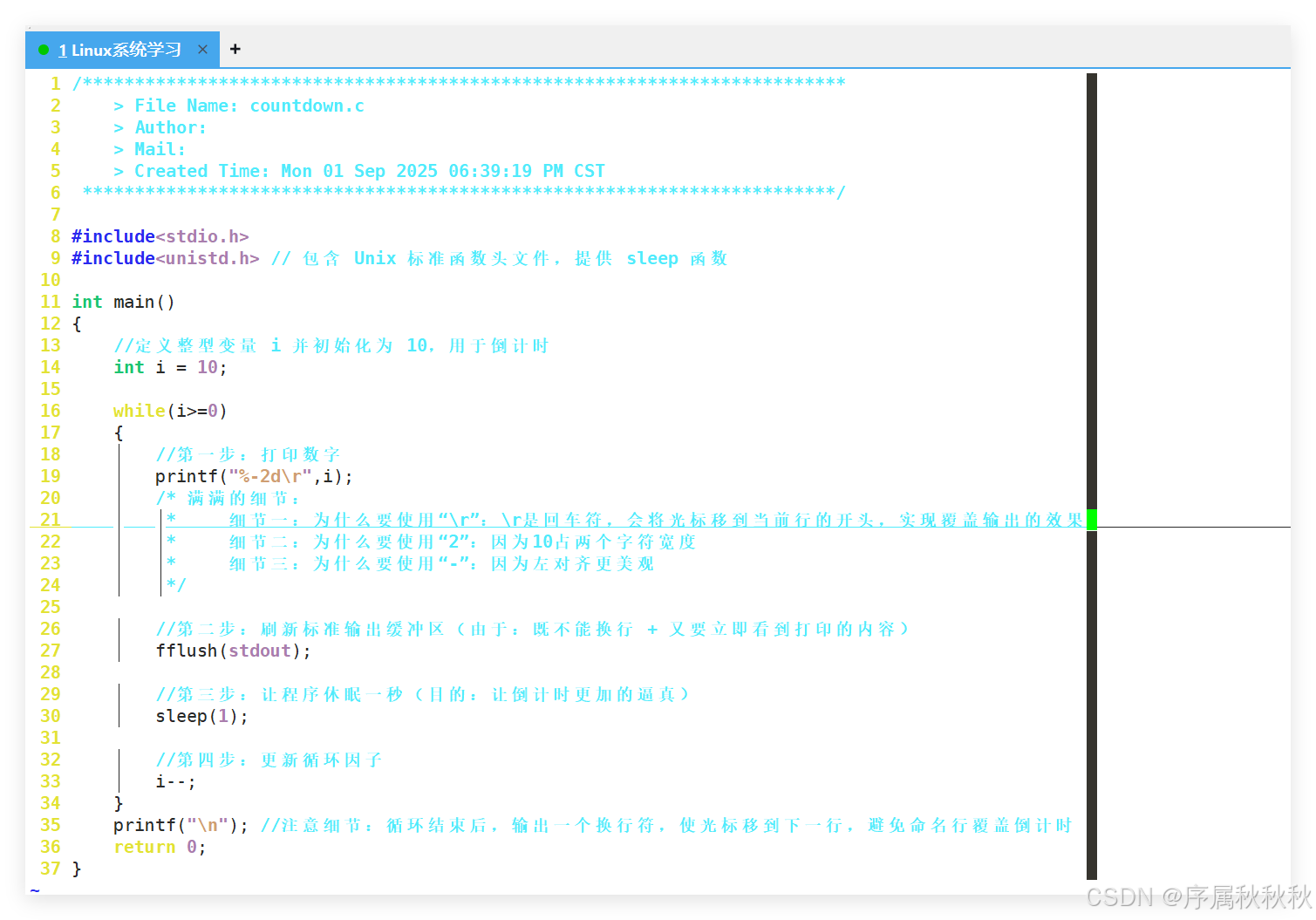
运行结果: