前言:
在上一讲,我们掌握了指针的基础概念、类型意义与运算规则,而C语言中指针的核心应用场景,离不开与数组的结合。这一讲我们将聚焦指针与数组的关系 ,从数组名的本质入手,拆解数组传参的底层逻辑,再延伸到二级指针、指针数组等进阶知识点,最终通过实战案例(如冒泡排序、模拟二维数组)帮你打通"指针+数组"的应用链路。
一、数组名的理解
很多初学者会误以为"数组名就是首元素地址"------这个说法不完全错,但有两个关键例外。理解数组名的真实含义,是掌握"指针操作数组"的前提。
1.1 数组名的默认含义
先看一个简单实验:打印数组名与首元素地址,观察结果:
c
#include <stdio.h>
int main() {
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
// 打印首元素地址 &arr[0]
printf("&arr[0] = %p\n", &arr[0]);
// 打印数组名 arr
printf("arr = %p\n", arr);
return 0;
}输出结果(地址值可能不同,但两者必相等):
&arr[0] = 004FF9CC
arr = 004FF9CC这说明:默认情况下,数组名等价于数组首元素的地址 。我们可以直接将数组名赋值给指针变量(如int* p = arr),本质就是让指针指向数组首元素。
1.2 数组名的两个"例外"
当数组名出现在以下两种场景时,它不再是"首元素地址",而是代表整个数组:
例外1:sizeof(数组名)------计算整个数组的大小
如果直接对数组名使用sizeof,得到的是"整个数组占用的字节数",而非指针大小(4/8字节)。例如:
c
#include <stdio.h>
int main() {
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
// int占4字节,10个元素共40字节
printf("sizeof(arr) = %zd\n", sizeof(arr));
return 0;
}输出结果 :sizeof(arr) = 40(若int为4字节)。
例外2:&数组名------取出整个数组的地址
&arr(取数组名的地址)得到的是"整个数组的地址",它与"首元素地址"的值相同,但意义完全不同。我们通过"地址+1"的差异来验证:
c
#include <stdio.h>
int main() {
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
printf("&arr[0] = %p\n", &arr[0]); // 首元素地址
printf("&arr[0]+1 = %p\n", &arr[0]+1); // 首元素地址+1(跳1个int)
printf("arr = %p\n", arr); // 等价于首元素地址
printf("arr+1 = %p\n", arr+1); // 首元素地址+1(跳1个int)
printf("&arr = %p\n", &arr); // 整个数组的地址(值与首元素地址相同)
printf("&arr+1 = %p\n", &arr+1); // 整个数组的地址+1(跳整个数组)
return 0;
}输出结果分析 (假设首地址为0077F820):
| 表达式 | 地址值 | 地址差原因 |
|---|---|---|
| &arr0 | 0077F820 |
首元素地址 |
| &arr0+1 | 0077F824 |
跳1个int(4字节) |
| arr | 0077F820 |
等价于首元素地址 |
| arr+1 | 0077F824 |
跳1个int(4字节) |
| &arr | 0077F820 |
整个数组的地址(值相同) |
| &arr+1 | 0077F848 |
跳整个数组(10×4=40字节) |
关键结论:
arr和&arr[0]是"首元素地址",+1跳过1个元素;&arr是"整个数组地址",+1跳过整个数组(大小由数组长度决定)。
二、使用指针访问数组
既然数组名默认是首元素地址,我们就可以用指针灵活访问数组元素,甚至实现与arr[i]完全等价的操作。
2.1 指针访问数组的核心等价关系
C语言编译器在处理数组元素访问时,会将arr[i]自动转换为*(arr + i)------本质是"首元素地址 + 偏移量i,再解引用"。
同理,若定义指针int* p = arr(p指向首元素),则:
p[i]等价于*(p + i)arr[i]等价于*(arr + i)- 甚至
i[arr]也等价于*(i + arr)(语法允许,但不推荐,可读性差)
用代码验证这一关系:
c
#include <stdio.h>
int main() {
int arr[5] = {10,20,30,40,50};
int* p = arr; // p指向数组首元素
// 以下四种访问方式完全等价,均输出30(第3个元素,下标2)
printf("arr[2] = %d\n", arr[2]);
printf("*(arr+2) = %d\n", *(arr+2));
printf("p[2] = %d\n", p[2]);
printf("*(p+2) = %d\n", *(p+2));
return 0;
}输出结果 :四种方式均输出30。
2.2 用指针完成数组的输入与输出
利用指针的灵活性,我们可以脱离数组下标,直接通过指针偏移实现数组的输入和输出:
c
#include <stdio.h>
int main() {
int arr[10] = {0};
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr; // 指针指向数组首元素
// 1. 用指针输入数组元素
printf("请输入10个整数:\n");
for (int i = 0; i < sz; i++) {
// p+i 是第i个元素的地址,等价于 &arr[i]
scanf("%d", p + i);
}
// 2. 用指针输出数组元素
printf("数组元素为:\n");
for (int i = 0; i < sz; i++) {
// *(p+i) 是第i个元素的值,等价于 arr[i]
printf("%d ", *(p + i));
}
return 0;
}逻辑说明 :p+i计算第i个元素的地址(偏移i个int大小),scanf通过地址写入值,printf通过解引用读取值,完全替代下标操作。
三、一维数组传参的本质
很多初学者会疑惑:"为什么数组传给函数后,在函数内用sizeof求不出数组大小?"答案藏在数组传参的底层本质里。
先看一个反例:尝试在函数内计算数组元素个数,结果会出乎我们意料:
c
#include <stdio.h>
// 函数参数为数组形式
void test(int arr[]) {
// 期望计算数组大小,实际得到的是指针大小(4或8字节)
int sz2 = sizeof(arr) / sizeof(arr[0]);
printf("函数内 sz2 = %d\n", sz2);
}
int main() {
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
// 外部计算数组大小,正确得到10
int sz1 = sizeof(arr) / sizeof(arr[0]);
printf("函数外 sz1 = %d\n", sz1);
test(arr); // 数组传参
return 0;
}输出结果:
函数外 sz1 = 10
函数内 sz2 = 1 ( 32位平台:4/4=1;64位平台:8/4=2)
为什么会出现这种情况呢?原因很简单:一维数组传参时,传递的不是整个数组,而是数组首元素的地址 。函数形参列表中的int arr[]只是"语法糖"------编译器会自动将其解析为int* arr(指针变量)。
也就是说,以下两种函数声明完全等价:
c
// 等价写法1:数组形式(语法糖)
void test(int arr[]);
// 等价写法2:指针形式(本质)
void test(int* arr); 因此,函数内的sizeof(arr)计算的是"指针变量的大小 "(32位4字节,64位8字节),而非数组大小。这也意味着:函数内无法通过形参获取数组长度,必须单独传递数组大小sz。
正确的数组传参示例
修正上述代码,通过单独传递sz实现数组处理:
c
#include <stdio.h>
// 形参:指针(接收首元素地址) + sz(数组大小)
void print_arr(int* arr, int sz) {
for (int i = 0; i < sz; i++) {
printf("%d ", *(arr + i));
}
}
int main() {
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
print_arr(arr, sz); // 传递首元素地址和大小
return 0;
}输出结果:(正确打印数组)
1 2 3 4 5 6 7 8 9 10
四、冒泡排序
冒泡排序是经典的排序算法,核心思想是"两两相邻元素比较,逆序则交换"。结合指针操作数组,我们可以高效实现冒泡排序,并优化其性能。
基础版冒泡排序
思路:
- 外层循环控制"排序趟数":
n个元素需要n-1趟(每趟确定1个最大值); - 内层循环控制"每趟比较次数":第
i趟需要比较n-i-1次(已确定的最大值无需再比较); - 用指针访问数组元素,逆序则交换。
代码实现:
c
#include <stdio.h>
// 冒泡排序:升序排列
void bubble_sort(int* arr, int sz) {
// 1. 外层循环:控制趟数(sz-1趟)
for (int i = 0; i < sz - 1; i++) {
// 2. 内层循环:控制每趟比较次数(sz-i-1次)
for (int j = 0; j < sz - i - 1; j++) {
// 指针访问:arr[j] 等价于 *(arr+j)
if (*(arr + j) > *(arr + j + 1)) {
// 交换两个元素
int tmp = *(arr + j);
*(arr + j) = *(arr + j + 1);
*(arr + j + 1) = tmp;
}
}
}
}
int main() {
int arr[] = {3,1,7,5,8,9,0,2,4,6};
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz); // 排序
// 打印排序后数组
for (int i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}输出结果:
0 1 2 3 4 5 6 7 8 9
优化版冒泡排序(加上了提前终止)
基础版存在冗余:若某一趟未发生任何交换,说明数组已有序,无需继续后续趟数。我们可以用一个flag标记是否发生交换,实现优化:
c
#include <stdio.h>
void bubble_sort(int* arr, int sz) {
for (int i = 0; i < sz - 1; i++) {
int flag = 1; // 1:假设本趟有序,0:本趟无序
for (int j = 0; j < sz - i - 1; j++) {
if (*(arr + j) > *(arr + j + 1)) {
// 发生交换,标记为无序
flag = 0;
int tmp = *(arr + j);
*(arr + j) = *(arr + j + 1);
*(arr + j + 1) = tmp;
}
}
// 本趟无交换,数组已有序,提前退出
if (flag == 1) {
break;
}
}
}
// main函数与基础版一致
int main() {
int arr[] = {3,1,7,5,8,9,0,2,4,6};
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz); // 排序
// 打印排序后数组
for (int i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}优化效果 :若数组本身有序(如[1,2,3,4,5]),仅需1趟比较就终止,时间复杂度从O(n²)降至O(n)。(时间复杂度将会在未来的数据结构部分向大家进行介绍,敬请期待)
五、二级指针
指针变量也是变量,变量就有地址------那么"指针变量的地址"存放在哪里?答案是二级指针(指向指针的指针)。
5.1 定义与内存关系
定义格式:
数据类型 ** 二级指针名`= &一级指针名。
例如:
c
#include <stdio.h>
int main() {
int a = 10; // 普通变量
int* pa = &a; // 一级指针:指向a,存储a的地址
int** ppa = &pa; // 二级指针:指向pa,存储pa的地址
return 0;
}内存关系图解(地址为示例值):
| 变量 | 变量值(地址/数据) | 存储地址 |
|---|---|---|
| a | 10 | 0x0012ff50 |
| pa | 0x0012ff50(a的地址) | 0x0012ff48 |
| ppa | 0x0012ff48(pa的地址) | 0x0012ff40 |
5.2 核心运算
二级指针有两种关键运算:*ppa 和 **ppa,分别对应不同的访问层级:
-
*ppa:访问一级指针pa对二级指针解引用一次,得到的是一级指针
pa的值(即a的地址),等价于pa。例如:
*ppa = &b等价于pa = &b(让pa指向新变量b)。 -
**ppa:访问普通变量a对二级指针解引用两次,先通过
*ppa找到pa,再通过*pa找到a,等价于a。例如:
**ppa = 30等价于*pa = 30,最终等价于a = 30。
我们用代码来验证一下:
c
#include <stdio.h>
int main() {
int a = 10;
int* pa = &a;
int** ppa = &pa;
printf("a = %d\n", a); // 输出10
printf("*pa = %d\n", *pa); // 输出10(通过一级指针访问a)
printf("**ppa = %d\n", **ppa); // 输出10(通过二级指针访问a)
// 修改a的值:通过二级指针
**ppa = 30;
printf("修改后 a = %d\n", a); // 输出30
// 让pa指向新变量b:通过二级指针
int b = 20;
*ppa = &b;
printf("*pa = %d\n", *pa); // 输出20(pa现在指向b)
return 0;
}输出结果:
a = 10
*pa = 10
**ppa = 10
修改后 a = 30
*pa = 20
六、指针数组
类比"整型数组(存放int)""字符数组(存放char)",指针数组是"存放指针的数组"------数组的每个元素都是一个指针(地址)。
指针数组的定义
定义格式:
数据类型* 数组名数组长度
例如:int* parr[3] 表示"一个长度为3的数组,每个元素是int*类型的指针"。
数组结构示意:
| 数组元素 | 元素类型 | 存储内容(示例) |
|---|---|---|
| parr0 | int* |
0x0012ff50(某int的地址) |
| parr1 | int* |
0x0012ff60(某int的地址) |
| parr2 | int* |
0x0012ff70(某int的地址) |
七、指针数组模拟二维数组
普通二维数组(如int arr[3][5])的行是连续存储的,而指针数组可以通过"存储多个一维数组的首地址",模拟出二维数组的访问效果(但行不连续)。
实现步骤:
- 定义3个一维数组(模拟二维数组的3行);
- 定义指针数组
parr,存储这3个一维数组的首地址; - 通过双重循环访问:
parr[i][j]等价于*(parr[i] + j)(访问第i行第j列元素)。
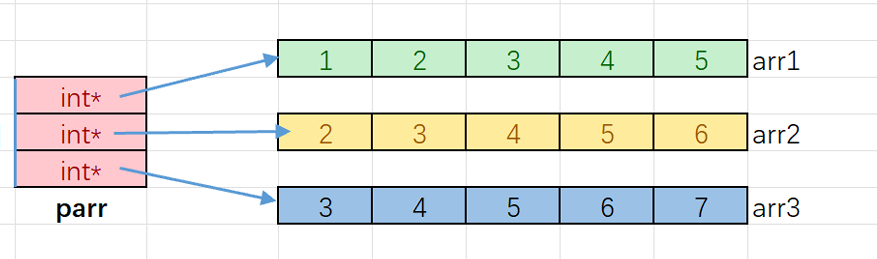
代码实现:
c
#include <stdio.h>
int main() {
// 3个一维数组(模拟二维数组的3行)
int arr1[] = {1,2,3,4,5};
int arr2[] = {2,3,4,5,6};
int arr3[] = {3,4,5,6,7};
// 指针数组:存储3个一维数组的首地址
int* parr[3] = {arr1, arr2, arr3};
// 双重循环:模拟二维数组访问
for (int i = 0; i < 3; i++) { // 控制"行"(3行)
for (int j = 0; j < 5; j++) { // 控制"列"(5列)
// parr[i][j] 等价于 *(parr[i] + j)
printf("%d ", parr[i][j]);
}
printf("\n"); // 每行结束换行
}
return 0;
}输出结果(模拟3行5列的二维数组):
1 2 3 4 5
2 3 4 5 6
3 4 5 6 7
关键说明:
- 这不是"真正的二维数组":普通二维数组的行是连续存储的,而指针数组的"行"(即3个一维数组)在内存中可能不连续;
- 优势:灵活度高,可将不同长度的一维数组"组合"成类似二维数组的结构,适合处理不规则数据。
通过这一讲,我们打通了"指针+数组"的应用链路------从基础概念到实战排序,再到进阶的二级指针与指针数组,这些知识点是C语言高效操作内存的核心。下一讲我们将进一步探索指针与函数、字符串的结合,敬请期待!